
 Périphériques technologiques
IA
Comment améliorer l'efficacité du stockage et de la transmission ? Le réseau de masques à forte intensité de paramètres a un effet significatif
Périphériques technologiques
IA
Comment améliorer l'efficacité du stockage et de la transmission ? Le réseau de masques à forte intensité de paramètres a un effet significatif
Comment améliorer l'efficacité du stockage et de la transmission ? Le réseau de masques à forte intensité de paramètres a un effet significatif

Afin de gérer des tâches plus complexes, l'échelle des réseaux de neurones a augmenté ces dernières années, et la manière de stocker et de transmettre efficacement les réseaux de neurones est devenue très importante. D'un autre côté, avec la proposition de l'hypothèse des billets de loterie (LTH), les réseaux neuronaux aléatoires et clairsemés ont récemment montré un fort potentiel. Il convient également d'explorer la manière d'utiliser ce potentiel pour améliorer l'efficacité du stockage et de la transmission du réseau.
Des chercheurs de la Northeastern University et du Rochester Institute of Technology ont proposé des réseaux de masquage efficaces aux paramètres (PEMN). Les auteurs explorent d'abord les capacités de représentation des réseaux stochastiques générés par un nombre limité de nombres aléatoires. Les expériences montrent que même si le réseau est généré à partir d’un nombre limité de nombres aléatoires, il possède toujours de bonnes capacités de représentation en choisissant différentes structures de sous-réseaux.
A travers cette expérience exploratoire, l'auteur a naturellement proposé d'utiliser comme prototype un nombre limité de nombres aléatoires, combiné à un ensemble de masques pour exprimer un réseau de neurones. Étant donné qu'un nombre limité de nombres aléatoires et de masques binaires occupent très peu d'espace de stockage, l'auteur l'utilise pour proposer une nouvelle idée de compression de réseau. L'article a été accepté pour NeurIPS 2022. Le code est open source.

- Adresse papier : https://arxiv.org/abs/2210.06699
- Code papier : https://github.com/yueb17/PEMN
1. Recherches connexes
Les chercheurs du MIT ont proposé l'hypothèse du billet de loterie (ICLR'19) : dans un réseau initialisé de manière aléatoire, il existe un sous-réseau de loterie (billet gagnant) qui obtient de bons résultats lorsqu'il est formé seul. L'hypothèse des billets de loterie explore la possibilité d'entraînement de réseaux stochastiques clairsemés. Les chercheurs d'Uber ont proposé Supermask (NeurIPS'19) : dans un réseau initialisé de manière aléatoire, il existe un sous-réseau qui peut être directement utilisé pour l'inférence sans formation. Supermask explore la convivialité des réseaux clairsemés stochastiques. Des chercheurs de l’Université de Washington ont proposé Edge-Popup (CVPR’20) : apprendre le masque du sous-réseau par rétropropagation, ce qui améliore considérablement la convivialité des réseaux clairsemés aléatoires.
2. Motivation/processus de recherche
Les recherches connexes ci-dessus ont exploré le potentiel des réseaux clairsemés aléatoires sous différents angles, tels que la capacité d'entraînement et la convivialité, où la convivialité peut également être comprise comme une capacité de représentation. Dans ce travail, les auteurs s'intéressent à la manière dont un réseau neuronal généré à partir de nombres aléatoires peut représenter sans poids d'entraînement. Suite à l’exploration de ce problème, les auteurs ont proposé des réseaux de masquage efficaces aux paramètres (PEMN). Naturellement, l’auteur utilise PEMN pour proposer une nouvelle idée de compression de réseau et sert d’exemple pour explorer les scénarios d’application potentiels de PEMN.
3. Explorez la capacité de représentation des réseaux de neurones composés de nombres aléatoires
Étant donné un réseau aléatoire, l'auteur choisit l'algorithme Edge-Popup pour sélectionner des sous-réseaux afin d'explorer sa capacité de représentation. La différence est qu'au lieu d'initialiser aléatoirement l'ensemble du réseau, l'auteur propose trois stratégies de génération de réseau à forte intensité de paramètres pour utiliser un prototype afin de construire un réseau aléatoire.
- Une couche : sélectionnez le poids de la structure répétée dans le réseau comme prototype pour remplir d'autres couches de réseau avec la même structure.
- Remplissage de couche maximale (MP) : sélectionnez la couche réseau avec le plus grand nombre de paramètres comme prototype et tronquez les quantités de paramètres correspondantes pour remplir d'autres couches réseau.
- Random vector padding (RP) : sélectionnez un vecteur aléatoire d'une certaine longueur comme prototype et copiez-le pour remplir l'ensemble du réseau.
Trois stratégies de génération de réseaux aléatoires différentes réduisent progressivement le nombre de valeurs uniques dans le réseau. Nous sélectionnons des sous-réseaux en fonction des réseaux aléatoires obtenus par différentes stratégies, explorant ainsi un nombre limité de nombres aléatoires. de réseaux aléatoires générés.

La figure ci-dessus montre les résultats expérimentaux de la classification d'images CIFAR10 à l'aide du réseau ConvMixer et ViT. L'axe Y est la précision et l'axe X est le réseau aléatoire obtenu en utilisant différentes stratégies. Comme le
Selon les résultats expérimentaux, nous avons observé que même si le réseau aléatoire ne dispose que d'un nombre très limité de nombres aléatoires non répétitifs (tels que PR_1e-3), il peut toujours bien maintenir la capacité de représentation du sous-réseau sélectionné. . Jusqu'à présent, l'auteur a exploré la capacité de représentation d'un réseau neuronal composé d'un nombre limité de nombres aléatoires à travers différentes stratégies de génération de réseaux aléatoires et a observé que même si les nombres aléatoires non répétitifs sont très limités, le réseau aléatoire correspondant peut toujours représenter bien les données.
Dans le même temps, sur la base de ces stratégies de génération de réseaux aléatoires et combiné au masque de sous-réseau obtenu, l'auteur a proposé un nouveau type de réseau neuronal appelé Réseaux de masquage efficaces aux paramètres (PEMN).
4. Une nouvelle idée de compression de réseau
Cet article choisit la compression de réseau neuronal comme exemple pour étendre les applications potentielles du PEMN. Plus précisément, les différentes stratégies de génération de réseaux aléatoires proposées dans cet article peuvent utiliser efficacement des prototypes pour représenter des réseaux aléatoires complets, en particulier la stratégie de remplissage vectoriel aléatoire (RP) la plus fine.
L'auteur utilise le prototype de vecteur aléatoire dans la stratégie RP et un ensemble correspondant de masques de sous-réseau pour représenter un réseau aléatoire. Le prototype doit être enregistré au format virgule flottante, tandis que le masque doit uniquement être enregistré au format binaire. Étant donné que la longueur du prototype dans RP peut être très courte (car un nombre limité de nombres aléatoires non répétitifs ont toujours une forte capacité de représentation), la surcharge liée à la représentation d'un réseau neuronal deviendra très faible, c'est-à-dire le stockage d'un format de nombre à virgule flottante avec une longueur limitée. Un vecteur aléatoire et un ensemble de masques au format binaire. Par rapport aux réseaux clairsemés traditionnels qui stockent les valeurs à virgule flottante des sous-réseaux, cet article propose une nouvelle idée de compression de réseau pour stocker et transmettre efficacement les réseaux de neurones.

Dans la figure ci-dessus, l'auteur utilise PEMN pour compresser le réseau et le compare avec la méthode traditionnelle d'élagage du réseau. L'expérience utilise le réseau ResNet pour effectuer des tâches de classification d'images sur l'ensemble de données du CIFAR. Nous observons que le nouveau schéma de compression fonctionne généralement mieux que l'élagage de réseau traditionnel, notamment à des taux de compression très élevés, le PEMN peut toujours conserver une bonne précision.
5. Conclusion
Inspiré par le potentiel démontré récemment par les réseaux aléatoires, cet article propose différentes stratégies intensives en paramètres pour construire des réseaux de neurones aléatoires, puis explore les méthodes générées lorsqu'il n'y a que des nombres aléatoires non répétitifs limités. Le potentiel de représentation de réseaux neuronaux aléatoires et les réseaux de masquage efficaces aux paramètres (PEMN) sont proposés. L'auteur applique le PEMN aux scénarios de compression réseau pour explorer son potentiel dans des applications pratiques et propose une nouvelle idée pour la compression réseau. Les auteurs proposent des expériences approfondies montrant que même s’il n’y a qu’un nombre très limité de nombres aléatoires non répétitifs dans un réseau aléatoire, celui-ci possède toujours de bonnes capacités de représentation grâce à la sélection de sous-réseaux. De plus, par rapport aux algorithmes d'élagage traditionnels, les expériences montrent que la méthode nouvellement proposée peut obtenir de meilleurs effets de compression de réseau, vérifiant ainsi le potentiel d'application du PEMN dans ce scénario.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Huawei lancera l'année prochaine des produits de stockage MED innovants : la capacité du rack dépasse 10 Po et la consommation électrique est inférieure à 2 kW
Mar 07, 2024 pm 10:43 PM
Huawei lancera l'année prochaine des produits de stockage MED innovants : la capacité du rack dépasse 10 Po et la consommation électrique est inférieure à 2 kW
Mar 07, 2024 pm 10:43 PM
Ce site Web a rapporté le 7 mars que le Dr Zhou Yuefeng, président de la gamme de produits de stockage de données de Huawei, a récemment assisté à la conférence MWC2024 et a spécifiquement présenté la solution de stockage magnétoélectrique OceanStorArctic de nouvelle génération conçue pour les données chaudes (WarmData) et les données froides (ColdData). Zhou Yuefeng, président de la gamme de produits de stockage de données de Huawei, a publié une série de solutions innovantes Source de l'image : Le communiqué de presse officiel de Huawei joint à ce site est le suivant : Le coût de cette solution est 20 % inférieur à celui de la bande magnétique, et son coût est de 20 % inférieur à celui de la bande magnétique. la consommation électrique est 90 % inférieure à celle des disques durs. Selon les médias technologiques étrangers blockandfiles, un porte-parole de Huawei a également révélé des informations sur la solution de stockage magnétoélectrique : le disque magnétoélectronique (MED) de Huawei est une innovation majeure dans le domaine des supports de stockage magnétiques. ME de première génération
 Compétences en développement Vue3+TS+Vite : comment chiffrer et stocker des données
Sep 10, 2023 pm 04:51 PM
Compétences en développement Vue3+TS+Vite : comment chiffrer et stocker des données
Sep 10, 2023 pm 04:51 PM
Conseils de développement Vue3+TS+Vite : Comment crypter et stocker des données Avec le développement rapide de la technologie Internet, la sécurité des données et la protection de la vie privée deviennent de plus en plus importantes. Dans l'environnement de développement Vue3+TS+Vite, comment chiffrer et stocker les données est un problème auquel chaque développeur doit faire face. Cet article présentera certaines techniques courantes de cryptage et de stockage des données pour aider les développeurs à améliorer la sécurité des applications et l'expérience utilisateur. 1. Chiffrement des données Chiffrement des données frontal Le chiffrement frontal est un élément important de la protection de la sécurité des données. Couramment utilisé
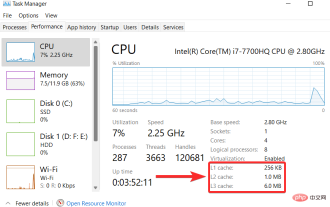 Comment vider le cache sous Windows 11 : Tutoriel détaillé avec images
Apr 24, 2023 pm 09:37 PM
Comment vider le cache sous Windows 11 : Tutoriel détaillé avec images
Apr 24, 2023 pm 09:37 PM
Qu’est-ce que le cache ? Un cache (prononcé ka·shay) est un composant matériel ou logiciel spécialisé à haute vitesse utilisé pour stocker des données et des instructions fréquemment demandées, qui à leur tour peuvent être utilisées pour charger plus rapidement des sites Web, des applications, des services et d'autres aspects du système. . La mise en cache rend les données les plus fréquemment consultées facilement disponibles. Les fichiers cache ne sont pas identiques à la mémoire cache. Les fichiers cache font référence aux fichiers fréquemment nécessaires tels que les fichiers PNG, les icônes, les logos, les shaders, etc., qui peuvent être requis par plusieurs programmes. Ces fichiers sont stockés dans votre espace disque physique, généralement cachés. La mémoire cache, quant à elle, est un type de mémoire plus rapide que la mémoire principale et/ou la RAM. Il réduit considérablement le temps d'accès aux données car il est plus proche du CPU et plus rapide que la RAM.
 Processus d'installation de Git sur Ubuntu
Mar 20, 2024 pm 04:51 PM
Processus d'installation de Git sur Ubuntu
Mar 20, 2024 pm 04:51 PM
Git est un système de contrôle de version distribué rapide, fiable et adaptable. Il est conçu pour prendre en charge des flux de travail distribués et non linéaires, ce qui le rend idéal pour les équipes de développement de logiciels de toutes tailles. Chaque répertoire de travail Git est un référentiel indépendant avec un historique complet de toutes les modifications et la possibilité de suivre les versions même sans accès au réseau ni serveur central. GitHub est un référentiel Git hébergé sur le cloud qui fournit toutes les fonctionnalités du contrôle de révision distribué. GitHub est un référentiel Git hébergé sur le cloud. Contrairement à Git qui est un outil CLI, GitHub dispose d'une interface utilisateur graphique basée sur le Web. Il est utilisé pour le contrôle de version, ce qui implique de collaborer avec d'autres développeurs et de suivre les modifications apportées aux scripts et aux scripts au fil du temps.
 Comment utiliser correctement sessionStorage pour protéger les données sensibles
Jan 13, 2024 am 11:54 AM
Comment utiliser correctement sessionStorage pour protéger les données sensibles
Jan 13, 2024 am 11:54 AM
Comment utiliser correctement sessionStorage pour stocker des informations sensibles nécessite des exemples de code spécifiques Que ce soit dans le développement Web ou le développement d'applications mobiles, nous devons souvent stocker et traiter des informations sensibles, telles que les informations de connexion des utilisateurs, les numéros d'identification, etc. Dans le développement front-end, l'utilisation de sessionStorage est une solution de stockage courante. Cependant, étant donné que sessionStorage est un stockage basé sur un navigateur, certains problèmes de sécurité doivent être pris en compte pour garantir que les informations sensibles stockées ne soient pas consultées et utilisées de manière malveillante.
 Comment transférer des fichiers d'enregistrement d'écran vers un téléphone mobile sans perte_Tutoriel sur le transfert de vidéos d'enregistrement d'écran d'un ordinateur vers un téléphone mobile sans compression
Mar 01, 2024 pm 09:53 PM
Comment transférer des fichiers d'enregistrement d'écran vers un téléphone mobile sans perte_Tutoriel sur le transfert de vidéos d'enregistrement d'écran d'un ordinateur vers un téléphone mobile sans compression
Mar 01, 2024 pm 09:53 PM
Dans notre vie quotidienne et au travail, nous devons souvent utiliser des appareils informatiques et mobiles pour transférer des fichiers vidéo entre eux. Cependant, les fichiers vidéo à la réception sont sujets au flou. Cela est dû à la compression du logiciel de transmission. le processus de transmission. Comment éviter cette situation et comment transférer des fichiers vers un autre appareil sans perte ? Vous pouvez utiliser le logiciel d'enregistrement d'écran EV pour transférer les fichiers vidéo enregistrés sur le téléphone mobile vers l'ordinateur sous une forme sans perte et non compressée pour la lecture originale. La vidéo ci-dessous vous apportera des tutoriels pertinents, j'espère qu'elle pourra vous aider. La première étape pour transférer sans perte des fichiers d'enregistrement d'écran sur votre téléphone mobile consiste à télécharger le logiciel d'enregistrement d'écran EV sur votre téléphone mobile, puis à cliquer sur « Boîte à outils » sur la page d'accueil et à rechercher la fonction « Transfert WiFi ». La deuxième étape est d'abandonner
 Comment PHP et Swoole parviennent-ils à une mise en cache et un stockage efficaces des données ?
Jul 23, 2023 pm 04:03 PM
Comment PHP et Swoole parviennent-ils à une mise en cache et un stockage efficaces des données ?
Jul 23, 2023 pm 04:03 PM
Comment PHP et Swoole parviennent-ils à une mise en cache et un stockage efficaces des données ? Présentation : Dans le développement d'applications Web, la mise en cache et le stockage des données sont un élément très important. PHP et swoole fournissent une méthode efficace pour mettre en cache et stocker des données. Cet article présentera comment utiliser PHP et swoole pour obtenir une mise en cache et un stockage efficaces des données, et donnera des exemples de code correspondants. 1. Introduction à swoole : swoole est un moteur de communication réseau asynchrone hautes performances développé pour le langage PHP.
 Comprendre les tableaux d'intelligence artificielle dans un seul article : commencer avec MindsDB
Apr 12, 2023 pm 12:04 PM
Comprendre les tableaux d'intelligence artificielle dans un seul article : commencer avec MindsDB
Apr 12, 2023 pm 12:04 PM
Cet article est réimprimé du compte public WeChat « Vivre à l'ère de l'information ». L'auteur vit à l'ère de l'information. Pour réimprimer cet article, veuillez contacter le compte public Vivre à l’ère de l’information. Pour les étudiants familiarisés avec les opérations de base de données, écrire de belles instructions SQL et trouver des moyens de trouver les données dont ils ont besoin dans la base de données est une opération de routine. Pour les étudiants familiarisés avec l'apprentissage automatique, il s'agit également d'une opération de routine consistant à obtenir des données, à prétraiter les données, à créer un modèle, à déterminer l'ensemble de formation et l'ensemble de test, et à utiliser le modèle formé pour faire une série de prédictions sur l'avenir. Alors, peut-on combiner les deux technologies ? Nous voyons que les données sont stockées dans la base de données et que les prédictions doivent être basées sur des données passées. Si nous interrogeons les données futures via les données existantes dans la base de données, alors il est
