

Extrayez des fonctionnalités significatives à partir de données de séries chronologiques à l'aide de Pandas et Python, notamment les moyennes mobiles, l'autocorrélation et les transformations de Fourier.
L'analyse des séries chronologiques est un outil puissant pour comprendre et prédire les tendances dans divers secteurs (tels que la finance, l'économie, la santé, etc.). L'extraction de fonctionnalités est une étape clé de ce processus, qui implique la conversion des données brutes en fonctionnalités significatives pouvant être utilisées pour entraîner des modèles à des fins de prédiction et d'analyse. Dans cet article, nous explorerons les techniques d'extraction de fonctionnalités de séries chronologiques à l'aide de Python et Pandas.
Avant de nous plonger dans l’extraction de fonctionnalités, passons brièvement en revue les données de séries chronologiques. Les données de séries chronologiques sont une séquence de points de données indexés par ordre chronologique. Des exemples de données de séries chronologiques incluent les cours des actions, les mesures de température et les données de trafic. Les données de séries chronologiques peuvent être univariées ou multivariées. Les données de séries chronologiques univariées n'ont qu'une seule variable, tandis que les données de séries chronologiques multivariées ont plusieurs variables.

Il existe diverses techniques d'extraction de caractéristiques qui peuvent être utilisées pour l'analyse de séries chronologiques. Dans cet article, nous présenterons les techniques suivantes :
import pandas as pd
# create a time series with minute frequency
ts = pd.Series([1, 2, 3, 4, 5], index=pd.date_range('2022-01-01', periods=5, freq='T'))
# downsample to daily frequency
daily_ts = ts.resample('D').sum()
print(daily_ts)Dans l'exemple ci-dessus, nous avons créé une série temporelle avec une fréquence de minutes, puis l'avons échantillonnée à une fréquence quotidienne à l'aide de la méthode resample().
 2. Moyenne mobile
2. Moyenne mobile
import pandas as pd # create a time series ts = pd.Series([1, 2, 3, 4, 5]) # calculate the rolling mean with a window size of 3 rolling_mean = ts.rolling(window=3).mean() print(rolling_mean)
Nous créons une série temporelle puis utilisons la méthode Rolling() pour calculer la moyenne mobile avec une taille de fenêtre de 3.
 Vous pouvez voir que les deux premières valeurs généreront du NAN car elles n'atteignent pas le nombre minimum de moyenne mobile 3. Si nécessaire, vous pouvez utiliser la méthode fillna pour remplir.
Vous pouvez voir que les deux premières valeurs généreront du NAN car elles n'atteignent pas le nombre minimum de moyenne mobile 3. Si nécessaire, vous pouvez utiliser la méthode fillna pour remplir.
3. Lissage exponentiel
import pandas as pd ts = pd.Series([1, 2, 3, 4, 5]) ts.ewm( alpha =0.5).mean()
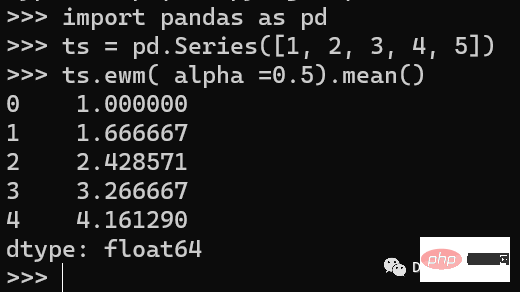 Dans l'exemple ci-dessus, nous avons créé une série chronologique puis utilisé la méthode ewm() pour calculer une moyenne mobile exponentielle avec un facteur de lissage de 0,5.
Dans l'exemple ci-dessus, nous avons créé une série chronologique puis utilisé la méthode ewm() pour calculer une moyenne mobile exponentielle avec un facteur de lissage de 0,5.
ewm a de nombreux paramètres, nous en présentons ici quelques-uns principaux.
com : Spécifiez l'atténuation en fonction du centre de masse




min_periods Nombre minimum d'observations avec des valeurs dans la fenêtre, par défaut 0.
ajuster S'il faut effectuer une correction d'erreur. La valeur par défaut est True.
adjust =Ture时公式如下:

adjust =False

Autocorrelation 自相关是一种用于测量时间序列与其滞后版本之间相关性的技术。可以识别数据中重复的模式。Pandas提供了autocorr()方法来计算自相关性。
import pandas as pd # create a time series ts = pd.Series([1, 2, 3, 4, 5]) # calculate the autocorrelation with a lag of 1 autocorr = ts.autocorr(lag=1) print(autocorr)

Fourier Transform 傅里叶变换是一种将时间序列数据从时域变换到频域的技术。可以识别数据中的周期性模式。我们可以使用numpy的fft()方法来计算时间序列的快速傅里叶变换。
import pandas as pd import numpy as np # create a time series ts = pd.Series([1, 2, 3, 4, 5]) # calculate the Fourier transform fft = pd.Series(np.fft.fft(ts).real) print(fft)

这里我们只显示了实数的部分。
在本文中,我们介绍了几种使用Python和Pandas的时间序列特征提取技术。这些技术可以帮助将原始时间序列数据转换为可用于分析和预测的有意义的特征,在训练机器学习模型时,这些特征都可以当作额外的数据输入到模型中,可以增加模型的预测能力。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



