

L'algorithme de propagation d'étiquettes est un algorithme d'apprentissage automatique semi-supervisé qui attribue des étiquettes à des points de données précédemment non étiquetés. Pour utiliser cet algorithme en apprentissage automatique, seule une petite fraction des exemples comporte des étiquettes ou des classifications. Ces étiquettes sont propagées aux points de données non étiquetés pendant les processus de modélisation, d'ajustement et de prédiction de l'algorithme.

LabelPropagation est un algorithme rapide pour trouver des communautés dans des graphiques. Il utilise uniquement la structure du réseau comme guide pour détecter ces connexions et ne nécessite pas de fonction objectif prédéfinie ni d'informations a priori sur la population. La propagation des balises est obtenue en propageant des balises dans le réseau et en formant des connexions basées sur le processus de propagation des balises.
Les balises fermées reçoivent généralement la même balise. Un seul label peut dominer dans des groupes de nœuds densément connectés, mais aura des difficultés dans les régions peu connectées. Les étiquettes seront limitées à un groupe de nœuds étroitement connectés, et lorsque l'algorithme sera terminé, les nœuds qui se retrouveront avec la même étiquette pourront être considérés comme faisant partie de la même connexion. L'algorithme utilise la théorie des graphes comme suit :-
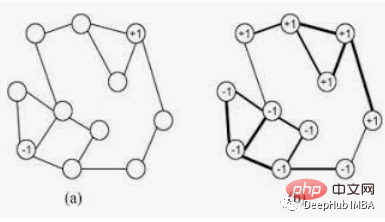
L'algorithme LabelPropagation fonctionne de la manière suivante :-
Pour démontrer le fonctionnement de l'algorithme LabelPropagation, nous utilisons l'ensemble de données Pima Indians Lors de la création du programme, j'ai importé les bibliothèques nécessaires à son exécution

Copiez une copie des données et utilisez la colonne d'étiquette comme colonne. cible de formation

Visualisation à l'aide de matplotlib :

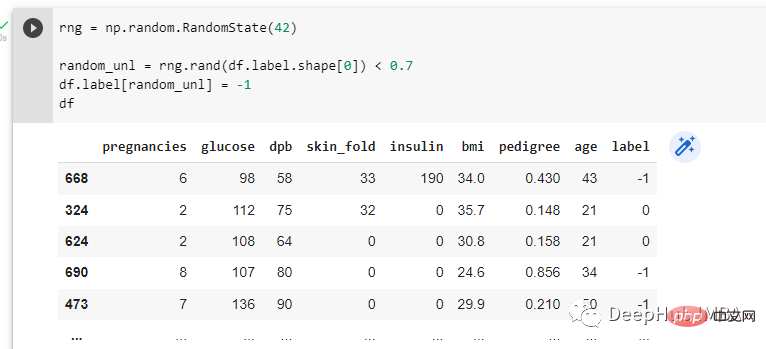
Randomisez 70 % des étiquettes de l'ensemble de données à l'aide d'un générateur de nombres aléatoires. Ensuite, des étiquettes aléatoires se voient attribuer -1 :-
Après le prétraitement des données, définissez les variables dépendantes et indépendantes, qui sont respectivement y et X. La variable y est la dernière colonne et la

Jetons un coup d'œil à un autre algorithme LabelSpreading.
LabelSpreading
 LabelSpreading peut être considérée comme la forme régularisée de LabelPropagation. En théorie des graphes, la matrice laplacienne est la représentation matricielle du graphe. La formule de la matrice laplacienne est :
LabelSpreading peut être considérée comme la forme régularisée de LabelPropagation. En théorie des graphes, la matrice laplacienne est la représentation matricielle du graphe. La formule de la matrice laplacienne est :
L est la matrice laplacienne, D est la matrice des degrés et A est la matrice de contiguïté.
Ce qui suit est un exemple simple d'étiquetage de graphe non orienté et le résultat de sa matrice laplacienne

Cet article utilisera l'ensemble de données du sonar pour démontrer comment utiliser la fonction LabelSpreading de sklearn.
Il y a plus de bibliothèques ici que ci-dessus, alors expliquez brièvement :
Une fois l'importation terminée, utilisez pandas pour lire l'ensemble de données :

J'ai créé la carte thermique en utilisant seaborn :-

Effectuez d'abord un prétraitement simple et supprimez les colonnes hautement corrélées, réduisant ainsi le nombre de colonnes de 61 à 58 :

Ensuite, mélangez et réorganisez les données, de sorte que les prédictions dans l'ensemble de données brouillées soient généralement meilleures. Pour être exact, faites une copie de l'ensemble de données et définissez y_orig comme cible d'entraînement :

Utilisez matplotlib pour dessiner un nuage de points 2D des points de données :-

Utilisez un générateur de nombres aléatoires pour randomiser 60 % de la balise de l'ensemble de données . Ensuite, des étiquettes aléatoires se voient attribuer -1 :-

Après le prétraitement des données, définissez les variables dépendantes et indépendantes, qui sont respectivement y et X. La variable y est la dernière colonne et la
En utilisant cette méthode, nous pouvons atteindre une précision de 87,98 % :-
Comparaison simple
1. Labelspreading contient alpha=0,2, alpha est appelé coefficient de serrage, qui fait référence à l'utilisation des informations de ses voisins. Ce n'est pas la quantité relative de son étiquette initiale. S'il est 0, cela signifie conserver les informations de l'étiquette initiale. S'il est 1, cela signifie remplacer toutes les informations initiales ; informations ; 
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Algorithme de remplacement de page
Algorithme de remplacement de page
 Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ?
 Comment résoudre l'erreur du ventilateur du processeur
Comment résoudre l'erreur du ventilateur du processeur
 La différence entre injectif et surjectif
La différence entre injectif et surjectif
 qu'est-ce que le moteur de recherche
qu'est-ce que le moteur de recherche
 Quelles sont les utilisations du dézender ?
Quelles sont les utilisations du dézender ?
 locallapstore
locallapstore
 Méthodes de réparation des vulnérabilités des bases de données
Méthodes de réparation des vulnérabilités des bases de données








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



