
 Périphériques technologiques
IA
Si elle ne peut pas soutenir sa vision de l'avenir, l'intelligence artificielle inaugurera-t-elle à nouveau un « hiver » ?
Périphériques technologiques
IA
Si elle ne peut pas soutenir sa vision de l'avenir, l'intelligence artificielle inaugurera-t-elle à nouveau un « hiver » ?
Si elle ne peut pas soutenir sa vision de l'avenir, l'intelligence artificielle inaugurera-t-elle à nouveau un « hiver » ?

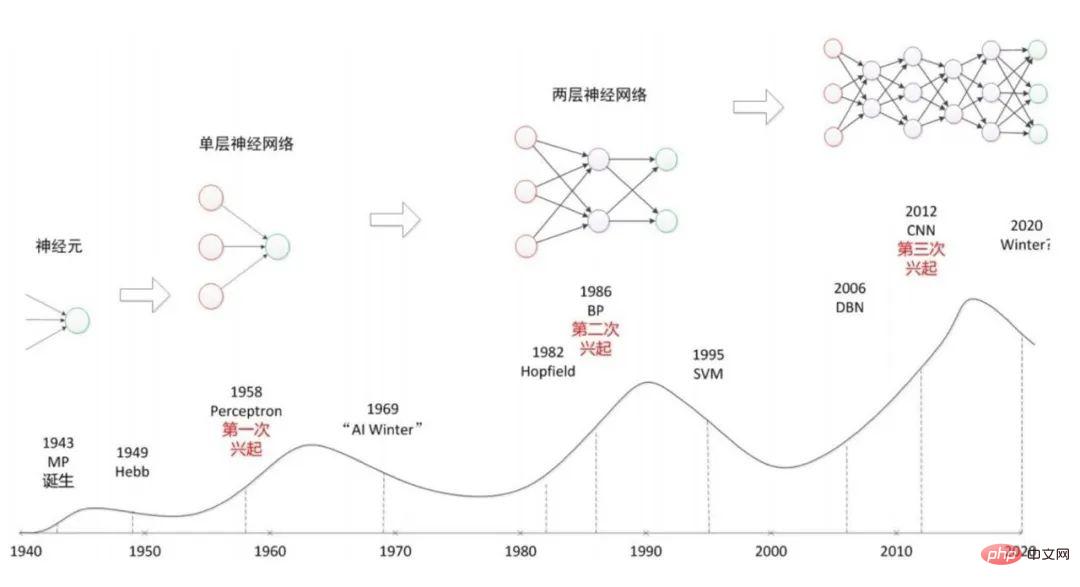
Depuis qu'Alan Turing a soulevé pour la première fois la question « Les machines peuvent-elles penser ? » dans son article fondateur « Computing Machinery and Intelligence » en 1950, le développement de l'intelligence artificielle ne s'est pas déroulé sans heurts et elle n'a pas encore atteint son « intelligence artificielle universelle ». " Objectif « intelligent ».

Cependant, le domaine a encore connu des progrès incroyables, tels que : le robot Deep Blue d'IBM battant le meilleur joueur d'échecs du monde, la naissance des voitures autonomes et AlphaGo de Google DeepMind battant les meilleurs joueurs de Go au monde. .. les réalisations actuelles démontrent les meilleurs résultats de recherche et de développement des quelque 65 dernières années.
Il convient de noter qu’il y a eu un « hiver de l’IA » bien documenté au cours de cette période, qui a presque complètement bouleversé les premières bonnes attentes des gens en matière d’intelligence artificielle.
L'un des facteurs qui ont conduit à l'hiver de l'IA est l'écart entre le battage médiatique et les progrès fondamentaux réels.
Au cours des dernières années, des spéculations ont été émises selon lesquelles un nouvel hiver de l'intelligence artificielle pourrait arriver. Alors, quels facteurs pourraient déclencher une ère glaciaire de l'intelligence artificielle ?
Fluctuations cycliques de l'intelligence artificielle
Un «hiver de l'IA» fait référence à une période pendant laquelle l'intérêt du public pour l'intelligence artificielle diminue progressivement à mesure que les investissements dans ces technologies dans les domaines commercial et universitaire diminuent progressivement.
L'intelligence artificielle s'est développée rapidement dans les années 1950 et 1960. Même si les avancées en matière d’intelligence artificielle ont été nombreuses, elles sont pour la plupart restées académiques.
Au début des années 1970, l’enthousiasme des gens pour l’intelligence artificielle commence à s’estomper, et cette période sombre dure jusque vers 1980.
En cet hiver de l'intelligence artificielle, les activités dédiées au développement d'une intelligence de type humain pour les machines commencent à manquer de financement.
Au cours de l'été 1956, un groupe de mathématiciens et d'informaticiens occupait le dernier étage du bâtiment qui abrite le département de mathématiques du Dartmouth College.
Pendant huit semaines, ils ont imaginé ensemble un nouveau domaine de recherche.
En tant que jeune professeur à l'Université de Dartmouth à l'époque, John McCarthy a inventé le terme « intelligence artificielle » alors qu'il concevait une proposition de séminaire.
Il estime que l'atelier devrait explorer l'hypothèse selon laquelle "chaque aspect de l'apprentissage humain ou toute autre caractéristique de l'intelligence peut en principe être décrit avec une telle précision qu'il peut être simulé par des machines".
Lors de cette réunion, les chercheurs ont esquissé les grandes lignes de l'intelligence artificielle telle que nous la connaissons aujourd'hui.
Il a donné naissance au premier camp de scientifiques en intelligence artificielle. Le « symbolisme » est une méthode de simulation intelligente basée sur le raisonnement logique, également connue sous le nom de logicisme, école de psychologie ou école d'informatique. Son principe repose principalement sur l'hypothèse physique. le système de symboles et le principe de rationalité limitée, qui ont longtemps dominé la recherche sur l’IA.
Leur système expert a atteint son apogée dans les années 1980.
Dans les années qui ont suivi la conférence, le « connexionnisme » attribuait l'intelligence humaine aux activités de haut niveau du cerveau humain, soulignant que la génération de l'intelligence est le résultat d'un grand nombre d'unités simples fonctionnant en parallèle à travers des interconnexions complexes. .
Il part des neurones puis étudie des modèles de réseaux neuronaux et des modèles cérébraux, ouvrant ainsi une autre voie de développement de l'intelligence artificielle.
Les deux approches ont longtemps été considérées comme s’excluant mutuellement, les deux parties estimant être sur la voie de l’intelligence artificielle générale.
En regardant les décennies qui ont suivi cette conférence, nous pouvons constater que les espoirs des chercheurs en IA ont souvent été déçus, et que ces revers ne les ont pas empêchés de développer l’IA.
Aujourd’hui, même si l’intelligence artificielle apporte des changements révolutionnaires aux industries et a le potentiel de perturber le marché du travail mondial, de nombreux experts se demandent encore si les applications actuelles de l’intelligence artificielle ont atteint leurs limites.
Comme le décrit Charles Choi dans Seven Revealed Ways AI Fail, les faiblesses des systèmes d'apprentissage profond d'aujourd'hui deviennent de plus en plus apparentes.
Pour autant, les chercheurs ne sont pas pessimistes quant à l’avenir de l’intelligence artificielle. Nous pourrions être confrontés à un nouvel hiver de l’IA dans un avenir proche.
Mais c’est peut-être le moment où des ingénieurs en IA inspirés nous conduisent enfin dans l’éternel été de la pensée machine.
Un article de Filip Piekniewski, expert en vision par ordinateur et en intelligence artificielle, intitulé "AI Winter is Coming" a suscité de vives discussions sur Internet.
Cet article critique principalement le battage médiatique autour du deep learning, estimant que cette technologie est loin d'être révolutionnaire et se heurte à des goulots d'étranglement de développement.
L’intérêt des grandes entreprises pour l’intelligence artificielle converge en fait, et un autre hiver de performance de l’intelligence artificielle pourrait bientôt arriver.
L'hiver de l'intelligence artificielle viendra-t-il ?
Depuis 1993, le domaine de l’intelligence artificielle a fait des progrès de plus en plus impressionnants.
En 1997, le système Deep Blue d'IBM est devenu le premier à vaincre le champion du monde d'échecs Gary﹒ Le joueur d'échecs informatique de Kasparov.
En 2005, un robot sans conducteur de Stanford a parcouru 131 miles sur une route du désert sans toucher un seul pas, remportant le DARPA Self-Driving Robot Challenge.
Début 2016, AlphaGo de DeepMind de Google a battu le meilleur joueur de Go au monde.
Tout a changé au cours des vingt dernières années.
Surtout avec le développement fulgurant d'Internet, l'industrie de l'intelligence artificielle dispose de suffisamment d'images, de sons, de vidéos et d'autres types de données pour entraîner les réseaux neuronaux et les appliquer largement.
Mais le succès sans cesse croissant du domaine du deep learning repose sur l'augmentation du nombre de couches dans les réseaux de neurones et sur l'augmentation du temps GPU utilisé pour les entraîner.
Une analyse réalisée par la société de recherche en intelligence artificielle OpenAI montre que la puissance de calcul requise pour former les plus grands systèmes d'intelligence artificielle double tous les deux ans, puis double tous les 3-4 mois.
Comme l’écrivent Neil C. Thompson et ses collègues dans Diminishing Returns of Deep Learning, de nombreux chercheurs craignent que les besoins informatiques de l’IA ne soient sur une trajectoire supérieure insoutenable.
Un problème courant rencontré par les premières recherches sur l'intelligence artificielle est un grave manque de puissance de calcul. Elles sont limitées par le matériel plutôt que par l'intelligence ou les capacités humaines.
À mesure que la puissance de calcul a considérablement augmenté au cours des 25 dernières années, les progrès que nous avons réalisés en matière d’intelligence artificielle ont également augmenté.
Cependant, face à l'augmentation massive des données et aux algorithmes de plus en plus complexes, le monde ajoute 20 ZB de données chaque année, et la demande en puissance de calcul de l'IA augmente 10 fois chaque année. Cette vitesse a largement dépassé le cycle de performance. doublé par la loi de Moore.
Nous approchons de la limite physique théorique du nombre de transistors pouvant être installés sur une puce.
Par exemple, Intel ralentit le rythme de lancement de nouvelles technologies de fabrication de puces car il est difficile de continuer à réduire la taille des transistors tout en réalisant des économies. Bref, la fin de la loi de Moore approche.

Crédit image : Ray Kurzwell, DFJ
Il existe des solutions à court terme qui assureront une croissance continue de la puissance de calcul, favorisant ainsi l'avancement de l'intelligence artificielle.
Par exemple, mi-2017, Google a annoncé avoir développé une puce d'intelligence artificielle spécialisée appelée « Cloud TPU », optimisée pour la formation et l'exécution de réseaux de neurones profonds.
Amazon développe sa propre puce pour Alexa (assistant personnel à intelligence artificielle). Dans le même temps, de nombreuses startups tentent actuellement d’adapter la conception de puces à des applications spécialisées en intelligence artificielle.
Cependant, ce ne sont que des solutions à court terme.
Que se passe-t-il lorsque nous manquons d'options pour optimiser la conception de puces traditionnelles ? Verrons-nous un autre hiver de l’IA ? La réponse est oui, à moins que l’informatique quantique puisse surpasser l’informatique classique et trouver une réponse plus solide.
Mais jusqu'à présent, il n'existe pas encore d'ordinateur quantique capable d'atteindre la « suprématie quantique » et plus efficace qu'un ordinateur traditionnel.
Si nous atteignons la limite de la puissance de calcul traditionnelle avant l'arrivée d'une véritable « suprématie quantique », je crains qu'il n'y ait un autre hiver de l'intelligence artificielle dans le futur.
Les problèmes auxquels les chercheurs en intelligence artificielle sont confrontés sont de plus en plus complexes et nous poussent à concrétiser la vision d’Alan Turing de l’intelligence artificielle générale artificielle. Cependant, il reste encore beaucoup de travail à faire.
Dans le même temps, il est très peu probable que nous puissions réaliser tout le potentiel de l’intelligence artificielle sans l’aide de l’informatique quantique.
Personne ne peut dire avec certitude si l'hiver de l'IA arrive.
Cependant, il est important d'être conscient des risques potentiels et de porter une attention particulière aux signes afin que nous puissions être préparés lorsque cela se produit.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
