

Utilisez Python pour analyser 1,4 milliard de données


Google Ngram Viewer est un outil amusant et utile qui utilise le vaste trésor de données numérisées de livres de Google pour tracer les changements dans l'utilisation des mots au fil du temps. Par exemple, le mot Python (sensible à la casse) :
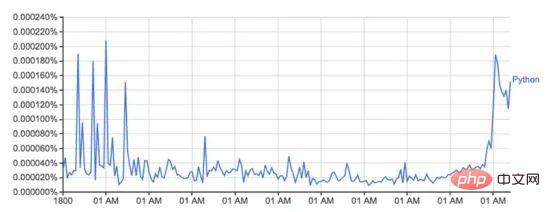
Ce graphique de books.google.com/ngrams… décrit l'utilisation du mot « Python » au fil du temps.
Il est alimenté par l'ensemble de données n-gram de Google, qui enregistre l'utilisation d'un mot ou d'une expression spécifique dans Google Books pour chaque année d'impression du livre. Cependant, ce n'est pas complet (cela n'inclut pas tous les livres jamais publiés !), il y a des millions de livres dans l'ensemble de données, couvrant la période du 16ème siècle à 2008. L'ensemble de données peut être téléchargé gratuitement à partir d'ici.
J'ai décidé d'utiliser Python et ma nouvelle bibliothèque de chargement de données PyTubes pour voir à quel point il était facile de régénérer le tracé ci-dessus.
Challenge
L'ensemble de données de 1 gramme peut être étendu à 27 Go de données sur le disque dur, ce qui représente une grande quantité de données une fois lu en python. Python peut facilement traiter des gigaoctets de données à la fois, mais lorsque les données sont corrompues et traitées, cela devient plus lent et moins efficace en termes de mémoire.
Au total, ces 1,4 milliards de données (1 430 727 243) sont dispersées dans 38 fichiers sources, avec un total de 24 millions (24 359 460) de mots (et balises de parties de discours, voir ci-dessous), calculés de 1505 à 2008. .
Lors du traitement d'un milliard de lignes de données, les choses ralentissent rapidement. Et Python natif n’est pas optimisé pour gérer cet aspect des données. Heureusement, numpy est vraiment efficace pour gérer de grandes quantités de données. En utilisant quelques astuces simples, nous pouvons rendre cette analyse réalisable en utilisant numpy.
La gestion des chaînes en python/numpy est compliquée. La surcharge de mémoire des chaînes en python est importante et numpy ne peut gérer que des chaînes de longueur connue et fixe. En raison de cette situation, la plupart des mots sont de longueurs différentes, ce n’est donc pas idéal.
Chargement des données
Tous les codes/exemples ci-dessous fonctionnent sur un Macbook Pro 2016 avec 8 Go de RAM. Si le matériel ou l'instance cloud a une meilleure configuration de RAM, les performances seront meilleures.
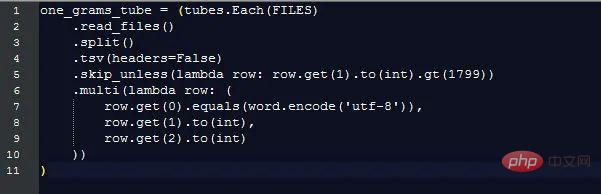
Les données de 1 gramme sont stockées dans le fichier sous la forme d'un formulaire délimité par des tabulations, qui se présente comme suit :

Chaque élément de données contient les champs suivants :
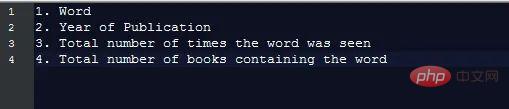
Afin de générer des graphiques comme requis, nous avons seulement besoin de connaître ces informations, c'est-à-dire :

En extrayant ces informations, le coût supplémentaire du traitement des données de chaîne de différentes longueurs est ignoré, mais nous devons quand même comparer les valeursde différentes chaînes pour distinguer les lignes de données qui correspondent aux champs qui nous intéressent. Voici ce que pytubes peut faire :
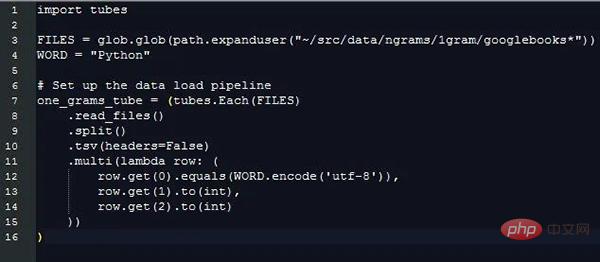
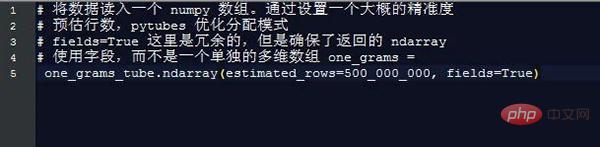
Près de 170 secondes (3 minutes) plus tard, one_grams est un tableau numpy contenant près de 1,4 milliard de lignes de données, ressemblant à ceci (en-têtes ajoutés à titre d'illustration) :
╒ ═══════════╤═══════════════╕
│ Is_Word │Année │Count │
╞══ │
├─ ──────── ──┼────────┼─────────┤
│ 0 │ 1804 │ 1 │
├──────── ───┼──── ────┼────────┤
│ 0 │ 1805 │
├──── ───────┼──── ──────┼── ───────┤
│ 0 │ 1811 │ 1 │
├───────── ──┼────────┼ ───────── ┤
│ 0 │ 1820 │ ... │
╘═══════════╧════ ════╧════ ═ ════╛
À partir de là, il suffit d'utiliser les méthodes numpy pour calculer quelque chose :
Utilisation totale des mots chaque année
Google affiche le pourcentage d'occurrences de chaque mot (le nombre de fois qu'un certain mot est apparu au cours de cette année fois/total nombre d'occurrences de tous les mots dans l'année), ce qui est plus utile que de simplement compter les mots originaux. Pour calculer ce pourcentage, nous devons connaître le nombre total de mots.
Heureusement, numpy rend cela très simple :
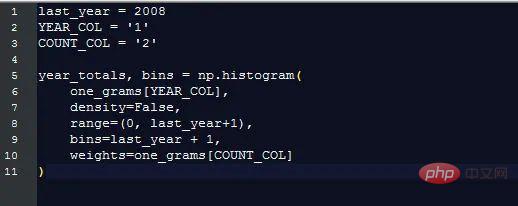
Tracé ce graphique pour montrer combien de mots Google collectait chaque année :
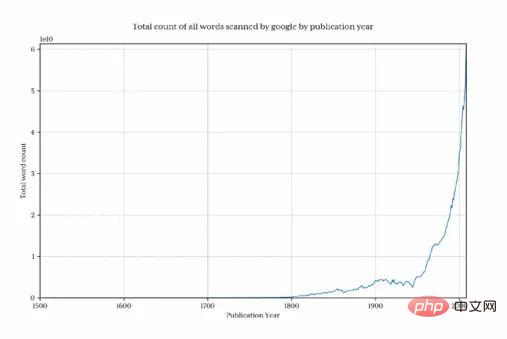
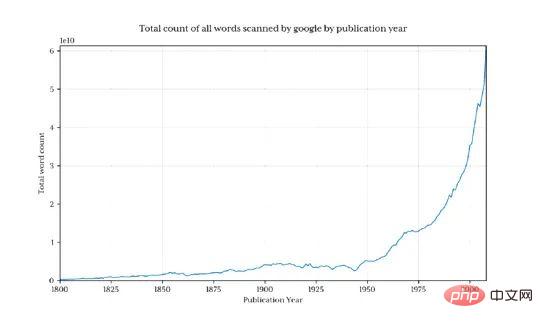
Il est clair qu'avant 1800, la quantité totale de données diminuait très rapidement, déformant ainsi le résultat final et cacher les modèles d’intérêt. Pour éviter ce problème, nous importons uniquement les données après 1800 :
Cela renvoie 1,3 milliard de lignes de données (seulement 3,7% des données avant 1800)
Pourcentage de Python chaque année
Obtenir le pourcentage de python chaque année est désormais particulièrement simple.
Utilisez une astuce simple pour créer un tableau basé sur l'année. La longueur de l'élément 2008 signifie que l'indice de chaque année est égal au numéro de l'année. Ainsi, par exemple, 1995 consiste simplement à obtenir l'élément de. 1995.
Cela ne vaut pas la peine d'utiliser numpy pour fonctionner :

Le résultat du traçage du nombre de mots :

La forme est presque la même que celle de la version de Google
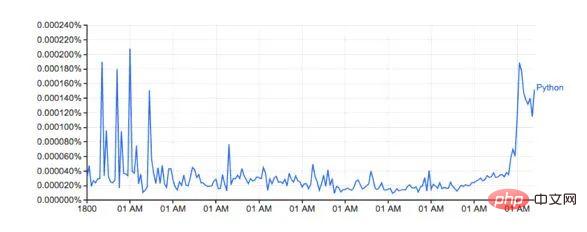
Les pourcentages réels ne correspondent pas, je Je pense que c'est parce que l'ensemble de données téléchargé contient des mots différents (par exemple : Python_VERB). Cet ensemble de données n'est pas très bien expliqué dans la page google et soulève plusieurs questions :
Comment utilise-t-on Python comme verbe ?
Le montant total du calcul de « Python » inclut-il « Python_VERB » ? Attendez
Heureusement, nous savons tous que la méthode que j'ai utilisée génère une icône qui ressemble beaucoup à Google, et les tendances associées ne sont pas affectées, donc pour cette exploration, je ne vais pas essayer de la réparer.
Performance
Google génère des images en 1 seconde environ, ce qui est raisonnable comparé aux 8 minutes pour ce script. Le backend de comptage de mots de Google fonctionne à partir d'une vue explicite de l'ensemble de données préparé.
Par exemple, calculer à l'avance l'utilisation totale des mots pour l'année précédente et la stocker dans une table de recherche distincte permettra de gagner beaucoup de temps. De même, conserver l'utilisation des mots dans une base de données/un fichier séparé, puis indexer la première colonne éliminera presque tout le temps de traitement.
Cette exploration montre vraiment qu'il est possible de charger, traiter et extraire des statistiques arbitraires à partir d'un ensemble de données d'un milliard de lignes dans un délai raisonnable en utilisant numpy et les tout nouveaux pytubes avec du matériel standard et Python,
Language Wars
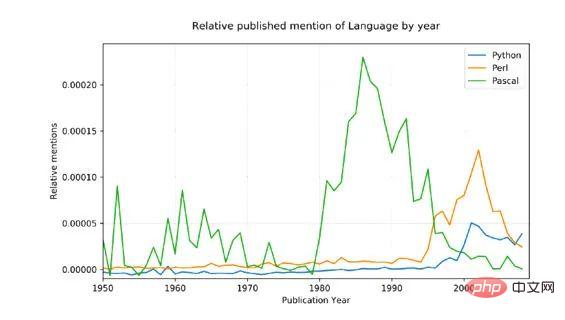
Pour le démontrer concept avec un exemple un peu plus complexe, j'ai décidé de comparer trois langages de programmation mentionnés de manière pertinente : Python, Pascal et Perl
Les données sources sont bruitées (elles incluent toutes les utilisations. Les mots anglais qui ont été utilisés ne sont pas seulement mentionnés dans la programmation. langages, mais aussi, par exemple, python a des significations non techniques ! ), afin d'ajuster à cet égard, nous avons fait deux choses :
Seule la première lettre du nom peut être mise en correspondance (Python, pas. python)
Le nombre total de mentions pour chaque langue a été converti en un pourcentage moyen de 1800 à 1960, ce qui devrait avoir une base raisonnable étant donné que Pascal a été mentionné pour la première fois en 1970.
Résultats :
Par rapport à Google (sans aucun ajustement de base) :
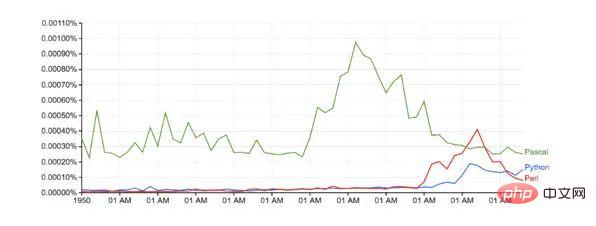
Durée d'exécution : un peu plus de 10 minutes
Futures améliorations de PyTubes
À ce stade, pytubes n'a que le concept d'un seul entier, soit 64 bits. Cela signifie que les tableaux numpy générés par pytubes utilisent des types i8 pour tous les entiers. À certains endroits (comme les données ngrams), les entiers 8 bits sont un peu excessifs et gaspillent de la mémoire (le ndarray total est de 38 Go, les dtypes peuvent facilement réduire cela de 60 %). Je prévois d'ajouter une prise en charge des entiers de niveau 1, 2 et 4 bits ( github.com/stestagg/py… )
Plus de logique de filtrage - Tube.skip_unless() est un moyen relativement simple de filtrer les lignes, mais il lui manque la capacité de combiner conditions (ET/OU/NON). Cela peut réduire plus rapidement la taille des données chargées dans certains cas d’utilisation.
Meilleure correspondance de chaînes - des tests simples tels que : commence avec, se termine avec, contient et is_one_of peuvent être facilement ajoutés pour améliorer considérablement l'efficacité du chargement des données de chaîne.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
