
 Périphériques technologiques
IA
Les systèmes d'apprentissage automatique modulaires sont-ils suffisants ? Les professeurs et les étudiants de Bengio vous donnent la réponse
Périphériques technologiques
IA
Les systèmes d'apprentissage automatique modulaires sont-ils suffisants ? Les professeurs et les étudiants de Bengio vous donnent la réponse
Les systèmes d'apprentissage automatique modulaires sont-ils suffisants ? Les professeurs et les étudiants de Bengio vous donnent la réponse

Les chercheurs en apprentissage profond s'inspirent des neurosciences et des sciences cognitives. Depuis les unités cachées et les méthodes de saisie jusqu'à la conception de connexions et d'architectures de réseau, de nombreuses études révolutionnaires sont basées sur l'imitation de stratégies de fonctionnement du cerveau. Il ne fait aucun doute que la modularité et l’attention ont été fréquemment utilisées en combinaison dans les réseaux artificiels ces dernières années et ont donné des résultats impressionnants.
En fait, la recherche en neurosciences cognitives montre que le cortex cérébral représente la connaissance de manière modulaire, communique entre différents modules et que le mécanisme d'attention effectue la sélection du contenu. C'est la modularité et l'attention mentionnées ci-dessus. Dans des recherches récentes, il a été suggéré que ce mode de communication dans le cerveau pourrait avoir des implications en matière de biais inductifs dans les réseaux profonds. La rareté des dépendances entre ces variables de haut niveau décompose les connaissances en fragments recombinables aussi indépendants que possible, rendant l’apprentissage plus efficace.
Bien que de nombreuses recherches récentes reposent sur de telles architectures modulaires, les chercheurs utilisent un grand nombre d'astuces et de modifications architecturales, ce qui rend difficile l'analyse de principes architecturaux réels et utilisables.
Les systèmes d'apprentissage automatique montrent progressivement les avantages des architectures plus clairsemées et plus modulaires. Les architectures modulaires ont non seulement de bonnes performances de généralisation, mais apportent également de meilleures performances et évolutivité hors distribution (OoD). interprétabilité. L’une des clés du succès de tels systèmes réside dans le fait que les systèmes de génération de données utilisés dans des contextes réels sont considérés comme constitués de parties peu interagissantes, et il serait utile de donner au modèle un biais inductif similaire. Cependant, étant donné que la distribution de ces données du monde réel est complexe et inconnue, le domaine manque d’évaluation quantitative rigoureuse de ces systèmes.
Un article rédigé par trois chercheurs de l'Université de Montréal au Canada : Sarthak Mittal, Yoshua Bengio et Guillaume Lajoie. Ils ont mené une évaluation complète des architectures modulaires courantes grâce à une distribution de données modulaire simple et connue. L'étude met en évidence les avantages de la modularité et de la parcimonie et révèle un aperçu des défis rencontrés lors de l'optimisation des systèmes modulaires. Le premier auteur et auteur correspondant, Sarthak Mittal, est un élève en master de Bengio et Lajoie.

- Adresse papier : https://arxiv.org/pdf/2206.02713.pdf
- Adresse GitHub : https://github.com/sarthmit/Mod_Arch
Plus précisément, ceci L'étude étend l'analyse de Rosenbaum et al. et propose une méthode pour évaluer, quantifier et analyser les composants communs des architectures modulaires. À cette fin, la recherche a développé une série de références et de mesures conçues pour explorer l’efficacité des réseaux modulaires. Cela révèle des informations précieuses qui aident à identifier non seulement où les approches actuelles réussissent, mais également quand et comment ces approches échouent.
La contribution de cette recherche peut être résumée comme suit :
- Cette recherche développe des tâches et des métriques de référence basées sur des règles de sélection probabilistes, et utilise des références et des métriques pour quantifier deux phénomènes importants dans les systèmes modulaires : l'effondrement et la spécialisation.
- Cette étude extrait les biais inductifs modulaires couramment utilisés et les évalue systématiquement à travers une série de modèles conçus pour extraire les propriétés architecturales couramment utilisées (modèles monolithiques, modulaires, modulaires-op, GT-Modulaires).
- L'étude a révélé que la spécialisation dans les systèmes modulaires peut améliorer considérablement les performances du modèle lorsqu'il existe de nombreuses règles latentes dans une tâche, mais pas lorsqu'il n'y en a que quelques-unes.
- L'étude a révélé que les systèmes modulaires standards ont tendance à être sous-optimaux, à la fois dans leur capacité à se concentrer sur les bonnes informations et dans leur capacité à se spécialiser, ce qui suggère la nécessité d'un biais inductif supplémentaire.
Définition / Terminologie
Dans cet article, nous explorons comment une série de systèmes modulaires effectuent des tâches communes formulées par un processus de génération de données synthétiques que nous appelons données de règles. Ils présentent la définition des composants clés, notamment (1) les règles et la manière dont ces règles forment des tâches, (2) les modules et la manière dont ces modules adoptent différentes architectures de modèles, (3) la spécialisation et la manière dont les modèles sont évalués. Les paramètres détaillés sont présentés dans la figure 1 ci-dessous.

Règles. Afin de bien comprendre les systèmes modulaires et d'analyser leurs avantages et leurs inconvénients, les chercheurs ont envisagé une configuration complète permettant un contrôle précis des différentes exigences des tâches. En particulier, les opérations, qu'ils appellent règles, doivent être apprises sur les distributions génératrices de données présentées dans l'équation 1-3 ci-dessous.

Étant donné la distribution ci-dessus, le chercheur définit une règle pour devenir son expert, c'est-à-dire que la règle r est définie comme p_y(·|x, c = r), où c est la classification représentant la variable de contexte, x est la séquence d'entrée.
Mission. Une tâche est décrite par un ensemble de règles (distributions génératrices de données) présentées dans l'équation 1-3. Différents ensembles de {p_y(· | x, c)}_c signifient différentes tâches. Pour un nombre donné de règles, le modèle est entraîné sur plusieurs tâches afin d'éliminer tout biais spécifique à la tâche.
module. Un système modulaire se compose d'un ensemble de modules de réseau neuronal, où chaque module contribue au résultat global. Cela peut être vu à travers la forme fonctionnelle suivante.

où y_m représente la sortie et p_m représente l'activation du m^ième module.
Architecture modèle. L'architecture modèle décrit quelle architecture est choisie pour chaque module d'un système modulaire ou pour les modules individuels d'un système monolithique. Dans cet article, les chercheurs envisagent d’utiliser le perceptron multicouche (MLP), l’attention multi-têtes (MHA) et le réseau neuronal récurrent (RNN). Il est important que les règles (ou distributions génératrices de données) soient adaptées à l'architecture du modèle, comme les règles basées sur MLP.
Processus de génération de données
Étant donné que les chercheurs visent à explorer les systèmes modulaires à l'aide de données synthétiques, ils détaillent le processus de génération de données basé sur le schéma de règles décrit ci-dessus. Plus précisément, les chercheurs ont utilisé un simple processus de génération de données de type mixte d'experts (MoE), dans l'espoir que différents modules pourraient être spécialisés pour différents experts en règles.
Ils expliquent le processus de génération de données pour trois architectures de modèles, qui sont MLP, MHA et RNN. De plus, il existe deux versions sous chaque tâche : régression et classification.
MLP. Les chercheurs ont défini un schéma de données adapté à l'apprentissage basé sur des systèmes MLP modulaires. Dans ce schéma de génération de données synthétiques, un échantillon de données se compose de deux nombres indépendants et d'une sélection régulière échantillonnée à partir d'une certaine distribution. Différentes règles génèrent différentes combinaisons linéaires de deux nombres pour donner un résultat, c'est-à-dire que la sélection de la combinaison linéaire est instanciée dynamiquement selon les règles, comme le montre l'équation 4-6 ci-dessous.
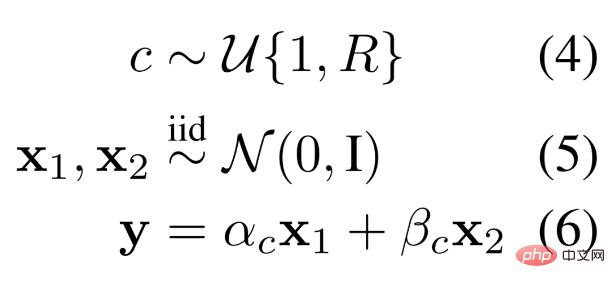

MHA. Aujourd’hui, les chercheurs ont défini un schéma de données adapté à l’apprentissage dans un système MHA modulaire. Par conséquent, ils ont conçu une distribution de génération de données avec la propriété suivante : chaque règle se compose de différents concepts de recherche, de récupération et de la combinaison linéaire finale des informations récupérées. Les chercheurs décrivent mathématiquement ce processus dans l’équation 7-11 ci-dessous.

RNN. Pour les systèmes circulatoires, les chercheurs ont défini des règles pour un système dynamique linéaire dans lequel l'une des multiples règles peut être déclenchée à tout moment. Mathématiquement, ce processus est illustré dans l'équation 12-15 ci-dessous.

Modèle
Certains travaux antérieurs affirmaient que les systèmes de modules formés de bout en bout sont supérieurs aux systèmes monolithiques, en particulier dans les environnements distribués. Cependant, il n'y a pas eu d'analyse détaillée et approfondie des avantages de ces systèmes modulaires ni de leur spécialisation réelle en fonction de la distribution de la génération de données.
Par conséquent, les chercheurs ont considéré quatre types de modèles qui permettent différents degrés de spécialisation, à savoir Monolithique (unique), Modulaire (modulaire), Modulaire-op et GT-Modulaire. Le tableau 1 ci-dessous illustre ces modèles.

Monolithique. Un système monolithique est un grand réseau de neurones qui prend en entrée tout un ensemble de données (x, c) et fait une prédiction y^ sur cette base. Il n'y a aucun biais inductif en faveur de la modularité ou de la rareté de l'explicite intégré au système, et il repose entièrement sur la rétropropagation pour apprendre la forme fonctionnelle requise pour résoudre la tâche.
Modulaire. Un système modulaire se compose de nombreux modules, chacun étant un réseau neuronal d'un type d'architecture donné (MLP, MHA ou RNN). Chaque module m prend les données (x, c) en entrée et calcule une sortie yˆ_m et un score de confiance, normalisé entre les modules à la probabilité d'activation p_m.
Opération modulaire. Un système d'exploitation modulaire est très similaire à un système modulaire, avec une différence. Au lieu de définir la probabilité d'activation p_m du module m en fonction de (x, c), les chercheurs ont veillé à ce que l'activation soit déterminée uniquement par le contexte de règle C.
GT-Modulaire. Les systèmes modulaires à valeur réelle servent de références oracle, c'est-à-dire des systèmes modulaires parfaitement spécialisés.
Les chercheurs montrent que du monolithique au GT-Modulaire, les modèles incluent de plus en plus de biais inductifs pour la modularité et la parcimonie.
Metrics
Pour évaluer de manière fiable les systèmes modulaires, les chercheurs ont proposé une série de mesures qui non seulement mesurent les avantages en termes de performances de tels systèmes, mais les évaluent également sous deux formes importantes : l'effondrement et la spécialisation.
Performances. Le premier ensemble de mesures d'évaluation est basé sur les performances dans les contextes de distribution et hors distribution (OoD), reflétant les performances de différents modèles sur diverses tâches. Pour le paramètre de classification, nous rapportons l'erreur de classification ; pour le paramètre de régression, nous rapportons la perte.
Crash. Les chercheurs ont proposé un ensemble de mesures, Collapse-Avg et Collapse-Worst, pour quantifier le degré d'effondrement rencontré par un système modulaire (c'est-à-dire le degré de sous-utilisation des modules). La figure 2 ci-dessous montre un exemple où vous pouvez voir que le module 3 n'est pas utilisé.
Professionnalisation. Pour compléter les métriques d'effondrement, nous proposons également l'ensemble de métriques suivant, à savoir (1) l'alignement, (2) l'adaptation et (3) l'information mutuelle inverse qui quantifie le degré de spécialisation atteint par un système modulaire.
Expériences
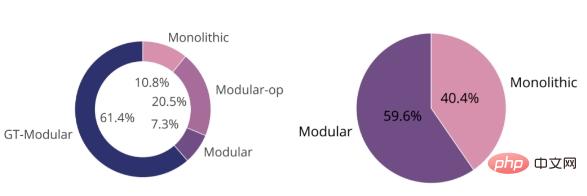
La figure ci-dessous montre que le système GT-Modular est optimal dans la plupart des cas (à gauche), ce qui montre que la spécialisation est bénéfique. Nous constatons également qu'entre le système modulaire standard formé de bout en bout et le système monolithique, le premier surpasse le second, mais pas de beaucoup. Ensemble, ces deux diagrammes circulaires démontrent que les systèmes modulaires actuels pour une formation de bout en bout ne permettent pas une bonne spécialisation et sont donc largement sous-optimaux.

L'étude examine ensuite des choix d'architecture spécifiques et analyse leurs performances et leurs tendances à travers un nombre croissant de règles.

La figure 4 montre que même si un système parfaitement spécialisé (GT-Modular) apporterait des avantages, un système modulaire typique pour une formation de bout en bout est sous-optimal et ne peut pas offrir ces avantages, d'autant plus que le nombre de règles augmente. De plus, même si ces systèmes modulaires de bout en bout surpassent souvent les systèmes monolithiques, l’avantage n’est généralement que minime.

Dans la figure 7, nous voyons également la moyenne des modes d'entraînement pour différents modèles sur tous les autres paramètres, la moyenne inclut l'erreur de classification et la perte de régression. Comme on peut le constater, une bonne spécialisation conduit non seulement à de meilleures performances, mais accélère également la formation.

La figure suivante montre deux mesures d'effondrement : Collapse-Avg et Collapse-Worst. De plus, la figure ci-dessous montre également trois indicateurs de spécialisation, d'alignement, d'adaptation et d'information mutuelle inverse pour différents modèles avec différents nombres de règles :

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le 29 juillet, lors de la cérémonie de lancement de la 400 000e nouvelle voiture d'AITO Wenjie, Yu Chengdong, directeur général de Huawei, président de Terminal BG et président de la BU Smart Car Solutions, a assisté et prononcé un discours et a annoncé que les modèles de la série Wenjie seraient sera lancé cette année En août, la version Huawei Qiankun ADS 3.0 a été lancée et il est prévu de pousser successivement les mises à niveau d'août à septembre. Le Xiangjie S9, qui sortira le 6 août, lancera le système de conduite intelligent ADS3.0 de Huawei. Avec l'aide du lidar, la version Huawei Qiankun ADS3.0 améliorera considérablement ses capacités de conduite intelligente, disposera de capacités intégrées de bout en bout et adoptera une nouvelle architecture de bout en bout de GOD (identification générale des obstacles)/PDP (prédictive prise de décision et contrôle), fournissant la fonction NCA de conduite intelligente d'une place de stationnement à l'autre et mettant à niveau CAS3.0
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Toujours nouveau ! Mises à niveau de la série Huawei Mate60 vers HarmonyOS 4.2 : amélioration du cloud AI, le dialecte Xiaoyi est si facile à utiliser
Jun 02, 2024 pm 02:58 PM
Toujours nouveau ! Mises à niveau de la série Huawei Mate60 vers HarmonyOS 4.2 : amélioration du cloud AI, le dialecte Xiaoyi est si facile à utiliser
Jun 02, 2024 pm 02:58 PM
Le 11 avril, Huawei a officiellement annoncé pour la première fois le plan de mise à niveau de 100 machines HarmonyOS 4.2. Cette fois, plus de 180 appareils participeront à la mise à niveau, couvrant les téléphones mobiles, les tablettes, les montres, les écouteurs, les écrans intelligents et d'autres appareils. Au cours du mois dernier, avec la progression constante du plan de mise à niveau de 100 machines HarmonyOS4.2, de nombreux modèles populaires, notamment Huawei Pocket2, la série Huawei MateX5, la série nova12, la série Huawei Pura, etc., ont également commencé à être mis à niveau et à s'adapter, ce qui signifie qu'il y aura davantage d'utilisateurs de modèles Huawei pourront profiter de l'expérience commune et souvent nouvelle apportée par HarmonyOS. À en juger par les commentaires des utilisateurs, l'expérience des modèles de la série Huawei Mate60 s'est améliorée à tous égards après la mise à niveau d'HarmonyOS4.2. Surtout Huawei M
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
