


Certains supports d'apprentissage PDF téléchargés en ligne comporteront des filigranes, ce qui affectera grandement la lecture. Par exemple, l'image ci-dessous a été découpée dans un fichier pdf. Aujourd'hui, nous allons utiliser Python pour résoudre ce problème.

PIL : Python Imaging Library est une bibliothèque standard de traitement d'image très puissante en python, mais elle ne peut prendre en charge que python 2.7, donc certains volontaires ont créé un oreiller qui prend en charge python 3 basé sur PIL et ajouté. quelques nouvelles fonctionnalités.
pip install pillow
pymupdf peut utiliser Python pour accéder aux fichiers avec les extensions *.pdf, .xps, .oxps, .epub, .cbz ou *.fb2. De nombreux formats d'image populaires sont également pris en charge, notamment les images TIFF multipages.
pip install PyMuPDF
Importez les modules requis
from PIL import Image from itertools import product import fitz import os
pdf Le principe de suppression du filigrane est similaire à celui de la suppression du filigrane d'une image. L'éditeur commencera par supprimer le filigrane de l'image ci-dessus.
Les amis qui ont étudié les ordinateurs savent tous que RVB est utilisé pour représenter le rouge, le vert et le bleu dans les ordinateurs, (255, 0, 0) est utilisé pour représenter le rouge, (0, 255, 0) est utilisé pour représenter le vert et (0, 0, 255) est utilisé pour représenter le bleu, (255, 255, 255) représente le blanc, (0, 0, 0) représente le noir. Le principe de la suppression du filigrane est de changer la couleur du filigrane en blanc (255). , 255, 255).
Obtenez d'abord la largeur et la hauteur de l'image, puis utilisez le module itertools pour obtenir le produit cartésien de la largeur et de la hauteur en pixels. La couleur de chaque pixel est composée des trois premiers bits du canal RVB et du quatrième bit du canal Alpha. Le canal Alpha n'est pas requis, uniquement les données RVB.
def remove_img():
image_file = input("请输入图片地址:")
img = Image.open(image_file)
width, height = img.size
for pos in product(range(width), range(height)):
rgb = img.getpixel(pos)[:3]
print(rgb)
Utilisez la capture d'écran WeChat pour vérifier le RVB des pixels du filigrane.
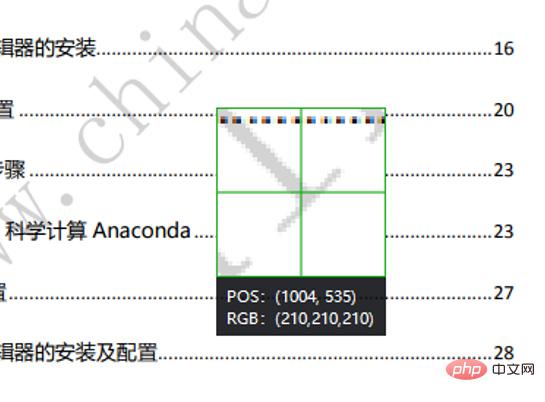
Vous pouvez voir que le RVB du filigrane est (210, 210, 210). Ici, si la somme du RVB dépasse 620, il est déterminé qu'il s'agit d'un point de filigrane. À ce stade, la couleur du pixel est. remplacé par du blanc. Enfin, enregistrez l'image.
rgb = img.getpixel(pos)[:3]
if(sum(rgb) >= 620):
img.putpixel(pos, (255, 255, 255))
img.save('d:/qsy.png')
Exemples de résultats :

PDF Le principe de la suppression du filigrane est à peu près le même que celui de la suppression du filigrane d'une image. Après avoir ouvert le fichier pdf avec PyMuPDF, chaque page du pdf est convertie en. une image pixmap, pixmap Il a son propre RVB, il suffit de changer le RVB dans le filigrane pdf en (255, 255, 255) et enfin de l'enregistrer en tant qu'image.
def remove_pdf():
page_num = 0
pdf_file = input("请输入 pdf 地址:")
pdf = fitz.open(pdf_file);
for page in pdf:
pixmap = page.get_pixmap()
for pos in product(range(pixmap.width), range(pixmap.height)):
rgb = pixmap.pixel(pos[0], pos[1])
if(sum(rgb) >= 620):
pixmap.set_pixel(pos[0], pos[1], (255, 255, 255))
pixmap.pil_save(f"d:/pdf_images/{page_num}.png")
print(f"第{page_num}水印去除完成")
page_num = page_num + 1
Exemples de résultats :
Convertir les images en pdf Ce qu'il faut noter, c'est que le tri des images doit d'abord être converti en type int, puis trié. Après avoir ouvert l'image avec le module PyMuPDF, utilisez la fonction convertToPDF() pour convertir l'image en un PDF d'une seule page. Insérer dans un nouveau fichier pdf.
def pic2pdf():
pic_dir = input("请输入图片文件夹路径:")
pdf = fitz.open()
img_files = sorted(os.listdir(pic_dir),key=lambda x:int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
pdf.insertPDF(imgpdf)
pdf.save("d:/demo.pdf")
pdf.close()
Les filigranes gênants sur les PDF et les images peuvent enfin disparaître devant le puissant python. En avez-vous assez appris, les gars ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



