
 Périphériques technologiques
IA
Un article discute brièvement de la capacité de généralisation du deep learning
Périphériques technologiques
IA
Un article discute brièvement de la capacité de généralisation du deep learning
Un article discute brièvement de la capacité de généralisation du deep learning


1. La question de la capacité de généralisation du DNN
L'article explique principalement pourquoi le modèle de réseau neuronal surparamétré peut avoir de bonnes performances de généralisation ? Autrement dit, il ne mémorise pas simplement l'ensemble de formation, mais résume une règle générale de l'ensemble de formation, afin qu'elle puisse être adaptée à l'ensemble de test (capacité de généralisation).

Prenons l'exemple du modèle d'arbre de décision classique. Lorsque le modèle d'arbre apprend les règles générales de l'ensemble de données : une bonne situation est que si l'arbre divise d'abord le nœud, il peut simplement bien distinguer les échantillons avec des étiquettes différentes. . , la profondeur est très faible et le nombre correspondant d'échantillons sur chaque feuille est suffisant (c'est-à-dire que la quantité de données basées sur des règles statistiques est également relativement importante), alors les règles obtenues sont plus susceptibles d'être généralisées à d'autres données. . (c'est-à-dire : bon ajustement et capacité de généralisation).
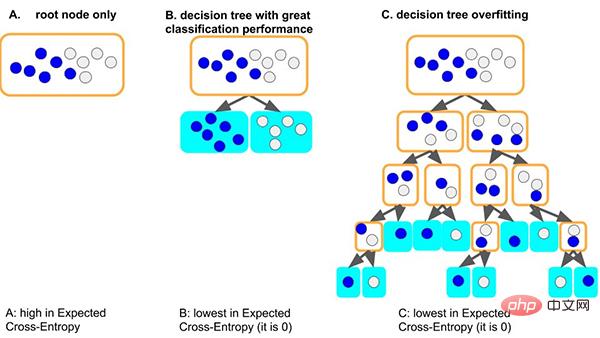
Une autre situation pire est que si l'arbre ne peut pas apprendre certaines règles générales, afin d'apprendre cet ensemble de données, l'arbre deviendra de plus en plus profond, et chaque nœud feuille peut correspondre à un petit nombre d'échantillons (moins le les informations statistiques apportées par les données peuvent n'être que du bruit), et enfin, mémoriser toutes les données par cœur (c'est-à-dire : surapprentissage et aucune capacité de généralisation). Nous pouvons voir que les modèles d’arbres trop profonds peuvent facilement être surajustés.
Alors, comment un réseau de neurones surparamétré peut-il parvenir à une bonne généralisation ?
2. Les raisons de la capacité de généralisation du DNN
Cet article explique d'un point de vue simple et général - en explorant les raisons de la capacité de généralisation dans le processus d'optimisation de la descente de gradient des réseaux de neurones :
Nous avons résumé la théorie de la cohérence du gradient : Les gradients des différents échantillons produisent de la cohérence, c'est pourquoi les réseaux de neurones peuvent avoir de bonnes capacités de généralisation. Lorsque les gradients des différents échantillons sont bien alignés pendant l’entraînement, c’est-à-dire lorsqu’ils sont cohérents, la descente de gradient est stable, peut converger rapidement et le modèle résultant peut bien se généraliser. Sinon, si les échantillons sont trop peu nombreux ou si le temps de formation est trop long, cela risque de ne pas se généraliser.

Sur la base de cette théorie, nous pouvons faire l'explication suivante.
2.1 Généralisation des réseaux de neurones de largeur
Les modèles de réseaux de neurones plus larges ont de bonnes capacités de généralisation. En effet, les réseaux plus larges comportent plus de sous-réseaux et sont plus susceptibles de produire une cohérence de gradient que les réseaux plus petits, ce qui entraîne une meilleure généralisation. En d’autres termes, la descente de gradient est un sélecteur de fonctionnalités qui donne la priorité aux gradients de généralisation (cohérence), et des réseaux plus larges peuvent avoir de meilleures fonctionnalités simplement parce qu’ils ont plus de fonctionnalités.
- Article original : Généralisation et largeur. Neyshabur et al. [2018b] ont découvert que les réseaux plus larges se généralisent mieux. Pouvons-nous maintenant expliquer cela de manière intuitive, les réseaux plus larges ont plus de sous-réseaux à un niveau donné, et donc le sous-réseau. avec une cohérence maximale dans un réseau plus large peut être plus cohérent que son homologue dans un réseau plus mince, et donc mieux généraliser. En d'autres termes, puisque - comme discuté dans la section 10 - la descente de gradient est un sélecteur de fonctionnalités qui donne la priorité à une bonne généralisation (cohérente). En termes de fonctionnalités, les réseaux plus larges sont susceptibles d'avoir de meilleures fonctionnalités simplement parce qu'ils ont plus de fonctionnalités. À cet égard, voir également l'hypothèse des billets de loterie [Frankle et Carbin, 2018]
- Lien papier : https://github.com/aialgorithm/Blog.
Mais personnellement, je pense qu'il faut encore distinguer la largeur de la couche d'entrée réseau/couche cachée. Surtout pour la couche d'entrée des tâches d'exploration de données, étant donné que les entités d'entrée sont généralement conçues manuellement, vous devez envisager la sélection des entités (c'est-à-dire réduire la largeur de la couche d'entrée, sinon l'entrée directe du bruit des entités interférera avec la cohérence du dégradé). .
2.2 Généralisation des réseaux de neurones profonds
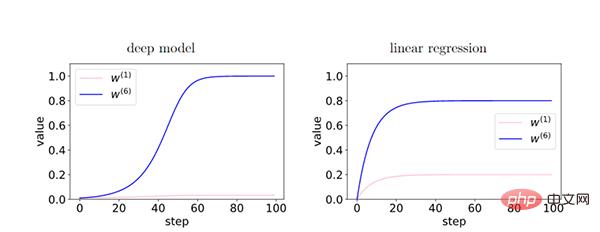
Plus le réseau est profond, le phénomène de cohérence du gradient est amplifié et a une meilleure capacité de généralisation.

Dans le modèle profond, puisque le feedback entre les couches renforce le gradient cohérent, il existe une différence relative entre les caractéristiques du gradient cohérent (W6) et les caractéristiques du gradient incohérent (W1) pendant le processus d'entraînement. De manière exponentielle amplifié. Cela amène les réseaux plus profonds à préférer les gradients cohérents, ce qui se traduit par de meilleures capacités de généralisation.
2.3 Arrêt anticipé
En arrêtant tôt, nous pouvons réduire l'influence excessive des gradients incohérents et améliorer la généralisation.
Pendant l'entraînement, certains échantillons faciles s'ajustent plus tôt que d'autres échantillons (échantillons durs). Au début de la formation, le gradient de corrélation de ces échantillons faciles domine et est facile à ajuster. Au stade ultérieur de la formation, le gradient incohérent des échantillons difficiles domine le gradient moyen g(wt), ce qui entraîne une faible capacité de généralisation. À ce stade, il est nécessaire de s'arrêter tôt.

- (Remarque : les échantillons simples sont ceux qui ont de nombreux gradients en commun dans l'ensemble de données. Pour cette raison, la plupart des gradients lui sont bénéfiques et convergent plus rapidement.)
2.4 Descente de gradient complet VS taux d'apprentissage
Nous avons constaté que la descente à gradient complet peut également avoir une bonne capacité de généralisation. En outre, des expériences minutieuses montrent que la descente de gradient stochastique ne conduit pas nécessairement à une meilleure généralisation, mais cela n'exclut pas la possibilité que les gradients stochastiques soient plus susceptibles de sortir des minima locaux, de jouer un rôle dans la régularisation, etc.
- Sur la base de notre théorie, le taux d'apprentissage fini et la stochasticité des mini-lots ne sont pas nécessaires pour la généralisation
Nous pensons qu'un taux d'apprentissage inférieur ne peut pas réduire l'erreur de généralisation, car un taux d'apprentissage inférieur signifie plus de nombre d'itérations (à l'opposé d'arrêt anticipé).
- En supposant un taux d'apprentissage suffisamment faible, à mesure que la formation progresse, l'écart de généralisation ne peut pas diminuer. Cela découle de l'analyse itérative de la stabilité de la formation : avec 40 étapes supplémentaires, la stabilité ne peut que se dégrader. indiquerait une limitation intéressante de la théorie
2.5 Régularisation L2 et L1
Ajoutez la régularisation L2 et L1 à la fonction objectif, et le calcul du gradient correspondant, le gradient qui doit être ajouté au terme de régularisation L1 est le signe ( w), et le gradient L2 est w. En prenant la régularisation L2 comme exemple, la formule de mise à jour du gradient W(i+1) correspondante est : Image
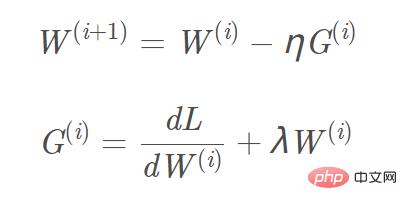
Nous pouvons considérer la « régularisation L2 (atténuation du poids) » comme une « force de fond », et chaque paramètre est poussé proche d'une valeur zéro indépendante des données (L1 est facile d'obtenir une solution clairsemée, et L2 est facile d'obtenir une solution lisse proche de 0) pour éliminer l'influence dans la direction du gradient faible. Ce n'est que dans le cas de directions de gradient cohérentes que les paramètres peuvent être relativement séparés de la « force de fond » et que la mise à jour du gradient peut être effectuée sur la base des données.

2.6 Avancement de l'algorithme de descente de gradient
- Momentum, Adam et autres algorithmes de descente de gradient
Momentum, Adam et autres algorithmes de descente de gradient, la direction de mise à jour du paramètre W est non seulement déterminée par le gradient actuel, mais également par le gradient précédemment accumulé. La direction du gradient est liée (c'est-à-dire que l'effet des gradients cohérents accumulés est préservé). Cela permet aux paramètres d'être mis à jour plus rapidement dans les dimensions où la direction du gradient change légèrement, et réduit l'amplitude de mise à jour dans les dimensions où la direction du gradient change de manière significative, ce qui a pour effet d'accélérer la convergence et de réduire l'oscillation.
- Supprimer la descente de gradient dans les directions de gradient faible
Nous pouvons supprimer les mises à jour de gradient dans les directions de gradient faible en optimisant l'algorithme de descente de gradient par lots, améliorant ainsi les capacités de généralisation. Par exemple, nous pouvons utiliser la descente de gradient winsorisée pour exclure les valeurs aberrantes du gradient, puis prendre la moyenne. Ou prenez la médiane du gradient au lieu de la moyenne pour réduire l'impact des valeurs aberrantes du gradient.

Résumé
Quelques mots à la fin de l'article Si vous êtes intéressé par la théorie de l'apprentissage profond, vous pouvez lire les recherches connexes mentionnées dans l'article.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
BERT est un modèle de langage d'apprentissage profond pré-entraîné proposé par Google en 2018. Le nom complet est BidirectionnelEncoderRepresentationsfromTransformers, qui est basé sur l'architecture Transformer et présente les caractéristiques d'un codage bidirectionnel. Par rapport aux modèles de codage unidirectionnels traditionnels, BERT peut prendre en compte les informations contextuelles en même temps lors du traitement du texte, de sorte qu'il fonctionne bien dans les tâches de traitement du langage naturel. Sa bidirectionnalité permet à BERT de mieux comprendre les relations sémantiques dans les phrases, améliorant ainsi la capacité expressive du modèle. Grâce à des méthodes de pré-formation et de réglage fin, BERT peut être utilisé pour diverses tâches de traitement du langage naturel, telles que l'analyse des sentiments, la dénomination
 YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
Les méthodes d'apprentissage profond d'aujourd'hui se concentrent sur la conception de la fonction objectif la plus appropriée afin que les résultats de prédiction du modèle soient les plus proches de la situation réelle. Dans le même temps, une architecture adaptée doit être conçue pour obtenir suffisamment d’informations pour la prédiction. Les méthodes existantes ignorent le fait que lorsque les données d’entrée subissent une extraction de caractéristiques couche par couche et une transformation spatiale, une grande quantité d’informations sera perdue. Cet article abordera des problèmes importants lors de la transmission de données via des réseaux profonds, à savoir les goulots d'étranglement de l'information et les fonctions réversibles. Sur cette base, le concept d'information de gradient programmable (PGI) est proposé pour faire face aux différents changements requis par les réseaux profonds pour atteindre des objectifs multiples. PGI peut fournir des informations d'entrée complètes pour la tâche cible afin de calculer la fonction objectif, obtenant ainsi des informations de gradient fiables pour mettre à jour les pondérations du réseau. De plus, un nouveau cadre de réseau léger est conçu
 Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
L'intégration d'espace latent (LatentSpaceEmbedding) est le processus de mappage de données de grande dimension vers un espace de faible dimension. Dans le domaine de l'apprentissage automatique et de l'apprentissage profond, l'intégration d'espace latent est généralement un modèle de réseau neuronal qui mappe les données d'entrée de grande dimension dans un ensemble de représentations vectorielles de basse dimension. Cet ensemble de vecteurs est souvent appelé « vecteurs latents » ou « latents ». encodages". Le but de l’intégration de l’espace latent est de capturer les caractéristiques importantes des données et de les représenter sous une forme plus concise et compréhensible. Grâce à l'intégration de l'espace latent, nous pouvons effectuer des opérations telles que la visualisation, la classification et le regroupement de données dans un espace de faible dimension pour mieux comprendre et utiliser les données. L'intégration d'espace latent a de nombreuses applications dans de nombreux domaines, tels que la génération d'images, l'extraction de caractéristiques, la réduction de dimensionnalité, etc. L'intégration de l'espace latent est le principal
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
