
 développement back-end
Tutoriel Python
Écrivez un programme Python pour explorer les flux de fonds des secteurs
développement back-end
Tutoriel Python
Écrivez un programme Python pour explorer les flux de fonds des secteurs
Écrivez un programme Python pour explorer les flux de fonds des secteurs


Grâce à l'exemple ci-dessus d'exploration du flux de capitaux d'actions individuelles, vous devriez pouvoir apprendre à écrire votre propre code d'exploration. Maintenant, consolidez-le et faites un petit exercice similaire. Vous devez écrire votre propre programme Python pour analyser les flux de capitaux des secteurs en ligne. L'URL analysée est http://data.eastmoney.com/bkzj/hy.html et l'interface d'affichage est illustrée dans la figure 1.金 Figure 1 L'interface du site Web de flux de fonds
1, recherchez JS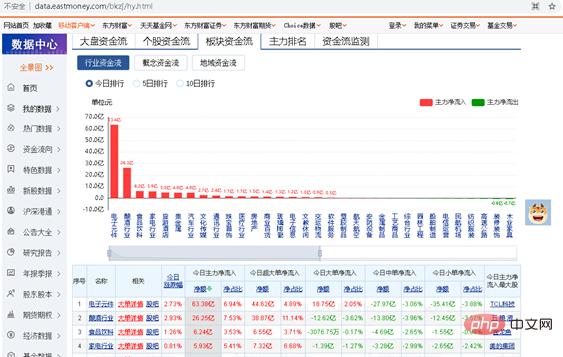
Figure 2 Recherchez la page web correspondant à JS
Saisissez ensuite l'URL dans le navigateur, l'URL est relativement longue. 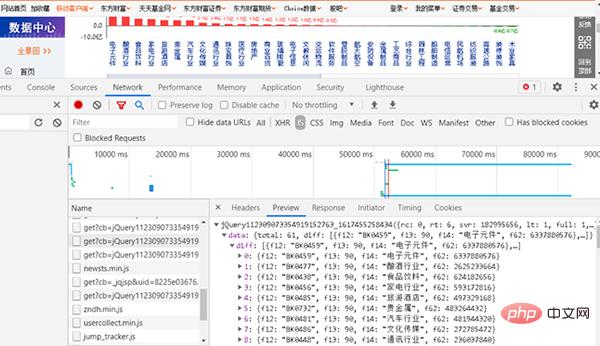
Figure 3 Obtention des sections et des flux de fonds à partir du site Web
Le contenu correspondant à cette URL est le contenu que nous souhaitons explorer. 
# coding=utf-8 import requests url=" http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_ 1617455258436&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3 e90d46a5&fs=m%3A90+t%3A2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2 Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124" r = requests.get(url)
Statut de réponse de la figure 4
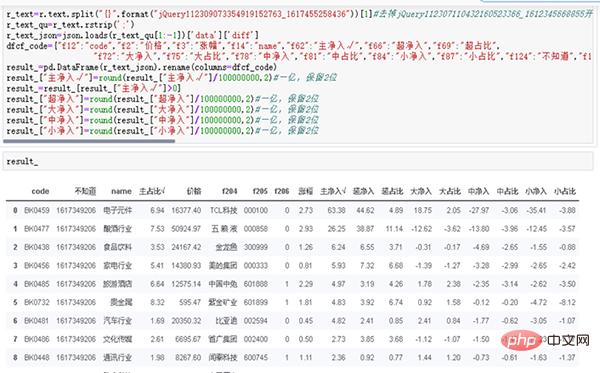
3, nettoyez str au format standard JSON 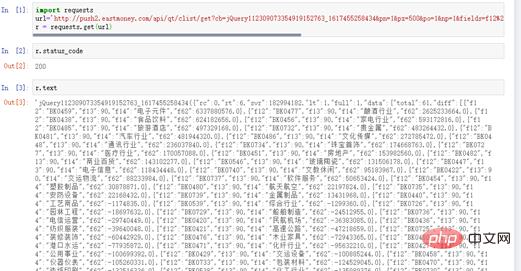
r_text=r.text.split("{}".format("jQuery112309073354919152763_1617455258436"))[1]
r_textr_text_qu=r_text.rstrip(';')
r_text_json=json.loads(r_text_qu[1:-1])['data']['diff']
dfcf_code={"f12":"code","f2":"价格","f3":"涨幅","f14":"name","f62":"主净入√","f66":"超净入","f69":"超占比", "f72":"大净入","f75":"大占比","f78":"中净入","f81":"中占比","f84":"小净入","f87":"小占比","f124":"不知道","f184":"主占比√"}
result_=pd.DataFrame(r_text_json).rename(columns=dfcf_code)
result_["主净入√"]=round(result_["主净入√"]/100000000,2)#一亿,保留2位
result_=result_[result_["主净入√"]>0]
result_["超净入"]=round(result_["超净入"]/100000000,2)#一亿,保留2位
result_["大净入"]=round(result_["大净入"]/100000000,2)#一亿,保留2位
result_["中净入"]=round(result_["中净入"]/100000000,2)#一亿,保留2位
result_["小净入"]=round(result_["小净入"]/100000000,2)#一亿,保留2位
result_
 (3) Utilisez des robots d'exploration pour obtenir des données et les enregistrer.
(3) Utilisez des robots d'exploration pour obtenir des données et les enregistrer.
Grâce à l'analyse de cas et au combat réel, nous devons apprendre à écrire notre propre code pour explorer les données financières et avoir la capacité de les convertir au format standard JSON. Effectuer le travail quotidien d'exploration et de stockage des données pour fournir un support de données efficace pour les futurs tests historiques et l'analyse historique des données.
Bien entendu, les lecteurs avertis peuvent sauvegarder les résultats dans des bases de données telles que MySQL, MongoDB ou même la base de données cloud Mongo Atlas. L'auteur ne se concentrera pas sur l'explication ici. Nous nous concentrons entièrement sur l’étude de l’apprentissage quantitatif et de la stratégie. L'utilisation du format txt pour enregistrer les données peut résoudre complètement le problème du stockage précoce des données, et les données sont également complètes et efficaces.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
De nombreux développeurs de sites Web sont confrontés au problème de l'intégration de Node.js ou des services Python sous l'architecture de lampe: la lampe existante (Linux Apache MySQL PHP) a besoin d'un site Web ...
 Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Solution aux problèmes d'autorisation Lors de la visualisation de la version Python dans Linux Terminal Lorsque vous essayez d'afficher la version Python dans Linux Terminal, entrez Python ...
 Quelle est la raison pour laquelle les fichiers de stockage persistants de pipeline ne peuvent pas être écrits lors de l'utilisation du robot Scapy?
Apr 01, 2025 pm 04:03 PM
Quelle est la raison pour laquelle les fichiers de stockage persistants de pipeline ne peuvent pas être écrits lors de l'utilisation du robot Scapy?
Apr 01, 2025 pm 04:03 PM
Lorsque vous utilisez Scapy Crawler, la raison pour laquelle les fichiers de stockage persistants ne peuvent pas être écrits? Discussion Lorsque vous apprenez à utiliser Scapy Crawler pour les robots de données, vous rencontrez souvent un ...
 Quelle est la raison pour laquelle le pool de processus Python gère les demandes TCP simultanées et fait coincé le client?
Apr 01, 2025 pm 04:09 PM
Quelle est la raison pour laquelle le pool de processus Python gère les demandes TCP simultanées et fait coincé le client?
Apr 01, 2025 pm 04:09 PM
Python Process Pool gère les demandes TCP simultanées qui font coincé le client. Lorsque vous utilisez Python pour la programmation réseau, il est crucial de gérer efficacement les demandes TCP simultanées. ...
 Comment afficher les fonctions originales encapsulées en interne par Python Functools.Partial Objet?
Apr 01, 2025 pm 04:15 PM
Comment afficher les fonctions originales encapsulées en interne par Python Functools.Partial Objet?
Apr 01, 2025 pm 04:15 PM
Explorez profondément la méthode de visualisation de Python Functools.Partial Objet dans Functools.Partial en utilisant Python ...
 Python multiplateform de bureau de bureau de bureau: quelle bibliothèque GUI est la meilleure pour vous?
Apr 01, 2025 pm 05:24 PM
Python multiplateform de bureau de bureau de bureau: quelle bibliothèque GUI est la meilleure pour vous?
Apr 01, 2025 pm 05:24 PM
Choix de la bibliothèque de développement d'applications de bureau multiplateforme Python De nombreux développeurs Python souhaitent développer des applications de bureau pouvant s'exécuter sur Windows et Linux Systems ...
 Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Précision avec Python: Source de sablier Dessin graphique et vérification d'entrée Cet article résoudra le problème de définition variable rencontré par un novice Python dans le programme de dessin graphique de sablier. Code...
 Google et AWS fournissent-ils des sources publiques d'image PYPI?
Apr 01, 2025 pm 05:15 PM
Google et AWS fournissent-ils des sources publiques d'image PYPI?
Apr 01, 2025 pm 05:15 PM
De nombreux développeurs s'appuient sur PYPI (PythonPackageIndex) ...
