

L'objectif de XAI est de fournir des explications significatives sur le comportement et les décisions du modèle. Cet article a compilé 10 bibliothèques Python pour l'IA explicable qui peuvent être vues jusqu'à présent
XAI, Explainable AI fait référence à un système ou à une stratégie qui peut fournir des explications claires et compréhensibles pour les processus décisionnels et les prédictions de l'intelligence artificielle (IA). L'objectif de XAI est de fournir des explications significatives sur leurs actions et décisions, ce qui contribue à accroître la confiance, à assurer la responsabilité et la transparence dans les décisions modèles. XAI ne se limite pas à l'interprétation, mais mène également des expériences de ML de manière à rendre les inférences plus faciles à extraire et à interpréter pour les utilisateurs.
En pratique, XAI peut être obtenu grâce à diverses méthodes, telles que l'utilisation de mesures d'importance des caractéristiques, de techniques de visualisation ou en créant des modèles intrinsèquement interprétables, tels que des arbres de décision ou des modèles de régression linéaire. Le choix de la méthode dépend du type de problème à résoudre et du niveau d’interprétabilité requis.
Les systèmes d’IA sont utilisés dans un nombre croissant d’applications, notamment dans les soins de santé, la finance et la justice pénale, où l’impact potentiel de l’IA sur la vie des gens est important et où il est essentiel de comprendre pourquoi une décision a été prise. Parce que le coût des mauvaises décisions dans ces domaines est élevé (les enjeux sont élevés), XAI devient de plus en plus important, car même les décisions prises par l'IA doivent être soigneusement vérifiées pour en vérifier la validité et l'explicabilité.

Préparation des données : Cette étape comprend la collecte et le traitement des données. Les données doivent être de haute qualité, équilibrées et représentatives du problème réel à résoudre. Disposer de données équilibrées, représentatives et propres réduit les efforts futurs visant à maintenir l’IA explicable.
Formation du modèle : le modèle est formé sur des données préparées, soit un modèle d'apprentissage automatique traditionnel, soit un réseau neuronal d'apprentissage profond. Le choix du modèle dépend du problème à résoudre et du niveau d’interprétabilité requis. Plus le modèle est simple, plus il est facile d’interpréter les résultats, mais les performances des modèles simples ne seront pas très élevées.
Évaluation du modèle : le choix de méthodes d'évaluation et de mesures de performance appropriées est nécessaire pour maintenir l'interprétabilité du modèle. Il est également important d’évaluer l’interprétabilité du modèle à ce stade pour s’assurer qu’il peut fournir des explications significatives pour ses prédictions.
Génération d'explications : cela peut être fait en utilisant diverses techniques telles que les mesures d'importance des caractéristiques, les techniques de visualisation ou en créant des modèles intrinsèquement explicables.
Vérification des explications : Vérifiez l'exactitude et l'exhaustivité des explications générées par le modèle. Cela permet de garantir que l’explication est crédible.
Déploiement et surveillance : le travail de XAI ne s'arrête pas à la création et à la validation de modèles. Cela nécessite un travail d’explicabilité continu après le déploiement. Lors de la surveillance dans un environnement réel, il est important d’évaluer régulièrement les performances et l’interprétabilité du système.
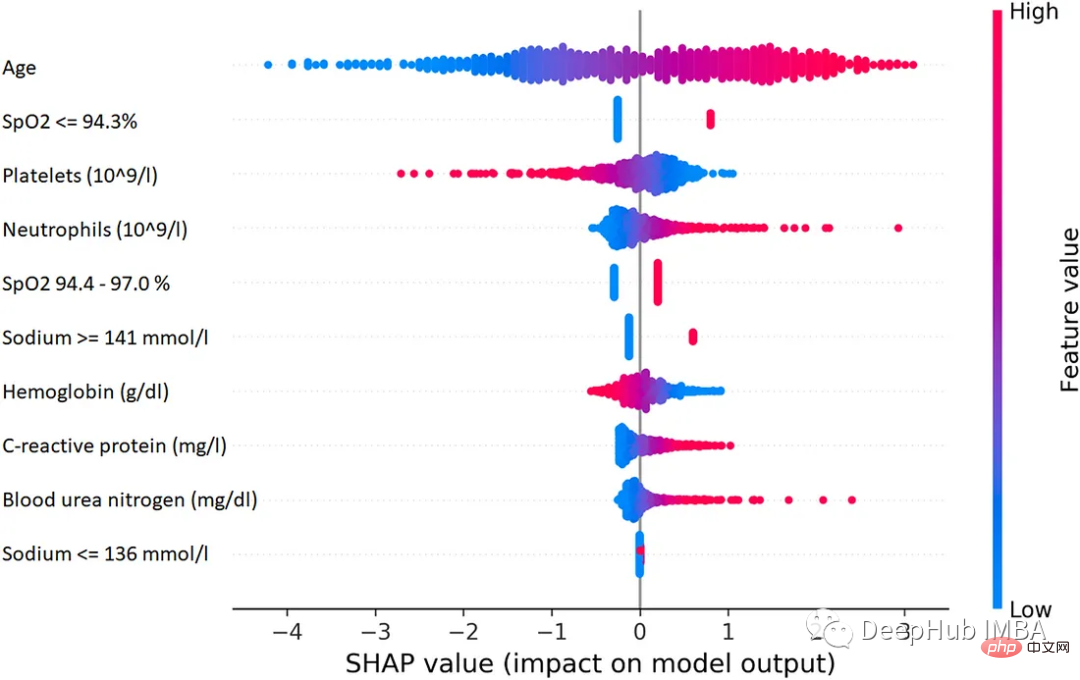
SHAP est une méthode de théorie des jeux qui peut être utilisée pour expliquer le résultat de n'importe quel modèle d'apprentissage automatique. Il utilise la valeur Shapley classique de la théorie des jeux et ses extensions associées pour relier l'allocation optimale de crédits aux interprétations locales.
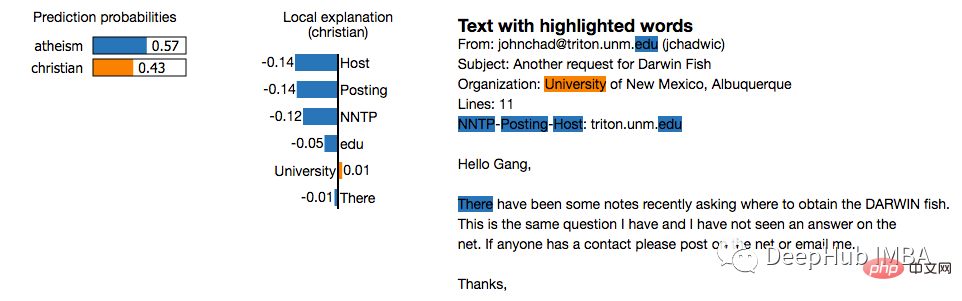
LIME est une approche indépendante du modèle qui fonctionne en approchant localement le comportement du modèle autour d'une prédiction spécifique. LIME tente d'expliquer ce que fait un modèle d'apprentissage automatique. LIME prend en charge l'interprétation des prédictions individuelles à partir de classificateurs de texte, de classificateurs de données tabulaires ou d'images.
ELI5 est un package Python qui aide à déboguer les classificateurs d'apprentissage automatique et à interpréter leurs prédictions. Il prend en charge les frameworks et packages d'apprentissage automatique suivants :
Utilisation de base :
Show_weights() affiche tous les poids du modèle, Show_prediction() peut être utilisé pour vérifier les prédictions individuelles du modèle

ELI5 implémente également certains algorithmes pour vérifier les modèles de boîte noire :
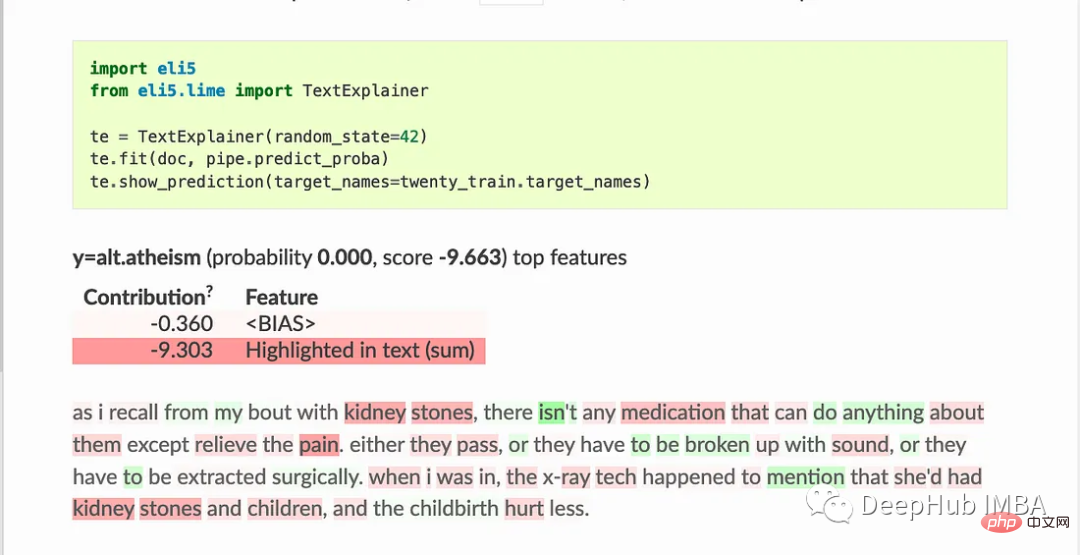
TextExplainer utilise l'algorithme LIME pour expliquer les prédictions de n'importe quel classificateur de texte. La méthode de l'importance de permutation peut être utilisée pour calculer l'importance des caractéristiques pour les estimateurs boîte noire.
Shapash propose plusieurs types de visualisations pour faciliter la compréhension du modèle. Utilisez le résumé pour comprendre les décisions proposées par le modèle. Ce projet est développé par les data scientists de la MAIF. Shapash explique principalement le modèle à travers un ensemble d'excellentes visualisations.
Shapash fonctionne via le mécanisme d'application Web et peut être parfaitement intégré à Jupyter/ipython.
from shapash import SmartExplainer
xpl = SmartExplainer(
model=regressor,
preprocessing=encoder, # Optional: compile step can use inverse_transform method
features_dict=house_dict# Optional parameter, dict specifies label for features name
)
xpl.compile(x=Xtest,
y_pred=y_pred,
y_target=ytest, # Optional: allows to display True Values vs Predicted Values
)
xpl.plot.contribution_plot("OverallQual")
Les ancres expliquent le comportement de modèles complexes à l'aide de règles de haute précision appelées points d'ancrage, qui représentent des conditions de prédiction locales « suffisantes ». L'algorithme peut calculer efficacement l'explication de n'importe quel modèle de boîte noire avec des garanties de probabilité élevées.
Les ancres peuvent être considérées comme LIME v2, où certaines limitations de LIME (telles que l'incapacité d'ajuster des modèles pour des instances invisibles des données) ont été corrigées. Les ancres utilisent des zones locales plutôt que chaque point de vue individuel. Il est plus léger que SHAP sur le plan informatique et peut donc être utilisé avec des ensembles de données de grande dimension ou volumineux. Mais certaines limitations sont que les étiquettes ne peuvent être que des nombres entiers.

BreakDown est un outil qui peut être utilisé pour expliquer les prédictions d'un modèle linéaire. Il fonctionne en décomposant la sortie du modèle en contribution de chaque fonctionnalité d'entrée. Il existe deux méthodes principales dans ce package. Explainer() et Explanation()
model = tree.DecisionTreeRegressor() model = model.fit(train_data,y=train_labels) #necessary imports from pyBreakDown.explainer import Explainer from pyBreakDown.explanation import Explanation #make explainer object exp = Explainer(clf=model, data=train_data, colnames=feature_names) #What do you want to be explained from the data (select an observation) explanation = exp.explain(observation=data[302,:],direction="up")

Interpret-Text combine la technologie d'interprétabilité développée par la communauté pour les modèles PNL et un panneau de visualisation pour visualiser les résultats. Les expériences peuvent être menées sur plusieurs interprètes de pointe et analysées de manière comparative. Cette boîte à outils peut interpréter les modèles d'apprentissage automatique globalement sur chaque balise ou localement sur chaque document.
Voici la liste des interprètes disponibles dans ce package :
from interpret_text.widget import ExplanationDashboard from interpret_text.explanation.explanation import _create_local_explanation # create local explanation local_explanantion = _create_local_explanation( classification=True, text_explanation=True, local_importance_values=feature_importance_values, method=name_of_model, model_task="classification", features=parsed_sentence_list, classes=list_of_classes, ) # Dash it ExplanationDashboard(local_explanantion)
8, aix360 (AI Explainability 360)
 AI Explainability 360 toolkit est une bibliothèque open source, ce package a été développé par IBM, dans leur largement utilisé sur la plateforme. AI Explainability 360 contient un ensemble complet d'algorithmes couvrant différentes dimensions d'explication ainsi que des mesures d'explicabilité des agents.
AI Explainability 360 toolkit est une bibliothèque open source, ce package a été développé par IBM, dans leur largement utilisé sur la plateforme. AI Explainability 360 contient un ensemble complet d'algorithmes couvrant différentes dimensions d'explication ainsi que des mesures d'explicabilité des agents.
 Toolkit combine des algorithmes et des indicateurs issus des articles suivants :
Toolkit combine des algorithmes et des indicateurs issus des articles suivants :
OmniXAI (Omni explable AI的缩写),解决了在实践中解释机器学习模型产生的判断的几个问题。
它是一个用于可解释AI (XAI)的Python机器学习库,提供全方位的可解释AI和可解释机器学习功能,并能够解决实践中解释机器学习模型所做决策的许多痛点。OmniXAI旨在成为一站式综合库,为数据科学家、ML研究人员和从业者提供可解释的AI。
from omnixai.visualization.dashboard import Dashboard # Launch a dashboard for visualization dashboard = Dashboard( instances=test_instances,# The instances to explain local_explanations=local_explanations, # Set the local explanations global_explanations=global_explanations, # Set the global explanations prediction_explanations=prediction_explanations, # Set the prediction metrics class_names=class_names, # Set class names explainer=explainer# The created TabularExplainer for what if analysis ) dashboard.show()

XAI 库由 The Institute for Ethical AI & ML 维护,它是根据 Responsible Machine Learning 的 8 条原则开发的。它仍处于 alpha 阶段因此请不要将其用于生产工作流程。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



