
 développement back-end
Tutoriel Python
Huit scripts d'automatisation Python prêts à l'emploi !
développement back-end
Tutoriel Python
Huit scripts d'automatisation Python prêts à l'emploi !
Huit scripts d'automatisation Python prêts à l'emploi !


Vous pouvez effectuer de nombreuses tâches répétitives chaque jour, telles que lire des actualités, envoyer des e-mails, consulter la météo, nettoyer des dossiers, etc. Grâce à des scripts automatisés, vous n'avez pas besoin d'effectuer ces tâches manuellement encore et encore, ce qui est très pratique. Dans une certaine mesure, Python est synonyme d'automatisation.
Aujourd'hui, je partage 8 scripts d'automatisation Python très utiles. Si vous le souhaitez, n'oubliez pas de collecter, de suivre et d'aimer.
1. Lire automatiquement les actualités Web
Ce script peut récupérer le texte des pages Web, puis le lire automatiquement par la voix. C'est un bon choix lorsque vous souhaitez écouter des actualités.
Le code est divisé en deux parties. La première consiste à explorer le texte de la page Web et la seconde consiste à lire le texte à haute voix via l'outil de lecture.
Bibliothèques tierces requises :
Beautiful Soup - un analyseur de texte HTML/XML classique, utilisé pour extraire les informations des pages Web explorées.
requests - Outil HTTP incroyablement utile, utilisé pour envoyer des requêtes aux pages Web afin d'obtenir des données.
Pyttsx3 - Convertissez le texte en parole et contrôlez le débit, la fréquence et la voix.
import pyttsx3
import requests
from bs4 import BeautifulSoup
engine = pyttsx3.init('sapi5')
voices = engine.getProperty('voices')
newVoiceRate = 130 ## Reduce The Speech Rate
engine.setProperty('rate',newVoiceRate)
engine.setProperty('voice', voices[1].id)
def speak(audio):
engine.say(audio)
engine.runAndWait()
text = str(input("Paste articlen"))
res = requests.get(text)
soup = BeautifulSoup(res.text,'html.parser')
articles = []
for i in range(len(soup.select('.p'))):
article = soup.select('.p')[i].getText().strip()
articles.append(article)
text = " ".join(articles)
speak(text)
# engine.save_to_file(text, 'test.mp3') ## If you want to save the speech as a audio file
engine.runAndWait()2. Exploration automatisée des données
L'exploration des données est la première étape d'un projet de science des données. Vous devez comprendre les informations de base des données pour analyser plus en profondeur la valeur.
Généralement, nous utilisons pandas, matplotlib et d'autres outils pour explorer les données, mais nous devons écrire beaucoup de code nous-mêmes si nous voulons améliorer l'efficacité, Dtale est un bon choix.
Dtale se caractérise par la génération de rapports d'analyse automatisés avec une seule ligne de code. Il combine le backend Flask et l'interface React pour nous fournir un moyen simple de visualiser et d'analyser les structures de données Pandas.
Nous pouvons utiliser Dtale sur Jupyter.
Bibliothèques tierces requises :
Dtale - génère automatiquement des rapports d'analyse.
### Importing Seaborn Library For Some Datasets
import seaborn as sns
### Printing Inbuilt Datasets of Seaborn Library
print(sns.get_dataset_names())
### Loading Titanic Dataset
df=sns.load_dataset('titanic')
### Importing The Library
import dtale
#### Generating Quick Summary
dtale.show(df)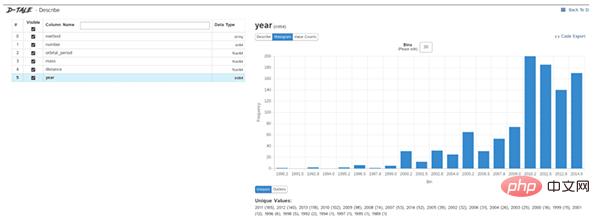
3. Envoyer automatiquement plusieurs e-mails
Ce script peut nous aider à envoyer des e-mails par lots et à intervalles réguliers. Le contenu des e-mails et les pièces jointes peuvent également être personnalisés et ajustés, ce qui est très pratique.
Par rapport aux clients de messagerie, l'avantage des scripts Python est qu'ils peuvent déployer des services de messagerie de manière intelligente, par lots et avec une personnalisation élevée.
Bibliothèques tierces requises :
Email - pour gérer les e-mails
Smtlib - pour envoyer des e-mails aux serveurs SMTP, il définit un objet de session client SMTP qui envoie des e-mails à Internet sur n'importe quel ordinateur doté d'un SMTP ou Écouteur ESMTP
Pandas - Outil d'analyse et de nettoyage des données.
import smtplib
from email.message import EmailMessage
import pandas as pd
def send_email(remail, rsubject, rcontent):
email = EmailMessage()## Creating a object for EmailMessage
email['from'] = 'The Pythoneer Here'## Person who is sending
email['to'] = remail## Whom we are sending
email['subject'] = rsubject ## Subject of email
email.set_content(rcontent) ## content of email
with smtplib.SMTP(host='smtp.gmail.com',port=587)as smtp:
smtp.ehlo() ## server object
smtp.starttls() ## used to send data between server and client
smtp.login("deltadelta371@gmail.com","delta@371") ## login id and password of gmail
smtp.send_message(email)## Sending email
print("email send to ",remail)## Printing success message
if __name__ == '__main__':
df = pd.read_excel('list.xlsx')
length = len(df)+1
for index, item in df.iterrows():
email = item[0]
subject = item[1]
content = item[2]
send_email(email,subject,content)4. Convertir un PDF en fichier audio
Le script peut convertir un pdf en fichier audio. Le principe est également très simple. Utilisez d'abord PyPDF pour extraire le texte du pdf, puis utilisez Pyttsx3 pour convertir le texte en parole. .
import pyttsx3,PyPDF2
pdfreader = PyPDF2.PdfFileReader(open('story.pdf','rb'))
speaker = pyttsx3.init()
for page_num in range(pdfreader.numPages):
text = pdfreader.getPage(page_num).extractText()## extracting text from the PDF
cleaned_text = text.strip().replace('n',' ')## Removes unnecessary spaces and break lines
print(cleaned_text)## Print the text from PDF
#speaker.say(cleaned_text)## Let The Speaker Speak The Text
speaker.save_to_file(cleaned_text,'story.mp3')## Saving Text In a audio file 'story.mp3'
speaker.runAndWait()
speaker.stop()5. Jouer de la musique aléatoire dans la liste
Ce script sélectionnera au hasard une chanson dans le dossier de chansons à lire. Il convient de noter que os.startfile ne prend en charge que les systèmes Windows.
import random, os music_dir = 'G:\new english songs' songs = os.listdir(music_dir) song = random.randint(0,len(songs)) print(songs[song])## Prints The Song Name os.startfile(os.path.join(music_dir, songs[0]))
6. Informations météorologiques intelligentes
Le site Web du National Weather Service fournit une API pour obtenir des prévisions météorologiques, qui renvoie directement les données météorologiques au format json. Il vous suffit donc d'extraire les champs correspondants de json.
Ce qui suit est l'URL de la météo dans la ville désignée (comté, district). Ouvrez directement l'URL et les données météorologiques de la ville correspondante seront renvoyées. Par exemple :
http://www.weather.com.cn/data/cityinfo/101021200.html L'URL météo correspondant au district de Xuhui, Shanghai.
Le code spécifique est le suivant :
mport requests
import json
import logging as log
def get_weather_wind(url):
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
info = json.loads(r.content.decode())
# get wind data
data = info['weatherinfo']
WD = data['WD']
WS = data['WS']
return "{}({})".format(WD, WS)
def get_weather_city(url):
# open url and get return data
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
# convert string to json
info = json.loads(r.content.decode())
# get useful data
data = info['weatherinfo']
city = data['city']
temp1 = data['temp1']
temp2 = data['temp2']
weather = data['weather']
return "{} {} {}~{}".format(city, weather, temp1, temp2)
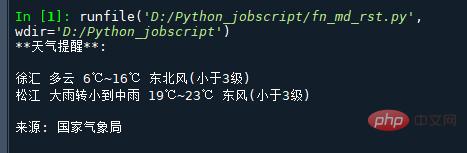
if __name__ == '__main__':
msg = """**天气提醒**:
{} {}
{} {}
来源: 国家气象局
""".format(
get_weather_city('http://www.weather.com.cn/data/cityinfo/101021200.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101021200.html'),
get_weather_city('http://www.weather.com.cn/data/cityinfo/101020900.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101020900.html')
)
print(msg)Le résultat est le suivant :
7. Les URL longues deviennent des URL courtes
Parfois, ces grosses URL deviennent très ennuyeuses et difficiles à lire et partager, ces pieds peuvent convertir des URL longues en URL courtes.
import contextlib
from urllib.parse import urlencode
from urllib.request import urlopen
import sys
def make_tiny(url):
request_url = ('http://tinyurl.com/api-create.php?' +
urlencode({'url':url}))
with contextlib.closing(urlopen(request_url)) as response:
return response.read().decode('utf-8')
def main():
for tinyurl in map(make_tiny, sys.argv[1:]):
print(tinyurl)
if __name__ == '__main__':
main()Ce script est très pratique. Par exemple, s'il existe une plateforme de contenu qui bloque les articles du compte public, alors vous pouvez changer le lien de l'article du compte public en un lien court puis l'insérer dedans pour contourner
8. Nettoyer le dossier de téléchargement
L'une des choses les plus encombrées au monde est le dossier de téléchargement du développeur, qui contient de nombreux fichiers désorganisés. Ce script nettoiera votre dossier de téléchargement en fonction de la taille limite, avec un nettoyage limité. des fichiers plus anciens :
import os
import threading
import time
def get_file_list(file_path):
#文件按最后修改时间排序
dir_list = os.listdir(file_path)
if not dir_list:
return
else:
dir_list = sorted(dir_list, key=lambda x: os.path.getmtime(os.path.join(file_path, x)))
return dir_list
def get_size(file_path):
"""[summary]
Args:
file_path ([type]): [目录]
Returns:
[type]: 返回目录大小,MB
"""
totalsize=0
for filename in os.listdir(file_path):
totalsize=totalsize+os.path.getsize(os.path.join(file_path, filename))
#print(totalsize / 1024 / 1024)
return totalsize / 1024 / 1024
def detect_file_size(file_path, size_Max, size_Del):
"""[summary]
Args:
file_path ([type]): [文件目录]
size_Max ([type]): [文件夹最大大小]
size_Del ([type]): [超过size_Max时要删除的大小]
"""
print(get_size(file_path))
if get_size(file_path) > size_Max:
fileList = get_file_list(file_path)
for i in range(len(fileList)):
if get_size(file_path) > (size_Max - size_Del):
print ("del :%d %s" % (i + 1, fileList[i]))
#os.remove(file_path + fileList[i])Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
En ce qui concerne le problème de la suppression de l'interpréteur Python qui est livré avec des systèmes Linux, de nombreuses distributions Linux préinstalleront l'interpréteur Python lors de l'installation, et il n'utilise pas le gestionnaire de packages ...
 Comment résoudre le problème de la détection de type pylance des décorateurs personnalisés dans Python?
Apr 02, 2025 am 06:42 AM
Comment résoudre le problème de la détection de type pylance des décorateurs personnalisés dans Python?
Apr 02, 2025 am 06:42 AM
Solution de problème de détection de type pylance Lorsque vous utilisez un décorateur personnalisé dans la programmation Python, le décorateur est un outil puissant qui peut être utilisé pour ajouter des lignes ...
 La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
À propos de Pythonasyncio ...
 Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Utilisation de Python dans Linux Terminal ...
 Python 3.6 Chargement du fichier de cornichon MODULENOTFOUNDERROR: Que dois-je faire si je charge le fichier de cornichon '__builtin__'?
Apr 02, 2025 am 06:27 AM
Python 3.6 Chargement du fichier de cornichon MODULENOTFOUNDERROR: Que dois-je faire si je charge le fichier de cornichon '__builtin__'?
Apr 02, 2025 am 06:27 AM
Chargement du fichier de cornichon dans Python 3.6 Erreur d'environnement: modulenotFounonError: NomoduLenamed ...
 FastAPI et AIOHTTP partagent-ils la même boucle d'événements mondiaux?
Apr 02, 2025 am 06:12 AM
FastAPI et AIOHTTP partagent-ils la même boucle d'événements mondiaux?
Apr 02, 2025 am 06:12 AM
Problèmes de compatibilité entre les bibliothèques asynchrones Python dans Python, la programmation asynchrone est devenue le processus de concurrence élevée et d'E / S ...
 Comment s'assurer que le processus de l'enfant se termine également après avoir tué le processus parent via le signal dans Python?
Apr 02, 2025 am 06:39 AM
Comment s'assurer que le processus de l'enfant se termine également après avoir tué le processus parent via le signal dans Python?
Apr 02, 2025 am 06:39 AM
Le problème et la solution du processus enfant continuent d'exécuter lors de l'utilisation de signaux pour tuer le processus parent. Dans la programmation Python, après avoir tué le processus parent à travers des signaux, le processus de l'enfant est toujours ...
 Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Chargement des fichiers de cornichons dans Python 3.6 Rapport de l'environnement Erreur: modulenotFoundError: NomoduLenamed ...
