
 Périphériques technologiques
IA
Modèle d'exploration basé sur le gradient contradictoire et son application dans la prédiction des clics
Périphériques technologiques
IA
Modèle d'exploration basé sur le gradient contradictoire et son application dans la prédiction des clics
Modèle d'exploration basé sur le gradient contradictoire et son application dans la prédiction des clics

1. Résumé
Les modèles de classement jouent un rôle essentiel dans les systèmes de publicité, de recommandation et de recherche. Dans le module de classement, la technologie d'estimation du taux de clics est la priorité absolue. Actuellement, la plupart des technologies de prédiction du taux de clics du secteur utilisent des algorithmes d'apprentissage profond pour former des réseaux neuronaux profonds basés sur le lecteur de données. Cependant, le problème correspondant causé par le lecteur de données est que les nouveaux projets dans le système de recommandation auront un problème de démarrage à froid.
La méthode Exploration-Exploitation (E&E) est généralement utilisée pour traiter les problèmes de cycle de données dans les systèmes de recommandation en ligne à grande échelle. Les recherches antérieures pensaient généralement qu’une incertitude élevée dans les prévisions des modèles signifiait des rendements potentiels élevés, c’est pourquoi la plupart des travaux de recherche se concentraient sur l’estimation de l’incertitude. Pour les systèmes de recommandation en ligne utilisant la formation en continu, la stratégie d'exploration aura un impact plus important sur la collecte d'échantillons de formation, ce qui à son tour affectera l'apprentissage ultérieur du modèle. Cependant, la plupart des stratégies d’exploration actuelles ne peuvent pas modéliser correctement la manière dont les échantillons explorés affectent l’apprentissage ultérieur du modèle. Par conséquent, nous avons conçu un module de pseudo-exploration (Pseudo-Exploration) pour simuler l'impact sur l'apprentissage ultérieur du modèle de recommandation une fois l'échantillon exploré et affiché avec succès.
Le processus de quasi-exploration est réalisé en ajoutant des perturbations contradictoires à l'entrée du modèle. Nous fournissons également l'analyse théorique correspondante et la preuve de ce processus. Sur cette base, nous appelons cette méthode une stratégie d'exploration basée sur un gradient contradictoire (Adversarial Gradientdriven Exploration, ci-après dénommée AGE). Afin d'améliorer l'efficacité de l'exploration, nous proposons également une unité de contrôle dynamique pour filtrer les échantillons de faible valeur afin d'éviter de gaspiller des ressources dans une exploration de faible valeur. Afin de vérifier l'efficacité de l'algorithme AGE, nous avons non seulement mené un grand nombre d'expériences sur des ensembles de données universitaires publiques, mais avons également déployé le modèle AGE sur la plateforme de publicité display Alimama et obtenu de bons retours en ligne. Ce travail a été inclus sous forme d'article complet dans le volet de recherche KDD 2022. Vous êtes invités à lire et à communiquer.
Article : Adversarial Gradient Driven Exploration for Deep Click-Through Rate Prediction
Téléchargement : https://arxiv.org/abs/2112.11136
2 Contexte
Dans les systèmes publicitaires, modèle de prédiction du taux de clics (CTR). La méthode de streaming est généralement utilisée pour la formation, et la source des données de streaming est produite par le modèle CTR déployé en ligne, ce qui crée ce que l'on appelle le problème de la boucle de données. Étant donné que les publicités à démarrage à froid et à longue traîne ne sont pas entièrement affichées, le modèle CTR manque de données de formation pour ces publicités. Cela conduit également à ce que l'estimation par le modèle de ces publicités puisse contenir des erreurs importantes, ce qui rendra plus difficile l'affichage de ces publicités, ce qui rendra leur affichage plus difficile. il est difficile de terminer le démarrage à froid. Plus précisément, la figure 1 montre la relation entre le taux de clics réel d'une publicité et le nombre d'impressions : dans notre système, une nouvelle publicité doit être affichée en moyenne environ 10 000 fois avant que son taux de clics puisse atteindre une convergence. État. Cela pose un problème commun à de nombreux systèmes en ligne, à savoir comment démarrer à froid ces publicités tout en garantissant l'expérience utilisateur.
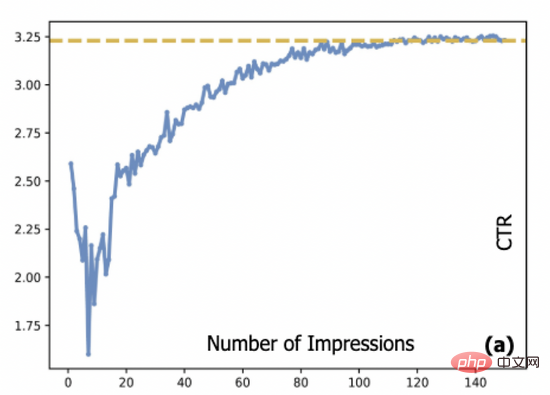
Figure 1 : La relation entre le CTR publicitaire et le nombre d'impressions
Les algorithmes d'exploration et d'exploitation (E&E) sont généralement utilisés pour résoudre les problèmes ci-dessus. Dans les systèmes de recommandation ou de publicité, les méthodes courantes (telles que les bandits contextuels multi-armés, les bandits contextuels multi-armés) modélisent généralement ce problème comme suit. À chaque étape, le système sélectionne une action basée sur la politique P (c'est-à-dire recommande un élément _ _ à l'utilisateur). Afin de maximiser la récompense cumulée (généralement mesurée par le nombre total de clics), le système doit déterminer si l'accent est actuellement mis sur l'exploration ou l'exploitation. Les recherches antérieures considèrent généralement qu’une incertitude élevée est une mesure des rendements potentiels. D'une part, la stratégie P doit donner la priorité aux projets ayant une plus grande utilité actuelle pour maximiser le cycle actuel d'avantages, d'autre part, l'algorithme doit également sélectionner des opérations avec une plus grande incertitude pour réaliser l'exploration ; S'il est utilisé pour représenter la stratégie de pondération de l'exploration et de l'exploitation, le score final du projet par le système peut être exprimé par la formule suivante :
L'estimation de l'incertitude est devenue le module central de nombreux algorithmes E&E. L'incertitude peut provenir de la variabilité des données, du bruit de mesure et de l'instabilité du modèle (par exemple, le caractère aléatoire des paramètres). Les méthodes d'estimation typiques incluent le MC-Dropout de Monte Carlo, le réseau neuronal bayésien, les processus gaussiens et la modélisation de l'incertitude basée sur les normes de gradient ( poids du modèle), etc. Sur cette base, il existe deux stratégies d'exploration typiques : les méthodes basées sur UCB utilisent généralement la limite supérieure des rendements potentiels comme score final [1, 2], tandis que les méthodes basées sur l'échantillonnage de Thompson sont complétées par un échantillonnage à partir de la distribution de probabilité estimée [ 3 ].
3. Introduction à la méthode
Nous pensons que la méthode ci-dessus ne considère pas une boucle fermée d'exploration complète. Pour les systèmes en ligne basés sur les données, l'avantage ultime de l'exploration vient des données de retour obtenues lors du processus d'exploration et des données de retour pour la formation et la mise à jour du modèle. L’incertitude de l’estimation du modèle elle-même ne reflète pas pleinement l’ensemble de la boucle de rétroaction. À cette fin, nous avons introduit un module de quasi-exploration pour simuler l'impact des données de rétroaction sur le modèle après avoir terminé l'action d'exploration, et l'utiliser pour mesurer l'efficacité de l'exploration. L'analyse a révélé que l'efficacité de l'exploration dépend non seulement de l'incertitude estimée du modèle, mais également de l'ampleur de la « contre-perturbation ». La perturbation dite contradictoire fait référence au vecteur de perturbation avec une longueur de module fixe ajouté à l'entrée du modèle qui provoque le plus grand changement dans la sortie du modèle. Dans cet article, nous avons également prouvé qu'une fois le modèle entraîné une fois à l'aide des données explorées, l'attente de changement dans la sortie du modèle équivaut à l'ajout d'un vecteur incrémental dont le module est l'incertitude et le vecteur de perturbation est le gradient antagoniste au vecteur d'entrée. . Nous avons vérifié que cette modélisation permet d'estimer l'impact ultérieur des échantillons explorés sur le modèle en boucle fermée, estimant ainsi la vraie valeur des échantillons explorés.
Nous appelons cette méthode Adversarial Gradient Driven Exploration, ou AGE en abrégé. Le modèle AGE se compose de deux parties : le module de pseudo-exploration et l'unité de déclenchement dynamique. Sa structure globale est illustrée à la figure 2.
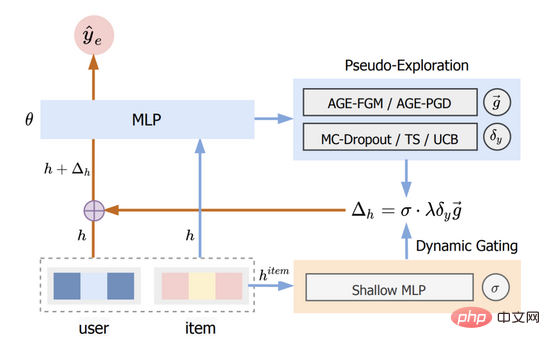
Figure 2 : Diagramme de structure AGE
Voir la section 3.1 pour plus de détails et la section 3.3 pour plus de détails.
3.1 Module de pseudo-exploration
3.1.1 Introduction du module
L'objectif principal du module de pseudo-exploration est de simuler quantitativement le changement du score de l'échantillon après que le modèle soit formé à l'aide de l'échantillon d'exploration, donc afin d'estimer les effets de clôture de l'exploration sur le modèle. Après dérivation, nous avons constaté que le processus ci-dessus peut être complété par la formule (2), qui représente le score de l'échantillon après exploration par le modèle, que nous utilisons pour le classement final.
La formule ci-dessus signifie que nous n'avons besoin d'effectuer aucune opération sur les paramètres du modèle d'origine. Il nous suffit d'ajouter le produit du gradient contradictoire, de l'incertitude estimée et de définir manuellement les hyperparamètres à la représentation d'entrée pour terminer l'exploration du modèle. scores estimés. Parmi eux, la méthode de calcul des paramètres sera présentée dans la section suivante. Plus loin dans cette section, nous présenterons le processus de dérivation détaillé de la formule (2) dans le module d'exploration proposé.
3.1.2 Dérivation détaillée
Pour chaque échantillon de données, l'entraînement du modèle affectera deux parties des paramètres : la représentation correspondant à l'échantillon (y compris le produit, l'intégration de l'utilisateur, etc.) et les paramètres du modèle. Étant donné que l'objectif des paramètres du modèle dans la formation est de s'adapter à tous les échantillons plutôt qu'à un seul échantillon, nous pouvons penser que la formation d'un seul échantillon affectera principalement la représentation de l'échantillon et que les paramètres du modèle eux-mêmes ne nécessitent que des ajustements mineurs. Par conséquent, dans les études ultérieures, nous ignorerons l’ajustement et nous concentrerons uniquement sur les changements dans les représentations correspondant aux échantillons. En supposant que la véritable étiquette de l'échantillon contenant la représentation soit, pendant la formation, nous devons trouver la quantité de mises à jour pour minimiser la fonction de perte. Sur cette base, nous définissons :
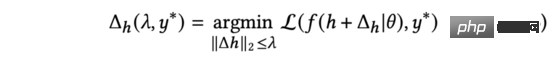
qui représente la fonction de perte utilisée dans l'entraînement, et la fonction de perte d'entropie croisée est généralement utilisée dans les tâches de prédiction CTR. En même temps, nous utilisons pour contraindre le changement maximum de représentation. Afin de simplifier l’écriture, nous écrirons le côté droit de la formule ci-dessus ainsi.
Selon le théorème de la valeur moyenne de Lagrange, lorsque la deuxième norme de est proche de 0, nous pouvons dériver la formule de la fonction de perte (3) ci-dessus comme suit :
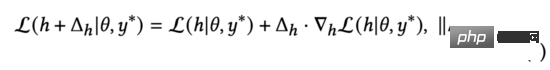
Nous observons la formule (4) et il est facile de trouver que La fonction de perte obtient sa valeur minimale lorsque les deux vecteurs ont des directions opposées. Dans l’équation (3), nous limitons les perturbations. Par conséquent, en résolvant l'équation (3), nous obtenons :
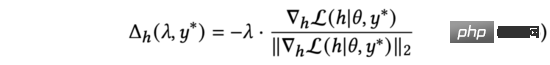
En pratique, nous utilisons pour remplacer le gradient normalisé dans l'équation (5). En déduisant la règle de chaîne, elle peut être développée en deux parties : et . En calculant plus loin, nous obtenons :
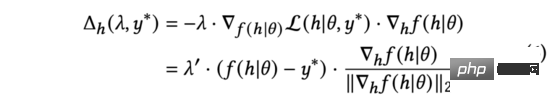
Dans l'équation ci-dessus, nous allons redimensionner pour garder l'équation vraie. Bien que les significations soient différentes, ce sont tous des hyperparamètres ajustés manuellement, nous pouvons donc directement effectuer le remplacement. Nous simplifions encore la formule (6) comme suit :
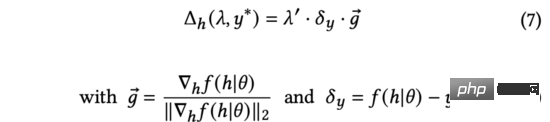
Dans la formule ci-dessus, le gradient normalisé représente la direction de la dérivée de la sortie du modèle par rapport à la représentation d'entrée. Étant donné que les commentaires réels des utilisateurs ne sont pas disponibles au moment de l'exploration, nous utiliserons l'incertitude d'estimation pour mesurer la différence entre le score prédit et les commentaires réels des utilisateurs.
Dans la formule (7), nous trouvons la solution analytique qui peut maximiser le changement dans la sortie de prédiction du modèle sous les contraintes de (la dérivation est la même que celle de la formule (3) à la formule (5)). De plus, nous constatons également que le processus ci-dessus d’ajout d’une représentation d’entrée se présente sous la même forme qu’une perturbation contradictoire (voir l’équation (9)).
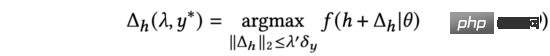
Par conséquent, nous utilisons le gradient contradictoire pour remplacer dans la formule (7) et nommons notre méthode comme algorithme d'exploration basé sur le gradient contradictoire.
La formule (9) montre que le moyen le plus efficace d'explorer AGE est d'ajouter des perturbations contradictoires à l'entrée de la représentation et d'utiliser la sortie du modèle perturbé comme facteur de classement : la direction du vecteur de perturbation représenté par le gradient contradictoire comme l'entrée et le degré d'incertitude de la prévision de la perturbation. Par conséquent, après avoir obtenu la somme, nous pouvons utiliser la formule suivante pour calculer le score de prédiction du modèle après exploration, qui est la formule (2) susmentionnée.
3.2 Détails de mise en œuvre
Dans AGE, nous utilisons la méthode MC-Dropout pour estimer l'incertitude. Plus précisément, MC-Dropout attribue un poids de masque aléatoire à chaque neurone du modèle profond. La méthode spécifique est présentée dans la formule suivante (11). L’un des avantages de cette méthode est que nous pouvons obtenir directement l’incertitude sans modifier la structure originale du modèle. En fonctionnement réel, l'incertitude peut être exprimée en calculant la variance d'abandon grâce à l'idée d'UCB, ou en se référant à la méthode d'échantillonnage aléatoire de Thompson en calculant la différence entre l'échantillonnage et la moyenne, c'est-à-dire la formule ( 12) et formule (13) ).
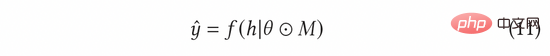
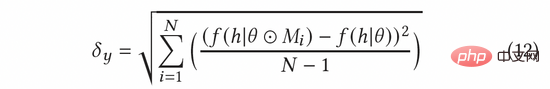
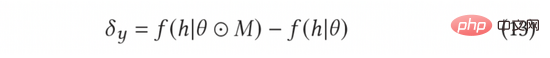
Le gradient contradictoire normalisé peut être calculé selon la méthode du gradient rapide (FGM) dans la formule (8). Afin de calculer plus précisément le gradient adverse, nous pouvons en outre utiliser la méthode de descente de gradient proximal (PGD) pour mettre à jour de manière itérative le gradient en plusieurs étapes, comme le montre l'équation (14).
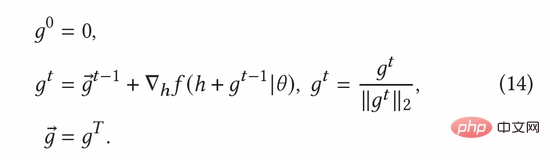
3.3 Unité de Gating Dynamique
En pratique, nous avons constaté que toutes les publicités ne valent pas la peine d'être explorées. Dans un système publicitaire Top-K général, le nombre d'annonces pouvant être affichées auprès des utilisateurs finaux est relativement faible. Par conséquent, pour les annonces avec de faibles taux de clics (par exemple, les annonces de mauvaise qualité elles-mêmes), même si le modèle présente une grande incertitude dans la prédiction de ces annonces, la valeur exploratoire reste très faible compte tenu des attributs commerciaux du système publicitaire. . Bien que nous puissions obtenir une grande quantité de données sur ces publicités grâce à l'exploration, afin que ces publicités puissent être entièrement entraînées par le modèle et estimées avec plus de précision, le faible taux de clics de ces publicités rendra impossible l'obtention de ces publicités ; par eux-mêmes, même après une exploration complète du trafic, une telle exploration est sans aucun doute inefficace. Dans cet article, nous avons essayé une heuristique simple pour rendre l'exploration plus efficace : si le score estimé du modèle pour l'annonce est supérieur au taux de clics moyen pour l'annonce dans tous les groupes, nous explorerons sinon, l'exploration n'aura pas lieu ;
Pour calculer le taux de clics moyen des annonces, nous introduisons le module Dynamic Gating Threshold Unit (DGU). DGU utilise uniquement les fonctionnalités côté publicité comme entrée pour estimer le taux de clics moyen des publicités. Lorsque le taux de clics estimé par le modèle est inférieur au taux de clics publicitaire moyen estimé par le module DGU, aucune exploration ne sera effectuée. Dans le cas contraire, une exploration normale sera effectuée. Le processus est représenté dans la formule suivante :
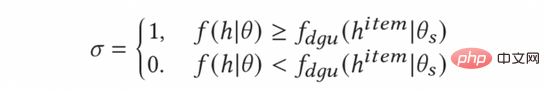
Enfin, nous le substituerons dans la formule (10) pour obtenir la méthode de calcul finale et complète du modèle d'exploration AGE comme suit.
4. Évaluation expérimentale
4.1 Expérience hors ligne
Nous avons comparé trois grandes catégories de méthodes de base, notamment les méthodes d'exploration basées sur un échantillonnage aléatoire, les méthodes d'exploration basées sur un modèle approfondi et les méthodes d'exploration basées sur le gradient. . On peut observer que les modèles de base construits sur la base de la méthode Thompson Sampling (TS) sont meilleurs que les modèles basés sur UCB, prouvant que TS est un meilleur algorithme pour mesurer l'incertitude du modèle. De plus, nous pouvons observer que l’algorithme AGE surpasse toutes les méthodes de base, ce qui prouve également l’efficacité de la méthode AGE. Plus précisément, AGE-TS et AGE-UCB surpassent les meilleures lignes de base UR-gradient-TS et UR-gradient-UCB [4], avec des valeurs d'amélioration de 5,41 % et 15,3 % respectivement. La méthode AGE-TS augmente les clics de 28,0 % par rapport à la méthode de base sans exploration. Il convient de noter que les algorithmes UCB et TS basés sur AGE AGE-UCB et AGE-TS obtiennent des résultats similaires, ce qui n'est pas le cas des algorithmes UCB et TS basés sur le gradient, ce qui prouve également que AGE peut compenser l'instabilité de la méthode UCB.
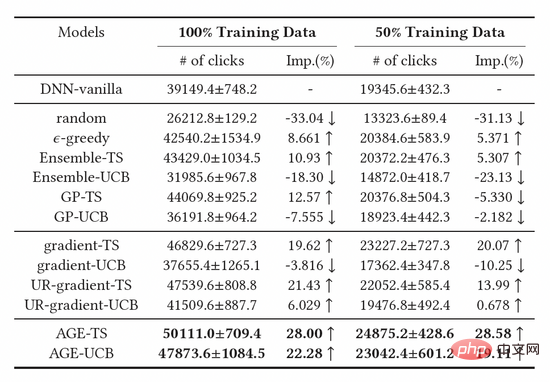
Tableau 1 : Résultats expérimentaux hors ligne
Nous avons également mené un grand nombre d'expériences d'ablation pour prouver l'efficacité de chaque module. Comme le montre le tableau 2, l'unité de seuil, le gradient contradictoire et l'unité d'incertitude sont tous indispensables. Afin de déterminer davantage l'effet du DGU, nous avons essayé différents paramètres de seuil fixe et avons finalement constaté que leurs effets n'étaient pas aussi bons que le seuil dynamique du DGU.
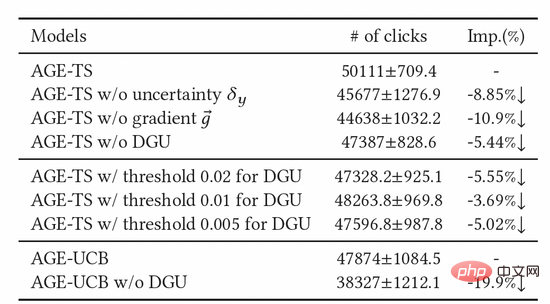
Tableau 2 : Résultats de l'expérience d'ablation
4.2 Expérience en ligne
Nous avons également déployé le modèle AGE dans le système publicitaire display Alimama Afin d'évaluer avec précision la valeur d'exploration du modèle, nous avons conçu une méthode d'évaluation basée sur. des seaux équitables. Comme le montre la figure 3, nous avons d'abord configuré le bucket C et le bucket D pour la collecte de données. Dans le bucket D, nous déployons des algorithmes d'exploration tels que AGE, tandis que dans le bucket C, nous adoptons le modèle CTR conventionnel sans exploration. Après un certain temps, nous appliquons les données de retour obtenues du bucket C et du bucket D à la formation des modèles déployés sur les buckets équitables A et B respectivement. Enfin, nous comparerons les performances du modèle sur les tranches équitables A et B. Dans les expériences en ligne, nous utilisons plusieurs indicateurs standards pour l'évaluation, notamment le taux de clics (CTR), le nombre d'annonces affichées PV et PCOC, le rapport entre le CTR prévu et le CTR réel. De plus, nous avons introduit une mesure opérationnelle (AFR) pour mesurer la satisfaction des annonceurs.
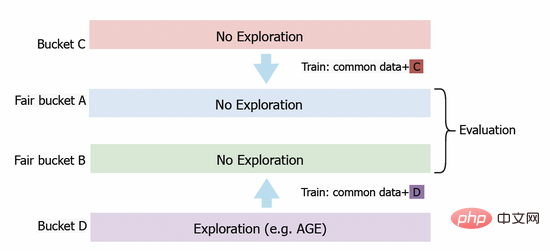
Figure 3 : Plan d'expérimentation du seau équitable
Comme le montre le tableau 3, les indicateurs ci-dessus ont été efficacement améliorés. Parmi elles, AGE surpasse largement toutes les autres méthodes : le CTR et le PV sont respectivement 6,4 % et 3,0 % supérieurs au modèle de référence. Dans le même temps, l'utilisation du modèle AGE améliore également la précision de prédiction du modèle, c'est-à-dire que la précision de prédiction PCOC est plus proche de 1. Plus important encore, l'indicateur AFR s'est également amélioré de 5,5 %, ce qui montre que notre méthode d'exploration peut améliorer efficacement l'expérience des annonceurs.
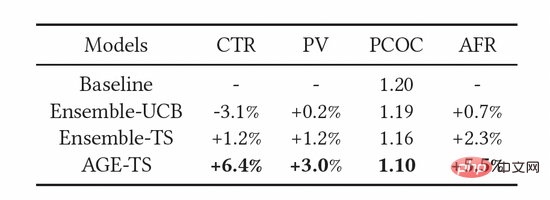
Tableau 3 : Résultats des expériences en ligne
5. Résumé
Contrairement à la plupart des méthodes d'exploration et d'exploitation qui se concentrent sur l'estimation des rendements potentiels, notre approche AGE recadre cela dans une perspective d'apprentissage en ligne basée sur les données. En plus d'estimer l'incertitude de la prédiction du modèle actuel, l'algorithme AGE utilise le module de quasi-exploration pour examiner plus en détail l'impact ultérieur des échantillons d'exploration sur la formation du modèle. Nous avons mené des expériences de tests A/B sur des ensembles de données de recherche universitaire et sur des liens de production, et les résultats pertinents ont confirmé l'efficacité de la méthode AGE. À l’avenir, nous déploierons AGE dans davantage de scénarios d’application.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Comment annuler la suppression de l'écran d'accueil sur iPhone
Apr 17, 2024 pm 07:37 PM
Comment annuler la suppression de l'écran d'accueil sur iPhone
Apr 17, 2024 pm 07:37 PM
Vous avez supprimé quelque chose d'important de votre écran d'accueil et vous essayez de le récupérer ? Vous pouvez remettre les icônes d’applications à l’écran de différentes manières. Nous avons discuté de toutes les méthodes que vous pouvez suivre et remettre l'icône de l'application sur l'écran d'accueil. Comment annuler la suppression de l'écran d'accueil sur iPhone Comme nous l'avons mentionné précédemment, il existe plusieurs façons de restaurer cette modification sur iPhone. Méthode 1 – Remplacer l'icône de l'application dans la bibliothèque d'applications Vous pouvez placer une icône d'application sur votre écran d'accueil directement à partir de la bibliothèque d'applications. Étape 1 – Faites glisser votre doigt sur le côté pour trouver toutes les applications de la bibliothèque d'applications. Étape 2 – Recherchez l'icône de l'application que vous avez supprimée précédemment. Étape 3 – Faites simplement glisser l'icône de l'application de la bibliothèque principale vers le bon emplacement sur l'écran d'accueil. Voici le schéma d'application
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
