
 développement back-end
Tutoriel Python
Démonstration complète du code d'analyse de documents à l'aide de Python et OCR (code ci-joint)
développement back-end
Tutoriel Python
Démonstration complète du code d'analyse de documents à l'aide de Python et OCR (code ci-joint)
Démonstration complète du code d'analyse de documents à l'aide de Python et OCR (code ci-joint)


L'analyse de documents implique l'examen des données contenues dans des documents et l'extraction d'informations utiles. Cela peut réduire beaucoup de travail manuel grâce à l’automatisation. Une stratégie d'analyse populaire consiste à convertir des documents en images et à utiliser la vision par ordinateur pour la reconnaissance. L'analyse d'image de document fait référence à la technologie permettant d'obtenir des informations à partir des données de pixels de l'image d'un document. Dans certains cas, il n'y a pas de réponse claire sur ce que devraient être les résultats attendus (texte, images, graphiques, nombres, tableaux, formules). ..).

OCR (Optical Character Recognition, reconnaissance optique de caractères) est le processus de détection et d'extraction de texte dans les images grâce à la vision par ordinateur. Il a été inventé pendant la Première Guerre mondiale, lorsque le scientifique israélien Emanuel Goldberg a créé une machine capable de lire des caractères et de les convertir en codes télégraphiques. Le domaine a désormais atteint un niveau très sophistiqué, mêlant traitement d’image, localisation de texte, segmentation de caractères et reconnaissance de caractères. Fondamentalement, une technique de détection d'objets pour le texte.
Dans cet article, je vais montrer comment utiliser l'OCR pour l'analyse de documents. Je vais montrer du code Python utile qui peut être facilement utilisé dans d'autres situations similaires (il suffit de copier, coller, exécuter) et fournir un téléchargement complet du code source.
Nous prendrons ici comme exemple les états financiers au format PDF d'une société cotée (lien ci-dessous).
https://s2.q4cdn.com/470004039/files/doc_financials/2021/q4/_10-K-2021-(As-Filed).pdf

Détecter et extraire le texte de ce PDF, Graphiques et tableaux
Paramètres d'environnement
Ce qui est ennuyeux dans l'analyse de documents, c'est qu'il existe de nombreux outils pour différents types de données (texte, graphiques, tableaux) et aucun d'entre eux ne fonctionne parfaitement. Voici quelques-unes des méthodes et packages les plus populaires :
- Traiter les documents sous forme de texte : utilisez PyPDF2 pour extraire du texte, utilisez Camelot ou TabulaPy pour extraire des tableaux et utilisez PyMuPDF pour extraire des graphiques.
- Convertir des documents en images (OCR) : utilisez pdf2image pour la conversion, PyTesseract et de nombreuses autres bibliothèques pour extraire des données, ou utilisez simplement LayoutParser.
Vous demandez peut-être : « Pourquoi ne pas traiter le fichier PDF directement, mais convertir les pages en images ? Vous pouvez le faire ? Le principal inconvénient de cette stratégie est le problème d'encodage : les documents peuvent avoir plusieurs encodages (c'est-à-dire UTF-8, ASCII, Unicode), donc la conversion en texte peut entraîner une perte de données. Donc, pour éviter ce problème, je vais utiliser l'OCR et convertir la page en image avec pdf2image. Notez que la bibliothèque de rendu PDF Poppler est requise.
# with pip pip install python-poppler # with conda conda install -c conda-forge poppler
Vous pouvez lire le fichier facilement :
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a pageExactement comme notre capture d'écran, si vous souhaitez enregistrer l'image de la page localement, vous pouvez utiliser le code suivant :
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1
Enfin, nous devons configurer le moteur de CV que nous allons utiliser. LayoutParser semble être le premier package à usage général pour l'OCR basé sur l'apprentissage profond. Il utilise deux modèles bien connus pour accomplir cette tâche :
Détection : la bibliothèque de détection d'objets la plus avancée de Facebook (la deuxième version Detectron2 sera utilisée ici).
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"
Tesseract : Le système OCR le plus célèbre, créé par Hewlett-Packard en 1985 et actuellement développé par Google.
pip install "layoutparser[ocr]"
Vous êtes maintenant prêt à démarrer le programme OCR pour la détection et l'extraction d'informations.
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt
Détection
La détection (cible) est le processus consistant à trouver des éléments d'information dans une image, puis à les entourer d'une bordure rectangulaire. Pour l'analyse de documents, les informations sont des titres, des textes, des graphiques, des tableaux...
Regardons une page complexe qui contient quelques éléments :
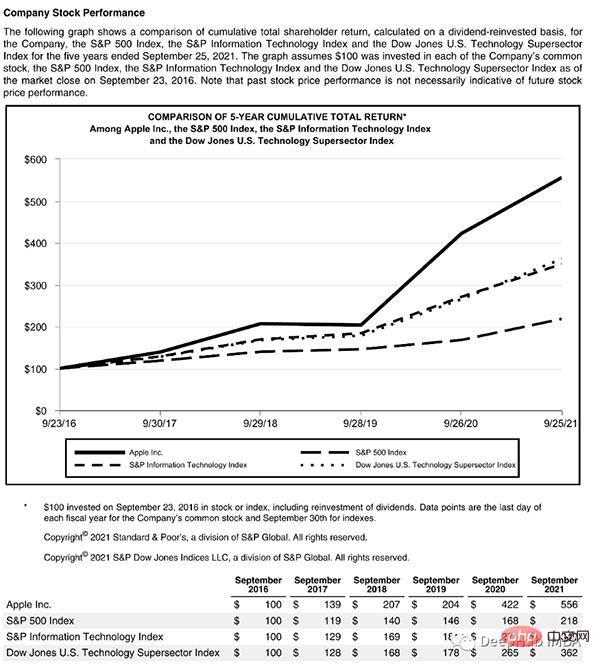
Cette page commence par un titre et comporte un bloc de texte, puis un graphique et un tableau, nous avons donc besoin d'un modèle entraîné pour reconnaître ces objets. Heureusement, Detectron est capable de le faire, il nous suffit de sélectionner un modèle à partir d'ici et de spécifier son chemin dans le code.
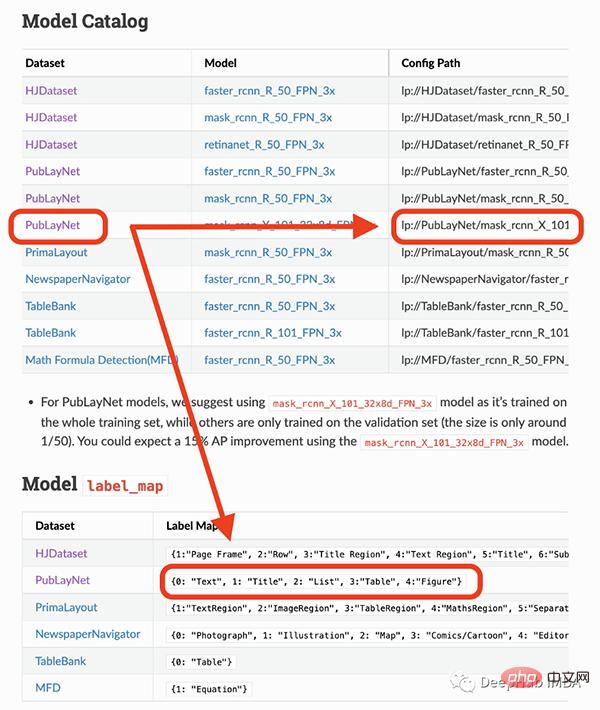
Le modèle que je vais utiliser ne peut détecter que 4 objets (texte, titre, liste, tableau, graphique). Par conséquent, si vous devez identifier d’autres éléments (comme des équations), vous devez utiliser d’autres modèles.
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)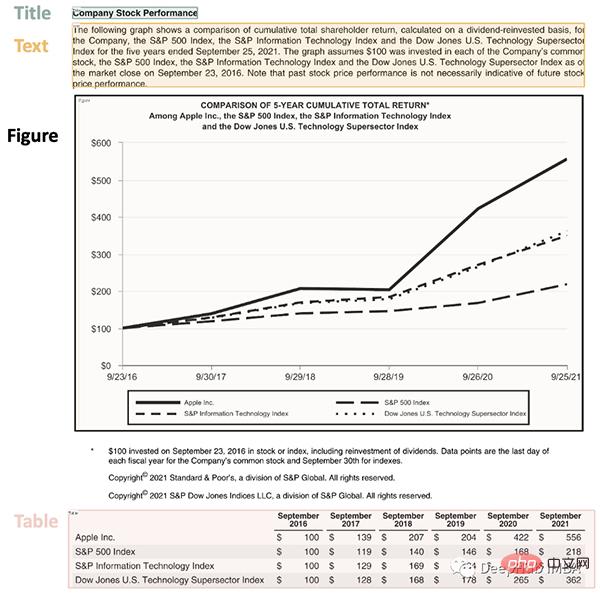
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
提取
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
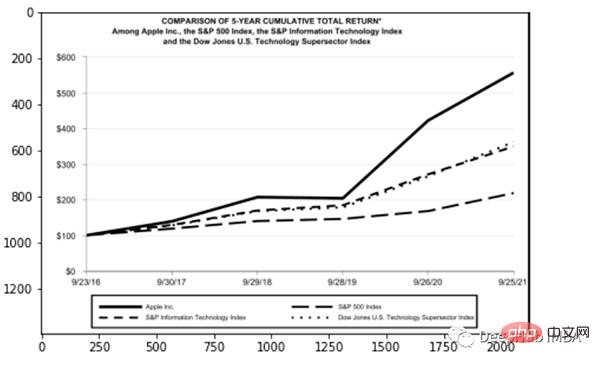
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
总结
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut se connecter à MARIADB, à condition que la configuration soit correcte. Sélectionnez d'abord "MariADB" comme type de connecteur. Dans la configuration de la connexion, définissez correctement l'hôte, le port, l'utilisateur, le mot de passe et la base de données. Lorsque vous testez la connexion, vérifiez que le service MARIADB est démarré, si le nom d'utilisateur et le mot de passe sont corrects, si le numéro de port est correct, si le pare-feu autorise les connexions et si la base de données existe. Dans une utilisation avancée, utilisez la technologie de mise en commun des connexions pour optimiser les performances. Les erreurs courantes incluent des autorisations insuffisantes, des problèmes de connexion réseau, etc. Lors des erreurs de débogage, analysez soigneusement les informations d'erreur et utilisez des outils de débogage. L'optimisation de la configuration du réseau peut améliorer les performances
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comment résoudre MySQL ne peut pas se connecter à l'hôte local
Apr 08, 2025 pm 02:24 PM
Comment résoudre MySQL ne peut pas se connecter à l'hôte local
Apr 08, 2025 pm 02:24 PM
La connexion MySQL peut être due aux raisons suivantes: le service MySQL n'est pas démarré, le pare-feu intercepte la connexion, le numéro de port est incorrect, le nom d'utilisateur ou le mot de passe est incorrect, l'adresse d'écoute dans my.cnf est mal configurée, etc. 2. Ajustez les paramètres du pare-feu pour permettre à MySQL d'écouter le port 3306; 3. Confirmez que le numéro de port est cohérent avec le numéro de port réel; 4. Vérifiez si le nom d'utilisateur et le mot de passe sont corrects; 5. Assurez-vous que les paramètres d'adresse de liaison dans My.cnf sont corrects.
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
