
 Périphériques technologiques
IA
DetectGPT : détection de texte générée par machine sans tir à l'aide d'une courbure probabiliste
Périphériques technologiques
IA
DetectGPT : détection de texte générée par machine sans tir à l'aide d'une courbure probabiliste
DetectGPT : détection de texte générée par machine sans tir à l'aide d'une courbure probabiliste

Le but de DetectGPT est de déterminer si un morceau de texte a été généré par un llm spécifique, tel que GPT-3. Pour classer le paragraphe x, DetectGPT génère d'abord une petite perturbation sur le paragraphe ~xi à l'aide d'un modèle commun pré-entraîné (par exemple, T5). DetectGPT compare ensuite la probabilité logarithmique de l'échantillon d'origine x avec chaque échantillon perturbé ~xi. Si le rapport logarithmique moyen est élevé, l'échantillon provient probablement du modèle source.

ChatGPT est un sujet brûlant. Des discussions sont en cours pour savoir s'il est possible de détecter qu'un article a été généré par un grand modèle de langage (LLM). DetectGPT définit un nouveau critère basé sur la courbure pour juger s'il faut générer à partir d'un LLM donné. DetectGPT ne nécessite pas de formation d'un classificateur distinct, de collecte d'un ensemble de données de passages réels ou générés, ni de filigrane explicite du texte généré. Il utilise uniquement les probabilités logarithmiques calculées par le modèle d'intérêt et les perturbations aléatoires d'article provenant d'un autre modèle de langage pré-entraîné à usage général (par exemple, T5).
1. DetectGPT : permutations et hypothèses aléatoires

identifie et exploite la tendance des canaux générés par la machine x~pθ (à gauche) à se situer dans la région de courbure négative de logp (x), où les échantillons proches ont une moyenne inférieure Probabilité du journal du modèle. En revanche, le texte écrit par l'homme x~preal(.) (à droite) a tendance à ne pas occuper de régions présentant une courbure de log-probabilité négative significative.
DetectGPT est basé sur l'hypothèse selon laquelle les échantillons du modèle source pθ se trouvent généralement dans la région de courbure négative de la fonction de probabilité logarithmique pθ, qui est différente du texte humain. Si nous appliquons une petite perturbation à un morceau de texte x~pθ, donnant ~x, le nombre d'échantillons générés par la machine log pθ(x) - log pθ(~x) devrait être relativement grand par rapport au texte écrit par l'homme. En utilisant cette hypothèse, considérons d'abord une fonction de perturbation q(.|x), qui donne une distribution sur ~x, une version légèrement modifiée de x avec une signification similaire (considérez généralement un texte approximatif de la longueur d'un paragraphe x). Par exemple, q(.|x) pourrait être le résultat de la simple demande à un humain de réécrire l'une des phrases pour x tout en préservant le sens de x. En utilisant le concept de fonction de perturbation, la différence de perturbation d (x; pθ, q) peut être définie :
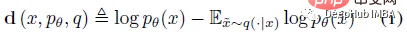
Par conséquent, l'hypothèse suivante 4.1 est :

Si q(.|x ) est Avec des échantillons provenant d'un modèle de remplissage de masque (tel que T5) plutôt que des réécritures humaines, l'hypothèse 4.1 peut alors être testée empiriquement de manière automatisée et évolutive.
2. DetectGPT : Test automatique
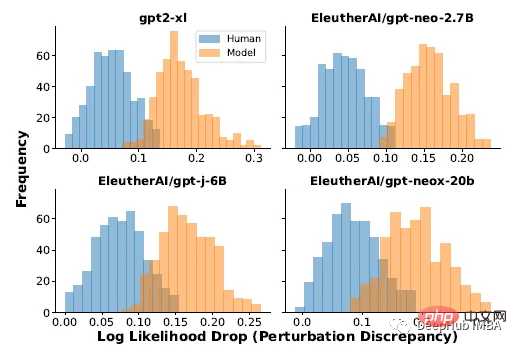
Après la réécriture d'un article, la diminution moyenne de log probabilité (différence de perturbation) des articles générés par le modèle est toujours supérieure à celle des articles écrits manuellement
Pour de vrai data , en utilisant 500 articles de presse de l'ensemble de données XSum. Utilisation de la sortie de quatre llms différents lorsque vous êtes invité à indiquer les 30 premiers jetons de chaque article dans XSum. La perturbation est appliquée à l'aide de T5-3B, masquant une plage de 2 mots échantillonnée au hasard jusqu'à ce que 15 % des mots de l'article soient masqués. L'espérance mathématique de l'équation (1) ci-dessus est approximée par 100 échantillons dans T5.
Les résultats expérimentaux ci-dessus montrent qu'il existe une différence significative dans la distribution des différences de perturbation entre les articles écrits par des humains et les échantillons modèles présentent souvent de grandes différences de perturbation. Sur la base de ces résultats, il est possible de détecter si un morceau de texte a été généré par le modèle p en seuillant simplement la différence de perturbation.
La normalisation des différences de perturbation par l'écart type des observations utilisées pour estimer E~x q(.|x) log p (~x) permet une meilleure détection, augmentant généralement l'AUROC d'environ 0,020, donc dans les expériences Une version normalisée du la différence de perturbation est utilisée dans .

Pseudo-code du processus de détection de DetectGPT
La différence de perturbation peut être utile, ce qu'elle mesure ne peut pas être clairement expliqué, c'est pourquoi l'auteur utilise la courbure pour expliquer dans la section suivante.
3. Interpréter la différence de perturbation comme une courbure
La différence de perturbation est approximativement une mesure de la courbure locale de la fonction de probabilité log à proximité du passage candidat, plus précisément, elle est proportionnelle à la trace négative de la matrice de Hesse du log fonction de probabilité.
Cette section a beaucoup de contenu, je ne l'expliquerai donc pas en détail ici. Si vous êtes intéressé, vous pouvez lire l'article original, qui est grossièrement résumé comme suit :
.L'échantillonnage dans l'espace sémantique garantit que tous les échantillons restent proches du collecteur de données, car la probabilité log devrait toujours diminuer si des marqueurs de perturbation sont ajoutés de manière aléatoire. L'objectif peut donc être interprété comme une contrainte approximative sur la courbure de la variété de données.
4. Affichage des résultats
Détection de texte généré par machine sans tir

Chaque expérience utilise 150 à 500 exemples pour l'évaluation. Le texte généré par la machine est généré en invitant les 30 premiers jetons du texte réel. Utilisez AUROC) pour évaluer les performances.
On peut voir que DetectGPT maximise la précision de détection moyenne des histoires XSum (AUROC amélioré de 0,1) et du contexte Wikipédia SQuAD (AUROC amélioré de 0,05).
Pour 14 combinaisons d'ensembles de données et de modèles sur 15, DetectGPT offre les performances de détection les plus précises, avec une amélioration moyenne de l'AUROC de 0,06.
Comparaison avec des détecteurs supervisés

Un modèle de détection de texte supervisé généré par une machine, formé sur un vaste ensemble de données de texte réel et généré, fonctionne aussi bien que DetectGPT sur du texte en distribution (rangée du haut), ou même mieux. La méthode Zero-shot est appliquée à de nouveaux domaines (rangée du bas) tels que les textes médicaux PubMed et les données d'actualité allemandes dans WMT16.
Évaluée sur 200 échantillons de chaque ensemble de données, les performances de détection du détecteur supervisé sur les données en diffusion telles que les actualités en anglais sont similaires à celles de DetectGPT, mais dans le cas de la rédaction scientifique en anglais, ses performances sont nettement pires que celles du zéro-shot. méthode, alors qu'en écriture allemande, elle échoue complètement.

DetectGPT L'AUROC moyen de GPT-3 est comparable aux modèles supervisés formés spécifiquement pour la détection de texte généré par machine.
150 exemples extraits des ensembles de données PubMedQA, XSum et writingprompt. Deux modèles de détecteurs pré-entraînés basés sur Roberta sont comparés à DetectGPT et à la ligne de base du seuil probabiliste. DetectGPT peut fournir des détections qui rivalisent avec des modèles supervisés plus puissants.
Variation de la détection de texte généré par la machine

Cette partie sert à voir si le détecteur peut détecter le texte généré par la machine modifié par l'homme. La révision manuelle a été simulée en remplaçant 5 mots du texte par des échantillons de T5 à 3B jusqu'à ce que r% du texte soit remplacé. DetectGPT est capable de maintenir la détection AUROC au-dessus de 0,8 même si près d'un quart du texte de l'échantillon modèle a été remplacé. DetectGPT affiche les performances de détection les plus élevées sur tous les niveaux de révision.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Classification d'images avec apprentissage en quelques prises de vue à l'aide de PyTorch
Apr 09, 2023 am 10:51 AM
Classification d'images avec apprentissage en quelques prises de vue à l'aide de PyTorch
Apr 09, 2023 am 10:51 AM
Ces dernières années, les modèles basés sur l’apprentissage profond ont donné de bons résultats dans des tâches telles que la détection d’objets et la reconnaissance d’images. Sur des ensembles de données de classification d'images complexes comme ImageNet, qui contient 1 000 classifications d'objets différentes, certains modèles dépassent désormais les niveaux humains. Mais ces modèles s'appuient sur un processus de formation supervisé, ils sont considérablement affectés par la disponibilité de données de formation étiquetées, et les classes que les modèles sont capables de détecter sont limitées aux classes sur lesquelles ils ont été formés. Puisqu’il n’y a pas suffisamment d’images étiquetées pour toutes les classes pendant la formation, ces modèles peuvent être moins utiles dans des contextes réels. Et nous voulons que le modèle soit capable de reconnaître les classes qu'il n'a pas vues lors de l'entraînement, car il est presque impossible de s'entraîner sur des images de tous les objets potentiels. Nous apprendrons de quelques exemples
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Sep 14, 2023 am 11:57 AM
Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Sep 14, 2023 am 11:57 AM
En janvier 2021, OpenAI a annoncé deux nouveaux modèles : DALL-E et CLIP. Les deux modèles sont des modèles multimodaux qui relient le texte et les images d’une manière ou d’une autre. Le nom complet de CLIP est Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), qui est une méthode de pré-formation basée sur des paires texte-image contrastées. Pourquoi introduire CLIP ? Parce que le StableDiffusion actuellement populaire n'est pas un modèle unique, mais se compose de plusieurs modèles. L'un des composants clés est l'encodeur de texte, qui est utilisé pour encoder la saisie de texte de l'utilisateur. Cet encodeur de texte est l'encodeur de texte CL dans le modèle CLIP.
 La vidéo Google AI est à nouveau géniale ! VideoPrism, un encodeur visuel universel tout-en-un, actualise 30 fonctionnalités de performances SOTA
Feb 26, 2024 am 09:58 AM
La vidéo Google AI est à nouveau géniale ! VideoPrism, un encodeur visuel universel tout-en-un, actualise 30 fonctionnalités de performances SOTA
Feb 26, 2024 am 09:58 AM
Après que le modèle vidéo d'IA Sora soit devenu populaire, de grandes entreprises telles que Meta et Google se sont retirées pour faire des recherches et rattraper OpenAI. Récemment, des chercheurs de l'équipe Google ont proposé un encodeur vidéo universel - VideoPrism. Il peut gérer diverses tâches de compréhension vidéo via un seul modèle figé. Adresse du papier image : https://arxiv.org/pdf/2402.13217.pdf Par exemple, VideoPrism peut classer et localiser la personne qui souffle les bougies dans la vidéo ci-dessous. Récupération d'image vidéo-texte, sur la base du contenu du texte, le contenu correspondant dans la vidéo peut être récupéré. Pour un autre exemple, décrivez la vidéo ci-dessous : une petite fille joue avec des blocs de construction. Des questions et réponses sur l’assurance qualité sont également disponibles.
 Comment diviser correctement un ensemble de données ? Résumé de trois méthodes courantes
Apr 08, 2023 pm 06:51 PM
Comment diviser correctement un ensemble de données ? Résumé de trois méthodes courantes
Apr 08, 2023 pm 06:51 PM
La décomposition de l'ensemble de données en un ensemble d'apprentissage nous aide à comprendre le modèle, ce qui est important pour la façon dont le modèle se généralise à de nouvelles données invisibles. Un modèle peut ne pas se généraliser correctement à de nouvelles données invisibles s'il est surajusté. Il n’est donc pas possible de faire de bonnes prédictions. Avoir une stratégie de validation appropriée est la première étape pour réussir à créer de bonnes prédictions et à utiliser la valeur commerciale des modèles d'IA. Cet article a compilé quelques stratégies courantes de fractionnement des données. Une simple répartition de l'entraînement et des tests divise l'ensemble de données en parties de formation et de validation, avec 80 % de formation et 20 % de validation. Vous pouvez le faire en utilisant l'échantillonnage aléatoire de Scikit. Tout d’abord, la graine aléatoire doit être corrigée, sinon la même répartition des données ne pourra pas être comparée et les résultats ne pourront pas être reproduits pendant le débogage. Si l'ensemble de données
 Exemple de code complet de formation parallèle PyTorch DistributedDataParallel
Apr 10, 2023 pm 08:51 PM
Exemple de code complet de formation parallèle PyTorch DistributedDataParallel
Apr 10, 2023 pm 08:51 PM
Le problème de la formation de grands réseaux de neurones profonds (DNN) à l’aide de grands ensembles de données constitue un défi majeur dans le domaine de l’apprentissage profond. À mesure que la taille des DNN et des ensembles de données augmente, les besoins en calcul et en mémoire pour la formation de ces modèles augmentent également. Cela rend difficile, voire impossible, la formation de ces modèles sur une seule machine avec des ressources informatiques limitées. Certains des défis majeurs liés à la formation de grands DNN à l'aide de grands ensembles de données comprennent : Longue durée de formation : le processus de formation peut prendre des semaines, voire des mois, en fonction de la complexité du modèle et de la taille de l'ensemble de données. Limites de mémoire : les DNN volumineux peuvent nécessiter de grandes quantités de mémoire pour stocker tous les paramètres du modèle, les gradients et les activations intermédiaires pendant l'entraînement. Cela peut provoquer des erreurs de mémoire insuffisante et limiter ce qui peut être entraîné sur une seule machine.
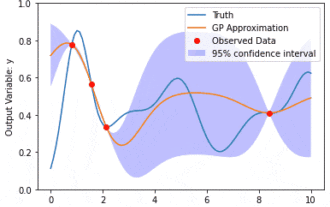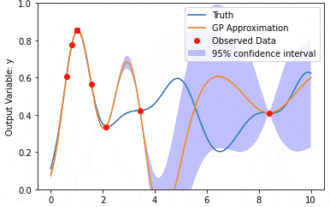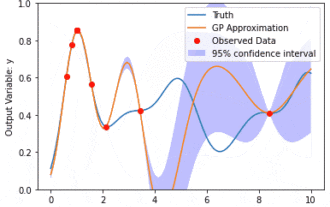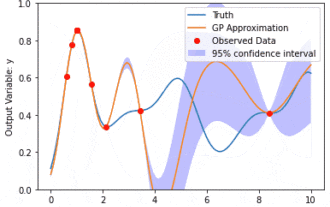 Modélisation des données à l'aide des processus gaussiens du modèle de noyau (KMGP)
Jan 30, 2024 am 11:15 AM
Modélisation des données à l'aide des processus gaussiens du modèle de noyau (KMGP)
Jan 30, 2024 am 11:15 AM
Les processus gaussiens du modèle de noyau (KMGP) sont des outils sophistiqués permettant de gérer la complexité de divers ensembles de données. Il étend le concept des processus gaussiens traditionnels à travers les fonctions du noyau. Cet article discutera en détail de la base théorique, des applications pratiques et des défis des KMGP. Le processus gaussien du modèle de noyau est une extension du processus gaussien traditionnel et est utilisé dans l'apprentissage automatique et les statistiques. Avant de comprendre kmgp, vous devez maîtriser les connaissances de base du processus gaussien, puis comprendre le rôle du modèle de noyau. Processus gaussiens (GP) Les processus gaussiens sont des ensembles de variables aléatoires, avec un nombre fini de variables distribuées conjointement par la distribution gaussienne, et sont utilisés pour définir des distributions de probabilité de fonctions. Les processus gaussiens sont couramment utilisés dans les tâches de régression et de classification en apprentissage automatique et peuvent être utilisés pour ajuster la distribution de probabilité des données. Une caractéristique importante des processus gaussiens est leur capacité à fournir des estimations et des prévisions d'incertitude.
 Calculer le coût carbone de l'intelligence artificielle
Apr 12, 2023 am 08:52 AM
Calculer le coût carbone de l'intelligence artificielle
Apr 12, 2023 am 08:52 AM
Si vous recherchez des sujets intéressants, l’Intelligence Artificielle (IA) ne vous décevra pas. L'intelligence artificielle englobe un ensemble d'algorithmes statistiques puissants et époustouflants qui peuvent jouer aux échecs, déchiffrer une écriture manuscrite bâclée, comprendre la parole, classer des images satellite, et bien plus encore. La disponibilité d’ensembles de données géants pour la formation de modèles d’apprentissage automatique a été l’un des facteurs clés du succès de l’intelligence artificielle. Mais tout ce travail informatique n’est pas gratuit. Certains experts en IA sont de plus en plus préoccupés par les impacts environnementaux associés à la création de nouveaux algorithmes, un débat qui a suscité de nouvelles idées sur la manière de permettre aux machines d'apprendre plus efficacement afin de réduire l'empreinte carbone de l'IA. De retour sur Terre Pour entrer dans les détails, il faut d'abord considérer les milliers de centres de données (disséminés dans le monde) qui traitent nos demandes informatiques 24h/24 et 7j/7.
