
 Périphériques technologiques
IA
Une étude montre que ChatGPT ne donnera pas à OpenAI un avantage durable en tant que premier arrivé
Périphériques technologiques
IA
Une étude montre que ChatGPT ne donnera pas à OpenAI un avantage durable en tant que premier arrivé
Une étude montre que ChatGPT ne donnera pas à OpenAI un avantage durable en tant que premier arrivé


ChatGPT développé par OpenAI est désormais devenu populaire partout dans le monde. Mais de l’avis des experts du secteur, bien que le battage marketing autour de ChatGPT soit raisonnable, ils ne croient pas qu’OpenAI puisse dominer le marché de l’intelligence artificielle avec son avantage de premier arrivé. Au lieu de cela, le succès sur le marché dépendra directement de la qualité et de la quantité de données dont dispose une entreprise technologique, ainsi que de la puissance de calcul dont elle a besoin pour faire fonctionner ses systèmes. Il est peu probable que ce marché soit une situation où le gagnant rafle tout et il est susceptible de se développer de manière plus fragmentée que le cloud computing.
Cet article révélera pourquoi les gens sont enthousiasmés par ChatGPT et expliquera pourquoi l'entrée précoce d'OpenAI dans l'industrie pourrait ne pas apporter un avantage durable en tant que premier arrivé. Les médias de l'industrie et collaborateur de CUBE, Sarbjeet Johal, et John Furrier, co-animateur du studio vidéo SiliconANGLE Media, CUBE, ont analysé et discuté de ce sujet.
Possibilités illimitées d'intelligence artificielle et de traitement du langage naturel
Pour ceux qui n'ont pas utilisé ChatGPT, les capacités de ChatGPT sont incroyables. L'un de ses cas d'utilisation passionnants est celui de Sam Charrington du podcast This Week in ML. Brian Gracely l'a fait sur son podcast Cloudcast, en utilisant ChatGPT pour un épisode intitulé "ChatGPT remplacera-t-il mon travail ?"

Ce que Sam Charrington a fait, c'est d'interviewer ChatGPT à l'aide de ChatGPT, il a simplement donné les invites du système. ChatGPT génère automatiquement des questions, que Sam alimente ensuite ChatGPT pour générer des réponses. Il a ensuite introduit les questions et les réponses dans le générateur d'avatar illustré ci-dessus et l'a accéléré deux fois plus pour que cela ressemble à un humain, ce qui est vraiment incroyable.
Les médias de l'industrie ont d'abord demandé à John Furrier si ChatGPT remplacerait les humains en tant que modérateurs de CUBE et ont demandé l'avis de Sarbjeet Johal, puis ont saisi leurs réponses dans ChatGPT, et ChatGPT a renvoyé les résultats de leurs réponses.
John et Sarbjeet discutent d'un exemple d'utilisation de ChatGPT dans le podcast. Dans ce podcast, ChatGPT est invité à mener une auto-entretien, dont les réponses sont introduites dans un générateur d'avatar et accélérées pour ressembler à une conversation entre deux personnes.
John a déclaré que l'utilisation de ChatGPT peut apporter de la valeur pour des tâches telles que la rédaction de textes marketing, le brainstorming des listes d'invités et la réponse à des questions spécifiques. Cependant, il a admis que les réponses générées par l’IA ne sont pas toujours exactes à 100 % et nécessitent quelques modifications.
Sarbjeet a également mentionné un exemple de chat avec ChatGPT, qui est capable de donner des réponses détaillées sous la forme d'une conversation. Par conséquent, ils pensent tous que même si les modèles d’intelligence artificielle actuels (tels que ChatGPT) démocratisent l’intelligence, ils ne sont pas encore capables de créer une nouvelle intelligence ou d’offrir des avantages concurrentiels dans certains domaines.
ChatGPT sera-t-il l'ère de Netscape ?
Alors qu'en est-il de la loi d'Amara proposée par le futuriste Roy Amara ?

Lorsqu'on a demandé à John et Sarbjeet si ChatGPT adhère également à la loi d'Amala, voici le résumé de ChatGPT de leurs réponses : John et Sarbjeet ont discuté de l'idée de la loi d'Amala, qui stipule : « Les gens ont une tendance générale à surestimer "
Sarbjeet pense que cela est vrai pour ChatGPT, plus les gens l'utilisent et commencent à voir ses limites, plus ils en ressentent l'impact. . D'un autre côté, John estime que ChatGPT est une technologie unique et puissante qui peut être sous-estimée à court terme mais qui dépassera les attentes des gens à long terme.
Il l'a comparé aux débuts d'Internet, où le navigateur Netscape était aussi enfantin qu'il l'était, mais qui a ensuite eu un impact énorme sur la société. Il a noté qu'à court terme, certains experts sont dédaigneux de ChatGPT, mais qu'à long terme, d'autres y voient un changement de donne ; Ils conviennent tous les deux qu’il existe une certaine polarisation autour du battage médiatique ChatGPT.
OpenAI bénéficiera-t-il d'un avantage de premier arrivé grâce à ChatGPT ?
L'entrée précoce d'OpenAI sur le marché donnera-t-elle à l'entreprise un avantage concurrentiel durable, mais le consensus de John et Sarbjeet est : probablement pas.

Tout au long de l'histoire du développement de l'industrie technologique, il existe de nombreux cas où les pionniers ont échoué. Altair, IBM, Tandy, Commodore et Apple ont tous été des pionniers en matière de technologie, mais Dell a émergé quelques années plus tard avec un meilleur modèle commercial.
·Netscape a pris d'assaut la Silicon Valley avec le premier navigateur.
·AltaVista est le premier moteur de recherche à indexer le texte intégral.
·Friendster et MySpace ont précédé Facebook.
·L'iPhone n'était certainement pas le premier appareil mobile.
Il existe de nombreux exemples d'échec, mais il existe également des exemples de réussite, comme AWS dans le domaine du cloud computing, Twitter avec l'avantage du premier arrivé et Bitcoin dans le domaine des crypto-monnaies.
OpenAI réussira-t-il avec ChatGPT ?
Voici ChatGPT résumant leurs réponses :
John et Sarbjeet ont discuté de la question de savoir si l'entrée précoce d'OpenAI sur le marché avec ChatGPT donnerait à l'entreprise un avantage concurrentiel durable. Ils reconnaissent que l'industrie technologique regorge d'exemples de pionniers ratés, tels qu'Altair, IBM, Tandy et Commodore dans le domaine des jeux informatiques, et Friendster et MySpace dans les médias sociaux.
Cependant, ils ont également mentionné quelques réussites récentes, telles que le fournisseur de cloud computing AWS, Twitter, Bitcoin et les smartphones. John pense qu'OpenAI n'apparaîtra peut-être pas sur la liste des pionniers à succès, mais la catégorie d'intelligence artificielle à grande échelle de modèles de langage sur laquelle ils travaillent sera couronnée de succès.
Sarbjeet estime également que la première entrée d'OpenAI sur le marché avec ChatGPT ne donnera pas à l'entreprise un avantage concurrentiel, car Google a recherché des technologies similaires et d'autres entreprises pourraient également participer à la concurrence sur le marché. Il a également souligné que ChatGPT est toujours sujet à des erreurs et que de nombreuses questions subsistent quant à l'origine de son contenu. Il s'agit donc d'une décision risquée pour OpenAI.
Les ordinateurs hyperscale dominent l'intelligence artificielle, vont-ils défier ChatGPT ?
Jetons un coup d'œil à quelques données issues de la recherche sur les technologies d'entreprise, et vous verrez la domination des entreprises hyperscale dans l'intelligence artificielle d'entreprise.
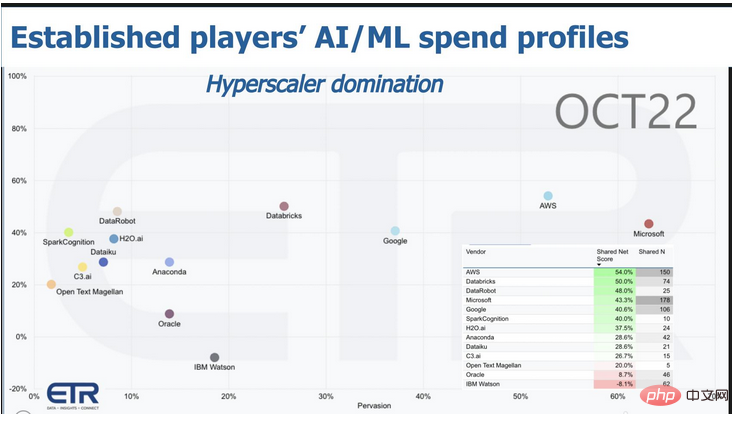
Le graphique ci-dessus montre le score net ou tendance de développement sur l'axe Y, et le taux de pénétration ou part de marché de l'enquête ETR sur l'axe X.
Le point à retenir le plus pertinent est que les hyperscalers dominent. Bien que les trois plus grands fournisseurs mondiaux de cloud computing figurent également sur d'autres listes.
Bien sûr, sur ce marché il existe des experts tels que C3.ai, DataRobot, SparkCognition, H2o.ai, Anaconda, Dataiku, ainsi qu'Oracle et IBM. Mais leur part parmi les acheteurs professionnels est dérisoire en comparaison avec les trois plus grands fournisseurs mondiaux de cloud computing. D'où ce contexte.
Qui gagnera la bataille de l'IA conversationnelle ?
Les grands géants du cloud computing et de l'internet sont prêts à saisir cette opportunité. Microsoft a investi jusqu'à 10 milliards de dollars américains, et Google investit évidemment massivement. Bien sûr, il existe actuellement sur le marché des sociétés comme Apple, Chinchilla, Bloom ou Jasper. Dans le même temps, des gouvernements comme les États-Unis, l’Union européenne et la Chine s’intéressent au développement de ce domaine.
Voici le résumé du sujet par ChatGPT :
John et Sarbjeet ont discuté de la concurrence dans le domaine de l'intelligence artificielle et du traitement du langage naturel, notant que les grandes entreprises technologiques comme Microsoft et Google investissent massivement dans le domaine, comme Chinchilla, Bloom Small. des sociétés comme Jasper sont également des concurrents potentiels. Ils ont également souligné que le rythme du changement technologique est désormais beaucoup plus rapide que par le passé et que le développement en deux ans équivaut à celui des dix dernières années.
Résumé :
L'intelligence artificielle conversationnelle démontrée par ChatGPT aura-t-elle un impact similaire sur le monde Oui, je le crois ? Le langage naturel et les interfaces conversationnelles vont révolutionner la façon dont les gens vivent, travaillent et jouent. Tout comme Amazon a transformé les centres de données en API, ce type de technologie transformera la technologie et de nombreuses tâches en commandes linguistiques.
OpenAI peut-il tirer parti de son avantage de premier arrivé pour créer une domination durable ? C’est une énigme, mais les panélistes pensent que c’est peu probable ? Ils soulignent qu’il y a trop de forces en jeu entre les grands géants de l’Internet, la réglementation gouvernementale et les investissements massifs qui seront investis dans ce secteur.
L'histoire du développement de l'industrie technologique montre qu'une ou plusieurs entreprises émergeront qui perturberont le marché et domineront le marché, mais les sociétés de capital-risque peuvent également refuser d'y investir parce qu'elles ne correspondent pas au modèle d'investissement sûr.
Peut-être que quelqu'un pourra déchiffrer son mot de passe. Quoi qu’il en soit, OpenAI a libéré le génie dans la bouteille, et il n’y a aucune chance qu’il revienne.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
