
 Périphériques technologiques
IA
Nouveau travail de Jeff Dean et d'autres : en regardant les modèles de langage sous un autre angle, l'échelle n'est pas assez grande et ne peut pas être découverte
Périphériques technologiques
IA
Nouveau travail de Jeff Dean et d'autres : en regardant les modèles de langage sous un autre angle, l'échelle n'est pas assez grande et ne peut pas être découverte
Nouveau travail de Jeff Dean et d'autres : en regardant les modèles de langage sous un autre angle, l'échelle n'est pas assez grande et ne peut pas être découverte

Ces dernières années, les modèles linguistiques ont eu un impact révolutionnaire sur le traitement du langage naturel (NLP). Il est connu que l’extension des modèles de langage, tels que les paramètres, peut conduire à de meilleures performances et à une meilleure efficacité des échantillons sur une gamme de tâches NLP en aval. Dans de nombreux cas, l’impact de la mise à l’échelle sur les performances peut souvent être prédit par les lois de mise à l’échelle, et la plupart des chercheurs ont étudié des phénomènes prévisibles.
Au contraire, 16 chercheurs dont Jeff Dean, Percy Liang, etc. ont collaboré à l'article "Emergent Abilities of Large Language Models". Ils ont discuté du phénomène d'imprévisibilité des grands modèles et l'ont appelé l'émergence de grands modèles de langage. . Capacités émergentes. Ce qu'on appelle l'émergence signifie que certains phénomènes n'existent pas dans le modèle plus petit mais existent dans le modèle plus grand. Ils pensent que cette capacité du modèle est émergente.
L'émergence en tant qu'idée est discutée depuis longtemps dans des domaines tels que la physique, la biologie et l'informatique. Cet article commence par une définition générale de l'émergence, adaptée des recherches de Steinhardt et ancrée dans 1972. Un article intitulé Plus. Is Different du prix Nobel et physicien Philip Anderson.
Cet article explore l'émergence de la taille du modèle, mesurée par les calculs d'entraînement et les paramètres du modèle. Plus précisément, cet article définit les capacités émergentes des grands modèles de langage comme des capacités qui ne sont pas présentes dans les modèles à petite échelle mais sont présentes dans les modèles à grande échelle ; par conséquent, les modèles à grande échelle ne peuvent pas être prédits en extrapolant simplement les améliorations de performances des modèles à petite échelle ; maquettes . Cette étude examine les capacités émergentes des modèles observés dans une série de travaux antérieurs et les classe en paramètres tels que le repérage à petite échelle et le repérage amélioré.
Cette capacité émergente du modèle inspire les recherches futures sur les raisons pour lesquelles ces capacités sont acquises et si des échelles plus grandes acquièrent davantage de capacités émergentes, et souligne l'importance de cette recherche.

Adresse papier : https://arxiv.org/pdf/2206.07682.pdf
Petit exemple de tâche d'incitation
Cet article discute d'abord de la capacité émergente dans le paradigme d'incitation. Par exemple, dans l'invite GPT-3, étant donné une invite de tâche de modèle de langage pré-entraînée, le modèle peut compléter la réponse sans formation supplémentaire ni mise à jour progressive des paramètres. De plus, Brown et al. La figure 1 montre un exemple d'invite.
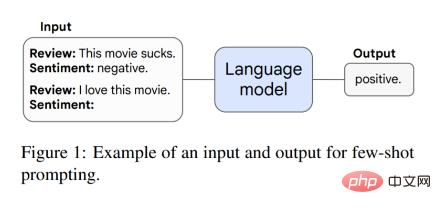

Lorsque le modèle a des performances stochastiques et a une certaine échelle, il peut effectuer des tâches via de petits exemples d'invites. À ce moment, la capacité émergente apparaîtra, et les performances du modèle seront alors beaucoup plus élevées que. performances aléatoires. La figure ci-dessous montre les 8 capacités émergentes de 5 séries de modèles de langage (LaMDA, GPT-3, Gopher, Chinchilla et PaLM).

BIG-Bench : les figures 2A-D représentent quatre tâches d'invite émergentes en quelques étapes de BIG-Bench, une suite de plus de 200 critères d'évaluation de modèles de langage. La figure 2A montre un test arithmétique qui teste l'addition et la soustraction de nombres à 3 chiffres et la multiplication de nombres à 2 chiffres. Le tableau 1 donne les fonctionnalités les plus émergentes de BIG-Bench.

Stratégie de pourboire améliorée
Actuellement, bien que les indices sur petits échantillons soient le moyen le plus courant d'interagir avec de grands modèles de langage, des travaux récents ont proposé plusieurs autres indices et stratégies de réglage fin pour améliorer davantage les capacités des modèles de langage. Cet article considère également qu’une technologie est une capacité émergente si elle ne montre aucune amélioration ou si elle est nuisible avant d’être appliquée à un modèle suffisamment grand.
Raisonnement en plusieurs étapes : les tâches de raisonnement, en particulier celles impliquant un raisonnement en plusieurs étapes, ont toujours été un grand défi pour les modèles de langage et les modèles PNL. Une stratégie d'incitation récente appelée chaîne de pensée permet aux modèles de langage de résoudre ce type de problème en les guidant pour générer une série d'étapes intermédiaires avant de donner une réponse finale. Comme le montre la figure 3A, lors de la mise à l'échelle jusqu'à 1 023 FLOP d'entraînement (environ 100 B de paramètres), l'invite de la chaîne de pensée n'a surpassé que l'invite standard, sans étapes intermédiaires.
Instruction (Instruction suivante) : Comme le montre la figure 3B, Wei et al. ont constaté que lorsque le FLOP d'entraînement est de 7·10^21 (paramètres 8B) ou moins, la technique de réglage fin des instructions nuira aux performances du modèle. les performances peuvent être améliorées en étendant les FLOP d'entraînement à 10 ^ 23 (~ 100B de paramètres).
Exécution du programme : comme le montre la figure 3C, dans l'évaluation dans le domaine de l'addition de 8 bits, l'utilisation du bloc-notes ne permet que ∼9 · 10^19 FLOP d'entraînement (paramètres 40 M) ou un modèle plus grand. La figure 3D montre que ces modèles peuvent également se généraliser à l'addition de 9 bits hors domaine, qui se produit dans ∼1,3 · 10 ^ 20 FLOP d'entraînement (100 millions de paramètres).

Cet article traite de la puissance émergente des modèles de langage, où jusqu'à présent des performances significatives n'ont été observées qu'à certaines échelles de calcul. Cette capacité émergente des modèles peut couvrir une variété de modèles de langage, de types de tâches et de scénarios expérimentaux. L’existence de cette émergence signifie qu’une mise à l’échelle supplémentaire peut étendre davantage les capacités des modèles linguistiques. Cette capacité est le résultat d’extensions de modèles de langage récemment découvertes. La manière dont elles sont apparues et la question de savoir si davantage d’extensions apporteront davantage de capacités émergentes pourraient être d’importantes orientations de recherche futures dans le domaine du PNL.
Pour plus d'informations, veuillez vous référer au document original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
