

Pourquoi Go a-t-il un modèle de planification GMP ? L'article suivant vous présentera les raisons pour lesquelles il existe un modèle de planification GMP dans le langage Go. J'espère qu'il vous sera utile !

Le modèle de planification GMP est l'essence même de Go. Il résout raisonnablement le problème d'efficacité des coroutines de planification simultanées multithread.
Tout d'abord, nous devons comprendre à quoi fait référence chaque GMP.
Les threads M détiennent chacun un processeur P. Quand ils veulent obtenir des coroutines Quand il. est obtenu, il est obtenu à partir de P en premier, donc le diagramme du modèle GMP est le suivant :
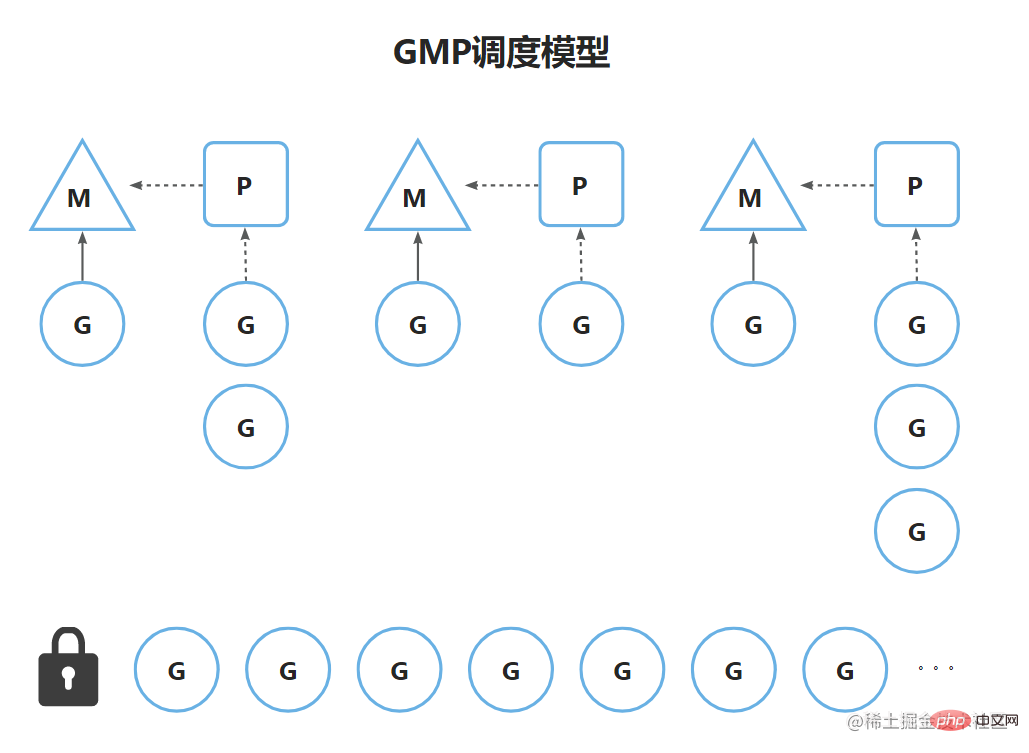
Le processus général est que le thread M obtient la coroutine de la file d'attente de P S'il ne peut pas l'obtenir, il sera en compétition pour le verrou. de la file d'attente globale pour l'obtenir.
La structure de la coroutine G et du thread M a été expliquée dans les articles précédents. Voici une analyse du processeur P.
Le processeur P stocke un lot de coroutines, de sorte que le thread M puisse en obtenir des coroutines sans verrouillage, sans avoir à rivaliser avec d'autres threads pour les coroutines dans la file d'attente globale, améliorant ainsi l'efficacité de la planification des coroutines.
p Le code source de la structure se trouve dans srcruntimeruntime2.go, certains champs importants sont affichés ici. srcruntimeruntime2.go中,这里展示部分重要字段。
type p struct {
...
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
...
}m为处理器p所属的线程runq是一个储存协程的队列runqhead,runqtail表示队列的头尾指针runnext指向下一个可运行的协程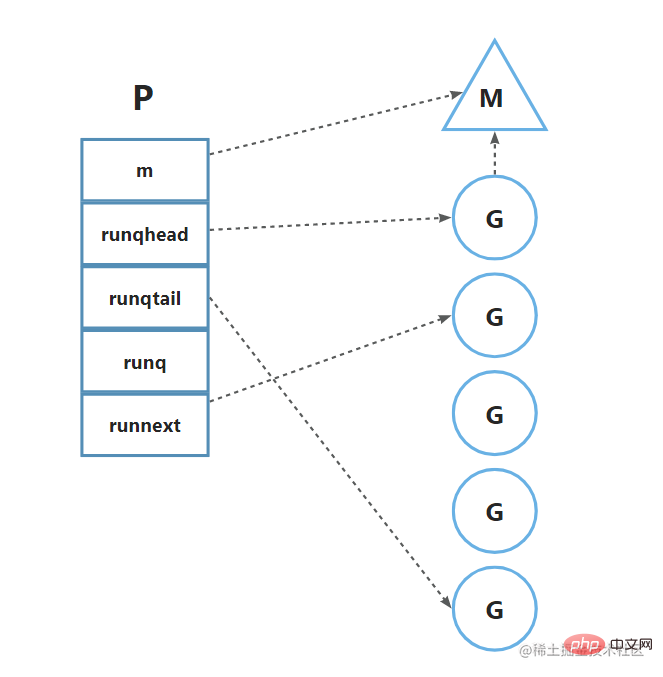
在srcruntimeproc.go中,有一个schedule方法,这是线程运行的第一个函数。这函数中,线程需要获取到可运行的协程,代码如下:
func schedule() {
...
// 寻找一个可运行的协程
gp, inheritTime, tryWakeP := findRunnable()
...
}func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
// 从本地队列中获取协程
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}
// 本地队列拿不到则从全局队列中获取协程
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
}从本地队列中获取协程
func runqget(pp *p) (gp *g, inheritTime bool) {
next := pp.runnext // 队列中下一个可运行的协程
if next != 0 && pp.runnext.cas(next, 0) {
return next.ptr(), true
}
...
}那如果本地队列和全局队列中都没有协程了怎么办呢,难道就让线程这么闲着?
这时候处理器P就会任务窃取,从其他线程的本地队列中窃取一些任务,美其名曰分担其他线程的压力,还提高了自己线程的利用率。
源码在srcruntimeproc.gostealWork中,感兴趣可以看看。
新建的协程该分配到本地还是全局队列呢,得分情况:
实际流程为:
runnext中,意味着下一个就运行该协程,插队了源码在srcruntimeproc.gonewproc
// Create a new g running fn.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc) // 创建新协程
pp := getg().m.p.ptr()
runqput(pp, newg, true) // 寻找本地队列放入
if mainStarted {
wakep()
}
})
}m est le thread auquel appartient le processeur p runq est une file d'attente qui stocke les coroutines runqhead, <code>runqtail représente les pointeurs de tête et de queue de la file d'attente
runnext pointe vers la prochaine coroutine exécutable

srcruntimeproc.go, il existe une méthode schedule, qui est la première fonction exécutée par le thread. Dans cette fonction, le thread doit obtenir une coroutine exécutable. Le code est le suivant : 🎜rrreeerrreee🎜Obtenir la coroutine de la file d'attente locale🎜rrreee🎜Et s'il n'y a pas de coroutines dans la file d'attente locale et la file d'attente globale, est-ce possible ? laisser Le fil est-il si inactif ? 🎜🎜À ce stade, le processeur P volera des tâches et volera certaines tâches des files d'attente locales d'autres threads. C'est ce qu'on appelle partager la pression d'autres threads et améliorer l'utilisation de ses propres threads. 🎜🎜Le code source est dans srcruntimeproc.gostealWork, vous pouvez y jeter un œil si vous êtes intéressé. 🎜runnext de P, ce qui signifie que la coroutine sera exécutée ensuite et que la file d'attente sera sautée🎜 🎜Si la coroutine de P est pleine, elle sera mise dans la file d'attente globale🎜srcruntimeproc.gonewproc. 🎜rrreee🎜🎜Conclusion🎜🎜🎜Cet article présente initialement le modèle de planification GMP et présente spécifiquement comment le processeur P et le thread M obtiennent des coroutines. 🎜🎜Le processeur P résout le problème de l'exclusion mutuelle multithread pour obtenir des coroutines et améliore l'efficacité de la planification des coroutines. Cependant, peu importe que les coroutines soient dans des files d'attente locales ou globales, il semble qu'elles ne soient exécutées que de manière séquentielle. implémenter des coroutines de manière asynchrone ? Qu'en est-il de l'exécution simultanée ? Poursuivons l'analyse dans le prochain article (même si personne ne le lira...). 🎜🎜Apprentissage recommandé : 🎜Tutoriel Golang🎜🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Python est-il front-end ou back-end ?
Python est-il front-end ou back-end ?
 La différence entre front-end et back-end
La différence entre front-end et back-end
 Introduction au contenu principal du travail du backend
Introduction au contenu principal du travail du backend
 Utilisation du cordon
Utilisation du cordon
 Outils de téléchargement et d'installation Linux courants
Outils de téléchargement et d'installation Linux courants
 le démarrage d'Apache a échoué
le démarrage d'Apache a échoué
 qu'est-ce que Hadoop
qu'est-ce que Hadoop
 Tutoriel sur la structure des données et l'algorithme
Tutoriel sur la structure des données et l'algorithme
 Définir l'imprimante par défaut
Définir l'imprimante par défaut




![Démarrez rapidement avec le framework Golang Gin [Utilisez Gin pour créer un système de messagerie instantanée simultanée de niveau million]](https://img.php.cn/upload/course/000/000/068/63a2b21046723283.jpg)








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



