
 Périphériques technologiques
IA
L'apprentissage automatique alimente une ingénierie logicielle de haute qualité
Périphériques technologiques
IA
L'apprentissage automatique alimente une ingénierie logicielle de haute qualité
L'apprentissage automatique alimente une ingénierie logicielle de haute qualité

Traducteur | Zhu Xianzhong
Reviewer | Sun Shujuan
Introduction
De manière générale, les tests logiciels sont souvent relativement simples : chaque entrée => sortie connue. Cependant, tout au long de l’histoire des tests logiciels, vous constaterez que de nombreux tests restent souvent au niveau des conjectures. En d'autres termes, lors des tests, le développeur imagine le processus de fonctionnement de l'utilisateur, estime la charge possible et analyse le temps que cela prendra, puis exécute le test et compare les résultats actuels avec la réponse de base. Si nous constatons qu’il n’y a pas de régression, alors le plan de build actuel est considéré comme correct, alors continuez les tests suivants ; S'il y a une régression, renvoyez-la. La plupart du temps, nous connaissons déjà le résultat, même s’il doit être mieux défini – les limites de la régression sont claires et pas si floues. En fait, c’est là qu’interviennent les systèmes d’apprentissage automatique (ML) et d’analyse prédictive, mettant fin à l’ambiguïté.
Une fois le test terminé, l'ingénieur de performance ne regarde pas seulement la moyenne arithmétique et la moyenne géométrique des résultats, il examine également les données en pourcentage pertinentes. Par exemple, lorsque le système est en cours d'exécution, 10 % des requêtes les plus lentes sont souvent causées par des erreurs système. Cette erreur créera une condition qui affecte toujours la vitesse du programme.
Bien que nous puissions associer manuellement les attributs disponibles dans les données, ML peut lier les attributs de données plus rapidement que vous. Après avoir identifié les conditions à l'origine de 10 % des requêtes incorrectes, les ingénieurs performances peuvent créer des scénarios de test pour reproduire le comportement. L'exécution de tests avant et après un correctif peut aider à confirmer que le correctif a été corrigé.

Figure 1 : Confiance globale dans les indicateurs de performance
Performance de l'apprentissage automatique et de la science des données
L'apprentissage automatique aide à promouvoir le développement de logiciels et à rendre la technologie de développement en question plus forte et plus conviviale dans les besoins différents domaines et industries. Nous pouvons exposer des modèles de causalité en alimentant les données des pipelines et des environnements dans des algorithmes d'apprentissage profond. Les algorithmes d'analyse prédictive combinés aux méthodes d'ingénierie des performances permettent un débit plus efficace et plus rapide, obtiennent des informations sur la manière dont les utilisateurs finaux utilisent les logiciels dans des scénarios naturels et aident les développeurs à réduire la probabilité que des produits défectueux soient utilisés dans des environnements de production. En identifiant les problèmes et leurs causes dès le début, vous pouvez les corriger dès le début du cycle de développement et éviter tout impact sur la production. Dans l’ensemble, voici quelques façons d’exploiter l’analyse prédictive pour améliorer les performances des applications.
- Déterminez la cause profonde. Vous pouvez utiliser des techniques d'apprentissage automatique pour déterminer la cause première des problèmes de disponibilité ou de performances afin de vous concentrer sur d'autres domaines qui nécessitent une attention particulière. L'analyse prédictive peut ensuite analyser diverses caractéristiques de chaque cluster, fournissant ainsi un aperçu des changements que nous devons apporter pour atteindre des performances idéales et éviter les goulots d'étranglement.
- Surveillez la santé des applications. L'utilisation de la technologie d'apprentissage automatique pour effectuer une surveillance des applications en temps réel aide les entreprises à détecter à temps la dégradation des performances du système et à réagir rapidement. La plupart des applications s'appuient sur plusieurs services pour obtenir l'état de l'application complète ; les modèles d'analyse prédictive sont capables de corréler et d'analyser les données lorsque l'application s'exécute normalement pour identifier si les données entrantes constituent une valeur aberrante.
- Prédire la charge des utilisateurs. Nous comptons sur le trafic utilisateur de pointe pour faire évoluer notre infrastructure afin de répondre au nombre d'utilisateurs accédant à l'application à l'avenir. Cette approche présente des limites car elle ne tient pas compte des changements ou d'autres facteurs inconnus. L'analyse prédictive permet de visualiser la charge des utilisateurs et de mieux préparer la réponse, aidant ainsi les équipes à planifier leurs besoins en infrastructure et l'utilisation de leurs capacités.
- Prévoyez les pannes avant qu'il ne soit trop tard. Prédire les temps d'arrêt ou les pannes des applications avant qu'ils ne surviennent aidera à prendre des mesures préventives. Les modèles d'analyse prédictive suivront les scénarios de pannes précédents et continueront à surveiller des situations similaires pour prédire les pannes futures.
- Arrêtez de regarder les seuils et commencez à analyser les données. Les quantités massives de données générées par l'observabilité et la surveillance nécessitent jusqu'à plusieurs centaines de mégaoctets par semaine. Même avec des outils d’analyse modernes, vous devez savoir à l’avance ce que vous recherchez. Cela a pour conséquence que les équipes n’examinent pas directement les données, mais fixent plutôt des seuils comme déclencheurs d’action. Même les équipes matures recherchent des exceptions au lieu de fouiller dans leurs données. Pour atténuer cela, nous intégrons le modèle aux sources de données disponibles. Le modèle filtre ensuite les données et calcule des seuils au fil du temps. Grâce à cette technique, le modèle est alimenté et agrégé de données historiques, fournissant des seuils basés sur la saisonnalité plutôt que fixés par les humains. La définition de seuils basés sur des algorithmes permet de déclencher moins d'alertes, mais cela conduit également à une meilleure actionnabilité et à une valeur plus élevée.
- Analysez et corrélez les ensembles de données. Vos données sont principalement des séries chronologiques, il est donc plus facile de voir les variables individuelles évoluer au fil du temps. De nombreuses tendances résultent de l’interaction de plusieurs mesures. Par exemple, le temps de réponse ne diminuera que si plusieurs transactions se déroulent simultanément sur la même cible. Pour les humains, c’est presque impossible, mais des algorithmes correctement entraînés peuvent aider à découvrir ces corrélations.
L'importance des données dans l'analyse prédictive
Le « Big Data » fait généralement référence à un ensemble de données. Oui, il s’agit d’un grand ensemble de données, la vitesse augmente rapidement et le contenu change considérablement. L’analyse de ces données nécessite des méthodes spécialisées afin que nous puissions en extraire des modèles et des informations. Ces dernières années, les améliorations apportées au stockage, aux processeurs, au parallélisme des processus et à la conception des algorithmes ont permis aux systèmes de traiter de grandes quantités de données dans un délai raisonnable, permettant ainsi une utilisation plus large de ces méthodes. Pour obtenir des résultats significatifs, vous devez assurer la cohérence des données.
Par exemple, chaque projet doit utiliser le même système de classement, donc si un projet utilise 1 comme valeur clé et qu'un autre utilise 5 - tout comme lorsque les gens utilisent "DEFCON 5" pour signifier "DEFCON 1" ; alors les valeurs doit être normalisé avant le traitement. Les algorithmes prédictifs se composent d’algorithmes et des données qu’ils alimentent, et le développement de logiciels génère de grandes quantités de données qui, jusqu’à récemment, restaient inutilisées, attendant d’être supprimées. Cependant, les algorithmes d'analyse prédictive peuvent traiter ces fichiers pour poser et répondre à des questions basées sur ces données pour des modèles que nous ne pouvons pas détecter, tels que :
- Perdons-nous du temps à tester des scénarios inutilisés ?
- Quel est le lien entre les améliorations des performances et le bonheur des utilisateurs ?
- Combien de temps faut-il pour réparer un défaut spécifique ?
Ces questions et leurs réponses correspondent à la vocation de l'analyse prédictive : mieux comprendre ce qui est susceptible de se produire.
Algorithme
Un autre élément majeur de l'analyse prédictive est l'algorithme que vous devez choisir ou mettre en œuvre avec soin. Il est crucial de commencer simplement, car les modèles ont tendance à devenir de plus en plus complexes, de plus en plus sensibles aux modifications des données d'entrée et à fausser potentiellement les prévisions. Ils peuvent résoudre deux types de problèmes : la classification et la régression (voir Figure 2).
- Classification : La classification est utilisée pour prédire le résultat d'une collection en divisant la collection en différentes catégories en commençant par déduire des étiquettes (telles que « bas » ou « haut ») à partir des données d'entrée.
- Régression : La régression est utilisée pour prédire le résultat d'un ensemble lorsque la variable de sortie est un ensemble de valeurs réelles. Il traitera les données d'entrée pour faire des prédictions - par exemple, la quantité de mémoire utilisée, les lignes de code écrites par les développeurs, etc. Les modèles de prédiction les plus couramment utilisés sont les réseaux de neurones, les arbres de décision et la régression linéaire et logistique.
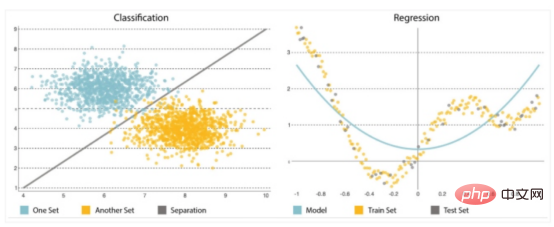
Figure 2 : Classification et régression
Réseau de neurones
Les réseaux de neurones apprennent par des exemples et utilisent des données historiques et des données actuelles pour prédire les valeurs futures. Leur architecture leur permet d’identifier des relations complexes cachées dans les données, reproduisant ainsi la façon dont notre cerveau détecte des modèles. Ils se composent de nombreuses couches qui acceptent les données, calculent des prédictions et fournissent le résultat sous la forme d’une prédiction unique.
Arbre de décision
Un arbre de décision est une méthode analytique qui présente les résultats dans une série d'options « si/alors » pour prédire les risques et les avantages potentiels d'une option spécifique. Il peut résoudre tous les problèmes de classification et répondre à des questions complexes.
Comme le montre la figure 3, un arbre de décision est similaire à un arbre descendant généré par un algorithme capable d'identifier différentes manières de diviser les données en partitions en forme de branche pour illustrer les décisions futures et aider à identifier le chemin des décisions.
Si le chargement prend plus de trois secondes, une branche dans l'arborescence peut être celle d'un utilisateur qui a abandonné son panier. En dessous, une autre branche peut indiquer s’il s’agit de femelles. Une réponse « oui » fait monter les enjeux, car l'analyse montre que les femmes sont plus susceptibles de faire des achats impulsifs, et ce retard peut conduire à la rumination.
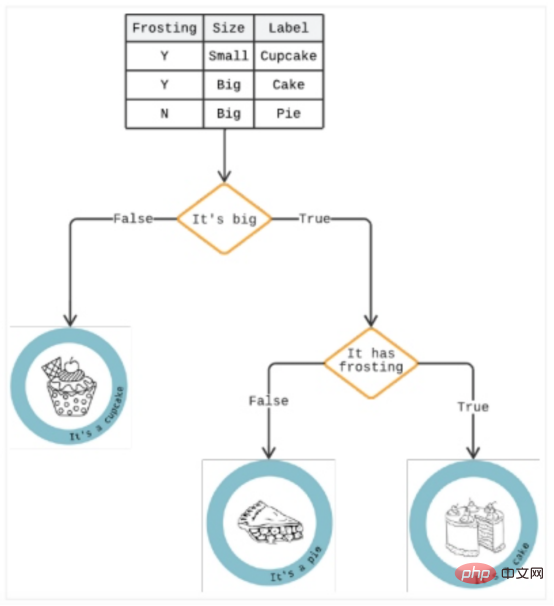
Figure 3 : Exemple d'arbre de décision
Régression linéaire et logistique
La régression est l'une des méthodes statistiques les plus populaires. Ceci est crucial lors de l’estimation des chiffres, tels que le nombre de ressources supplémentaires que nous devons ajouter à chaque service lors de la vente du Black Friday. De nombreux algorithmes de régression sont conçus pour estimer les relations entre les variables et trouver des modèles clés dans des ensembles de données vastes et mixtes, ainsi que les relations entre elles. Cela va des simples modèles de régression linéaire (calcul d'une fonction droite qui s'adapte aux données) à la régression logistique (calcul d'une courbe) (Figure 4).
Régression linéaire et logistiqueComparaison globale | |
| Régression linéaire |
Régression logistique |
est utilisée pour définir des valeurs dans une plage continue, comme le risque de pics de trafic d'utilisateurs dans les prochains mois. |
Il s'agit d'une méthode statistique où les paramètres sont prédits sur la base d'anciens ensembles. Cela fonctionne mieux pour la classification binaire : ensembles de données avec y=0 ou 1, où 1 représente la classe par défaut différente. Son nom vient de sa fonction de conversion ( est une fonction logique ) . |
Il est représenté par y=a+bx, où x est l'ensemble d'entrées utilisé pour déterminer la sortie y. Les coefficients a et b sont utilisés pour quantifier la relation entre x et y, où a est l'ordonnée à l'origine et b est la pente de la droite. |
Il est représenté par la fonction logistique : où , β0 est l'interception, β 1 est le tarif . Il utilise les données d'entraînement pour calculer des coefficients qui minimisent l'erreur entre les résultats prévus et réels. |
L'objectif est d'ajuster la ligne droite la plus proche de la plupart des points, réduisant ainsi la distance ou l'erreur entre y et la ligne droite. |
Il forme une courbe en forme de S où un seuil est appliqué pour convertir les probabilités en classifications binaires. |
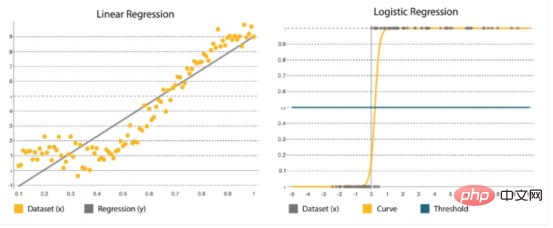
Figure 4 : Régression linéaire vs régression logistique
Il s'agit de méthodes d'apprentissage supervisé car l'algorithme résout des propriétés spécifiques. L'apprentissage non supervisé est utilisé lorsque vous n'avez pas de résultat spécifique en tête, mais que vous souhaitez identifier des modèles ou des tendances possibles. Dans ce cas, le modèle analyse autant de combinaisons de caractéristiques que possible pour trouver des corrélations sur lesquelles les humains peuvent agir.
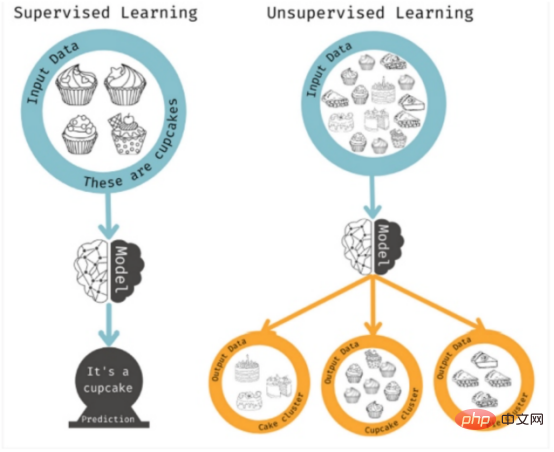
Figure 5 : Apprentissage supervisé ou non supervisé
« Shift Left » dans l'ingénierie de la performance
L'utilisation d'algorithmes précédents pour mesurer les perceptions des consommateurs à l'égard des produits et des applications rend l'ingénierie de la performance plus centrée sur le consommateur. Une fois toutes les informations collectées, elles doivent être stockées et analysées grâce à des outils et algorithmes appropriés. Ces données peuvent inclure des journaux d'erreurs, des scénarios de test, des résultats de tests, des événements de production, des fichiers journaux d'application, des documents de projet, des journaux d'événements, des traces, etc. Nous pouvons ensuite appliquer cela aux données pour obtenir diverses informations :
- Analyser les défauts de l'environnement
- Évaluer l'impact sur l'expérience client
- Identifier les modèles de problèmes
- Créer des tests plus précis scénarios et plus encore
Cette technologie prend en charge une approche de la qualité axée sur la gauche, vous permettant de prédire le temps qu'il faudra pour effectuer les tests de performance, le nombre de défauts pouvant être identifiés et le nombre de défauts pouvant en résulter. en production, obtenant ainsi une meilleure couverture des tests de performances et créant une expérience utilisateur réaliste. Les problèmes d’utilisabilité, de compatibilité, de performances et de sécurité peuvent être évités et corrigés sans impact sur les utilisateurs.
Voici quelques exemples des types d'informations qui peuvent contribuer à améliorer la qualité :
- Type de défaut
- À quel stade le défaut a été découvert
- Quelle est la cause première du défaut
- Défaut Est-il reproductible
Une fois que vous savez cela, vous pouvez apporter des modifications et créer des tests pour éviter des problèmes similaires plus rapidement.
Conclusion
Les ingénieurs logiciels ont fait des centaines d'hypothèses depuis l'aube de la programmation. Mais les utilisateurs numériques d’aujourd’hui en sont plus conscients et moins tolérants aux erreurs et aux échecs. D’un autre côté, les entreprises s’efforcent également d’offrir des expériences utilisateur plus attrayantes et plus raffinées grâce à des services sur mesure et à des logiciels complexes de plus en plus difficiles à tester.
Aujourd'hui, tout doit fonctionner de manière transparente et prendre en charge tous les navigateurs, appareils mobiles et applications populaires. Un accident de quelques minutes peut causer des milliers, voire des millions de dollars de dégâts. Pour éviter que des problèmes ne surviennent, les équipes doivent intégrer des solutions d'observabilité et l'expérience utilisateur tout au long du cycle de vie du logiciel. La gestion de la qualité et des performances de systèmes complexes nécessite bien plus que la simple exécution de scénarios de test et de tests de charge. Les tendances peuvent vous aider à déterminer si une situation est sous contrôle, s’améliore ou se détériore, et à quelle vitesse. La technologie d'apprentissage automatique peut aider à prédire les problèmes de performances afin que les équipes puissent apporter des ajustements correctifs. Enfin, concluons en citant une citation de Benjamin Franklin : "Mieux vaut prévenir que guérir." une université de Weifang et un vétéran de l'industrie de la programmation indépendante.
Titre original :Performance Engineering Powered by Machine Learning
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 Quatre outils de programmation assistés par IA recommandés
Apr 22, 2024 pm 05:34 PM
Quatre outils de programmation assistés par IA recommandés
Apr 22, 2024 pm 05:34 PM
Cet outil de programmation assistée par l'IA a mis au jour un grand nombre d'outils de programmation assistée par l'IA utiles à cette étape de développement rapide de l'IA. Les outils de programmation assistés par l'IA peuvent améliorer l'efficacité du développement, améliorer la qualité du code et réduire les taux de bogues. Ils constituent des assistants importants dans le processus de développement logiciel moderne. Aujourd'hui, Dayao partagera avec vous 4 outils de programmation assistés par l'IA (et tous prennent en charge le langage C#). J'espère que cela sera utile à tout le monde. https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot est un assistant de codage IA qui vous aide à écrire du code plus rapidement et avec moins d'effort, afin que vous puissiez vous concentrer davantage sur la résolution de problèmes et la collaboration. Git
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
