
 développement back-end
Tutoriel Python
J'ai compilé plusieurs expressions régulières Python, vous pouvez les prendre et les utiliser !
développement back-end
Tutoriel Python
J'ai compilé plusieurs expressions régulières Python, vous pouvez les prendre et les utiliser !
J'ai compilé plusieurs expressions régulières Python, vous pouvez les prendre et les utiliser !


Les expressions régulières peuvent être utilisées pour rechercher, modifier et manipuler du texte. Python RegEx est largement utilisé par presque toutes les entreprises et présente un bon attrait pour leurs applications, ce qui rend les expressions régulières de plus en plus importantes.
Aujourd'hui, nous allons apprendre ensemble les expressions régulières Python.
Pourquoi utiliser des expressions régulières.
Pour répondre à cette question, examinons d’abord les différents problèmes auxquels nous sommes confrontés et qui peuvent être résolus en utilisant des expressions régulières.
Considérez le scénario suivant :
À la fin de l'article, il y a un fichier journal contenant une grande quantité de données. À partir de ce fichier journal, nous espérons obtenir uniquement la date et l'heure. À première vue, la lisibilité du fichier journal est très faible.

Dans ce cas, les expressions régulières peuvent être utilisées pour identifier des modèles et extraire facilement les informations requises.
Considérez le scénario suivant : vous êtes un vendeur et avez beaucoup d'adresses e-mail, beaucoup d'entre elles sont fausses/invalides, regardez l'image ci-dessous :

Ce que nous pouvons faire, c'est utiliser une formule d'expressions régulières qui peut vérifier le format des adresses e-mail et filtrer les fausses pièces d'identité des vraies pièces d'identité.
Le scénario suivant est très similaire à celui de l'exemple du vendeur, considérons l'image suivante :

Comment valider un numéro de téléphone puis le classer en fonction du pays d'origine ?
Chaque numéro correct aura un modèle spécifique qui peut être suivi et suivi à l'aide d'expressions régulières.
Ensuite, un autre scénario simple :
Nous avons une base de données sur les étudiants avec des détails tels que le nom, l'âge et l'adresse. Imaginons une situation dans laquelle le code de district était à l'origine 59006 mais a maintenant été remplacé par 59076, une situation dans laquelle la mise à jour manuelle de ce code pour chaque élève prendrait beaucoup de temps et le processus serait très long.
Fondamentalement, pour résoudre ces problèmes à l'aide d'expressions régulières, nous trouvons d'abord une chaîne spécifique à partir des données de l'élève contenant les codes PIN, puis nous les remplaçons toutes par la nouvelle chaîne.
Que sont les expressions régulières
Les expressions régulières sont utilisées pour identifier les modèles de recherche dans les chaînes de texte. Cela aide également à déterminer l'exactitude des données. Vous pouvez même utiliser des expressions régulières pour rechercher, remplacer, formater des données, etc.
Considérons l'exemple suivant :

Parmi toutes les données d'une chaîne donnée, en supposant que nous n'avons besoin que de la ville, celle-ci peut être convertie de manière formatée en un dictionnaire contenant uniquement le nom et la ville. La question est maintenant : pouvons-nous identifier un modèle pour deviner les noms et les villes ? On peut aussi connaître l'âge, en vieillissant, c'est facile, non ? C'est juste un entier.
Que fait-on de ce nom ? Si vous regardez le modèle, tous les noms commencent par une lettre majuscule. À l'aide d'expressions régulières, nous pouvons identifier les noms et les âges en utilisant cette méthode.
Nous pouvons utiliser le code suivant
import re
Nameage = '''
Janice is 22 and Theon is 33
Gabriel is 44 and Joey is 21
'''
ages = re.findall(r'd{1,3}', Nameage)
names = re.findall(r'[A-Z][a-z]*',Nameage)
ageDict = {}
x = 0
for eachname in names
ageDict[eachname] = ages[x]
x+=1
print(ageDict)Sortie :
{'Janice': '22', 'Theon': '33', 'Gabriel': '44', 'Joey': '21'}Quelques exemples d'expressions régulières :
De nombreuses opérations peuvent être effectuées à l'aide d'expressions régulières. Ici, j'ai répertorié quelques éléments très importants pour vous aider à mieux comprendre l'utilisation des expressions régulières.
Voyons d'abord comment trouver un mot spécifique dans une chaîne
Trouver un mot dans une chaîne
import re
if re.search("inform","we need to inform him with the latest information"):
print("There is inform")Tout ce que nous faisons ici est de rechercher si le mot informer est présent dans notre chaîne de recherche.
Bien sûr on peut aussi optimiser le code suivant
import re
allinform = re.findall("inform","We need to inform him with the latest information!")
for i in allinform:
print(i)Ici, dans ce cas particulier, l'infor sera trouvée deux fois. L’un vient de l’information et l’autre de l’information.
Comme indiqué ci-dessus, trouver des mots dans des expressions régulières est aussi simple que cela.
Ensuite, nous apprendrons comment générer des itérateurs à l'aide d'expressions régulières.
Générer des itérateurs
Générer des itérateurs est le processus simple de recherche et de ciblage des indices de début et de fin d'une chaîne. Prenons l'exemple suivant :
import re
Str = "we need to inform him with the latest information"
for i in re.finditer("inform.", Str
locTuple = i.span()
print(locTuple)Pour chaque correspondance trouvée, les indices de début et de fin sont imprimés. Lorsque nous exécutons le programme ci-dessus, le résultat est le suivant :
(11, 18) (38, 45)
Ensuite, nous vérifierons comment faire correspondre des mots avec des modèles à l'aide d'expressions régulières.
将单词与模式匹配
考虑一个输入字符串,我们必须将某些单词与该字符串匹配。要详细说明,请查看以下示例代码:
import re
Str = "Sat, hat, mat, pat"
allStr = re.findall("[shmp]at", Str)
for i in allStr:
print(i)字符串中有什么共同点?可以看到字母“a”和“t”在所有输入字符串中都很常见。代码中的 [shmp] 表示要查找的单词的首字母,因此,任何以字母 s、h、m 或 p 开头的子字符串都将被视为匹配,其中任何一个,并且最后必须跟在“at”后面。
Output:
hat mat pat
接下来我们将检查如何使用正则表达式一次匹配一系列字符。
匹配一系列字符范围
我们希望输出第一个字母应该在 h 和 m 之间并且必须紧跟 at 的所有单词。看看下面的例子,我们应该得到的输出是 hat 和 mat
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[h-m]at", Str)
for i in someStr:
print(i)Output:
hat mat
现在让我们稍微改变一下上面的程序以获得一个不同的结果
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[^h-m]at", Str)
for i in someStr:
print(i)发现细微差别了吗,我们在正则表达式中添加了插入符号 (^),它的作用否定了它所遵循的任何效果。我们不会给出从 h 到 m 开始的所有内容的输出,而是会向我们展示除此之外的所有内容的输出。
我们可以预期的输出是不以 h 和 m 之间的字母开头但最后仍然紧随其后的单词。Output:
sat pat
替换字符串:
接下来,我们可以使用正则表达式检查另一个操作,其中我们将字符串中的一项替换为其他内容:
import re
Food = "hat rat mat pat"
regex = re.compile("[r]at")
Food = regex.sub("food", Food)
print(Food)在上面的示例中,单词 rat 被替换为单词 food。正则表达式的替代方法就是利用这种情况,它也有各种各样的实际用例。Output:
hat food mat pat
反斜杠问题
import re randstr = "Here is Edureka" print(randstr)
Output:
Here is Edureka
这就是反斜杠问题,其中一个斜线从输出中消失了,这个特殊问题可以使用正则表达式来解决。
import re randstr = "Here is Edureka" print(re.search(r"Edureka", randstr))
Output:
<re.Match object; span=(8, 16), match='Edureka'>
这就是使用正则表达式解决反斜杠问题的简单方法。
匹配单个字符
使用正则表达式可以轻松地单独匹配字符串中的单个字符
import re
randstr = "12345"
print("Matches: ", len(re.findall("d{5}", randstr)))Output:
Matches: 1
删除换行符
我们可以在 Python 中使用正则表达式轻松删除换行符
import re
randstr = '''
You Never
Walk Alone
Liverpool FC
'''
print(randstr)
regex = re.compile("
")
randstr = regex.sub(" ", randstr)
print(randstr)Output:
You Never Walk Alone Liverpool FC You Never Walk Alone Liverpool FC
可以从上面的输出中看到,新行已被空格替换,并且输出打印在一行上。
还可以使用许多其他东西,具体取决于要替换字符串的内容
: Backspace : Formfeed : Carriage Return : Tab : Vertical Tab
可以使用如下代码
import re
randstr = "12345"
print("Matches:", len(re.findall("d", randstr)))Output:
Matches: 5
从上面的输出可以看出,d 匹配字符串中存在的整数。但是,如果我们用 D 替换它,它将匹配除整数之外的所有内容,与 d 完全相反。
接下来我们了解一些在 Python 中使用正则表达式的重要实际例子。
正则表达式的实际例子
我们将检查使用最为广泛的 3 个主要用例
- 电话号码验证
- 电子邮件地址验证
- 网页抓取
电话号码验证
需要在任何相关场景中轻松验证电话号码
考虑以下电话号码:
- 444-122-1234
- 123-122-78999
- 111-123-23
- 67-7890-2019
电话号码的一般格式如下:
- 以 3 位数字和“-”符号开头
- 3 个中间数字和“-”号
- 最后4位数
我们将在下面的示例中使用 w,请注意 w = [a-zA-Z0-9_]
import re
phn = "412-555-1212"
if re.search("w{3}-w{3}-w{4}", phn):
print("Valid phone number")Output:
Valid phone number
电子邮件验证
在任何情况下验证电子邮件地址的有效性。
考虑以下电子邮件地址示例:
- Anirudh@gmail.com
- Anirudh@com
- AC.com
- 123 @.com
我们只需一眼就可以从无效的邮件 ID 中识别出有效的邮件 ID,但是当我们的程序为我们做这件事时,却并没有那么容易,但是使用正则,就非常简单了。
指导思路,所有电子邮件地址应包括:
- 1 到 20 个小写和/或大写字母、数字以及 . _ % +
- 一个@符号
- 2 到 20 个小写和大写字母、数字和加号
- 一个点号
- 2 到 3 个小写和大写字母
import re
email = "ac@aol.com md@.com @seo.com dc@.com"
print("Email Matches: ", len(re.findall("[w._%+-]{1,20}@[w.-]{2,20}.[A-Za-z]{2,3}", email)))Output:
Email Matches: 1
从上面的输出可以看出,我们输入的 4 封电子邮件中有一封有效的邮件。
这基本上证明了使用正则表达式并实际使用它们是多么简单和高效。
网页抓取
从网站上删除所有电话号码以满足需求。
要了解网络抓取,请查看下图:
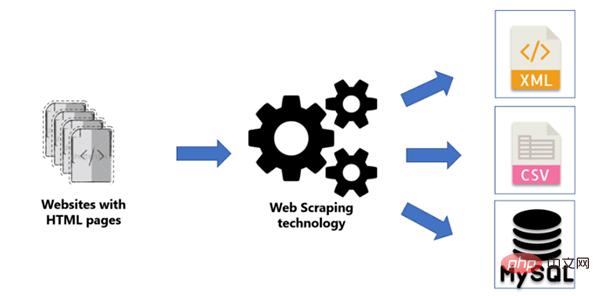
我们已经知道,一个网站将由多个网页组成,我们需要从这些页面中抓取一些信息。
网页抓取主要用于从网站中提取信息,可以将提取的信息以 XML、CSV 甚至 MySQL 数据库的形式保存,这可以通过使用 Python 正则表达式轻松实现。
import urllib.request
from re import findall
url = "http://www.summet.com/dmsi/html/codesamples/addresses.html"
response = urllib.request.urlopen(url)
html = response.read()
htmlStr = html.decode()
pdata = findall("(d{3}) d{3}-d{4}", htmlStr)
for item in pdata:
print(item)Output:
(257) 563-7401 (372) 587-2335 (786) 713-8616 (793) 151-6230 (492) 709-6392 (654) 393-5734 (404) 960-3807 (314) 244-6306 (947) 278-5929 (684) 579-1879 (389) 737-2852 ...
我们首先是通过导入执行网络抓取所需的包,最终结果包括作为使用正则表达式完成网络抓取的结果而提取的电话号码。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python convient plus aux débutants, avec une courbe d'apprentissage en douceur et une syntaxe concise; JavaScript convient au développement frontal, avec une courbe d'apprentissage abrupte et une syntaxe flexible. 1. La syntaxe Python est intuitive et adaptée à la science des données et au développement back-end. 2. JavaScript est flexible et largement utilisé dans la programmation frontale et côté serveur.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP est originaire en 1994 et a été développé par Rasmuslerdorf. Il a été utilisé à l'origine pour suivre les visiteurs du site Web et a progressivement évolué en un langage de script côté serveur et a été largement utilisé dans le développement Web. Python a été développé par Guidovan Rossum à la fin des années 1980 et a été publié pour la première fois en 1991. Il met l'accent sur la lisibilité et la simplicité du code, et convient à l'informatique scientifique, à l'analyse des données et à d'autres domaines.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
