
 développement back-end
Tutoriel Python
Trente fonctions Python résolvent 99% des tâches de traitement de données !
développement back-end
Tutoriel Python
Trente fonctions Python résolvent 99% des tâches de traitement de données !
Trente fonctions Python résolvent 99% des tâches de traitement de données !


Nous savons que Pandas est la bibliothèque d'analyse et de manipulation de données la plus utilisée en Python. Il fournit de nombreuses fonctions et méthodes pour résoudre rapidement les problèmes de traitement des données lors de l'analyse des données.
Afin de mieux maîtriser l'utilisation des fonctions Python, j'ai pris comme exemple l'ensemble de données de désabonnement des clients pour partager les 30 fonctions et méthodes les plus couramment utilisées dans le processus d'analyse des données. Les données peuvent être téléchargées à la fin de l'article. .
Les données ressemblent à ceci :
import numpy as np
import pandas as pd
df = pd.read_csv("Churn_Modelling.csv")
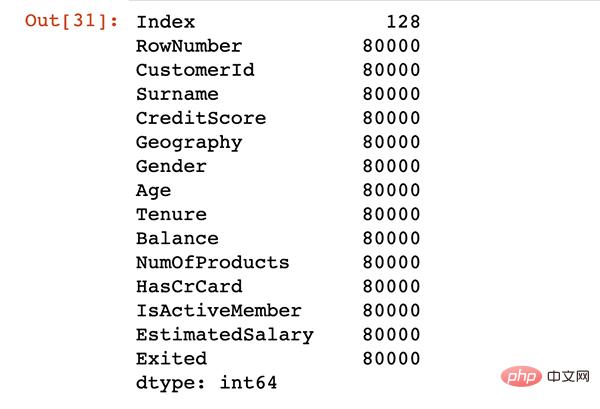
print(df.shape)
df.columns
Sortie du résultat
(10000, 14) Index(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography','Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard','IsActiveMember', 'EstimatedSalary', 'Exited'],dtype='object')
1. Supprimer les colonnes
df.drop(['RowNumber', 'CustomerId', 'Surname', 'CreditScore'], axis=1, inplace=True) print(df[:2]) print(df.shape)
Sortie du résultat
Description : Le paramètre "axis" est défini sur 1 pour placer des colonnes et sur 0 pour placer des lignes. Définissez le paramètre "inplace=True" sur True pour enregistrer les modifications. Nous avons soustrait 4 colonnes, le nombre de colonnes a donc été réduit de 14 à 10.
GeographyGenderAgeTenureBalanceNumOfProductsHasCrCard 0FranceFemale 42 20.011 IsActiveMemberEstimatedSalaryExited 0 1101348.88 1 (10000, 10)
2.Sélectionnez des colonnes spécifiques
Nous lisons les données de colonnes partielles à partir du fichier csv. Le paramètre usecols peut être utilisé.
df_spec = pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_spec.head()
3.nrows
Vous pouvez utiliser le paramètre nrows pour créer un bloc de données contenant les 5000 premières lignes du fichier csv. Vous pouvez également utiliser le paramètre skiprows pour sélectionner des lignes à partir de la fin du fichier. Skiprows=5000 signifie que nous sauterons les 5000 premières lignes lors de la lecture du fichier csv.
df_partial = pd.read_csv("Churn_Modelling.csv", nrows=5000)
print(df_partial.shape)
4. Échantillon
Après avoir créé le bloc de données, nous aurons peut-être besoin d'un petit échantillon pour tester les données. Nous pouvons utiliser le paramètre n ou frac pour déterminer la taille de l'échantillon.
df= pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_sample = df.sample(n=1000)
df_sample2 = df.sample(frac=0.1)
5. Vérifier les valeurs manquantes
La fonction isna détermine les valeurs manquantes dans un bloc de données. En utilisant isna avec la fonction somme, nous pouvons voir le nombre de valeurs manquantes dans chaque colonne.
df.isna().sum()
6. Utilisez loc et iloc pour ajouter les valeurs manquantes
Utilisez loc et iloc pour ajouter les valeurs manquantes :
- loc : Sélectionnez avec l'étiquette
- iloc : Sélectionnez l'index .
Nous créons d’abord 20 index aléatoires à sélectionner.
missing_index = np.random.randint(10000, size=20)
Nous utiliserons loc pour changer certaines valeurs en np.nan (valeurs manquantes).
df.loc[missing_index, ['Balance','Geography']] = np.nan
Il manque 20 valeurs dans les colonnes "Solde" et "Géographie". Faisons un autre exemple en utilisant iloc.
df.iloc[missing_index, -1] = np.nan
7. Remplir les valeurs manquantes
La fonction fillna est utilisée pour remplir les valeurs manquantes. Il offre de nombreuses options. Nous pouvons utiliser une valeur spécifique, une fonction agrégée telle que la moyenne, ou la valeur précédente ou suivante.
avg = df['Balance'].mean() df['Balance'].fillna(value=avg, inplace=True)
Le paramètre méthode de la fonction fillna peut être utilisé pour remplir les valeurs manquantes en fonction de la valeur précédente ou suivante dans la colonne (par exemple, method="ffill"). Cela peut être très utile pour les données séquentielles telles que les séries chronologiques.
8. Supprimer les valeurs manquantes
Une autre façon de gérer les valeurs manquantes consiste à les supprimer. Le code suivant supprimera les lignes contenant les valeurs manquantes.
df.dropna(axis=0, how='any', inplace=True)
9. Sélectionnez des lignes en fonction des conditions
Dans certains cas, nous avons besoin d'observations (c'est-à-dire des lignes) qui correspondent à certaines conditions
france_churn = df[(df.Geography == 'France') & (df.Exited == 1)] france_churn.Geography.value_counts()
10 Décrire les conditions avec des requêtes
Les fonctions de requête offrent une méthode de livraison conditionnelle plus flexible. Nous pouvons les décrire à l'aide de chaînes.
df2 = df.query('80000 < Balance < 100000')
df2 = df.query('80000 < Balance < 100000'
df2 = df.query('80000 < Balance < 100000')
11. Utilisez isin pour décrire la condition
La condition peut avoir plusieurs valeurs. Dans ce cas, il est préférable d'utiliser la méthode isin au lieu d'écrire les valeurs individuellement.
df[df['Tenure'].isin([4,6,9,10])][:3]

12. Fonction Groupby
La fonction Pandas Groupby est une fonction polyvalente et facile à utiliser qui vous aide à obtenir un aperçu de vos données. Cela facilite l’exploration des ensembles de données et révèle les relations sous-jacentes entre les variables.
Nous ferons plusieurs exemples de fonctions de rapport de groupe. Commençons simplement. Le code suivant regroupera les lignes en fonction de la combinaison Géographie, Genre puis donnera le flux moyen de chaque groupe
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).mean()
13.Groupby combiné avec des fonctions d'agrégation
La fonction agg permet d'appliquer plusieurs fonctions d'agrégation sur le groupe, la liste des les fonctions sont comme le passage de paramètres.
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).agg(['mean','count'])
14. Appliquer différentes fonctions d'agrégation à différents groupes
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg({'Exited':'sum', 'Balance':'mean'})
df_summary.rename(columns={'Exited':'# of churned customers', 'Balance':'Average Balance of Customers'},inplace=True)
De plus, la "fonction NamedAgg" permet de renommer les colonnes de l'agrégat
import pandas as pd
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg(Number_of_churned_customers = pd.NamedAgg('Exited', 'sum'),Average_balance_of_customers = pd.NamedAgg('Balance', 'mean'))
print(df_summary)

15. format de données. Nous pouvons changer cela en réinitialisant l'index.
print(df_summary.reset_index())
 16. Réinitialiser et supprimer l'index d'origine
16. Réinitialiser et supprimer l'index d'origine
Dans certains cas, nous devons réinitialiser l'index et supprimer l'index d'origine en même temps.
df[['Geography','Exited','Balance']].sample(n=6).reset_index(drop=True)
17. Définir une colonne spécifique comme index
Nous pouvons définir n'importe quelle colonne du dataframe comme index.
df_new.set_index('Geography')
18. Insérez une nouvelle colonne
group = np.random.randint(10, size=6) df_new['Group'] = group
19 où la fonction
Elle est utilisée pour remplacer la valeur dans une ligne ou une colonne en fonction d'une condition. La valeur de remplacement par défaut est NaN, mais nous pouvons également spécifier une valeur de remplacement.
df_new['Balance'] = df_new['Balance'].where(df_new['Group'] >= 6, 0)
20. Fonction de classement
La fonction de classement attribue un classement à une valeur. Créons une colonne qui classe les clients en fonction de leur solde.
df_new['rank'] = df_new['Balance'].rank(method='first', ascending=False).astype('int')
21. Nombre de valeurs uniques dans une colonne
C'est pratique lorsque vous travaillez avec des variables catégorielles. Nous devrons peut-être vérifier le nombre de catégories uniques. Nous pouvons vérifier la taille de la séquence renvoyée par la fonction value count ou utiliser la fonction nunique.
df.Geography.nunique
22. Utilisation de la mémoire
En utilisant la fonction memory_usage, ces valeurs affichent la mémoire en octets.
df.memory_usage()
23.数据类型转换
默认情况下,分类数据与对象数据类型一起存储。但是,它可能会导致不必要的内存使用,尤其是当分类变量具有较低的基数。
低基数意味着列与行数相比几乎没有唯一值。例如,地理列具有 3 个唯一值和 10000 行。
我们可以通过将其数据类型更改为"类别"来节省内存。
df['Geography'] = df['Geography'].astype('category')
24.替换值
替换函数可用于替换数据帧中的值。
df['Geography'].replace({0:'B1',1:'B2'})
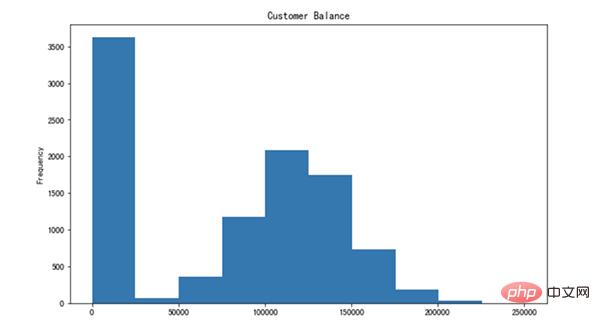
25.绘制直方图
pandas 不是一个数据可视化库,但它使得创建基本绘图变得非常简单。
我发现使用 Pandas 创建基本绘图更容易,而不是使用其他数据可视化库。
让我们创建平衡列的直方图。
26.减少浮点数小数点
pandas 可能会为浮点数显示过多的小数点。我们可以轻松地调整它。
df['Balance'].plot(kind='hist', figsize=(10,6), title='Customer Balance')
27.更改显示选项
我们可以更改各种参数的默认显示选项,而不是每次手动调整显示选项。
- get_option:返回当前选项
- set_option:更改选项 让我们将小数点的显示选项更改为 2。
pd.set_option("display.precision", 2)
可能要更改的一些其他选项包括:
- max_colwidth:列中显示的最大字符数
- max_columns:要显示的最大列数
- max_rows:要显示的最大行数
28.通过列计算百分比变化
pct_change用于计算序列中值的变化百分比。在计算时间序列或元素顺序数组中更改的百分比时,它很有用。
ser= pd.Series([2,4,5,6,72,4,6,72]) ser.pct_change()
29.基于字符串的筛选
我们可能需要根据文本数据(如客户名称)筛选观测值(行)。我已经在数据帧中添加了df_new名称。
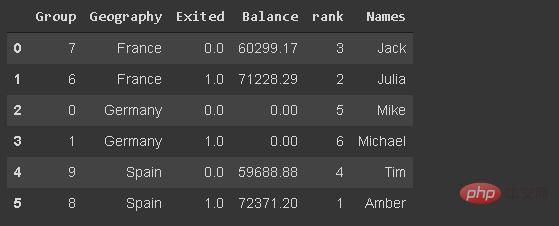
df_new[df_new.Names.str.startswith('Mi')]
我们可能需要根据文本数据(如客户名称)筛选观测值(行)。我已经在数据帧中添加了df_new名称。

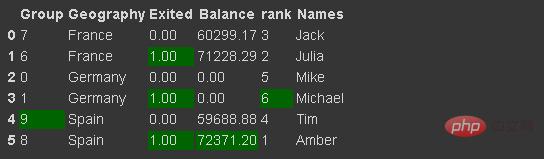
30.设置数据样式
我们可以通过使用返回 Style 对象的 Style 属性来实现此目的,它提供了许多用于格式化和显示数据框的选项。例如,我们可以突出显示最小值或最大值。
它还允许应用自定义样式函数。
df_new.style.highlight_max(axis=0, color='darkgreen')
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
