
 développement back-end
Tutoriel Python
Optimisation des performances Python du point de vue du compilateur
développement back-end
Tutoriel Python
Optimisation des performances Python du point de vue du compilateur
Optimisation des performances Python du point de vue du compilateur

"La vie est courte, il faut du python" !
Les codeurs vétérans aiment vraiment l'élégance de Python. Cependant, dans un environnement de production, les fonctionnalités de langage dynamiques comme Python qui ne sont pas construites avec la performance comme priorité peuvent être dangereuses. Par conséquent, les bibliothèques hautes performances populaires telles que TensorFlow ou PyTorch sont principalement utilisées. python En tant que langage d'interface, utilisé pour interagir avec des bibliothèques C/C++ optimisées.
Il existe de nombreuses façons d'optimiser les performances des programmes Python. Du point de vue du compilateur, les hautes performances peuvent être compilées dans un langage de niveau inférieur analysable statiquement, tel que C ou C++, avec une surcharge d'exécution inférieure du code machine natif. lui permettant d'être comparable en performances à C/C++.
Codon peut être considéré comme un tel compilateur, tirant parti d'une compilation anticipée, d'une vérification de type bidirectionnelle spécialisée et d'une nouvelle représentation intermédiaire bidirectionnelle pour activer des extensions facultatives spécifiques à un domaine dans la syntaxe du langage et des optimisations du compilateur. Il permet aux programmeurs professionnels d'écrire du code hautes performances de manière intuitive, de haut niveau et familière.
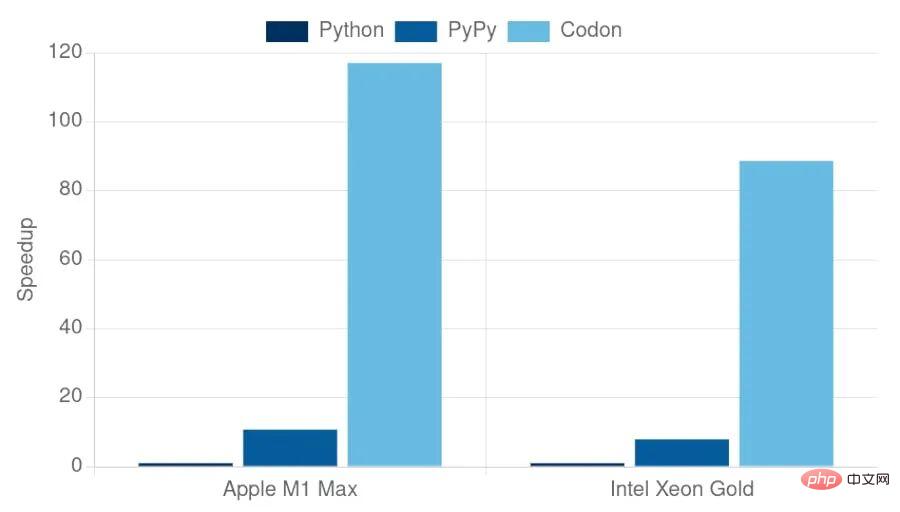
Contrairement à d'autres implémentations Python orientées performances (telles que PyPy ou Numba), Codon est construit dès le départ en tant que système autonome, compilé à l'avance dans un exécutable statique, sans avoir besoin d'un runtime Python existant (par exemple, CPython ). Par conséquent, en principe, Codon peut obtenir de meilleures performances et surmonter les problèmes spécifiques à l'exécution de Python tels que les verrous globaux de l'interpréteur. En pratique, Codon compile les scripts Python (comme un compilateur C) en code natif, s'exécutant 10 à 100 fois plus rapidement que l'exécution interprétée.
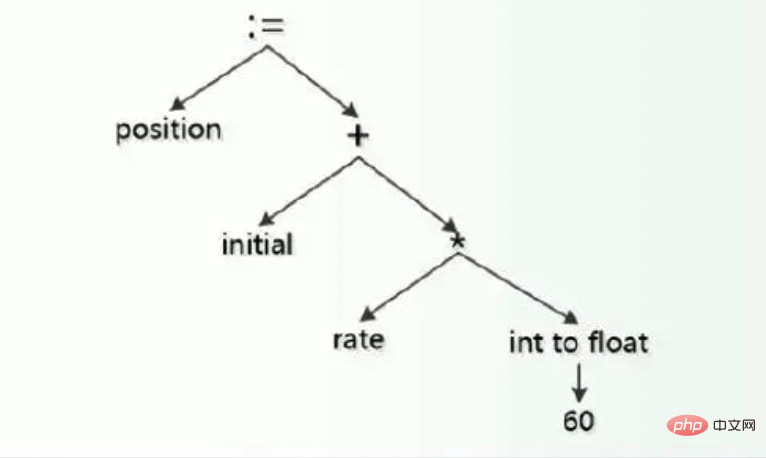
1. Introduction à Codon
Codon est modélisé sur la base du langage Seq, qui est un DSL bioinformatique. Seq a été conçu à l'origine comme un DSL de style pyramidal présentant de nombreux avantages, tels qu'une facilité d'adoption, d'excellentes performances et de puissantes capacités d'expression. Cependant, en raison de règles de type strictes, Seq ne prend pas en charge de nombreuses constructions courantes du langage Python et ne fournit pas non plus de mécanisme permettant d'implémenter facilement de nouvelles optimisations du compilateur. En appliquant l'IR bidirectionnel et des vérificateurs de type améliorés, Codon fournit une solution générale à ces problèmes basée sur Seq.
Codon couvre la plupart des fonctionnalités de Python et fournit un cadre pour réaliser une optimisation dans des domaines spécifiques. De plus, un système de typage flexible est fourni pour mieux gérer diverses fonctionnalités linguistiques. Le système de types est similaire à RPython et PyPy et au système de types statiques. Ces idées ont également été appliquées dans le contexte d'autres langages dynamiques, tels que PRuby. L'approche utilisée par l'IR bidirectionnel présente des similitudes avec les systèmes de type enfichable direct, tels que le cadre d'inspection de Java.
Bien que l'expression intermédiaire de Codon ne soit pas le premier IR personnalisable, elle ne prend pas en charge la personnalisation de tout le contenu, optant plutôt pour une personnalisation simple et bien définie qui peut être combinée avec la bidirectionnalité pour implémenter des fonctionnalités plus complexes. En termes de structure, CIR s'inspire de LLVM et de l'IR de Rust. Ces IR bénéficient d’un ensemble de nœuds et d’une structure considérablement simplifiés, ce qui simplifie la mise en œuvre des canaux IR. Structurellement, cependant, ces implémentations restructurent fondamentalement le code source, éliminant les informations sémantiques qui doivent être refactorisées pour effectuer la transformation. Pour remédier à cette lacune, Taichi adopte une structure hiérarchique qui maintient le flux de contrôle et les informations sémantiques au détriment d'une complexité accrue. Cependant, contrairement à Codon, ces IR sont largement indépendants du front-end de leur langage, ce qui rend le maintien de l'exactitude du type et la génération de nouveau code quelque peu peu pratique, voire impossible. Par conséquent, CIR exploite la hiérarchie simplifiée de ces méthodes, en conservant les nœuds de flux de contrôle du code source et un sous-ensemble complètement réduit de nœuds internes. Surtout, il améliore cette structure grâce à la bidirectionnalité, ce qui rend les nouveaux IR faciles à générer et à manipuler.
2. Vérification de type et inférence
Codon utilise la vérification de type statique et compile dans LLVM IR sans utiliser d'informations de type d'exécution, similaire à ce qui était fait auparavant dans le contexte de langages dynamiques tels que Python end. -la vérification de type de bout en bout fonctionne. À cette fin, Codon est livré avec un système de types statiques bidirectionnels, appelé LTS-DI, qui utilise l'inférence de style HindleyMilner pour déduire les types dans le programme sans nécessiter que l'utilisateur annote manuellement les types (cette approche, bien que prise en charge, n'est pas pris en charge en Python Pas courant parmi les développeurs).
En raison de la nature de la syntaxe de Python et des idiomes pythoniques courants, LTS-DI adapte le raisonnement standard de type hm pour prendre en charge les constructions Python notables telles que les compréhensions, les itérateurs, les générateurs, les opérations de fonctions complexes, les paramètres de variables, la vérification de type statique, etc. Pour gérer ces structures et bien d’autres, LTS-DI s’appuie sur :
- Monomorphisme (instancier une version distincte d'une fonction pour chaque combinaison d'arguments d'entrée)
- Localisation (traiter chaque fonction comme une unité de vérification de type isolée)
- Instanciation retardée (l'instanciation de la fonction est retardée, jusqu'à ce que tous les paramètres de la fonction soient connus) .
De nombreuses constructions Python nécessitent également des expressions de compilation (similaires aux expressions pr compressées de C++), qui sont prises en charge par codon. Bien que ces approches ne soient pas rares dans la pratique (par exemple, les modèles C++ utilisent des singletons) et que l'instanciation paresseuse soit déjà utilisée dans le système de types HMF, nous ne connaissons pas leur utilisation combinée dans le contexte de programmes Python à vérification de type. Enfin, veuillez noter que le système de types de Codon dans son implémentation actuelle est complètement statique et n'effectue aucune inférence de type d'exécution. Par conséquent, certaines fonctionnalités de Python, telles que le polymorphisme d'exécution ou la réflexion d'exécution, ne sont pas prises en charge. Dans le contexte du calcul scientifique, la suppression de ces fonctionnalités s’est avérée représenter un compromis raisonnable entre utilité et performances.
3. Expressions intermédiaires
De nombreux langages se compilent de manière relativement simple : le code source est analysé dans un arbre de syntaxe abstraite (AST), optimisé et converti en code machine, souvent à l'aide d'un framework tel que LLVM. . Bien que cette approche soit relativement facile à mettre en œuvre, l'AST contient souvent beaucoup plus de types de nœuds que nécessaire pour représenter un programme donné. Cette complexité peut rendre la mise en œuvre de l’optimisation, de la transformation et de l’analyse difficile, voire peu pratique. Une autre approche consiste à convertir l'AST en une représentation intermédiaire (IR) avant d'effectuer la passe d'optimisation. La représentation intermédiaire contient généralement un ensemble simplifié de nœuds avec une sémantique bien définie, ce qui les rend plus propices à la conversion et à l'optimisation.
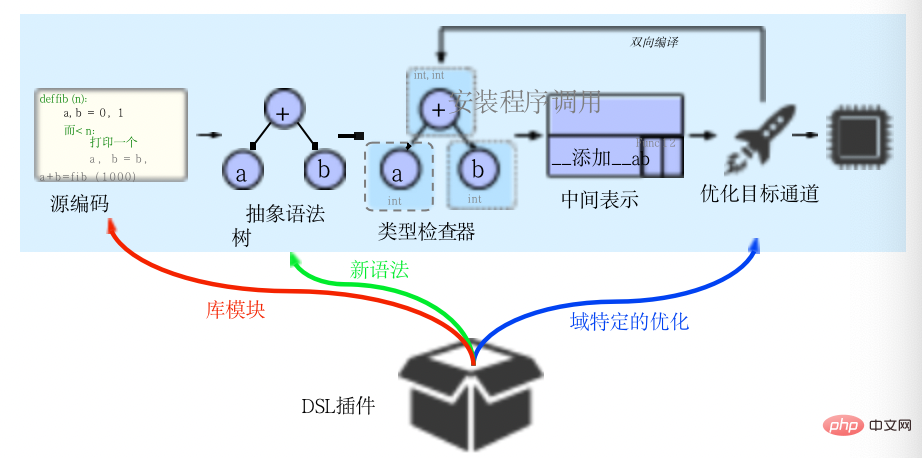
Codon implémente cette approche dans son IR, qui se situe entre les phases de vérification de type et d'optimisation, comme le montre l'image ci-dessus. La représentation intermédiaire de Codon (CIR) est beaucoup plus simple que l'AST, avec une structure plus simple et moins de types de nœuds. Malgré leur simplicité, les représentations intermédiaires de Codon conservent une grande partie des informations sémantiques du code source et facilitent la « réduction progressive », permettant une optimisation à plusieurs niveaux d'abstraction.
3.1 Mappage du code source
CIR est en partie inspiré de l'IR de LLVM. Dans LLVM, une structure similaire à la forme d'allocation statique unique (SSA) est adoptée, distinguant les valeurs et les variables allouées dans un emplacement, qui sont conceptuellement similaires aux emplacements mémoire. La compilation se déroule d'abord de manière linéaire, où le code source. est analysé dans un arbre de syntaxe abstraite sur lequel une vérification de type est effectuée pour générer des expressions intermédiaires. Cependant, contrairement à d'autres frameworks de compilation, Codon est bidirectionnel et l'optimisation IR peut revenir à l'étape de vérification de type pour générer de nouveaux nœuds qui n'étaient pas dans le programme d'origine. Le framework est « extensible au domaine » et un « plug-in DSL » se compose de modules de bibliothèque, de syntaxe et d'optimisations spécifiques au domaine.
Afin de réaliser le mappage de la structure du code source, une valeur peut être imbriquée dans un arbre arbitrairement grand. Cette structure permet de réduire facilement un CIR à un graphe de flux de contrôle, par exemple. Cependant, contrairement à LLVM, CIR utilisait à l'origine des nœuds explicites appelés flux pour représenter le flux de contrôle, permettant une correspondance structurelle étroite avec le code source. Représenter explicitement la hiérarchie des flux de contrôle est similaire à l'approche adoptée par Taichi. Surtout, cela facilite la mise en œuvre des optimisations et des transformations qui reposent sur des concepts précis de flux de contrôle. Un exemple simple est celui des flux, qui conserve des boucles explicites dans CIR et permet au codon d'identifier facilement des modèles de boucles communs, plutôt que de déchiffrer un labyrinthe de branches comme c'est le cas dans LLVM IR.
3.2 Opérateurs
CIR ne représente pas explicitement les opérateurs comme "+", mais les convertit en appels de fonction correspondants. Cela permet une surcharge transparente des opérateurs de types arbitraires, avec la même sémantique que celle de Python. Par exemple, l'opérateur + se résout en un appel d'ajout.
Une question naturelle qui découle de cette approche est de savoir comment implémenter les opérateurs pour les types primitifs tels que les ints et les floats. Codon résout ce problème en autorisant LLVM IR en ligne via les annotations de fonction @llvm, ce qui permet à tous les opérateurs primitifs d'être écrits dans le code source du codon. Les informations sur les propriétés des opérateurs telles que la commutativité et l'associativité peuvent être transmises sous forme d'annotations dans IR.
3.3 IR bidirectionnel
Le pipeline de compilation traditionnel est linéaire dans son flux de données : le code source est analysé en AST, généralement converti en IR, optimisé et finalement converti en code machine. Codon a introduit le concept d'IR bidirectionnel, dans lequel le canal IR peut revenir à l'étape de vérification de type, générant de nouveaux nœuds IR et des nœuds spécialisés qui n'existent pas dans le programme source. Ses avantages incluent :
- Les conversions les plus complexes peuvent être implémentées directement dans le codon. Par exemple, l’optimisation de la prélecture implique un planificateur de programme dynamique général, qu’il est irréaliste de mettre en œuvre uniquement dans Codon IR.
- De nouvelles instanciations de types de données définis par l'utilisateur peuvent être générées à la demande. Par exemple, les optimisations qui nécessitent l'utilisation de dictionnaires Codon peuvent être instanciées en tant que types Dict pour les types de clé et de valeur appropriés. L'instanciation d'un type ou d'une fonction est un processus très simple qui nécessite une réinvocation complète du vérificateur de type en raison de l'implémentation en cascade et de la spécialisation.
De même, le canal IR lui-même peut être générique, en utilisant le système de types d'expression de Codon pour fonctionner sur différents types. Les types IR n'ont pas de génériques associés (contrairement aux types AST). Cependant, chaque type CIR comporte une référence au type AST utilisé pour le générer, ainsi qu'à tous les paramètres de type générique AST. Ces types AST associés sont utilisés lors de la réinvocation du vérificateur de type et permettent d'interroger les types CIR pour leurs génériques sous-jacents. Notez que les types CIR correspondent à des abstractions de haut niveau ; les types IR LLVM sont inférieurs et ne correspondent pas directement aux types Codon.
En fait, la capacité d'instancier de nouveaux types lors de la livraison CIR est essentielle pour de nombreuses opérations CIR. Par exemple, créer un tuple (x,y) à partir des valeurs CIR données x et y nécessite d'instancier un nouveau type de tuple tuple[X,Y] (où l'identifiant en majuscule est le type d'expression), ce qui nécessite à son tour d'instancier un nouveau tuple. Opérateurs de tuples pour la vérification de l'égalité et des inégalités, l'itération, le hachage, etc. Cependant, le rappel du vérificateur de type rend le processus transparent.

L'image ci-dessus est un exemple d'une simple fonction Fibonacci vers le mappage du code source CIR. La fonction fib correspond à un CIR BodiedFunc avec un seul argument entier. Le corps contient un flux de contrôle If, qui renvoie une constante ou appelle la fonction de manière récursive pour obtenir le résultat. Notez que les opérateurs comme + sont traduits en appels de fonction (par exemple, add), mais IR est mappé au code source brut dans sa structure, permettant une correspondance et une conversion simples de modèles. Dans ce cas, surchargez simplement le gestionnaire d'appel, vérifiez si la fonction remplit les conditions de remplacement et effectuez l'action si elle correspond. Les utilisateurs peuvent également définir leur propre schéma de parcours et modifier la structure IR à volonté.
3.4 Canaux et transformations
CIR fournit une infrastructure complète d'analyse et de transformation : les utilisateurs écrivent des passes à l'aide de diverses classes d'application intégrées au CIR et les enregistrent auprès du gestionnaire de mots de passe, où des canaux plus complexes peuvent exploiter la bidirectionnalité du CIR et réinvoquer le type. vérificateur pour obtenir de nouveaux types, fonctions et méthodes CIR, dont des exemples sont présentés dans la figure ci-dessous.
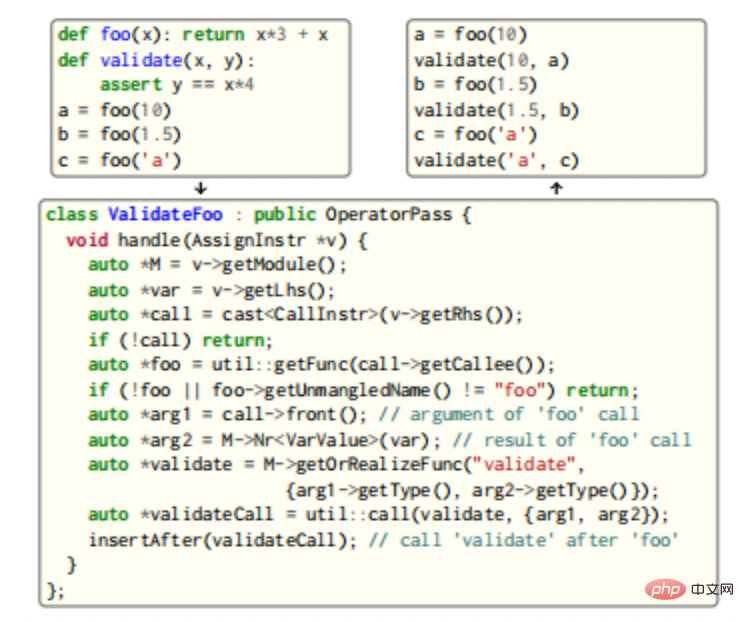
Dans cet exemple, les appels à la fonction foo sont recherchés et après chaque appel, un appel est inséré qui valide les paramètres de foo et sa sortie. Étant donné que les deux fonctions sont génériques, le vérificateur de type est réinvoqué pour générer trois nouvelles instanciations de validation uniques. L'instanciation de nouveaux types et fonctions nécessite la gestion des spécialisations possibles et l'implémentation de nœuds supplémentaires (par exemple, la méthode de l'opérateur == __eq__ doit être implémentée dans l'exemple pour implémenter la validation), ainsi que la mise en cache de l'implémentation pour une utilisation ultérieure.
3.5 Génération et exécution de code
Codon utilise LLVM pour générer du code natif. La conversion de Codon IR en LLVM IR est généralement un processus simple. La plupart des types Codon peuvent également être intuitivement convertis en types IR LLVM : int devient i64, float devient double, bool devient int8, et ainsi de suite - ces conversions permettent également l'interopérabilité C/C++. Les types de tuples sont convertis en types struct contenant les types d'éléments appropriés, qui sont transmis par valeur (remarque, les tuples sont immuables en Python) ; cette façon de gérer les tuples permet d'optimiser entièrement LLVM dans la plupart des cas. Les types de référence, tels que les listes, Dict, etc., sont implémentés en tant qu'objets alloués dynamiquement et sont transmis par référence. Ceux-ci suivent les types sémantiques variables de Python et peuvent être mis à niveau vers des types facultatifs si nécessaire pour ne gérer aucune valeur facultatif. un tuple du type i1 de LLVM et du type sous-jacent, le premier indiquant si le type facultatif contient une valeur. Les options sur les types référence sont spécifiquement conçues pour utiliser un pointeur nul pour indiquer les valeurs manquantes.
Les générateurs sont une construction de langage populaire en Python ; en fait, chaque boucle for parcourt un générateur. Il est important de noter que les générateurs de Codon n’entraînent aucune surcharge supplémentaire et se compilent autant que possible en code C standard équivalent. À cette fin, Codon utilise des coroutines LLVM pour implémenter des générateurs.
Codon utilise une petite bibliothèque d'exécution lors de l'exécution du code. En particulier, le garbage collector Boehm est utilisé pour gérer la mémoire allouée. Codon propose deux modes de compilation : débogage et release. Le mode débogage inclut des informations de débogage complètes, permettant au programme d'être débogué à l'aide d'outils tels que GDB et LLDB, ainsi que des informations de traçage complètes, notamment le nom du fichier et le numéro de ligne. Le mode Release effectue davantage d'optimisations (y compris les optimisations -O3 de GCC/Clang) et omet certaines informations de sécurité et de débogage. Par conséquent, les utilisateurs peuvent utiliser le mode débogage pour des cycles de programmation et de débogage rapides et le mode release pour un déploiement hautes performances.
3.6 Évolutivité
En raison de la flexibilité et de l'IR bidirectionnel du framework, ainsi que de l'expressivité globale de la syntaxe Python, les applications Codon implémentent généralement la plupart des fonctionnalités des composants spécifiques à un domaine dans le code source lui-même. Une approche modulaire peut être présentée sous forme de bibliothèques dynamiques et de fichiers sources Codon. Ce plugin peut être chargé par le compilateur de codons au moment de la compilation.
Certains frameworks, comme MLIR, permettent la personnalisation. Condon IR, en revanche, limite certains types de nœuds et s'appuie sur la bidirectionnalité pour plus de flexibilité. En particulier, CIR permet aux utilisateurs de dériver des types, flux, constantes et directives « personnalisés » qui interagissent avec le reste du framework via des interfaces déclaratives. Par exemple, les nœuds personnalisés proviennent de la classe de base personnalisée appropriée (type personnalisé, flux personnalisé, etc.) et exposent un « constructeur » pour construire l'IR LLVM correspondant. L'implémentation de types et de nœuds personnalisés implique de définir un générateur (par exemple un type de bâtiment) via une méthode virtuelle ; la classe de type personnalisé elle-même définit une méthode getBuilder pour obtenir une instance de ce générateur. Cette construction standardisée de nœuds fonctionne de manière transparente avec les canaux et analyses existants.
4 Applications
4.1 Performances de référence
De nombreux programmes Python standard fonctionnent déjà immédiatement, ce qui facilite l'optimisation de plusieurs modèles courants dans le code Python, tels que les mises à jour de dictionnaire (qui peuvent être optimisées pour utiliser une seule recherche au lieu de two ), ou des ajouts de chaînes consécutifs (qui peuvent être regroupés en une seule connexion pour réduire la surcharge d'allocation).

Le graphique ci-dessus montre les performances d'exécution de Codon, ainsi que les performances de CPython (v3.10) et PyPy (v7.3), sur des benchmarks, limités à un ensemble de benchmarks "de base", ne dépendant pas de Bibliothèques externes. Comparé à CPython et PyPy, Codon est toujours plus rapide, parfois d'un ordre de grandeur. Même si les benchmarks constituent un bon indicateur de performance, ils ne sont pas sans inconvénients et ne racontent souvent pas tout. Codon permet aux utilisateurs d'écrire du code Python simple pour une variété de domaines tout en offrant des performances élevées sur des applications et des ensembles de données du monde réel.
4.2 OpenMP : parallélisme des tâches et des boucles
Étant donné que Codon est construit indépendamment du runtime Python existant, il n'est pas affecté par le verrouillage global de l'interpréteur CPython et peut donc tirer pleinement parti du multi-threading. Pour prendre en charge la programmation parallèle, une extension de Codon permet aux utilisateurs finaux d'utiliser OpenMP.
Pour OpenMP, le corps de la boucle parallèle est présenté comme une nouvelle fonction, qui est ensuite appelée par plusieurs threads par le runtime OpenMP. Par exemple, le corps de la boucle dans la figure ci-dessous serait décrit comme une fonction f qui prend comme paramètres les variables a, b, c et la variable de boucle i.
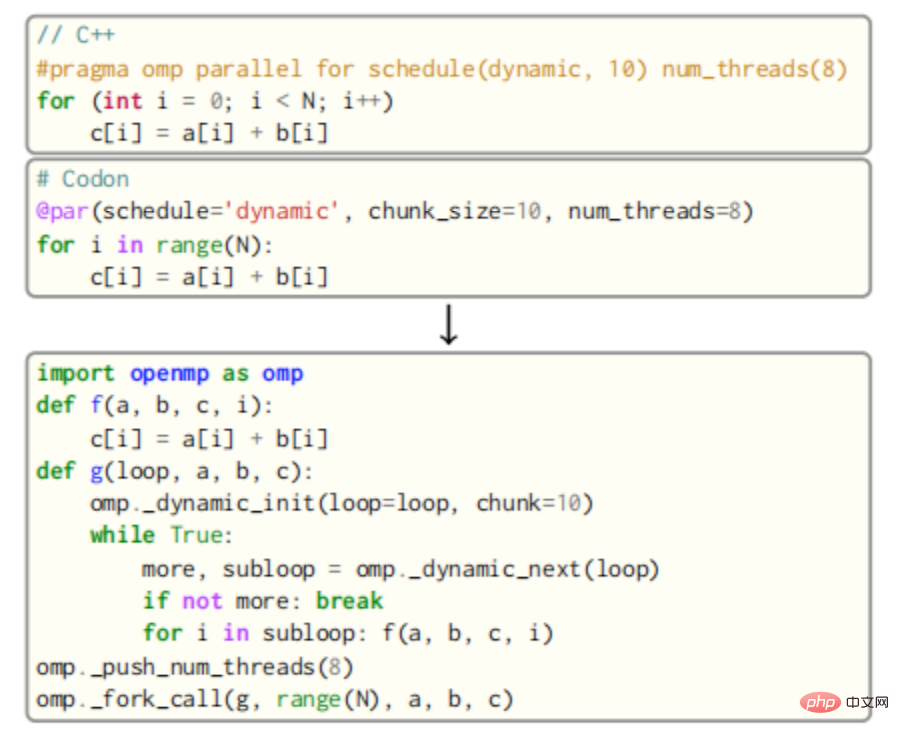
L'appel à f sera ensuite inséré dans une nouvelle fonction g qui appelle la routine de planification dynamique à tour de rôle d'OpenMP avec une taille de bloc de 10. Enfin, tous les threads de la file d'attente appelleront g via la fonction fork_call d'OpenMP. Le résultat est affiché dans l'extrait de code correct dans l'image ci-dessus, avec une attention particulière étant accordée à la gestion des variables privées ainsi que des variables partagées. La réduction des variables nécessite également une génération de code supplémentaire pour les opérations atomiques (ou l'utilisation de verrous) et une couche supplémentaire d'appels API OpenMP.
La compilation bidirectionnelle de Codon est un élément clé du pass OpenMP. Les « modèles » pour les différentes boucles sont implémentés dans le code source de Codon. Après analyse du code, ces « modèles » sont transmis et spécialisés en remplissant les corps de boucles, les tailles et plannings de blocs, en réécrivant les expressions qui dépendent des variables partagées, etc. Cette conception simplifie grandement la mise en œuvre du pass et ajoute un certain degré de polyvalence.
Contrairement à Clang ou GCC, le canal OpenMP de Codon peut déduire quelles variables sont partagées et lesquelles sont privées, ainsi que tout code minifié en cours. Des réductions personnalisées peuvent être effectuées simplement en fournissant une méthode de magie atomique appropriée (par exemple .aborom_add) sur le type de réduction. Codon parcourt le générateur (le comportement par défaut des boucles Python) jusqu'à une "boucle impérative", c'est-à-dire une boucle de style C avec des valeurs de début, d'arrêt et de pas. Si la balise @par est présente, la boucle forcée sera convertie en boucle parallèle OpenMP. Les boucles parallèles non forcées sont parallélisées en générant une nouvelle tâche OpenMP pour chaque itération de boucle et en plaçant un point de synchronisation après la boucle. Ce schéma permet de paralléliser toutes les boucles for Python.
Les transformations OpenMP sont implémentées sous la forme d'un ensemble de CIR correspondant à des boucles for marquées avec l'attribut @par, et ces boucles sont transformées en constructions OpenMP appropriées dans le CIR. Presque toutes les structures OpenMP sont implémentées en tant que fonctions d'ordre supérieur de Condon lui-même.
4.3 CoLa : un DSL pour la compression par blocs
CoLa est un DSL basé sur Codon qui cible la compression de données par blocs, qui est au cœur de nombreux algorithmes de compression d'images et de vidéos couramment utilisés aujourd'hui. Ces types de compression reposent fortement sur la division d'une zone de pixels en une série de blocs de plus en plus petits, formant une hiérarchie de données multidimensionnelle où chaque bloc doit connaître sa position par rapport aux autres blocs. Par exemple, la compression vidéo H.264 divise l'image d'entrée en une série de blocs de 16 x 16 pixels, chaque pixel en blocs de 8 x 8 pixels, puis divise ces pixels en blocs de 4 x 4 pixels. Le suivi de la position entre ces parcelles individuelles de pixels nécessite une grande quantité de données d'information, ce qui obscurcit rapidement les algorithmes sous-jacents dans les implémentations existantes.
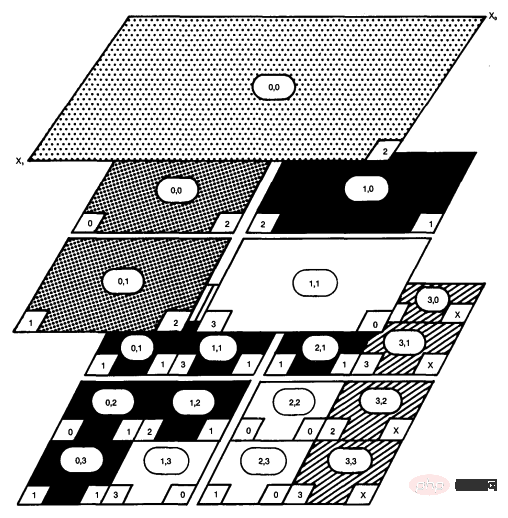
CoLa introduit l'abstraction du tableau hiérarchique multidimensionnel (HMDA), qui simplifie l'expression et l'utilisation des données hiérarchiques. HMDA représente un tableau multidimensionnel avec une notion de position, qui suit l'origine de tout HMDA donné par rapport à un système de coordonnées global. HMDA peut également suivre leur taille et leur longueur de foulée. Avec ces trois éléments de données, n’importe quel HMDA peut déterminer sa position par rapport à n’importe quel autre HMDA à tout moment du programme. CoLa résume HMDA dans Codon en tant que bibliothèque centrée sur deux nouveaux types de données : les blocs et les vues. Le bloc crée et possède un tableau multidimensionnel sous-jacent, et la vue pointe vers une zone spécifique du bloc. CoLa expose deux hiérarchies principales : les opérations de construction, la copie positionnelle et le partitionnement, qui créent respectivement des blocs et des vues. CoLa prend en charge l'indexation standard à l'aide d'index entiers et de tranches, mais introduit également deux schémas d'indexation uniques qui imitent la façon dont les normes de compression décrivent l'accès aux données. Les index « hors limites » permettent aux utilisateurs d'accéder aux données entourant une vue, tandis que les index « gérés » permettent aux utilisateurs d'indexer un HMDA à l'aide d'un autre HMDA.
Bien que la combinaison de la physique de Codon et des abstractions de CoLa offre aux utilisateurs les avantages d'un langage de haut niveau et d'abstractions spécifiques à la compression, l'abstraction HMDA introduit une surcharge d'exécution importante en raison des opérations d'indexation supplémentaires requises. Pour la compression, de nombreux accès HMDA se produisent au niveau le plus interne du calcul, de sorte que tout calcul supplémentaire en plus de l'accès au tableau d'origine s'avère préjudiciable au moteur d'exécution. CoLa exploite le framework Codon pour implémenter des hiérarchies, réduisant ainsi le nombre de vues intermédiaires créées et les tentatives de propagation pour déduire la position d'un HMDA donné. Cela réduit la taille globale de la hiérarchie et simplifie les calculs d'index réels. Sans ces optimisations, CoLa est en moyenne 48,8×, 6,7× et 20,5× plus lent que le code C de référence pour JPEG et H.264]. Après optimisation, les performances ont été grandement améliorées, avec des temps d'exécution moyens de respectivement 1,06×, 0,67× et 0,91× par rapport au même code de référence.
CoLa est implémenté en tant que plugin Codon et, en tant que tel, est livré avec une bibliothèque de primitives de compression, ainsi qu'un ensemble de canaux CIR et LLVM qui optimisent les routines de création et d'accès. CoLa simplifie également les opérations courantes d'indexation et de réduction à l'aide d'une syntaxe d'accès à la structure de données personnalisée et d'opérateurs fournis par Codon.
5. Résumé
Essentiellement, codon est un framework configurable par domaine pour concevoir et mettre en œuvre rapidement le DSL. En appliquant un algorithme de vérification de type spécialisé et un nouvel algorithme IR bidirectionnel, le code dynamique dans divers domaines peut être facilement optimisé. Par rapport à l'utilisation directe de Python, Codon peut égaler les performances C/C++ sans sacrifier la simplicité de haut niveau.
Actuellement, Codon possède plusieurs fonctionnalités Python qui ne sont pas prises en charge, notamment le polymorphisme d'exécution, la réflexion d'exécution et les opérations de type (par exemple, la modification dynamique de la table de méthodes, l'ajout dynamique de membres de classe, les métaclasses et les décorateurs de classe). couverture de la bibliothèque Python standard. Bien que Python compilé par Codon puisse exister en tant que solution restrictive, il convient d'y prêter attention.
【Matériel de référence et lectures associées】
- https://www.php.cn/link/a7453a5f026fb6831d68bdc9cb0edcae
- https://www.php.cn/link/c49e446a46fa27a6e18ffb6119461c3f
- Compilateur JIT de traçage de PyPy,https ://doi.org/10.1145/1565824.1565827
- Un cadre de programmation multi-étapes basé sur le type pour la génération de code en C++,https://doi.org/10.1109/CGO51591. 2021.9370333
- https://www.php.cn/link/9fd5e502c1640f62738c8a908d3eb0f7
- LLVM : un cadre de compilation pour la transformation de l'analyse de programmes tout au long de la vie,https://doi.org/10.1109/CGO.2004.1281 665
- AnyDSL : un cadre d'évaluation partielle pour la programmation de bibliothèques hautes performances,https://doi.org/10.1145/3276489
- Un langage de programmation basé sur Python pour la génomique informatique hautes performances,https : //doi.org/10.1038/s41587 -021-00985-6
- Un compilateur pour les applications pythoniques et DSL hautes performances,https://dl.acm.org/doi/abs/10.1145/3578360.3580275
- https://www.php.cn /link/6c7de1f27f7de61a6daddfffbe05c058
- Taichi : un langage pour le calcul haute performance sur des structures de données spatialement clairsemées,https://doi.org/10.1145/3355089. 335650
- https://www.php.cn/link/ca5150ff1c65880ded50f92ed067c95e
- 操作系统中的系统抽象
- 温故知新:从计算机体系结构看操作系统
- 从操作系统看Docker
- Linux 内核裁剪框架初探
- 机器学习系统架构的10个要素
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Minio Object Storage: Déploiement haute performance dans le système Centos System Minio est un système de stockage d'objets distribué haute performance développé sur la base du langage Go, compatible avec Amazons3. Il prend en charge une variété de langages clients, notamment Java, Python, JavaScript et GO. Cet article introduira brièvement l'installation et la compatibilité de Minio sur les systèmes CentOS. Compatibilité de la version CentOS Minio a été vérifiée sur plusieurs versions CentOS, y compris, mais sans s'y limiter: CentOS7.9: fournit un guide d'installation complet couvrant la configuration du cluster, la préparation de l'environnement, les paramètres de fichiers de configuration, le partitionnement du disque et la mini
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
 Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Lors de l'installation de Pytorch sur le système CentOS, vous devez sélectionner soigneusement la version appropriée et considérer les facteurs clés suivants: 1. Compatibilité de l'environnement du système: Système d'exploitation: Il est recommandé d'utiliser CentOS7 ou plus. CUDA et CUDNN: La version Pytorch et la version CUDA sont étroitement liées. Par exemple, Pytorch1.9.0 nécessite CUDA11.1, tandis que Pytorch2.0.1 nécessite CUDA11.3. La version CUDNN doit également correspondre à la version CUDA. Avant de sélectionner la version Pytorch, assurez-vous de confirmer que des versions compatibles CUDA et CUDNN ont été installées. Version Python: branche officielle de Pytorch
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
