
 Périphériques technologiques
IA
GPT3 et Google PaLM complètement explosés ! Le modèle de récupération amélioré Atlas actualise les petites tâches basées sur les connaissances SOTA
Périphériques technologiques
IA
GPT3 et Google PaLM complètement explosés ! Le modèle de récupération amélioré Atlas actualise les petites tâches basées sur les connaissances SOTA
GPT3 et Google PaLM complètement explosés ! Le modèle de récupération amélioré Atlas actualise les petites tâches basées sur les connaissances SOTA

Inconsciemment, les grands modèles + petits échantillons sont devenus l'approche dominante dans le domaine de l'apprentissage de petits échantillons. Dans de nombreux contextes de tâches, une idée courante est d'abord d'étiqueter de petits échantillons de données, puis de pré-entraîner de grands modèles basés sur l'utilisation de petites données. échantillons pour la formation. Bien que, comme nous l'avons vu, les grands modèles aient obtenu des résultats étonnants sur un large éventail de tâches d'apprentissage sur petits échantillons, cela met aussi naturellement certaines des lacunes inhérentes aux grands modèles sous le feu des projecteurs.
L'apprentissage sur petits échantillons attend du modèle qu'il ait la capacité de réaliser un raisonnement indépendant basé sur un petit nombre d'échantillons, c'est-à-dire que le modèle idéal doit maîtriser les idées de résolution de problèmes en résolvant des problèmes, afin de pouvoir tirer des inférences. sur d'autres cas face à de nouveaux problèmes. Cependant, la capacité d'apprentissage idéale et pratique des grands modèles + petits échantillons semble reposer sur la grande quantité d'informations stockées lors de la formation de grands modèles pour mémoriser le processus de résolution d'un problème. Bien qu'il soit extrêmement courageux sur divers ensembles de données, il le fera toujours. échouer. Cela amène des doutes chez les gens. Un étudiant qui étudie de cette manière est-il vraiment un étudiant potentiel ?

L'article présenté aujourd'hui par Meta AI applique la méthode d'amélioration de la récupération au domaine de l'apprentissage de petits échantillons d'une nouvelle manière. Il utilise non seulement 64 exemples, mais utilise également 64 exemples dans l'ensemble de données Natural Questions. , et a atteint une précision de 42 %. Il a également réduit le nombre de paramètres de 50 fois (540B—>11B) par rapport au grand modèle PaLM, et présentait d'autres avantages en termes d'interprétabilité, de contrôlabilité et de possibilité de mise à jour. avec des modèles plus grands.
Titre de l'article :Apprentissage en quelques étapes avec récupération de modèles de langage augmentésLien de l'article :https://arxiv.org/pdf/2208.03299.pdf
Récupération améliorée Traçabilité
Au début de l'article, une question a été posée à tout le monde : « Dans le domaine de l'apprentissage de petits échantillons, est-il vraiment nécessaire d'utiliser un grand nombre de paramètres pour stocker des informations ? les uns après les autres grands modèles L'une des raisons pour lesquelles le modèle peut actualiser sans cesse SOTA est que ses énormes paramètres stockent les informations nécessaires au problème. Depuis la naissance de Transformer, les grands modèles sont le paradigme dominant dans le domaine de la PNL. Avec le développement progressif des grands modèles, les « gros » problèmes sont constamment exposés. Il est tout à fait significatif de se poser la question de la nécessité du « grand ». de l'article commence à partir de À partir de cette question, une réponse négative est donnée à cette question et la méthode consiste à récupérer le modèle amélioré.

Amélioration de la récupération de traçabilité. En fait, bien que sa technologie soit principalement utilisée dans des tâches telles que la réponse aux questions de domaine ouvert, la lecture automatique et la génération de texte, l'idée de l'amélioration de la récupération remonte au RNN. l’ère de la PNL. L'inconvénient du modèle RNN, qui ne peut pas résoudre la dépendance à long terme des données, a incité les chercheurs à explorer largement les solutions. Le Transformer, que nous connaissons bien, utilise le mécanisme Attention pour résoudre efficacement le problème de l'incapacité du modèle à se souvenir. ouvrant ainsi la porte à l’ère de la pré-formation des grands modèles.
À cette époque, il existait en fait un autre moyen, le Cached LM. Son idée principale était que, puisque RNN pourrait ne pas être en mesure de s'en souvenir dès qu'il passerait l'examen, autant laisser RNN prendre le large. -book examen en introduisant le mécanisme de cache, les mots prédits lors de la formation sont stockés dans le cache et les informations de la requête et de l'index du cache peuvent être combinées pour terminer la tâche pendant la prédiction, résolvant ainsi les lacunes du modèle RNN. temps.
En conséquence, la technologie d'amélioration de la récupération s'est lancée dans une voie complètement différente des grands modèles qui s'appuient sur les informations de la mémoire des paramètres. Le modèle basé sur l'amélioration de la récupération permet l'introduction de connaissances externes provenant de différentes sources, et ces sources de récupération incluent un corpus de formation, des données externes, des données non supervisées et d'autres options. Le modèle d'amélioration de récupération se compose généralement d'un récupérateur et d'un générateur. Le récupérateur obtient des connaissances pertinentes à partir de sources de récupération externes en fonction de l'interrogation, et le générateur combine l'interrogation avec les connaissances pertinentes récupérées pour effectuer des prédictions de modèle.
En dernière analyse, l'objectif du modèle amélioré par la récupération est de s'attendre à ce que le modèle apprenne non seulement à mémoriser les données, mais aussi à apprendre à trouver les données par lui-même. Cette fonctionnalité présente de grands avantages dans de nombreuses connaissances. tâches intensives, et le modèle amélioré par la récupération a également obtenu un grand succès dans ces domaines, mais on ne sait pas si l'amélioration de la récupération est adaptée à l'apprentissage à petite échelle. En revenant à cet article dans Meta AI, nous avons testé avec succès l'application de l'amélioration de la récupération dans l'apprentissage de petits échantillons, et Atlas a vu le jour.
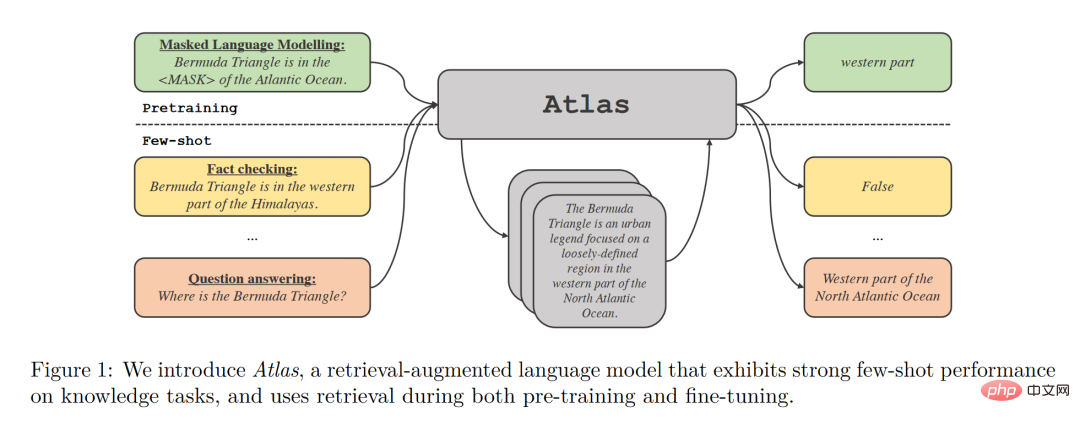
Structure du modèle
Atlas a deux sous-modèles, un récupérateur et un modèle de langage. Lorsqu'il est confronté à une tâche, Atlas utilise un moteur de recherche pour générer les documents top-k les plus pertinents à partir d'une grande quantité de corpus en fonction de la question d'entrée, puis place ces documents dans le modèle de langage avec la requête de question pour générer le résultat requis. .

La stratégie de formation de base du modèle Atlas consiste à former conjointement le retriever et le modèle de langage en utilisant la même fonction de perte. Le récupérateur et le modèle de langage sont tous deux basés sur le réseau Transformer pré-entraîné :
- Le récupérateur est conçu sur la base de Contriever, est pré-entraîné via des données non supervisées et utilise un encodeur à deux couches. la requête et le document sont codés indépendamment dans le code. Dans le processeur, la similarité entre la requête et le document est obtenue grâce au produit scalaire de la sortie correspondante. Cette conception permet à Atlas d'entraîner le récupérateur sans annotations de documents, réduisant ainsi considérablement les besoins en mémoire.
- Le modèle de langage est formé sur la base de T5. Différents documents et requêtes sont fusionnés les uns avec les autres et traités indépendamment par l'encodeur. Enfin, le décodeur effectue une attention croisée sur tous les paragraphes récupérés en série pour obtenir le résultat final. . Cette approche Fusion-in-Decoder aide Atlas à s'adapter efficacement à l'augmentation du nombre de documents.
Il est à noter que l'auteur a comparé et testé quatre fonctions de perte et la situation sans entraînement conjoint du retriever et du modèle de langage. Les résultats sont les suivants :
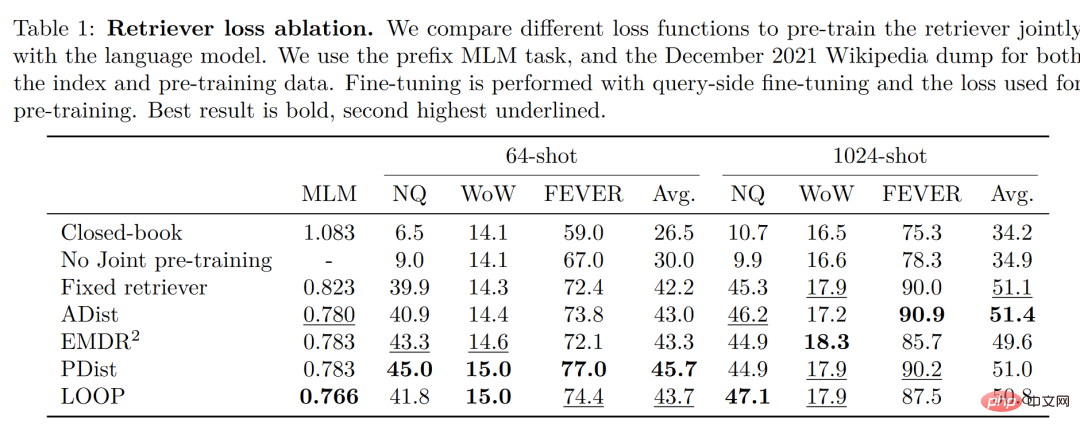
On peut voir cela dans. un petit échantillon d'environnement Dans ces conditions, la précision obtenue en utilisant la méthode de formation conjointe est nettement supérieure à celle sans formation conjointe. Par conséquent, l'auteur conclut que cette formation conjointe du retriever et du modèle de langage est la clé de la capacité d'Atlas à obtenir. petit échantillon d’apprentissage.
Résultats expérimentaux
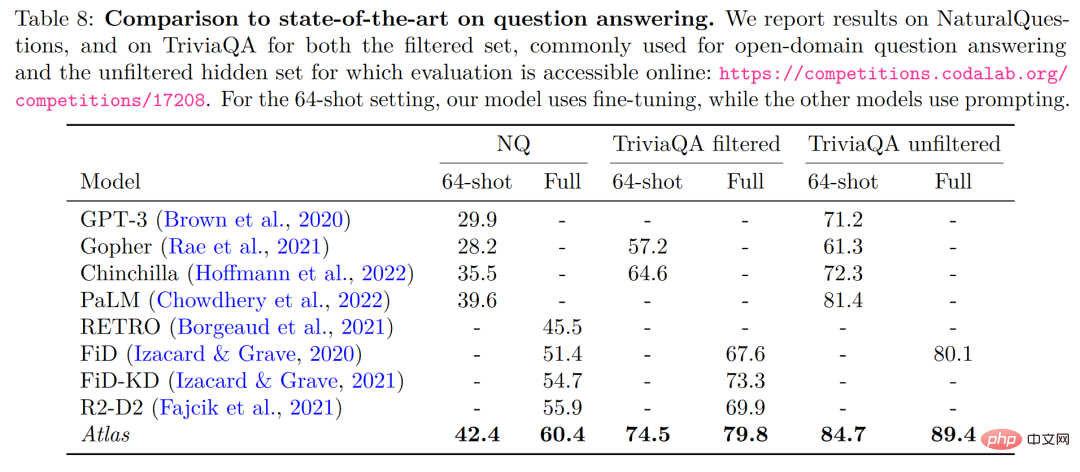
Dans la tâche de compréhension du langage multitâche à grande échelle (MMLU), par rapport à d'autres modèles, Atlas a de meilleures performances que GPT-3, qui a 15 fois le nombre de paramètres d'Atlas , avec seulement 11B paramètres, le taux de précision est très bon. Après l'introduction de l'entraînement multitâche, le taux de précision du test à 5 tirs est même proche de celui de Gopher, soit 25 fois le nombre de paramètres d'Atlas.
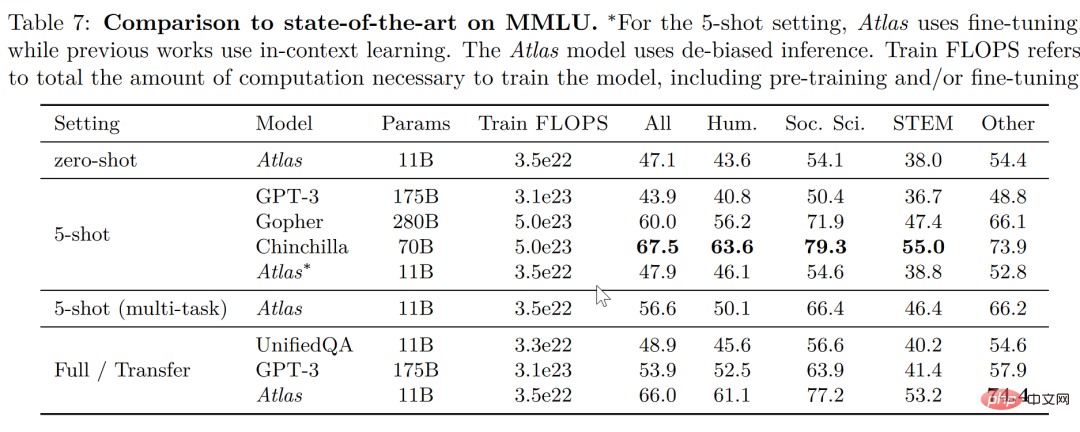
Dans les deux données de test de réponse aux questions du domaine ouvert - NaturalQuestions et TriviaQA, les performances d'Atlas et d'autres modèles sur 64 exemples et les performances sur l'ensemble d'entraînement complet sont comparées, comme le montre la figure ci-dessous, Atlas est un nouveau SOTA qui a été réalisé en 64 tirs, atteignant une précision de 84,7 % sur TrivuaQA en utilisant seulement 64 données.
Dans la tâche de vérification des faits (FEVER), Atlas a également obtenu de bien meilleurs résultats sur de petits échantillons que Gopher et ProoFVer, qui ont des dizaines de fois plus de paramètres qu'Atlas dans la tâche à 15 coups. a dépassé Gopher 5,1 %.

Sur KILT, la référence auto-publiée pour les tâches de traitement du langage naturel à forte intensité de connaissances, la précision d'Atlas formé à l'aide de 64 échantillons dans certaines tâches est même proche de la précision obtenue par d'autres modèles utilisant des échantillons complets. En entraînant Atlas avec tous les échantillons, Atlas a actualisé le SOTA sur cinq ensembles de données.
Interprétabilité, contrôlabilité, possibilité de mise à jour
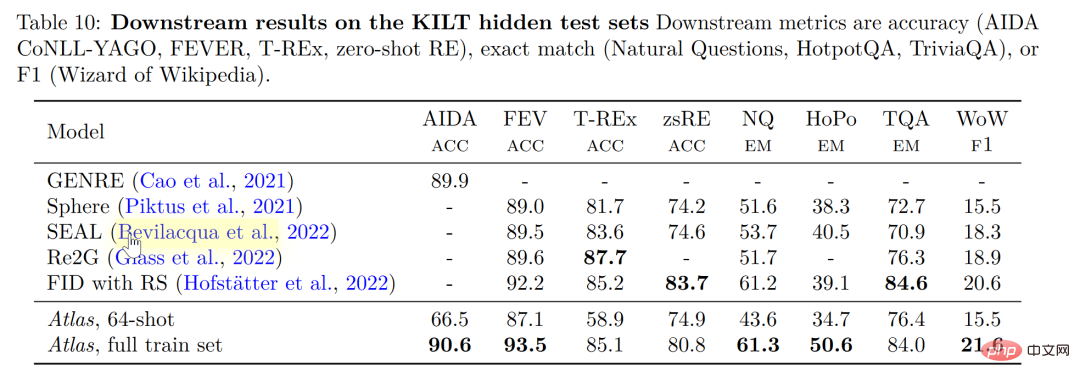
Selon les recherches menées dans cet article, le modèle d'amélioration de la récupération est non seulement plus petit et mieux équilibré, mais possède également des fonctionnalités que d'autres grands modèles n'ont pas en termes d'interprétabilité. La nature de la boîte noire des grands modèles rend difficile pour les chercheurs d'utiliser de grands modèles pour analyser le mécanisme de fonctionnement du modèle. Cependant, le modèle amélioré par la récupération peut extraire directement les documents récupérés, de sorte qu'en analysant les articles récupérés par la récupération, nous. peut obtenir un aperçu du travail de l’Atlas. Meilleure compréhension. Par exemple, l'article révèle que dans le domaine de l'algèbre abstraite, 73 % du corpus du modèle reposait sur Wikipédia, tandis que dans les domaines liés à l'éthique, seulement 3 % des documents extraits par le chercheur provenaient de Wikipédia, ce qui est cohérent avec l'opinion humaine. intuition. Comme le montre le graphique statistique sur le côté gauche de la figure ci-dessous, bien que le modèle préfère utiliser les données CCNet, dans les domaines STEM qui se concentrent davantage sur les formules et le raisonnement, le taux d'utilisation des articles Wikipédia a considérablement augmenté.
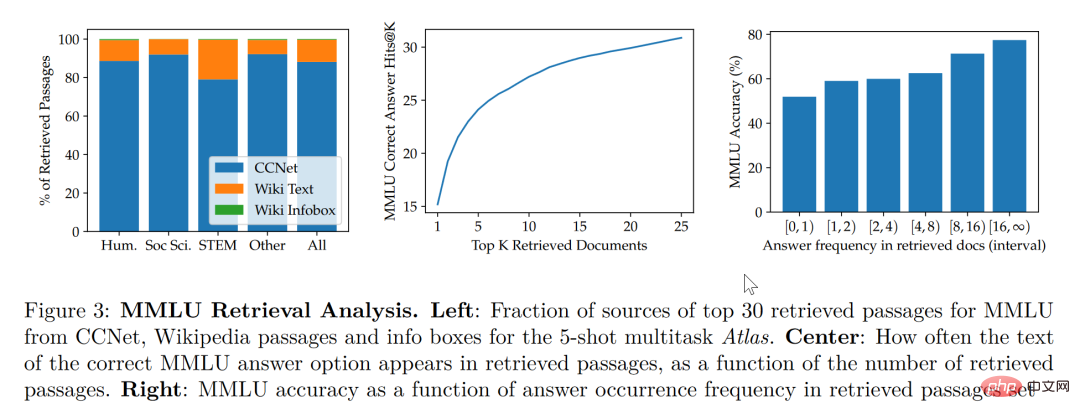
Selon le tableau statistique sur le côté droit de la figure ci-dessus, l'auteur a constaté qu'à mesure que le nombre d'articles récupérés contenant des réponses correctes augmente, la précision du modèle continue également d'augmenter lorsque l'article le fait. ne contiennent pas de réponses, elles ne sont correctes qu'à 55 %, et lorsque la réponse a été mentionnée plus de 15 fois, le taux de bonnes réponses atteint 77 %. En outre, lors de l'inspection manuelle des documents récupérés par 50 moteurs de recherche, il a été constaté que 44 % d'entre eux contenaient des informations générales utiles. De toute évidence, ces documents contenant des informations générales sur des questions peuvent offrir aux chercheurs de grandes opportunités d'élargir leur aide à la lecture.
De manière générale, nous avons tendance à penser que les grands modèles présentent un risque de « fuite » des données d'entraînement, c'est-à-dire que parfois les réponses des grands modèles aux questions de test ne sont pas basées sur la capacité d'apprentissage du modèle mais sur la capacité de mémoire du grand modèle, c'est-à-dire que les réponses aux questions du test ont été divulguées dans une grande quantité de corpus appris par le grand modèle. Dans cet article, après que l'auteur a éliminé manuellement les informations du corpus qui auraient pu être divulguées, le la précision du modèle est passée de 56,4 % à 55,8 %, soit une diminution de seulement 0,6 % , on peut voir que la méthode d'amélioration de la récupération peut efficacement éviter le risque de tricherie du modèle.
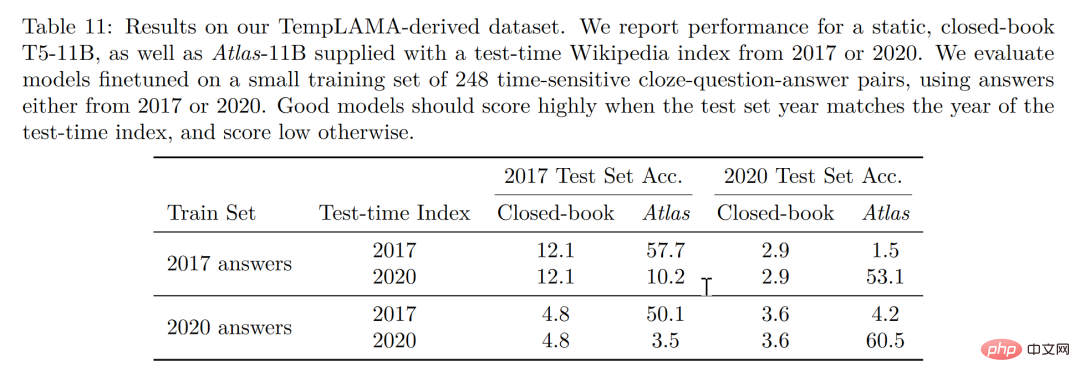
Enfin, la possibilité de mise à jour est également un avantage unique du modèle d'amélioration de récupération. Le modèle d'amélioration de récupération peut être mis à jour de temps en temps sans recyclage, mais uniquement en mettant à jour ou en remplaçant le corpus sur lequel il s'appuie. En construisant un ensemble de données de séries chronologiques, comme le montre la figure ci-dessous, sans mettre à jour les paramètres de l'Atlas, l'auteur a obtenu une précision de 53,1 % simplement en utilisant le corpus Atlas 2020. Ce qui est intéressant, c'est que même avec un réglage fin à l'aide de l'Atlas 2020. les données T5, T5 n'ont pas non plus très bien fonctionné. L'auteur estime que la raison est en grande partie due au fait que les données utilisées dans la pré-formation de T5 sont des données antérieures à 2020.
Conclusion
Nous pouvons imaginer qu'il y a trois élèves qui s'appuient uniquement sur la mémorisation par cœur pour résoudre un problème de mathématiques, et l'autre élève s'appuie sur la lecture de livres. Lors de sa rencontre, il ne savait pas comment rechercher les informations les plus appropriées et y répondre une par une. Cependant, le dernier étudiant était talentueux et intelligent. Il pouvait se rendre en toute confiance dans la salle d'examen et donner des conseils simplement. apprendre certaines connaissances à partir de manuels.
Évidemment, l'idéal de l'apprentissage en petit échantillon est de devenir le troisième étudiant, mais la réalité est susceptible de rester au-dessus du premier étudiant. Les grands modèles sont faciles à utiliser, mais « grand » n'est en aucun cas le but ultime du modèle. Pour en revenir à l'intention initiale de l'apprentissage sur petit échantillon, on s'attend à ce que le modèle ait un jugement raisonné et la capacité de tirer des inférences similaires à celles des humains. nous pouvons voir que cet article est d'un point de vue différent. Il serait bon de faire un pas en avant, au moins pour permettre à l'étudiant de ne pas charger autant de connaissances potentiellement redondantes dans sa tête, mais de prendre un manuel et de le faire. voyager léger. Peut-être même permettre aux étudiants de passer des examens à livre ouvert avec le manuel pour une révision constante, et ce sera plus proche de l'intelligence que les étudiants mémorisant par cœur !

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
