
 Périphériques technologiques
IA
Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou
Périphériques technologiques
IA
Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou
Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou


1. Contexte du problème
1. Introduction à l'expérience de marché bilatéral
Un marché biface, c'est-à-dire une plate-forme, comprend deux participants, producteurs et consommateurs, et les deux parties promeuvent chacun autre. Par exemple, Kuaishou a un producteur vidéo et un consommateur vidéo, et les deux identités peuvent se chevaucher dans une certaine mesure.
L'expérimentation bilatérale est une méthode expérimentale qui associe des groupes du côté des producteurs et des consommateurs.
Les expériences bilatérales présentent les avantages suivants :
(1) L'impact de la nouvelle stratégie sur deux aspects peut être détecté simultanément, comme les changements dans le DAU du produit et le nombre de personnes téléchargeant des œuvres. Les plateformes bilatérales ont souvent des effets de réseau transversaux. Plus il y a de lecteurs, plus les auteurs seront actifs, et plus les auteurs seront actifs, plus les lecteurs suivront.
(2) peut détecter le débordement et le transfert d'effet.
(3) Aidez-nous à mieux comprendre le mécanisme d'action. L'expérience AB elle-même ne peut pas nous dire la relation entre la cause et le résultat. Elle peut seulement nous dire quel type d'impact et de changements de données seront obtenus. ce que nous faisons. Cependant, le mécanisme d’action entre le côté production et le côté consommateur nécessite des conceptions expérimentales plus complexes et davantage d’indicateurs expérimentaux pour comprendre clairement ces problèmes.
2. Exemple d'expérience bilatérale
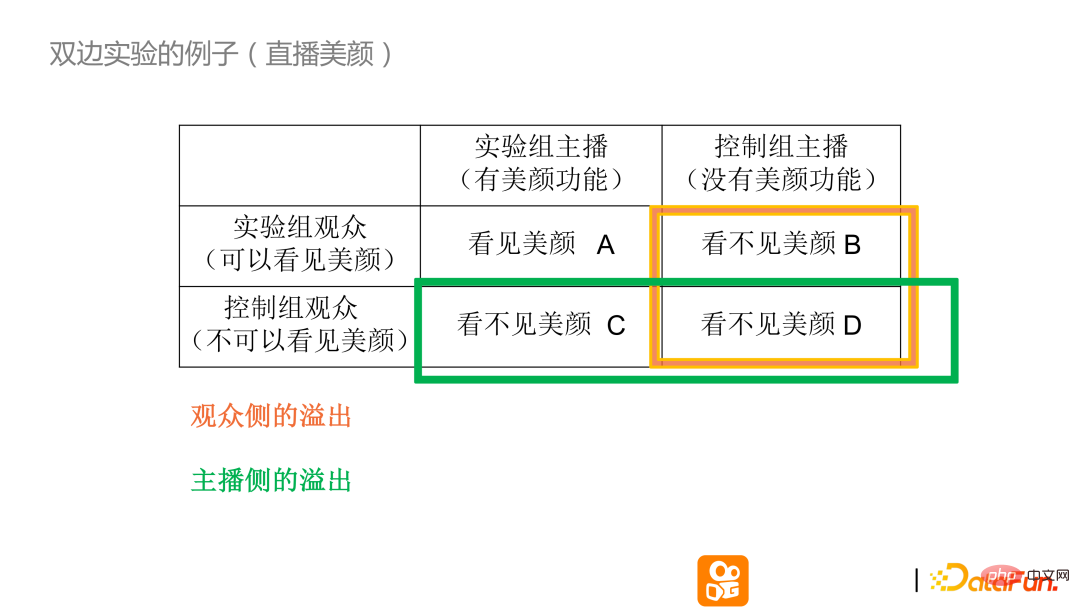
Ici utilise un exemple de beauté en direct pour aider tout le monde à mieux comprendre les expériences bilatérales.
Supposons que l'effet beauté soit ajouté à la scène de diffusion en direct. En regardant de côté depuis la table, les groupes de publics expérimentaux répartis dans les deux rangées contrôlent si le public peut voir la différence avant et après le soin de beauté en direct. Les colonnes du tableau représentent l'impact réel du fait que l'ancre soit belle ou non. En combinant les deux aspects ci-dessus, la fonction d'embellissement sera activée pour la vidéo si et seulement lorsque le présentateur du groupe expérimental se comparera au public du groupe expérimental. En fait, les trois autres groupes ne voient pas la fonction beauté. Mais il y a une différence entre BC ne voyant pas la beauté et D ne voyant pas la beauté. La distinction AD est un scénario courant dans les expériences AB conventionnelles. Cette scène utilise une conception bilatérale pour observer s'il y a un débordement du côté du public.
Il n'y a pas de fonction beauté pour le présentateur. S'il n'y a pas de débordement d'audience, les données BD doivent être cohérentes. Cependant, en fait, s'il y a des différences dans les données BD, si le présentateur n'en a pas. Fonction beauté, le public regardera d'autres ancres. En ce qui concerne la fonction beauté, l'effet réel aura un impact positif ou négatif. De la même manière, le débordement côté ancre peut également se faire via ce type d'expérience bilatérale pour mieux comprendre le mécanisme de l'expérience et s'il y a débordement des deux côtés de l'expérience.
2. Défis des stratégies d'incitation

Au sein de l'écosystème offre-consommateur, la durée de l'activité nécessite un soutien politique au trafic. Il s'agit de la stratégie d'incitation, qui comprend principalement les trois types suivants. Scénario :
(1) L'opération introduit des auteurs de haute qualité, mais la performance des données des auteurs sur la plateforme n'est pas sûre
(2) Certaines entreprises doivent exploiter des types spécifiques de auteurs et fournissent un support de macro-contrôle du trafic et une répartition plus forte du trafic
(3) Dans le scénario de volonté de la plateforme, elle se développe dans une direction spécifique et estime que le changement de la méthode de répartition du trafic renforcera l'offre de certains correspondants ; contenu.
Dans les scénarios ci-dessus, il ne s'agit souvent pas d'une méthode d'apprentissage en ligne, mais d'un macro-contrôle du trafic de la plateforme d'un point de vue humain. Pour ceux qui se concentrent sur le relativement long terme, il faut observer l’effet d’apprentissage (favoriser la production, etc.), et des méthodes telles que la rotation des tranches de temps ne sont pas essayées. Par exemple, le scénario suivant : fournir un support de trafic aux auteurs avec un type de trafic directionnel pour étudier si l'interaction et la production d'un tel trafic peuvent durer longtemps dans un scénario à long terme.
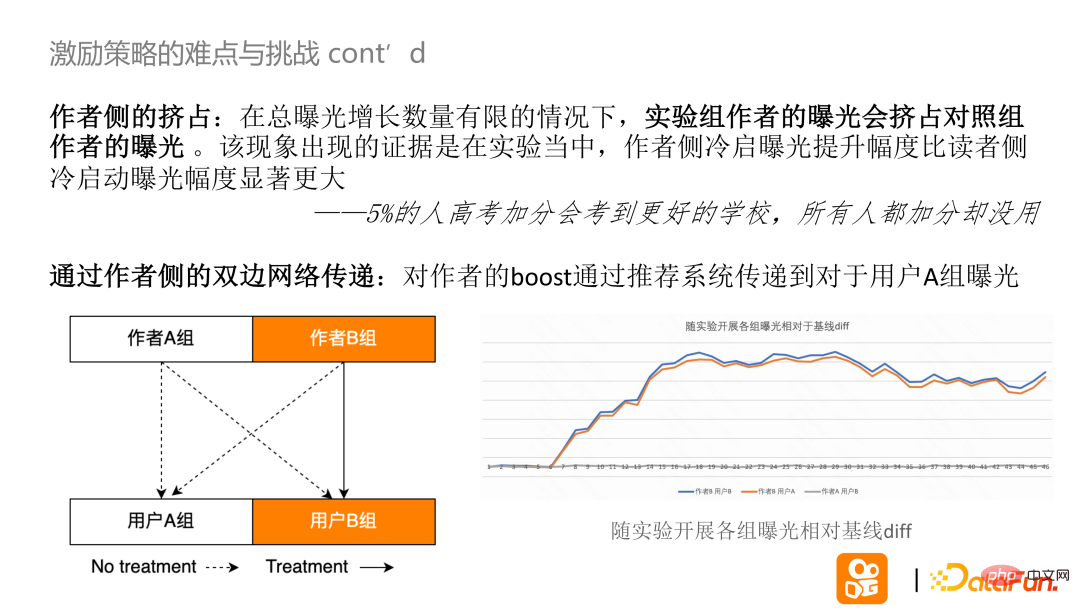
Le premier est la pression du côté de l'auteur : dans la plupart de ces expériences, le nombre total d'expositions sur la plateforme est limité. Dans les scénarios où la plateforme prend en charge la plateforme, l'exposition de la plateforme est limitée. Les auteurs du groupe expérimental augmentent et l'exposition du groupe témoin qui n'est pas pris en charge augmente. Si l’exposition au démarrage à froid de l’auteur augmente plus que celle du lecteur au démarrage à froid, cela prouve qu’il y a foule.
Selon la figure ci-dessus, basée sur la relation entre le groupe expérimental et le groupe témoin et la différence relative de base de l'exposition de chaque groupe, on peut voir qu'au début de l'expérience, le boost de l'auteur finira par être transmis non seulement au groupe d'utilisateurs B mais également au groupe d'utilisateurs B via le système de recommandation. Les différences d'exposition du groupe d'utilisateurs A, de l'auteur B, de l'utilisateur B et de l'auteur B et de l'utilisateur A sont fondamentalement cohérentes. Des expériences traditionnelles ont été consacrées à corriger la situation du trafic faussée par cette stratégie.

SUTVA suppose que l'individu i est uniquement lié au fait qu'il soit affecté au groupe expérimental ou au groupe témoin pendant l'expérience, et n'a rien à voir avec le groupe dans lequel se trouvent les autres nœuds sous le système expérimental, que d'autres nœuds soient ou non des relations de coopération. Il s'agit toujours d'une relation de compétition. SUTVA est l'hypothèse la plus fondamentale pour obtenir des conclusions efficaces dans les expériences AB.
Le réseau bilatéral actuel viole l'hypothèse de la SUTVA.

Dans le scénario vidéo courte, si chaque stratégie d'enregistrement est considérée comme un algorithme de tri. Différentes stratégies d'incitation représentent différents résultats de classement des courtes vidéos. RC dans la figure ci-dessus représente le groupe témoin, RT_25 % est la combinaison de tri d'algorithmes lorsque le trafic du groupe expérimental est de 25 %, et RT représente la poussée expérimentale du groupe expérimental d'une combinaison de tri d'algorithmes à 100 %. BCDE est le type d'utilisateur cible expérimental, c'est-à-dire l'auteur d'incitation sélectionné. Et D signifie que lorsque l'inférence expérimentale est de 25 %, elle tombe exactement dans le groupe expérimental. Supposons que grâce à la méthode de pondération des recommandations, D soit classé directement en première position. Si la stratégie passe à 100%, la BCDE sera pondérée. Dans ce cas, le classement des œuvres D diminuera. Ce scénario est l’encombrement du groupe expérimental et la raison de cet encombrement. 3. Solutions optionnelles de diminue à mesure que le débit du groupe témoin diminue.
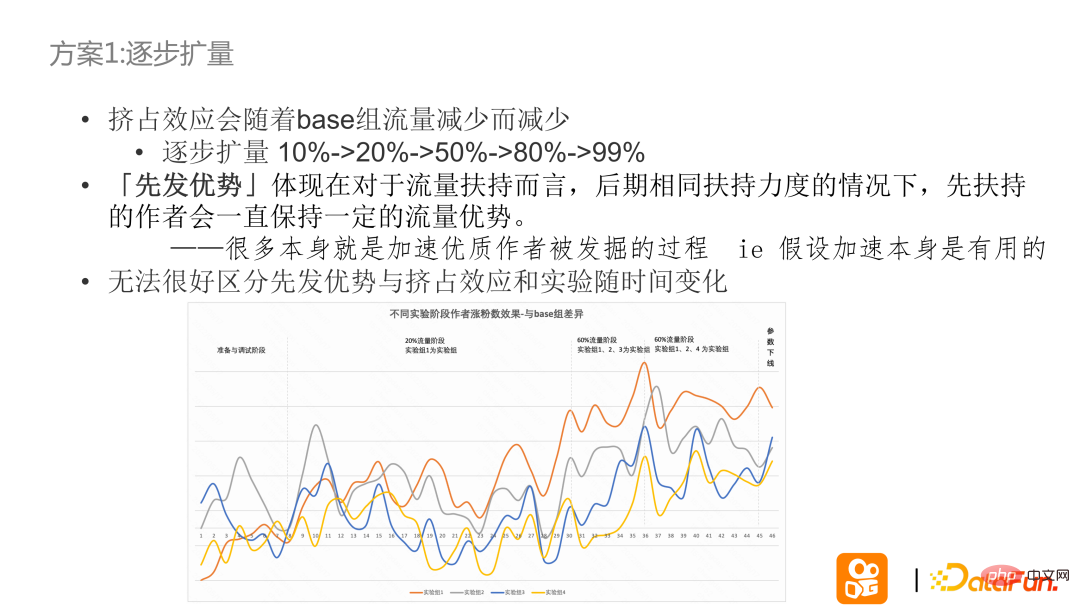
[Avantage du premier arrivant] Au cours de l'expérience, il a été constaté que dans le scénario de support du trafic, à intensité de support égale, soutenir l'auteur en premier maintiendra toujours l'avantage du trafic. La logique d’un soutien antérieur et d’un processus d’excavation accéléré est cohérente.
Détails expérimentaux de l'expansion progressive : La figure ci-dessus montre l'expansion progressive, et l'ordonnée est la différence dans les données de croissance de la poudre par rapport au groupe de base. Au début de l'expérience, 20 % du groupe expérimental ne soutenait que le groupe expérimental 1, et les indicateurs de données du groupe expérimental 1 ont commencé à augmenter ; lorsque l'expérience a augmenté à 60 %, les groupes expérimentaux 123 ont commencé à soutenir et les indicateurs expérimentaux des deux autres groupes ont également commencé à augmenter, mais il n'y avait toujours pas de groupe expérimental dépassé 1 ; a ensuite changé le groupe expérimental à 124 et a constaté que 4 commençait également à s'améliorer, mais 4 ne pouvait toujours pas dépasser le groupe expérimental 3.
De là, nous pouvons tirer la conclusion suivante : une expansion progressive est utile. Les indicateurs augmenteront en fonction de l'expansion. Il est impossible de confirmer si l'augmentation diminuera à mesure que le trafic augmente. Les résultats expérimentaux actuels peuvent conclure que les performances des données du groupe expérimental qui a reçu le support de trafic en premier seront meilleures que celles du groupe expérimental qui a reçu le support de trafic plus tard.
Comme le montre la figure ci-dessus, le groupe expérimental et le groupe témoin sont complètement isolés. Les lecteurs du groupe expérimental ne peuvent voir que les travaux du groupe expérimental, et les lecteurs du groupe témoin ne peuvent voir que les travaux du groupe témoin. groupe. Cela évite une tension entre l'auteur et le lecteur. Une approche similaire consiste à traiter la répartition du trafic entre les auteurs et les lecteurs comme un diagramme de réseau. Ce diagramme de réseau n'est pas connecté partout. Certains lecteurs n'aiment lire que certains types d'œuvres. des groupes expérimentaux peuvent être constitués. Séparation du groupe témoin. L’approche ci-dessus est cohérente avec la méthode de division des petits mondes et donne de meilleurs résultats pratiques, mais en même temps elle entraîne également des coûts de calcul plus élevés. Les principaux problèmes liés à la division du petit monde sont : (1) Le système de recommandation d'algorithmes nécessite une certaine échelle pour démarrer à froid. Lorsque le pool de segmentation doit être petit, cela affectera la personnalisation réelle. espace de distribution. Différentes entreprises et différentes plates-formes ont des exigences différentes en matière de granularité la plus fine de la structure de segmentation, dans le but de conserver l'effet d'élasticité des recommandations. Dans la plupart des cas, des effets marginaux décroissants sont recommandés. (2) Un isolement clair du trafic entraînera certaines restrictions sur le nombre d'expériences et les méthodes d'inspection des échantillons. Pour les scénarios d'expérimentation parallèles, les utilisateurs isolés doivent être constamment divisés et redivisés. Correction à partir de méthodes analytiques au lieu d'un plan expérimental : Les raisons de l'utilisation de méthodes expérimentales de correction : Tout d'abord, il est difficile de vérifier les hypothèses de la méthode de correction d'analyse réelle pour les expériences avec de grandes différences, le débordement et l'élimination du réseau. les effets varient, et il est difficile de le vérifier en peu de temps. Il est impossible d'obtenir une méthode générale en résumant les règles en interne. En fait, notre solution espère résoudre une large classe de problèmes. 

Construire une solution globale
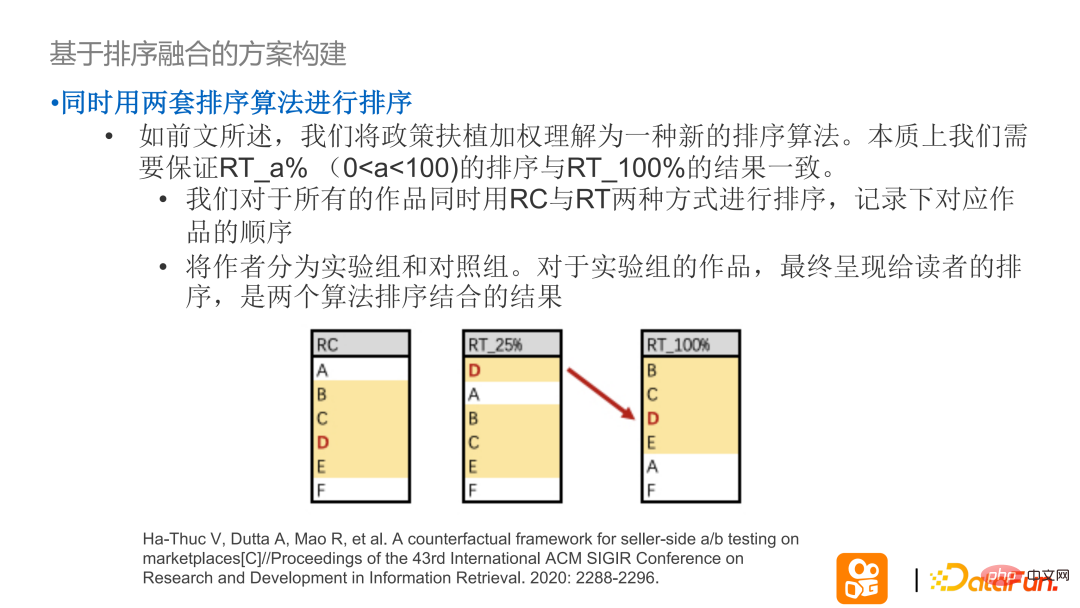
Construction d'une solution basée sur la fusion de classement - essentiellement, nous espérons garantir que le classement du groupe expérimental RT_a% et le classement réel du groupe expérimental RT_100 % peut être maintenu. Des résultats cohérents.
Méthode de mise en œuvre : Tout d'abord, utilisez deux ensembles d'algorithmes de tri RT/RC pour trier en même temps, et enregistrez l'ordre correspondant des œuvres en groupes expérimentaux et groupes témoins, et montrez aux lecteurs les résultats ; des deux algorithmes pour le groupe expérimental Trier l'ordre de fusion.
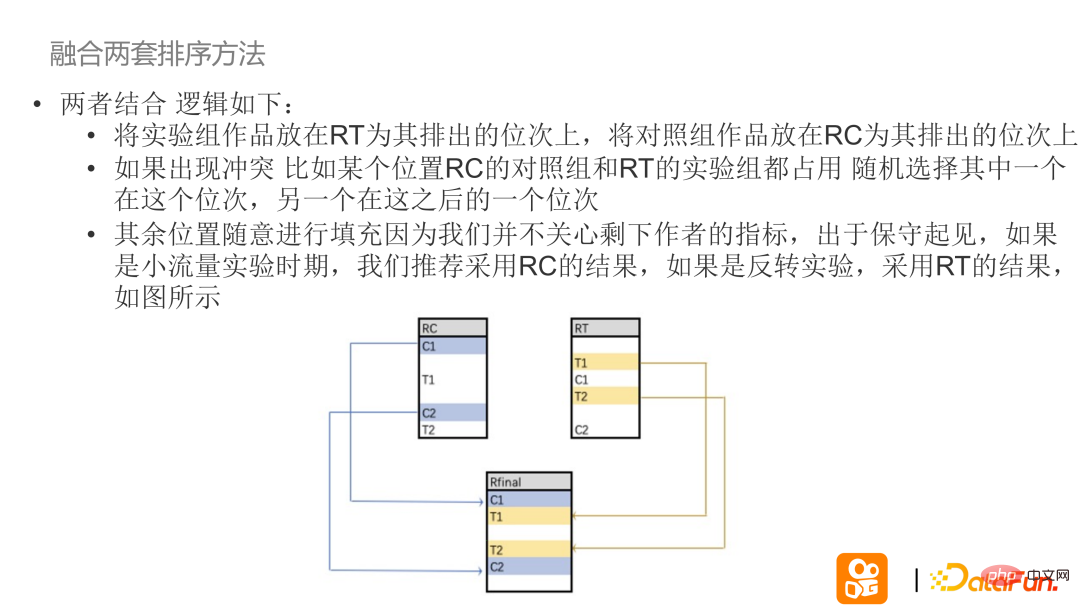
Faire de RC une solution de tri en ligne qui n'est actuellement pas prise en charge par tous les auteurs et élever les droits de tous les auteurs de connaissances dans RT. Après avoir fusionné les résultats de tri de RC et RT, placer d'abord les auteurs (T1T2) correspondant au RT du groupe expérimental dans la position de tri correspondante du groupe final, et conserver les auteurs du groupe témoin dans un ordre sans rapport avec l'original expérience. Par mesure de prudence, pendant la période de faible trafic, il est recommandé qu'à l'exception des travaux expérimentaux, les autres ouvrages soient exécutés dans l'ordre initial. Si l’expérience a été extrapolée, les résultats de RT seront pleinement utilisés.

Et si le groupe expérimental et le groupe témoin se disputaient le même poste ?
Selon le plan expérimental ci-dessus, si les œuvres du groupe expérimental et du groupe témoin sont en compétition pour le même poste, le moyen le plus simple est de sélectionner au hasard. La probabilité que cela se produise est très faible.
Si le groupe expérimental et le groupe témoin ont tous deux un% du trafic total, en supposant a=2,
En supposant que 10 œuvres sont promues à la fois, la probabilité que les 10 meilleures œuvres du groupe expérimental et du groupe témoin apparaissent est calculée comme le montre la figure ci-dessus, qui est d'environ 3,3 %. Si les deux algorithmes sont complètement indépendants, la probabilité de conflit dans les mêmes top 10 est plus faible.
Souvent, les améliorations sont progressives, avec RC et RT hautement corrélés et moins conflictuels. Dans le même temps, la probabilité de conflits peut également être estimée à l’avance grâce à des tests hors ligne.
Les principales évaluations des indicateurs des expériences bilatérales ci-dessus peuvent être divisées dans les trois catégories suivantes :
- Indicateurs côté auteur : nombre d'œuvres, nombre d'auteurs de production, directement inspectés du côté de l'auteur ; Indicateurs de volume de vues du rapport : CTR, EVTR, l'augmentation de l'exposition des œuvres de l'auteur = l'augmentation du nombre de vues des lecteurs sont calculés
- Indicateurs côté lecteur : Expérimental unilatéral côté lecteur ; vérification.
Tout d'abord, toute solution aura des problèmes. Les fortes retombées des marchés bifaces font qu’il est difficile de résoudre tous les problèmes avec une seule solution.
Les principaux problèmes de la conception expérimentale actuelle incluent les aspects suivants :
(1) Tout d'abord, il y a un certain coût du côté de l'ingénierie pour conserver deux ensembles d'incitations politiques de tri. sont utilisés, il vaudra mieux faire avancer l'algorithme. Il n'est pas facile de conserver deux ensembles d'angles sans fusion
(2) Deuxièmement, du point de vue de l'isolation des données de l'algorithme, une partie de l'amélioration vient de ; les données elles-mêmes et le modèle lui-même ont subi des changements majeurs. En conséquence, la logique de l'algorithme de tri n'est plus établie.
(3) Troisièmement, le calcul suppose a = 2 %, la valeur de a peut-elle être augmentée si davantage de trafic teste de petits effets ? Sélectionnez au hasard un mélange proportionnel pour réduire la probabilité de conflits de circulation plus importants. Enfin, les questions bilatérales seront résolues de manière unilatérale. La question de savoir si elles peuvent être résolues de manière bilatérale sera examinée à l'avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou
Apr 15, 2023 pm 07:40 PM
Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou
Apr 15, 2023 pm 07:40 PM
1. Contexte du problème 1. Introduction à l'expérience du marché biface Le marché biface, c'est-à-dire une plateforme, comprend deux participants, producteurs et consommateurs, et les deux parties se promeuvent mutuellement. Par exemple, Kuaishou a un producteur vidéo et un consommateur vidéo, et les deux identités peuvent se chevaucher dans une certaine mesure. L'expérimentation bilatérale est une méthode expérimentale qui combine des groupes du côté des producteurs et des consommateurs. Les expériences bilatérales présentent les avantages suivants : (1) L'impact de la nouvelle stratégie sur deux aspects peut être détecté simultanément, tels que les changements dans le DAU du produit et le nombre de personnes téléchargeant des œuvres. Les plateformes bilatérales ont souvent des effets de réseau transversaux. Plus il y a de lecteurs, plus les auteurs seront actifs, et plus les auteurs seront actifs, plus les lecteurs suivront. (2) Le débordement et le transfert d'effet peuvent être détectés. (3) Aidez-nous à mieux comprendre le mécanisme d'action. L'expérience AB elle-même ne peut pas nous dire la relation entre la cause et l'effet, seulement.
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Google utilise l'IA pour briser le sceau de dix ans de l'algorithme de tri. Elle est exécutée des milliards de fois chaque jour, mais les internautes disent que c'est la recherche la plus irréaliste ?
Jun 22, 2023 pm 09:18 PM
Google utilise l'IA pour briser le sceau de dix ans de l'algorithme de tri. Elle est exécutée des milliards de fois chaque jour, mais les internautes disent que c'est la recherche la plus irréaliste ?
Jun 22, 2023 pm 09:18 PM
Tri | Nuka-Cola, Chu Xingjuan Les amis qui ont suivi des cours d'informatique de base doivent avoir personnellement conçu un algorithme de tri, c'est-à-dire utiliser du code pour réorganiser les éléments d'une liste non ordonnée par ordre croissant ou décroissant. C'est un défi intéressant, et il existe de nombreuses façons possibles de le relever. Beaucoup de temps a été investi pour trouver comment accomplir les tâches de tri plus efficacement. En tant qu'opération de base, les algorithmes de tri sont intégrés aux bibliothèques standard de la plupart des langages de programmation. Il existe de nombreuses techniques et algorithmes de tri différents utilisés dans les bases de code du monde entier pour organiser de grandes quantités de données en ligne, mais au moins en ce qui concerne les bibliothèques C++ utilisées avec le compilateur LLVM, le code de tri n'a pas changé depuis plus d'une décennie. . Récemment, l'équipe Google DeepMindAI a développé un
 Comment filtrer et trier les données dans le développement de la technologie Vue
Oct 09, 2023 pm 01:25 PM
Comment filtrer et trier les données dans le développement de la technologie Vue
Oct 09, 2023 pm 01:25 PM
Comment filtrer et trier les données dans le développement de la technologie Vue Dans le développement de la technologie Vue, le filtrage et le tri des données sont des fonctions très courantes et importantes. Grâce au filtrage et au tri des données, nous pouvons rapidement interroger et afficher les informations dont nous avons besoin, améliorant ainsi l'expérience utilisateur. Cet article expliquera comment filtrer et trier les données dans Vue et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre et utiliser ces fonctions. 1. Filtrage des données Le filtrage des données fait référence au filtrage des données qui répondent aux exigences en fonction de conditions spécifiques. Dans Vue, on peut passer comp
 Comment implémenter l'algorithme de tri par sélection en C#
Sep 20, 2023 pm 01:33 PM
Comment implémenter l'algorithme de tri par sélection en C#
Sep 20, 2023 pm 01:33 PM
Comment implémenter l'algorithme de tri par sélection en C# Le tri par sélection (SelectionSort) est un algorithme de tri simple et intuitif. Son idée de base est de sélectionner à chaque fois l'élément le plus petit (ou le plus grand) parmi les éléments à trier et de le placer à la fin de. la séquence triée. Répétez ce processus jusqu'à ce que tous les éléments soient triés. Apprenons-en davantage sur la façon d'implémenter l'algorithme de tri par sélection en C#, ainsi que des exemples de code spécifiques. Création d'une méthode de tri par sélection Tout d'abord, nous devons créer une méthode pour implémenter le tri par sélection. Cette méthode accepte un
 Quels sont les algorithmes de tri des tableaux ?
Jun 02, 2024 pm 10:33 PM
Quels sont les algorithmes de tri des tableaux ?
Jun 02, 2024 pm 10:33 PM
Les algorithmes de tri de tableaux sont utilisés pour organiser les éléments dans un ordre spécifique. Les types courants d'algorithmes incluent : Tri à bulles : échangez les positions en comparant les éléments adjacents. Tri par sélection : recherchez le plus petit élément et remplacez-le par la position actuelle. Tri par insertion : insérez les éléments un par un à la bonne position. Tri rapide : méthode diviser pour mieux régner, sélectionnez l'élément pivot pour diviser le tableau. Tri par fusion : diviser pour mieux régner, tri récursif et fusion de sous-tableaux.
 Swoole Advanced : Comment utiliser le multithreading pour implémenter un algorithme de tri à grande vitesse
Jun 14, 2023 pm 09:16 PM
Swoole Advanced : Comment utiliser le multithreading pour implémenter un algorithme de tri à grande vitesse
Jun 14, 2023 pm 09:16 PM
Swoole est un framework de communication réseau hautes performances basé sur le langage PHP. Il prend en charge la mise en œuvre de plusieurs modes IO asynchrones et de plusieurs protocoles réseau avancés. Sur la base de Swoole, nous pouvons utiliser sa fonction multi-threading pour implémenter des opérations algorithmiques efficaces, telles que des algorithmes de tri à grande vitesse. L'algorithme de tri à grande vitesse (QuickSort) est un algorithme de tri courant. En localisant un élément de référence, les éléments sont divisés en deux sous-séquences. Celles plus petites que l'élément de référence sont placées à gauche et celles supérieures ou égales à la référence. L'élément est placé à droite. Ensuite, les sous-séquences gauche et droite sont placées par récursion.
 Comment utiliser l'algorithme de tri par base en C++
Sep 19, 2023 pm 12:15 PM
Comment utiliser l'algorithme de tri par base en C++
Sep 19, 2023 pm 12:15 PM
Comment utiliser l'algorithme de tri par base en C++ L'algorithme de tri par base est un algorithme de tri non comparatif qui termine le tri en divisant les éléments à trier en un ensemble limité de chiffres. En C++, nous pouvons utiliser l’algorithme de tri par base pour trier un ensemble d’entiers. Ci-dessous, nous verrons en détail comment implémenter l'algorithme de tri par base, avec des exemples de code spécifiques. Idée d'algorithme L'idée de l'algorithme de tri par base est de diviser les éléments à trier en un ensemble limité de bits numériques, puis de trier les éléments sur chaque bit tour à tour. Le tri sur chaque bit est terminé
