
 développement back-end
Tutoriel Python
Arrangement détaillé Python multi-thread et multi-processus
développement back-end
Tutoriel Python
Arrangement détaillé Python multi-thread et multi-processus
Arrangement détaillé Python multi-thread et multi-processus


La différence entre les threads et les processus
Le processus et le thread sont des concepts de base du système d'exploitation, mais ils sont relativement abstraits et difficiles à maîtriser. Concernant le multi-processus et le multi-threading, la phrase la plus classique dans les manuels scolaires est « Un processus est la plus petite unité d'allocation de ressources, et un thread est la plus petite unité de planification du CPU ». Un thread est un flux de contrôle séquentiel unique dans un programme. Unité d'exécution relativement indépendante et planifiable au sein d'un processus. Il s'agit de l'unité de base permettant au système de planifier et d'allouer indépendamment le processeur. Il fait référence à l'unité de planification d'un programme en cours d'exécution. L’exécution de plusieurs threads en même temps pour effectuer différentes tâches dans un seul programme est appelée multithreading.
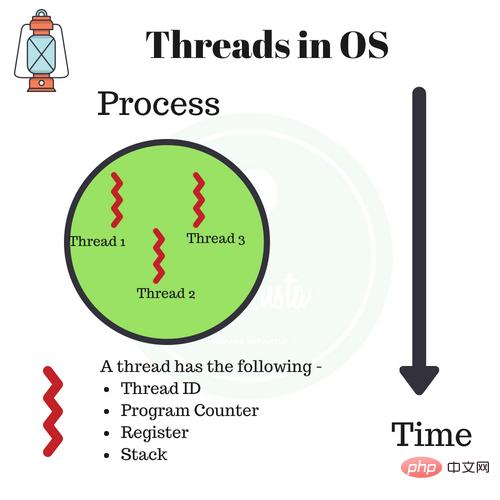
La différence entre les processus et les threads
Un processus est l'unité de base de l'allocation des ressources. Toutes les ressources liées au processus sont enregistrées dans le PCB du bloc de contrôle du processus. Pour indiquer que le processus possède ces ressources ou les utilise. De plus, le processus est également l’unité de planification qui préempte le processeur et dispose d’un espace d’adressage virtuel complet. Lorsque des processus sont planifiés, différents processus disposent d'espaces d'adressage virtuels différents et différents threads au sein d'un même processus partagent le même espace d'adressage.
Correspondant à un processus, un thread n'a rien à voir avec l'allocation des ressources. Il appartient à un certain processus et partage les ressources du processus avec d'autres threads du processus. Un thread se compose uniquement des registres de pile pertinents (pile système ou pile utilisateur) et de la table de contrôle de thread TCB. Les registres peuvent être utilisés pour stocker des variables locales dans un thread, mais ne peuvent pas stocker de variables liées à d'autres threads.
Habituellement, un processus peut contenir plusieurs threads, qui peuvent utiliser les ressources possédées par le processus. Dans les systèmes d'exploitation qui introduisent des threads, les processus sont généralement considérés comme l'unité de base de l'allocation des ressources, et les threads sont considérés comme l'unité de base du fonctionnement indépendant et de la planification indépendante.
Étant donné que les threads sont plus petits que les processus et ne possèdent fondamentalement pas de ressources système, la surcharge nécessaire à leur planification sera beaucoup plus petite, ce qui peut augmenter plus efficacement le degré d'exécution simultanée entre plusieurs programmes du système, améliorant ainsi considérablement l'utilisation des ressources système et débit.
Ainsi, les systèmes d'exploitation à usage général lancés ces dernières années ont introduit des threads pour améliorer encore la concurrence du système et le considèrent comme un indicateur important des systèmes d'exploitation modernes.
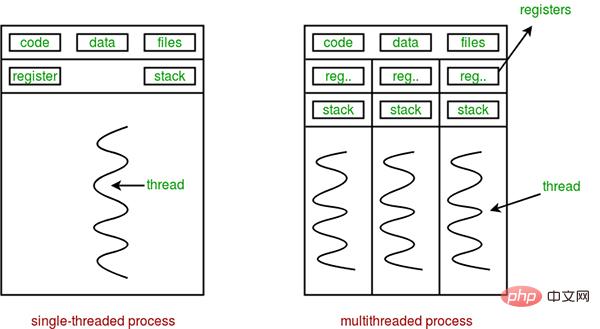
La différence entre les threads et les processus peut être résumée par les quatre points suivants :
- Espace d'adressage et autres ressources (telles que les fichiers ouverts) : les processus sont indépendants les uns des autres et partagés entre les threads d'un même processus. Les threads d'un processus ne sont pas visibles dans les autres processus.
- Communication : communication inter-processus IPC, les threads peuvent directement lire et écrire des segments de données de processus (tels que des variables globales) pour communiquer - cela nécessite l'assistance de moyens de synchronisation de processus et d'exclusion mutuelle pour garantir la cohérence des données.
- Planification et commutation : le changement de contexte de thread est beaucoup plus rapide que le changement de contexte de processus.
- Dans un OS multithread, un processus n'est pas une entité exécutable.
Comparaison de multi-processus et multi-thread
Dimensions de comparaison |
Multi-processus | Multi-threading |
Résumé |
|
Partage et synchronisation des données Le partage de données est complexe, la synchronisation est simple beaucoup de mémoire, commutation complexe, utilisation du processeur Faible |
Occupe moins de mémoire, commutation simple, utilisation élevée du processeur | Les threads dominent | |
| Complexe, lent | Simple, rapide | Les threads dominent | |
| Programmation simple et débogage simple | Programmation complexe et débogage complexe | Les processus dominent | Fiabilité |
| Les processus ne s'influenceront pas les uns les autres | Si un thread raccroche, l'ensemble du processus raccrochera |
Dominance du processus |
|
Distribué |
Convient aux multicœurs et multi-machines, facile à étendre à plusieurs machines | Processus Dominate multicœurs appropriés |
En résumé, les processus et les threads peuvent également être comparés aux trains et aux wagons :
- Les threads voyagent sous le processus (un simple wagon ne peut pas fonctionner)
- Un processus peut contenir plusieurs threads (un train peut avoir plusieurs wagons)
- Il est difficile de partager des données entre différents processus (il est difficile pour les passagers d'un train de changer de train, comme lors d'un transfert de gare)
- Les données sont faciles à partager entre différents threads dans le même processus (il est facile de passer d'un wagon à un autre) A au chariot B)
- Les processus consomment plus de ressources informatiques que les threads (l'utilisation de plusieurs trains consomme plus de ressources que plusieurs wagons)
- Les processus ne s'affecteront pas les uns les autres. Si un thread raccroche, l'ensemble du processus raccrochera (un train le fera). n'affecte pas un autre train, mais si le wagon central d'un train prend feu, cela affectera tous les wagons du train)
- Le processus peut être étendu à plusieurs machines, et le processus convient tout au plus au multicœur (différents trains peut être exécuté sur plusieurs Sur la voie, les wagons du même train ne peuvent pas être sur des voies différentes)
- L'adresse mémoire utilisée par le processus peut être verrouillée, c'est-à-dire que lorsqu'un thread utilise de la mémoire partagée, les autres threads doivent attendre cela se termine avant de pouvoir utiliser ce morceau de mémoire. (Par exemple, les toilettes dans le train) - "mutex"
- L'adresse mémoire utilisée par le processus peut limiter l'utilisation (par exemple, un restaurant dans le train, seul un nombre maximum de personnes est autorisé à entrer, si cela est plein, vous devez attendre à la porte, etc. Quelqu'un doit sortir pour entrer) - "Semaphore"
Python Global Interpreter Lock GIL
Global Interpreter Lock (anglais : Global Interpreter Lock, abréviation GIL) n'est pas une fonctionnalité de Python, elle est implémentée. Un concept introduit par l'analyseur Python (CPython). Parce que CPython est l'environnement d'exécution Python par défaut dans la plupart des environnements. Par conséquent, pour beaucoup de gens, CPython est Python, et ils tiennent pour acquis que GIL est un défaut du langage Python. Alors, qu'est-ce que le GIL dans l'implémentation de CPython ? Jetons un coup d'œil à l'explication officielle :
Le mécanisme utilisé par l'interpréteur CPython pour garantir qu'un seul thread exécute le bytecode Python à la fois. Cela simplifie l'implémentation de CPython en créant le modèle objet (y compris les types intégrés critiques tels que). dict) implicitement protégé contre les accès concurrents. Le verrouillage de l'intégralité de l'interpréteur facilite le multithread de l'interpréteur, au détriment d'une grande partie du parallélisme offert par les machines multiprocesseurs.
L'exécution du code Python est effectuée par le virtuel Python. machine (également appelée boucle principale de l'interpréteur, version CPython) à contrôler, Python a été conçu à l'origine pour n'avoir qu'un seul thread s'exécutant dans la boucle principale de l'interpréteur en même temps, c'est-à-dire qu'à tout moment, un seul thread s'exécute dans l'interpréteur. L'accès à la machine virtuelle Python est contrôlé par le Global Interpreter Lock (GIL), qui garantit qu'un seul thread est en cours d'exécution à la fois.
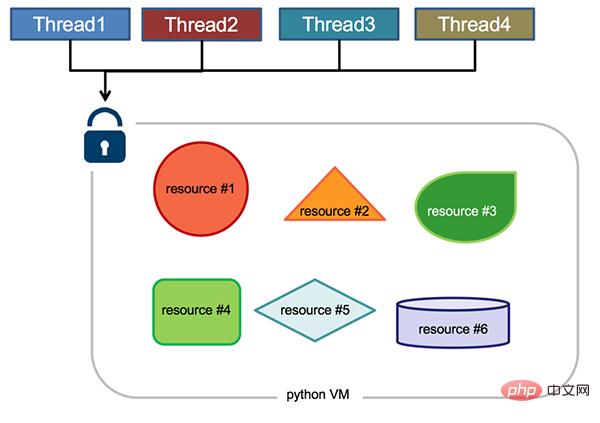
Quels sont les avantages du GIL ? En termes simples, il est plus rapide dans une situation à thread unique et plus pratique lorsqu'il est combiné avec la bibliothèque C, et il n'est pas nécessaire de prendre en compte les problèmes de sécurité des threads. C'était également le scénario d'application le plus courant et l'avantage des premiers Python. De plus, la conception de GIL simplifie la mise en œuvre de CPython, rendant le modèle objet, y compris les types intégrés clés tels que les dictionnaires, implicitement accessibles simultanément. Le verrouillage de l'interpréteur global facilite la mise en œuvre du support multithread, mais il fait également perdre les capacités de calcul parallèle de l'hôte multiprocesseur.
Dans un environnement multithread, la machine virtuelle Python s'exécute comme suit :
- Configurer le GIL
- Basculer vers un thread pour l'exécuter
- Exécuter jusqu'au nombre spécifié d'instructions de bytecode ou jusqu'à ce que le thread abandonne activement le contrôle (vous pouvez appeler sleep(0))
- Mettre le thread en état de veille
- Déverrouiller GIL
- Répétez à nouveau toutes les étapes ci-dessus
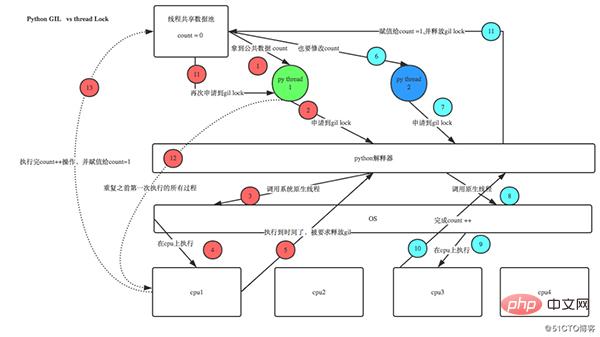
Avant Python 3.2, la logique de publication de GIL était que le thread actuel rencontrait une opération IO ou le nombre de ticks a atteint 100 (les ticks peuvent être considérés comme un compteur de Python lui-même, spécialement utilisé pour GIL, et est réinitialisé à zéro après chaque version. Ce nombre peut être ajusté via sys.setcheckinterval), et libéré. Parce que le thread à forte intensité de calcul demandera immédiatement le GIL après avoir publié le GIL, et généralement il a réacquis le GIL avant que les autres threads n'aient terminé la planification. Cela permettra au thread à forte intensité de calcul d'obtenir le GIL dans un délai très court. GIL sera occupé pendant longtemps, même jusqu'à la fin de l'exécution du thread.
Python 3.2 commence à utiliser le nouveau GIL. La nouvelle implémentation de GIL utilise un délai d'attente fixe pour demander au thread actuel d'abandonner le verrou global. Lorsque le thread actuel détient ce verrou et que d'autres threads demandent ce verrou, le thread actuel sera obligé de libérer le verrou après 5 millisecondes. Cette amélioration améliore la situation où un seul thread occupe le GIL pendant une longue période dans le cas d'un seul cœur.
Sur un processeur monocœur, des centaines de vérifications d'intervalle entraîneront un changement de thread. Sur les processeurs multicœurs, il y a de graves problèmes de thread. Chaque fois que le verrou GIL est libéré, les threads se disputent les verrous et changent de thread, ce qui consomme des ressources. Avec plusieurs threads sous un seul cœur, chaque fois que le GIL est libéré, le thread réveillé peut obtenir le verrou GIL, afin qu'il puisse s'exécuter de manière transparente. Cependant, en mode multicœur, une fois que CPU0 a publié le GIL, les threads sur d'autres processeurs seront en concurrence. mais le GIL peut Il est immédiatement obtenu par CPU0, provoquant le réveil des threads réveillés sur plusieurs autres CPU et l'attente de l'heure de commutation avant d'entrer dans l'état à planifier. Cela entraînera une turbulence des threads, ce qui entraînera une efficacité moindre.
De plus, à partir du mécanisme d'implémentation ci-dessus, on peut déduire que le multithreading de Python est plus convivial pour le code gourmand en E/S que le code gourmand en CPU.
Contre-mesures contre GIL :
- Utiliser une version supérieure de Python (le mécanisme GIL est optimisé)
- Utiliser le multi-processus pour remplacer le multi-threading (il n'y a pas de GIL entre multi-processus, mais le processus lui-même consomme plus de ressources )
- Spécifiez le thread en cours d'exécution du CPU (utilisez le module d'affinité)
- Utilisez des interpréteurs sans GIL tels que Jython et IronPython
- Utilisez uniquement le multi-threading pour les tâches gourmandes en E/S
- Utilisez des coroutines (mode mono-thread efficace, également appelés micro-threads ; généralement utilisés en conjonction avec plusieurs processus)
- Écrivez les composants clés sous forme d'extensions Python en C/C++ et utilisez des ctypes pour que le programme Python appelle directement les fonctions exportées de la bibliothèque de liens dynamiques compilée en langage C. . (avec nogil pour appeler les restrictions GIL)
Le package multitraitement de Python multiprocessing
Le package de threading de Python utilise principalement le développement multi-thread, mais en raison de l'existence de GIL, le multi-threading en Python n'est pas vraiment du multi-threading. Pour utiliser pleinement les ressources d'un processeur multicœur, vous devez utiliser plusieurs processus dans la plupart des cas. Le package multitraitement a été introduit dans Python 2.6, qui réplique complètement un ensemble d'interfaces fournies par threading pour faciliter la migration. La seule différence est qu'il utilise plusieurs processus au lieu de plusieurs threads. Chaque processus possède son propre GIL indépendant, il n'y aura donc aucun conflit de GIL entre les processus.
Avec ce multitraitement, vous pouvez facilement terminer la conversion d'un processus unique à une exécution simultanée. Le multitraitement prend en charge les sous-processus, la communication et le partage de données, effectue différentes formes de synchronisation et fournit des composants tels que Processus, Queue, Pipe et Lock.
Contexte du multitraitement
En plus de gérer le GIL de Python, une autre raison du multitraitement est l'incohérence entre le système d'exploitation Windows et le système Linux/Unix.
Le système d'exploitation Unix/Linux fournit un appel système fork(), ce qui est très spécial. Les fonctions ordinaires sont appelées une fois et renvoient une fois, mais fork() est appelée une fois et renvoie deux fois, car le système d'exploitation copie automatiquement le processus actuel (processus parent) (processus enfant), puis le copie respectivement dans le processus parent et le processus enfant. . retour. Le processus enfant renvoie toujours 0 et le processus parent renvoie l'ID du processus enfant. La raison en est qu'un processus parent peut débourser de nombreux processus enfants, le processus parent doit donc enregistrer l'ID de chaque processus enfant, et le processus enfant n'a besoin que d'appeler getpid() pour obtenir l'ID du processus parent.
Le module os de Python encapsule les appels système courants, y compris fork, qui peuvent facilement créer des sous-processus dans les programmes Python :
import os
print('Process (%s) start...' % os.getpid())
# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))
Les résultats d'exécution du code ci-dessus sous Linux, Unix et Mac sont :
Process (876) start... I (876) just created a child process (877). I am child process (877) and my parent is 876.
Avec l'appel Fork, lorsque un processus reçoit une nouvelle tâche, il peut copier un processus enfant pour gérer la nouvelle tâche. Sur un serveur Apache commun, le processus parent écoute sur le port. Chaque fois qu'il y a une nouvelle requête http, le processus enfant est bifurqué pour la traiter. requête http.
Étant donné que Windows n'a pas d'appel fork, le code ci-dessus ne peut pas s'exécuter sous Windows. Étant donné que Python est multiplateforme, il devrait naturellement fournir une prise en charge multi-processus multiplateforme. Le module multitraitement est une version multiplateforme du module multiprocessus. Le module multitraitement encapsule l'appel fork() afin que nous n'ayons pas besoin de prêter attention aux détails de fork(). Étant donné que Windows n'a pas d'appel fork, le multitraitement doit « simuler » l'effet du fork.
Composants et fonctions communs du multitraitement
Module de création de processus de gestion :
- Processus (utilisé pour créer des processus)
- Pool (utilisé pour créer des pools de processus de gestion)
- File d'attente (utilisée pour la communication des processus, le partage des ressources )
- Value, Array (pour la communication de processus, le partage de ressources)
- Pipe (pour la communication de canal)
- Manager (pour le partage de ressources)
Module de sous-processus de synchronisation :
- Condition (variable de condition)
- Événement (événement)
- Lock (verrouillage mutex)
- RLock (verrouillage mutex réentrant (le même processus peut l'obtenir plusieurs fois sans provoquer de blocage)
- Sémaphore (sémaphore)
Connect Apprenons à utiliser chaque composant et fonction ensemble
Processus (utilisé pour créer des processus)
Le module multitraitement fournit une classe Process pour représenter un objet de processus
En multitraitement, chaque processus est représenté par une classe Process
Méthode de construction : Process([group [, target. [, nom [, args [, kwargs]]]]])
- group:分组,实际上不使用,值始终为None
- target:表示调用对象,即子进程要执行的任务,你可以传入方法名
- name:为子进程设定名称
- args:要传给target函数的位置参数,以元组方式进行传入。
- kwargs:要传给target函数的字典参数,以字典方式进行传入。
实例方法:
- start():启动进程,并调用该子进程中的p.run()
- run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
- terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
- is_alive():返回进程是否在运行。如果p仍然运行,返回True
- join([timeout]):进程同步,主进程等待子进程完成后再执行后面的代码。线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间(超过这个时间,父线程不再等待子线程,继续往下执行),需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
属性介绍:
- daemon:默认值为False,如果设为True,代表p为后台运行的守护进程;当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程;必须在p.start()之前设置
- name:进程的名称
- pid:进程的pid
- exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
- authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
使用示例:(注意:在windows中Process()必须放到if name == ‘main’:下)
from multiprocessing import Process
import os
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')
Pool(用于创建管理进程池)
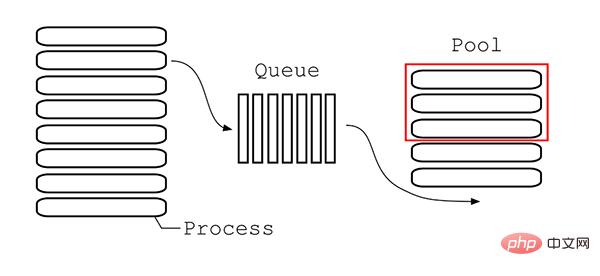
Pool类用于需要执行的目标很多,而手动限制进程数量又太繁琐时,如果目标少且不用控制进程数量则可以用Process类。Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,就重用进程池中的进程。
构造方法:Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
- processes :要创建的进程数,如果省略,将默认使用cpu_count()返回的数量。
- initializer:每个工作进程启动时要执行的可调用对象,默认为None。如果initializer是None,那么每一个工作进程在开始的时候会调用initializer(*initargs)。
- initargs:是要传给initializer的参数组。
- maxtasksperchild:工作进程退出之前可以完成的任务数,完成后用一个新的工作进程来替代原进程,来让闲置的资源被释放。maxtasksperchild默认是None,意味着只要Pool存在工作进程就会一直存活。
- context: 用在制定工作进程启动时的上下文,一般使用Pool() 或者一个context对象的Pool()方法来创建一个池,两种方法都适当的设置了context。
实例方法:
- apply(func[, args[, kwargs]]):在一个池工作进程中执行func(args,*kwargs),然后返回结果。需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async()。它是阻塞的。apply很少使用
- apply_async(func[, arg[, kwds={}[, callback=None]]]):在一个池工作进程中执行func(args,*kwargs),然后返回结果。此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。它是非阻塞。
- map(func, iterable[, chunksize=None]):Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到返回结果。注意,虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
- map_async(func, iterable[, chunksize=None]):map_async与map的关系同apply与apply_async
- imap():imap 与 map的区别是,map是当所有的进程都已经执行完了,并将结果返回了,imap()则是立即返回一个iterable可迭代对象。
- imap_unordered():不保证返回的结果顺序与进程添加的顺序一致。
- close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成。
- join():等待所有工作进程退出。此方法只能在close()或teminate()之后调用,让其不再接受新的Process。
- terminate():结束工作进程,不再处理未处理的任务。
方法apply_async()和map_async()的返回值是AsyncResul的实例obj。实例具有以下方法:
- get():返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发异常。如果远程操作中引发了异常,它将在调用此方法时再次被引发。
- ready():如果调用完成,返回True
- successful():如果调用完成且没有引发异常,返回True,如果在结果就绪之前调用此方法,引发异常
- wait([timeout]):等待结果变为可用。
- terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果p被垃圾回收,将自动调用此函数
<span style="color: rgb(106, 115, 125); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);"># -*- coding:utf-8 -*-</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Queue(用于进程通信,资源共享)</span><br><span style="color: rgb(106, 115, 125); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);"># Pool+map</span><br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">from</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">multiprocessing</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Pool</span><br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">def</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">test</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span>):<br><span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">print</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span>)<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">if</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">__name__</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==</span> <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"__main__"</span>:<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">lists</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">range</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">100</span>)<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Pool</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">8</span>)<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">map</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">test</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">lists</span>)<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">close</span>()<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">join</span>()<br>
<span style="color: rgb(106, 115, 125); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);"># -*- coding:utf-8 -*-</span><br><span style="color: rgb(106, 115, 125); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);"># 异步进程池(非阻塞)</span><br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">from</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">multiprocessing</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Pool</span><br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">def</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">test</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span>):<br><span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">print</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span>)<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">if</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">__name__</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==</span> <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"__main__"</span>:<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Pool</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">8</span>)<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">for</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">in</span> <span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">range</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">100</span>):<br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'''</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">For循环中执行步骤:</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">(1)循环遍历,将100个子进程添加到进程池(相对父进程会阻塞)</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">(2)每次执行8个子进程,等一个子进程执行完后,立马启动新的子进程。(相对父进程不阻塞)</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">apply_async为异步进程池写法。异步指的是启动子进程的过程,与父进程本身的执行(print)是异步的,而For循环中往进程池添加子进程的过程,与父进程本身的执行却是同步的。</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'''</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">apply_async</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">test</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">args</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span>,))<span style="color: rgb(106, 115, 125); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);"># 维持执行的进程总数为8,当一个进程执行完后启动一个新进程.</span><br><span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">print</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"test"</span>)<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">close</span>()<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">join</span>()<br>
<span style="color: rgb(106, 115, 125); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);"># -*- coding:utf-8 -*-</span><br><span style="color: rgb(106, 115, 125); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);"># 异步进程池(非阻塞)</span><br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">from</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">multiprocessing</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Pool</span><br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">def</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">test</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span>):<br><span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">print</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span>)<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">if</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">__name__</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==</span> <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"__main__"</span>:<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Pool</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">8</span>)<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">for</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">in</span> <span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">range</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">100</span>):<br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'''</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">实际测试发现,for循环内部执行步骤:</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">(1)遍历100个可迭代对象,往进程池放一个子进程</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">(2)执行这个子进程,等子进程执行完毕,再往进程池放一个子进程,再执行。(同时只执行一个子进程)</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">for循环执行完毕,再执行print函数。</span><br><span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'''</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">apply</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">test</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">args</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">i</span>,))<span style="color: rgb(106, 115, 125); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);"># 维持执行的进程总数为8,当一个进程执行完后启动一个新进程.</span><br><span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">print</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"test"</span>)<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">close</span>()<br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pool</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">join</span>()<br>
Queue(用于进程通信,资源共享)
在使用多进程的过程中,最好不要使用共享资源。普通的全局变量是不能被子进程所共享的,只有通过Multiprocessing组件构造的数据结构可以被共享。
Queue是用来创建进程间资源共享的队列的类,使用Queue可以达到多进程间数据传递的功能(缺点:只适用Process类,不能在Pool进程池中使用)。
构造方法:Queue([maxsize])
- maxsize是队列中允许最大项数,省略则无大小限制。
实例方法:
- put():用以插入数据到队列。put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
- get():可以从队列读取并且删除一个元素。get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常。若不希望在empty的时候抛出异常,令blocked为True或者参数全部置空即可。
- get_nowait():同q.get(False)
- put_nowait():同q.put(False)
- empty():调用此方法时q为空则返回True,该结果不可靠,比如在返回True的过程中,如果队列中又加入了项目。
- full():调用此方法时q已满则返回True,该结果不可靠,比如在返回True的过程中,如果队列中的项目被取走。
- qsize():返回队列中目前项目的正确数量,结果也不可靠,理由同q.empty()和q.full()一样
使用示例:
from multiprocessing import Process, Queue
import os, time, random
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__ == "__main__":
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
pw.start()
pr.start()
pw.join()# 等待pw结束
pr.terminate()# pr进程里是死循环,无法等待其结束,只能强行终止
JoinableQueue就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
构造方法:JoinableQueue([maxsize])
- maxsize:队列中允许最大项数,省略则无大小限制。
实例方法
JoinableQueue的实例p除了与Queue对象相同的方法之外还具有:
- task_done():使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
- join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止
使用示例:
# -*- coding:utf-8 -*-
from multiprocessing import Process, JoinableQueue
import time, random
def consumer(q):
while True:
res = q.get()
print('消费者拿到了 %s' % res)
q.task_done()
def producer(seq, q):
for item in seq:
time.sleep(random.randrange(1,2))
q.put(item)
print('生产者做好了 %s' % item)
q.join()
if __name__ == "__main__":
q = JoinableQueue()
seq = ('产品%s' % i for i in range(5))
p = Process(target=consumer, args=(q,))
p.daemon = True# 设置为守护进程,在主线程停止时p也停止,但是不用担心,producer内调用q.join保证了consumer已经处理完队列中的所有元素
p.start()
producer(seq, q)
print('主线程')
Value,Array(用于进程通信,资源共享)
multiprocessing 中Value和Array的实现原理都是在共享内存中创建ctypes()对象来达到共享数据的目的,两者实现方法大同小异,只是选用不同的ctypes数据类型而已。
Value
构造方法:Value((typecode_or_type, args[, lock])
- typecode_or_type:定义ctypes()对象的类型,可以传Type code或 C Type,具体对照表见下文。
- args:传递给typecode_or_type构造函数的参数
- lock:默认为True,创建一个互斥锁来限制对Value对象的访问,如果传入一个锁,如Lock或RLock的实例,将用于同步。如果传入False,Value的实例就不会被锁保护,它将不是进程安全的。
typecode_or_type支持的类型:
| Type code | C Type | Python Type | Minimum size in bytes | | --------- | ------------------ | ----------------- | --------------------- | | `'b'` | signed char| int | 1 | | `'B'` | unsigned char| int | 1 | | `'u'` | Py_UNICODE | Unicode character | 2 | | `'h'` | signed short | int | 2 | | `'H'` | unsigned short | int | 2 | | `'i'` | signed int | int | 2 | | `'I'` | unsigned int | int | 2 | | `'l'` | signed long| int | 4 | | `'L'` | unsigned long| int | 4 | | `'q'` | signed long long | int | 8 | | `'Q'` | unsigned long long | int | 8 | | `'f'` | float| float | 4 | | `'d'` | double | float | 8 |
参考地址:https://docs.python.org/3/library/array.html
Array
构造方法:Array(typecode_or_type, size_or_initializer, **kwds[, lock])
- typecode_or_type:同上
- size_or_initializer:如果它是一个整数,那么它确定数组的长度,并且数组将被初始化为零。否则,size_or_initializer是用于初始化数组的序列,其长度决定数组的长度。
- kwds:传递给typecode_or_type构造函数的参数
- lock:同上
使用示例:
import multiprocessing
def f(n, a):
n.value = 3.14
a[0] = 5
if __name__ == '__main__':
num = multiprocessing.Value('d', 0.0)
arr = multiprocessing.Array('i', range(10))
p = multiprocessing.Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
注意:Value和Array只适用于Process类。
Pipe(用于管道通信)
多进程还有一种数据传递方式叫管道原理和 Queue相同。Pipe可以在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道。
构造方法:Pipe([duplex])
- dumplex:默认管道是全双工的,如果将duplex射成False,conn1只能用于接收,conn2只能用于发送。
实例方法:
- send(obj):通过连接发送对象。obj是与序列化兼容的任意对象
- recv():接收conn2.send(obj)发送的对象。如果没有消息可接收,recv方法会一直阻塞。如果连接的另外一端已经关闭,那么recv方法会抛出EOFError。
- close():关闭连接。如果conn1被垃圾回收,将自动调用此方法
- fileno():返回连接使用的整数文件描述符
- poll([timeout]):如果连接上的数据可用,返回True。timeout指定等待的最长时限。如果省略此参数,方法将立即返回结果。如果将timeout射成None,操作将无限期地等待数据到达。
- recv_bytes([maxlength]):接收c.send_bytes()方法发送的一条完整的字节消息。maxlength指定要接收的最大字节数。如果进入的消息,超过了这个最大值,将引发IOError异常,并且在连接上无法进行进一步读取。如果连接的另外一端已经关闭,再也不存在任何数据,将引发EOFError异常。
- send_bytes(buffer [, offset [, size]]):通过连接发送字节数据缓冲区,buffer是支持缓冲区接口的任意对象,offset是缓冲区中的字节偏移量,而size是要发送字节数。结果数据以单条消息的形式发出,然后调用c.recv_bytes()函数进行接收
- recv_bytes_into(buffer [, offset]):接收一条完整的字节消息,并把它保存在buffer对象中,该对象支持可写入的缓冲区接口(即bytearray对象或类似的对象)。offset指定缓冲区中放置消息处的字节位移。返回值是收到的字节数。如果消息长度大于可用的缓冲区空间,将引发BufferTooShort异常。
使用示例:
from multiprocessing import Process, Pipe
import time
# 子进程执行方法
def f(Subconn):
time.sleep(1)
Subconn.send("吃了吗")
print("来自父亲的问候:", Subconn.recv())
Subconn.close()
if __name__ == "__main__":
parent_conn, child_conn = Pipe()# 创建管道两端
p = Process(target=f, args=(child_conn,))# 创建子进程
p.start()
print("来自儿子的问候:", parent_conn.recv())
parent_conn.send("嗯")
Manager(用于资源共享)
Manager()返回的manager对象控制了一个server进程,此进程包含的python对象可以被其他的进程通过proxies来访问。从而达到多进程间数据通信且安全。Manager模块常与Pool模块一起使用。
Manager支持的类型有list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value和Array。
管理器是独立运行的子进程,其中存在真实的对象,并以服务器的形式运行,其他进程通过使用代理访问共享对象,这些代理作为客户端运行。Manager()是BaseManager的子类,返回一个启动的SyncManager()实例,可用于创建共享对象并返回访问这些共享对象的代理。
BaseManager,创建管理器服务器的基类
构造方法:BaseManager([address[, authkey]])
- address:(hostname,port),指定服务器的网址地址,默认为简单分配一个空闲的端口
- authkey:连接到服务器的客户端的身份验证,默认为current_process().authkey的值
实例方法:
- start([initializer[, initargs]]):启动一个单独的子进程,并在该子进程中启动管理器服务器
- get_server():获取服务器对象
- connect():连接管理器对象
- shutdown():关闭管理器对象,只能在调用了start()方法之后调用
实例属性:
- address:只读属性,管理器服务器正在使用的地址
SyncManager,以下类型均不是进程安全的,需要加锁..
实例方法:
- Array(self,*args,**kwds)
- BoundedSemaphore(self,*args,**kwds)
- Condition(self,*args,**kwds)
- Event(self,*args,**kwds)
- JoinableQueue(self,*args,**kwds)
- Lock(self,*args,**kwds)
- Namespace(self,*args,**kwds)
- Pool(self,*args,**kwds)
- Queue(self,*args,**kwds)
- RLock(self,*args,**kwds)
- Semaphore(self,*args,**kwds)
- Value(self,*args,**kwds)
- dict(self,*args,**kwds)
- list(self,*args,**kwds)
使用示例:
import multiprocessing
def f(x, arr, l, d, n):
x.value = 3.14
arr[0] = 5
l.append('Hello')
d[1] = 2
n.a = 10
if __name__ == '__main__':
server = multiprocessing.Manager()
x = server.Value('d', 0.0)
arr = server.Array('i', range(10))
l = server.list()
# 子进程执行方法
def f(Subconn):
time.sleep(1)
Subconn.send("吃了吗")
print("来自父亲的问候:", Subconn.recv())
print(x.value)
print(arr)
print(l)
print(d)
print(n)
同步子进程模块
Lock(互斥锁)
Lock锁的作用是当多个进程需要访问共享资源的时候,避免访问的冲突。加锁保证了多个进程修改同一块数据时,同一时间只能有一个修改,即串行的修改,牺牲了速度但保证了数据安全。Lock包含两种状态——锁定和非锁定,以及两个基本的方法。
构造方法:Lock()
实例方法:
- acquire([timeout]): 使线程进入同步阻塞状态,尝试获得锁定。
- release(): 释放锁。使用前线程必须已获得锁定,否则将抛出异常。
使用示例:
from multiprocessing import Process, Lock
def l(lock, num):
lock.acquire()
print("Hello Num: %s" % (num))
lock.release()
if __name__ == '__main__':
lock = Lock()# 这个一定要定义为全局
for num in range(20):
Process(target=l, args=(lock, num)).start()
RLock(可重入的互斥锁(同一个进程可以多次获得它,同时不会造成阻塞)
RLock(可重入锁)是一个可以被同一个线程请求多次的同步指令。RLock使用了“拥有的线程”和“递归等级”的概念,处于锁定状态时,RLock被某个线程拥有。拥有RLock的线程可以再次调用acquire(),释放锁时需要调用release()相同次数。可以认为RLock包含一个锁定池和一个初始值为0的计数器,每次成功调用 acquire()/release(),计数器将+1/-1,为0时锁处于未锁定状态。
构造方法:RLock()
实例方法:
- acquire([timeout]):同Lock
- release(): 同Lock
Semaphore(信号量)
信号量是一个更高级的锁机制。信号量内部有一个计数器而不像锁对象内部有锁标识,而且只有当占用信号量的线程数超过信号量时线程才阻塞。这允许了多个线程可以同时访问相同的代码区。比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去,如果指定信号量为3,那么来一个人获得一把锁,计数加1,当计数等于3时,后面的人均需要等待。一旦释放,就有人可以获得一把锁。
构造方法:Semaphore([value])
- value:设定信号量,默认值为1
实例方法:
- acquire([timeout]):同Lock
- release(): 同Lock
使用示例:
from multiprocessing import Process, Semaphore
import time, random
def go_wc(sem, user):
sem.acquire()
print('%s 占到一个茅坑' % user)
time.sleep(random.randint(0, 3))
sem.release()
print(user, 'OK')
if __name__ == '__main__':
sem = Semaphore(2)
p_l = []
for i in range(5):
p = Process(target=go_wc, args=(sem, 'user%s' % i,))
p.start()
p_l.append(p)
for i in p_l:
i.join()
Condition(条件变量)
可以把Condition理解为一把高级的锁,它提供了比Lock, RLock更高级的功能,允许我们能够控制复杂的线程同步问题。Condition在内部维护一个锁对象(默认是RLock),可以在创建Condigtion对象的时候把琐对象作为参数传入。Condition也提供了acquire, release方法,其含义与锁的acquire, release方法一致,其实它只是简单的调用内部锁对象的对应的方法而已。Condition还提供了其他的一些方法。
构造方法:Condition([lock/rlock])
- 可以传递一个Lock/RLock实例给构造方法,否则它将自己生成一个RLock实例。
实例方法:
- acquire([timeout]):首先进行acquire,然后判断一些条件。如果条件不满足则wait
- release():释放 Lock
- wait([timeout]): 调用这个方法将使线程进入Condition的等待池等待通知,并释放锁。使用前线程必须已获得锁定,否则将抛出异常。处于wait状态的线程接到通知后会重新判断条件。
- notify(): 调用这个方法将从等待池挑选一个线程并通知,收到通知的线程将自动调用acquire()尝试获得锁定(进入锁定池);其他线程仍然在等待池中。调用这个方法不会释放锁定。使用前线程必须已获得锁定,否则将抛出异常。
- notifyAll(): 调用这个方法将通知等待池中所有的线程,这些线程都将进入锁定池尝试获得锁定。调用这个方法不会释放锁定。使用前线程必须已获得锁定,否则将抛出异常。
使用示例:
import multiprocessing
import time
def stage_1(cond):
"""perform first stage of work,
then notify stage_2 to continue
"""
name = multiprocessing.current_process().name
print('Starting', name)
with cond:
print('{} done and ready for stage 2'.format(name))
cond.notify_all()
def stage_2(cond):
"""wait for the condition telling us stage_1 is done"""
name = multiprocessing.current_process().name
print('Starting', name)
with cond:
cond.wait()
print('{} running'.format(name))
if __name__ == '__main__':
condition = multiprocessing.Condition()
s1 = multiprocessing.Process(name='s1',
target=stage_1,
args=(condition,))
s2_clients = [
multiprocessing.Process(
name='stage_2[{}]'.format(i),
target=stage_2,
args=(condition,),
)
for i in range(1, 3)
]
for c in s2_clients:
c.start()
time.sleep(1)
s1.start()
s1.join()
for c in s2_clients:
c.join()
Event(事件)
Event内部包含了一个标志位,初始的时候为false。可以使用set()来将其设置为true;或者使用clear()将其从新设置为false;可以使用is_set()来检查标志位的状态;另一个最重要的函数就是wait(timeout=None),用来阻塞当前线程,直到event的内部标志位被设置为true或者timeout超时。如果内部标志位为true则wait()函数理解返回。
使用示例:
import multiprocessing
import time
def wait_for_event(e):
"""Wait for the event to be set before doing anything"""
print('wait_for_event: starting')
e.wait()
print('wait_for_event: e.is_set()->', e.is_set())
def wait_for_event_timeout(e, t):
"""Wait t seconds and then timeout"""
print('wait_for_event_timeout: starting')
e.wait(t)
print('wait_for_event_timeout: e.is_set()->', e.is_set())
if __name__ == '__main__':
e = multiprocessing.Event()
w1 = multiprocessing.Process(
name='block',
target=wait_for_event,
args=(e,),
)
w1.start()
w2 = multiprocessing.Process(
name='nonblock',
target=wait_for_event_timeout,
args=(e, 2),
)
w2.start()
print('main: waiting before calling Event.set()')
time.sleep(3)
e.set()
print('main: event is set')
其他内容
multiprocessing.dummy 模块与 multiprocessing 模块的区别:dummy 模块是多线程,而 multiprocessing 是多进程, api 都是通用的。所有可以很方便将代码在多线程和多进程之间切换。multiprocessing.dummy通常在IO场景可以尝试使用,比如使用如下方式引入线程池。
from multiprocessing.dummy import Pool as ThreadPool
multiprocessing.dummy与早期的threading,不同的点好像是在多多核CPU下,只绑定了一个核心(具体未考证)。
参考文档:
- https://docs.python.org/3/library/multiprocessing.html
- https://www.rddoc.com/doc/Python/3.6.0/zh/library/multiprocessing/
Python并发之concurrent.futures
Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码。从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的更高级的抽象,对编写线程池/进程池提供了直接的支持。concurrent.futures基础模块是executor和future。
Executor
Executor是一个抽象类,它不能被直接使用。它为具体的异步执行定义了一些基本的方法。ThreadPoolExecutor和ProcessPoolExecutor继承了Executor,分别被用来创建线程池和进程池的代码。
ThreadPoolExecutor对象
ThreadPoolExecutor类是Executor子类,使用线程池执行异步调用。
class concurrent.futures.ThreadPoolExecutor(max_workers)
使用max_workers数目的线程池执行异步调用。
ProcessPoolExecutor对象
ThreadPoolExecutor类是Executor子类,使用进程池执行异步调用。
class concurrent.futures.ProcessPoolExecutor(max_workers=None)
使用max_workers数目的进程池执行异步调用,如果max_workers为None则使用机器的处理器数目(如4核机器max_worker配置为None时,则使用4个进程进行异步并发)。
submit()方法
Executor中定义了submit()方法,这个方法的作用是提交一个可执行的回调task,并返回一个future实例。future对象代表的就是给定的调用。
Executor.submit(fn, *args, **kwargs)
- fn:需要异步执行的函数
- *args, **kwargs:fn参数
使用示例:
from concurrent import futures def test(num): import time return time.ctime(), num with futures.ThreadPoolExecutor(max_workers=1) as executor: future = executor.submit(test, 1) print(future.result())
map()方法
除了submit,Exectuor还为我们提供了map方法,这个方法返回一个map(func, *iterables)迭代器,迭代器中的回调执行返回的结果有序的。
Executor.map(func, *iterables, timeout=None)
- func:需要异步执行的函数
- *iterables:可迭代对象,如列表等。每一次func执行,都会从iterables中取参数。
- timeout:设置每次异步操作的超时时间,timeout的值可以是int或float,如果操作超时,会返回raisesTimeoutError;如果不指定timeout参数,则不设置超时间。
使用示例:
from concurrent import futures def test(num): import time return time.ctime(), num data = [1, 2, 3] with futures.ThreadPoolExecutor(max_workers=1) as executor: for future in executor.map(test, data): print(future)
shutdown()方法
释放系统资源,在Executor.submit()或 Executor.map()等异步操作后调用。使用with语句可以避免显式调用此方法。
Executor.shutdown(wait=True)
Future
Future可以理解为一个在未来完成的操作,这是异步编程的基础。通常情况下,我们执行io操作,访问url时(如下)在等待结果返回之前会产生阻塞,cpu不能做其他事情,而Future的引入帮助我们在等待的这段时间可以完成其他的操作。
Future类封装了可调用的异步执行。Future 实例通过 Executor.submit()方法创建。
- cancel():试图取消调用。如果调用当前正在执行,并且不能被取消,那么该方法将返回False,否则调用将被取消,方法将返回True。
- cancelled():如果成功取消调用,返回True。
- running():如果调用当前正在执行并且不能被取消,返回True。
- done():如果调用成功地取消或结束了,返回True。
- result(timeout=None):返回调用返回的值。如果调用还没有完成,那么这个方法将等待超时秒。如果调用在超时秒内没有完成,那么就会有一个Futures.TimeoutError将报出。timeout可以是一个整形或者浮点型数值,如果timeout不指定或者为None,等待时间无限。如果futures在完成之前被取消了,那么 CancelledError 将会报出。
- exception(timeout=None):返回调用抛出的异常,如果调用还未完成,该方法会等待timeout指定的时长,如果该时长后调用还未完成,就会报出超时错误futures.TimeoutError。timeout可以是一个整形或者浮点型数值,如果timeout不指定或者为None,等待时间无限。如果futures在完成之前被取消了,那么 CancelledError 将会报出。如果调用完成并且无异常报出,返回None.
- add_done_callback(fn):将可调用fn捆绑到future上,当Future被取消或者结束运行,fn作为future的唯一参数将会被调用。如果future已经运行完成或者取消,fn将会被立即调用。
- wait(fs, timeout=None, return_when=ALL_COMPLETED)
- 等待fs提供的 Future 实例(possibly created by different Executor instances) 运行结束。返回一个命名的2元集合,分表代表已完成的和未完成的
- return_when 表明什么时候函数应该返回。它的值必须是一下值之
- FIRST_COMPLETED :函数在任何future结束或者取消的时候返回。
- FIRST_EXCEPTION :函数在任何future因为异常结束的时候返回,如果没有future报错,效果等于
- ALL_COMPLETED :函数在所有future结束后才会返回。
- as_completed(fs, timeout=None):参数是一个 Future 实例列表,返回值是一个迭代器,在运行结束后产出 Future实例 。
使用示例:
from concurrent.futures import ThreadPoolExecutor, wait, as_completed
from time import sleep
from random import randint
def return_after_5_secs(num):
sleep(randint(1, 5))
return "Return of {}".format(num)
pool = ThreadPoolExecutor(5)
futures = []
for x in range(5):
futures.append(pool.submit(return_after_5_secs, x))
print(1)
for x in as_completed(futures):
print(x.result())
print(2)
参考链接:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle est la raison pour laquelle PS continue de montrer le chargement?
Apr 06, 2025 pm 06:39 PM
Quelle est la raison pour laquelle PS continue de montrer le chargement?
Apr 06, 2025 pm 06:39 PM
Les problèmes de «chargement» PS sont causés par des problèmes d'accès aux ressources ou de traitement: la vitesse de lecture du disque dur est lente ou mauvaise: utilisez Crystaldiskinfo pour vérifier la santé du disque dur et remplacer le disque dur problématique. Mémoire insuffisante: améliorez la mémoire pour répondre aux besoins de PS pour les images à haute résolution et le traitement complexe de couche. Les pilotes de la carte graphique sont obsolètes ou corrompues: mettez à jour les pilotes pour optimiser la communication entre le PS et la carte graphique. Les chemins de fichier sont trop longs ou les noms de fichiers ont des caractères spéciaux: utilisez des chemins courts et évitez les caractères spéciaux. Problème du PS: réinstaller ou réparer le programme d'installation PS.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
La clé du contrôle des plumes est de comprendre sa nature progressive. Le PS lui-même ne fournit pas la possibilité de contrôler directement la courbe de gradient, mais vous pouvez ajuster de manière flexible le rayon et la douceur du gradient par plusieurs plumes, des masques correspondants et des sélections fines pour obtenir un effet de transition naturel.
 Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
La plume PS est un effet flou du bord de l'image, qui est réalisé par la moyenne pondérée des pixels dans la zone de bord. Le réglage du rayon de la plume peut contrôler le degré de flou, et plus la valeur est grande, plus elle est floue. Le réglage flexible du rayon peut optimiser l'effet en fonction des images et des besoins. Par exemple, l'utilisation d'un rayon plus petit pour maintenir les détails lors du traitement des photos des caractères et l'utilisation d'un rayon plus grand pour créer une sensation brumeuse lorsque le traitement de l'art fonctionne. Cependant, il convient de noter que trop grand, le rayon peut facilement perdre des détails de bord, et trop petit, l'effet ne sera pas évident. L'effet de plumes est affecté par la résolution de l'image et doit être ajusté en fonction de la compréhension de l'image et de la saisie de l'effet.
 Que dois-je faire si la carte PS est dans l'interface de chargement?
Apr 06, 2025 pm 06:54 PM
Que dois-je faire si la carte PS est dans l'interface de chargement?
Apr 06, 2025 pm 06:54 PM
L'interface de chargement de la carte PS peut être causée par le logiciel lui-même (corruption de fichiers ou conflit de plug-in), l'environnement système (corruption du pilote ou des fichiers système en raison), ou matériel (corruption du disque dur ou défaillance du bâton de mémoire). Vérifiez d'abord si les ressources informatiques sont suffisantes, fermez le programme d'arrière-plan et publiez la mémoire et les ressources CPU. Correction de l'installation de PS ou vérifiez les problèmes de compatibilité pour les plug-ins. Mettre à jour ou tomber la version PS. Vérifiez le pilote de la carte graphique et mettez-le à jour et exécutez la vérification du fichier système. Si vous résumez les problèmes ci-dessus, vous pouvez essayer la détection du disque dur et les tests de mémoire.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Quel impact la plume de PS a-t-elle sur la qualité de l'image?
Apr 06, 2025 pm 07:21 PM
Quel impact la plume de PS a-t-elle sur la qualité de l'image?
Apr 06, 2025 pm 07:21 PM
Les plumes de PS peuvent entraîner une perte de détails d'image, une saturation des couleurs réduite et une augmentation du bruit. Pour réduire l'impact, il est recommandé d'utiliser un rayon de plumes plus petit, de copier la couche puis de plume, et de comparer soigneusement la qualité d'image avant et après les plumes. De plus, les plumes ne conviennent pas à tous les cas, et parfois les outils tels que les masques conviennent plus à la gestion des bords de l'image.
