
 Périphériques technologiques
IA
Expliquez en termes simples le principe de fonctionnement de ChatGPT
Périphériques technologiques
IA
Expliquez en termes simples le principe de fonctionnement de ChatGPT
Expliquez en termes simples le principe de fonctionnement de ChatGPT

ChatGPT est le dernier modèle de langage publié par OpenAI, qui est considérablement amélioré par rapport à son prédécesseur GPT-3. Semblable à de nombreux modèles linguistiques à grande échelle, ChatGPT peut générer du texte dans différents styles et à des fins différentes, avec de meilleures performances en termes de précision, de détails narratifs et de cohérence contextuelle. Il représente la dernière génération de grands modèles de langage d’OpenAI et est conçu en mettant fortement l’accent sur l’interactivité.
OpenAI utilise une combinaison d'apprentissage supervisé et d'apprentissage par renforcement pour affiner ChatGPT, le composant d'apprentissage par renforcement rendant ChatGPT unique. OpenAI utilise la méthode de formation « apprentissage par renforcement avec retour humain » (RLHF), qui utilise le retour humain dans la formation pour minimiser les résultats inutiles, déformés ou biaisés.
Cet article analysera les limites du GPT-3 et les raisons pour lesquelles il découle du processus de formation. Il expliquera également le principe du RLHF et comprendra comment ChatGPT utilise le RLHF pour surmonter les problèmes du GPT-3. il explorera les limites de cette méthode.
Capabilité contre cohérence dans les grands modèles de langage
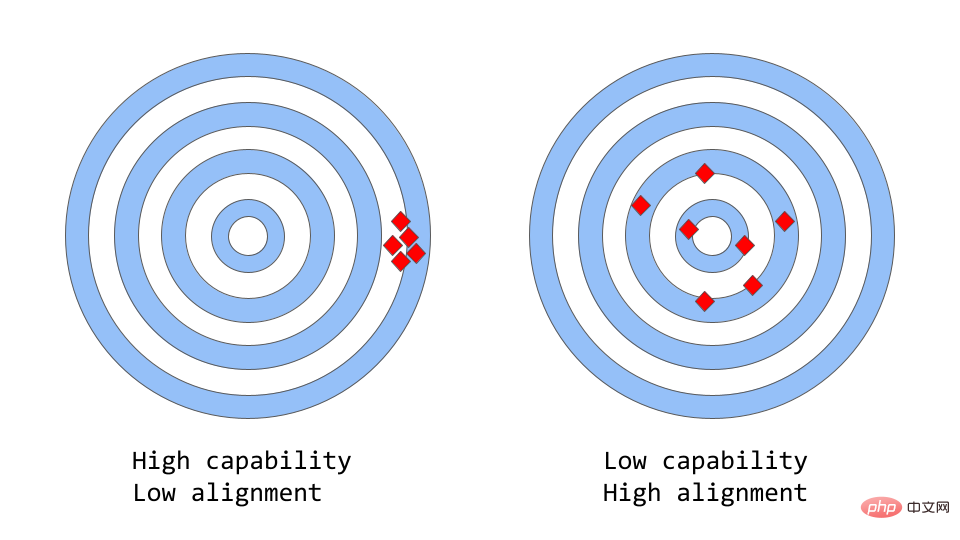
« Cohérence contre capacité » peut être considérée comme une analogie plus abstraite de « Précision contre précision ».
Dans l'apprentissage automatique, la capacité d'un modèle fait référence à la capacité du modèle à effectuer une tâche ou un ensemble de tâches spécifique. La capacité d'un modèle est généralement évaluée par la mesure dans laquelle il est capable d'optimiser sa fonction objective. Par exemple, un modèle utilisé pour prédire les prix du marché peut avoir une fonction objective qui mesure l'exactitude des prévisions du modèle. Un modèle est considéré comme ayant une grande capacité de performance s’il peut prédire avec précision les changements de tarifs au fil du temps.
La cohérence se concentre sur ce que vous voulez réellement que le modèle fasse, et non sur ce pour quoi il a été formé. La question qu'il soulève est de savoir « si la fonction objectif répond aux attentes », en fonction de la mesure dans laquelle les objectifs et les comportements du modèle répondent aux attentes humaines. Supposons que vous souhaitiez entraîner un classificateur d'oiseaux à classer les oiseaux comme « moineaux » ou « merles », en utilisant la perte logarithmique comme objectif de formation, et que le but ultime soit une très grande précision de classification. Le modèle peut avoir une faible perte de log, c'est-à-dire qu'il est plus performant mais moins précis sur l'ensemble de test. Il s'agit d'un exemple d'incohérence, dans lequel le modèle est capable d'optimiser l'objectif de formation mais est incohérent avec l'objectif final.
Le GPT-3 original est un modèle non uniforme. Les grands modèles de langage comme GPT-3 sont formés sur de grandes quantités de données textuelles provenant d'Internet et sont capables de générer du texte de type humain, mais ils ne produisent pas toujours un résultat qui correspond aux attentes humaines. En fait, leur fonction objectif est une distribution de probabilité sur une séquence de mots, utilisée pour prédire quel sera le prochain mot de la séquence.
Mais dans les applications réelles, le but de ces modèles est d'effectuer une certaine forme de travail cognitif précieux, et il existe une nette différence entre la manière dont ces modèles sont formés et la manière dont ils sont censés être utilisés. Bien que mathématiquement parlant, les machines calculant des distributions statistiques de séquences de mots puissent constituer un choix efficace pour modéliser le langage, les humains génèrent le langage en sélectionnant les séquences de texte qui correspondent le mieux à une situation donnée, en utilisant des connaissances de base connues et du bon sens pour faciliter ce processus. Cela peut poser un problème lorsque les modèles linguistiques sont utilisés dans des applications qui nécessitent un degré élevé de confiance ou de fiabilité, telles que les systèmes conversationnels ou les assistants personnels intelligents.
Bien que ces grands modèles entraînés sur d’énormes quantités de données soient devenus extrêmement puissants au cours des dernières années, ils ne parviennent souvent pas à exploiter leur potentiel lorsqu’ils sont utilisés dans la pratique pour faciliter la vie des gens. Les problèmes de cohérence dans les grands modèles de langage se manifestent souvent par :
- Fournir une aide inefficace : ne pas suivre les instructions explicites de l'utilisateur.
- Le contenu est fabriqué : un modèle qui invente des faits inexistants ou erronés.
- Manque d'explicabilité : il est difficile pour les gens de comprendre comment le modèle est arrivé à une décision ou à une prédiction spécifique.
- Content Bias Harmful : Un modèle de langage formé sur des données biaisées et nuisibles peut présenter ce comportement dans sa sortie, même s'il n'est pas explicitement invité à le faire.
Mais d'où vient exactement le problème de cohérence ? La manière dont le modèle linguistique est formé est-elle elle-même sujette à des incohérences ?
Comment les stratégies de formation aux modèles linguistiques créent-elles des incohérences ?
La prédiction du jeton suivant et la modélisation du langage masqué sont les technologies de base utilisées pour former des modèles de langage. Dans la première approche, le modèle reçoit une séquence de mots en entrée et est invité à prédire le mot suivant dans la séquence. Si vous fournissez au modèle la phrase d'entrée :
"Le chat s'est assis sur le"
il pourrait prédire le mot suivant comme "tapis", "chaise" ou "sol" car dans le contexte précédent, ces mots Le la probabilité d'occurrence est élevée ; le modèle linguistique est en fait capable d'évaluer la probabilité de chaque mot possible compte tenu de la séquence précédente. La méthode de modélisation du langage masqué est une variante de la prédiction du prochain jeton dans laquelle certains mots de la phrase d'entrée sont remplacés par des jetons spéciaux, tels que [MASK]. Il est ensuite demandé au modèle de prédire le mot correct qui doit être inséré dans la position du masque. Si le modèle reçoit une phrase :
"Le [MASQUE] est assis sur le "
il peut prédire que les mots qui doivent être renseignés dans la position MASQUE sont "chat" et "chien".L'un des avantages de ces fonctions objectives est qu'elles permettent au modèle d'apprendre la structure statistique du langage, comme les séquences de mots courantes et les modèles d'utilisation des mots. Cela aide souvent le modèle à générer un texte plus naturel et plus fluide, et constitue une étape importante dans la phase de pré-formation de chaque modèle de langage.
Cependant, ces fonctions objectives peuvent également causer des problèmes, principalement parce que le modèle ne peut pas faire la distinction entre les erreurs importantes et les erreurs sans importance. Un exemple très simple est si vous saisissez la phrase dans le modèle :
"L'Empire romain [MASK] avec le règne d'Auguste."
Il peut prédire que la position MASQUE doit être remplie par "commencé" ou ". terminé", Car la probabilité d'apparition de ces deux mots est très élevée.En général, ces stratégies de formation peuvent entraîner des incohérences dans les modèles de langage dans certaines tâches plus complexes, car un modèle entraîné uniquement pour prédire le mot suivant dans une séquence de texte n'apprendra pas nécessairement sa signification. Certaines représentations de niveau supérieur. . Par conséquent, le modèle est difficile à généraliser aux tâches qui nécessitent une compréhension plus approfondie du langage.
Les chercheurs étudient diverses méthodes pour résoudre le problème de cohérence dans les grands modèles de langage. ChatGPT est basé sur le modèle GPT-3 original, mais il a été formé davantage à l'aide de commentaires humains pour guider le processus d'apprentissage afin de résoudre les incohérences du modèle. La technologie spécifique utilisée est la RLHF susmentionnée. ChatGPT est le premier modèle à utiliser cette technologie dans des scénarios réels.
Alors, comment ChatGPT utilise-t-il les commentaires humains pour résoudre le problème de cohérence ?
Apprentissage par renforcement à partir des commentaires humains
L'approche se compose généralement de trois étapes différentes :Réglage supervisé : un modèle de langage pré-entraîné est réglé sur une petite quantité de données étiquetées pour apprendre une politique supervisée (c'est-à-dire Modèle SFT) qui génère une sortie à partir d'une liste donnée d'invites ;
- Simule les préférences humaines : les annotateurs votent sur un nombre relativement grand de sorties du modèle SFT, ce qui crée un nouvel ensemble de données de comparaison. Former un nouveau modèle sur cet ensemble de données, appelé modèle de récompense de formation (RM) ;
- Optimisation de la politique proximale (PPO) : le modèle RM est utilisé pour affiner et améliorer davantage le modèle SFT, et le résultat de sortie du PPO est une stratégie. modèle.
- L'étape 1 n'est effectuée qu'une seule fois, tandis que les étapes 2 et 3 peuvent être répétées en continu : collecter davantage de données de comparaison sur le meilleur modèle de politique actuel pour former un nouveau modèle RM, puis former une nouvelle politique. Ensuite, les détails de chaque étape seront détaillés.
Étape 1 : Modèle de réglage supervisé
La première étape consiste à collecter des données pour former un modèle de politique supervisé.
- Collecte de données : sélectionnez une liste d'invites et l'annotateur note le résultat attendu selon les besoins. Pour ChatGPT, deux sources différentes d'invites sont utilisées : certaines sont préparées directement à l'aide d'annotateurs ou de chercheurs, et d'autres sont obtenues à partir des requêtes API d'OpenAI (c'est-à-dire des utilisateurs de GPT-3). Bien que l'ensemble du processus soit lent et coûteux, le résultat final est un ensemble de données relativement petit et de haute qualité (peut-être 12 à 15 000 points de données) qui peut être utilisé pour régler un modèle de langage pré-entraîné.
- Sélection de modèles : les développeurs de ChatGPT ont choisi des modèles pré-entraînés de la série GPT-3.5 plutôt que de régler le modèle GPT-3 d'origine. Le modèle de base utilisé est la dernière version de text-davinci-003 (un modèle GPT-3 optimisé en ajustant le code du programme).
Pour créer un chatbot universel comme ChatGPT, les développeurs s'adaptent à un "modèle de code" plutôt qu'à un modèle de texte brut.
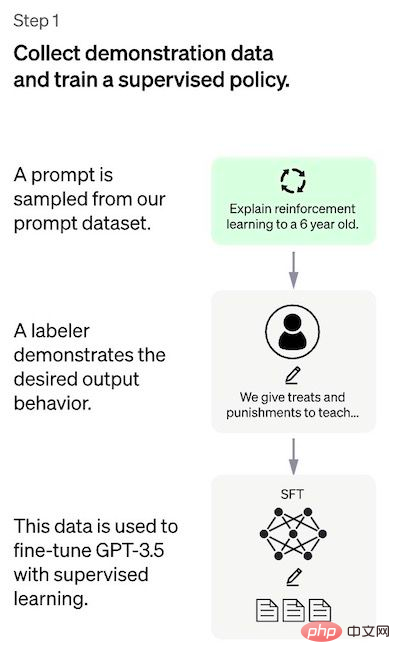
En raison de la quantité limitée de données à cette étape, le modèle SFT obtenu par ce processus peut générer un texte qui ne préoccupe toujours pas l'utilisateur et souffre souvent d'incohérences. Le problème ici est que l’étape d’apprentissage supervisé a un coût d’évolutivité élevé.
Pour surmonter ce problème, la stratégie utilisée consiste à demander à des annotateurs humains de trier les différentes sorties du modèle SFT pour créer le modèle RM, plutôt que de demander aux annotateurs humains de créer un ensemble de données organisé plus grand.
Étape 2 : Entraînement du modèle de récompense
Le but de cette étape est d'apprendre la fonction objectif directement à partir des données. Le but de cette fonction est d'évaluer les résultats du modèle SFT, ce qui représente à quel point ces résultats sont souhaitables pour les humains. Cela reflète fortement les préférences spécifiques des annotateurs humains sélectionnés et les lignes directrices communes qu'ils acceptent de suivre. En fin de compte, ce processus aboutira à un système qui imite les préférences humaines à partir des données.
Comment cela fonctionne :
- Sélectionnez une liste d'invites et le modèle SFT génère plusieurs sorties pour chaque invite (n'importe quelle valeur comprise entre 4 et 9)
- L'annotateur trie la sortie la plus élevée ; Triés du meilleur au pire. Le résultat est un nouvel ensemble de données étiqueté qui fait environ 10 fois la taille de l'ensemble de données exact utilisé pour le modèle SFT
- Ces nouvelles données sont utilisées pour entraîner le modèle RM ; Le modèle prend en entrée les sorties du modèle SFT et les trie par ordre de priorité.
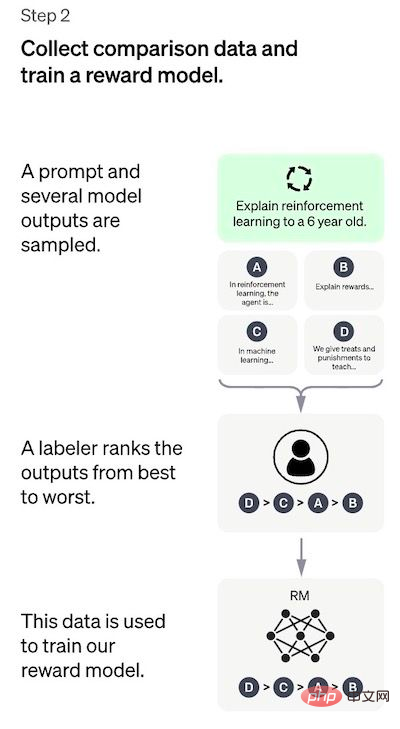
Il est beaucoup plus facile pour l'annotateur de trier le résultat que de l'étiqueter à partir de zéro, et le processus peut évoluer plus efficacement. En pratique, le nombre d'invites sélectionnées est d'environ 30 à 40 000 et comprend différentes combinaisons de sorties triées.
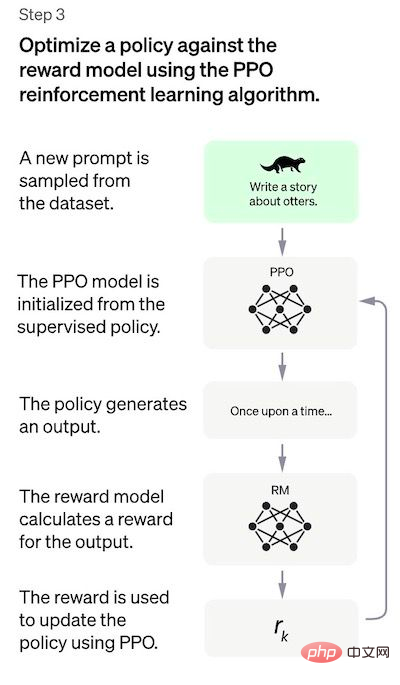
Étape 3 : Affiner le modèle SFT à l'aide du modèle PPO
Dans cette étape, l'apprentissage par renforcement est appliqué pour affiner le modèle SFT en optimisant le modèle RM. L'algorithme spécifique utilisé est appelé optimisation de politique proximale (PPO) et le modèle de réglage est appelé modèle d'optimisation de politique proximale.
Qu'est-ce que la PPO ? Les principales caractéristiques de cet algorithme sont les suivantes :
- PPO est un algorithme de formation des agents à l'apprentissage par renforcement. On l’appelle un algorithme « sur politique » car il apprend et met à jour directement la politique actuelle, plutôt que d’apprendre de l’expérience passée comme l’algorithme « hors politique » de DQN. PPO ajuste en permanence la stratégie en fonction des actions entreprises par l'agent et des récompenses obtenues
- PPO utilise la méthode « d'optimisation de la zone de confiance » pour entraîner la stratégie, ce qui limite dans une certaine mesure la plage de changement de la stratégie ; stratégie précédente pour assurer la stabilité sexuelle. Cela contraste fortement avec d'autres stratégies utilisant des méthodes de gradient, qui effectuent parfois des mises à jour à grande échelle de la politique, déstabilisant ainsi la politique.
- PPO utilise une fonction de valeur pour estimer le retour attendu d'un état ou d'une action donnée ; La fonction valeur est utilisée pour calculer la fonction avantage, qui représente la différence entre les rendements attendus et les rendements actuels. La fonction avantage est ensuite utilisée pour mettre à jour la politique en comparant les actions prises par la politique actuelle avec les actions qu'aurait prises la politique précédente. Cela permet au PPO de procéder à des mises à jour plus éclairées de la stratégie en fonction de la valeur estimée des mesures prises.
Dans cette étape, le modèle PPO est initialisé par le modèle SFT et la fonction valeur est initialisée par le modèle RM. Cet environnement est un « environnement de bandit » qui génère des invites aléatoires et attend des réponses aux invites. Pour une invite et une réponse données, il génère une récompense correspondante (déterminée par le modèle RM). Le modèle SFT ajoute un facteur de pénalité KL à chaque jeton pour tenter d'éviter une sur-optimisation du modèle RM.
Évaluation des performances
Étant donné que le modèle est formé sur la base d'une entrée annotée par l'homme, la partie centrale de l'évaluation est également basée sur l'entrée humaine, c'est-à-dire en demandant aux annotateurs d'évaluer la qualité de la sortie du modèle. Pour éviter de surajuster les jugements des annotateurs impliqués dans la phase de formation, l'ensemble de tests a utilisé des invites d'autres clients OpenAI qui n'apparaissaient pas dans les données de formation.
Le modèle est évalué selon trois critères :
- Servabilité : Juger de la capacité du modèle à suivre les instructions de l'utilisateur et à extrapoler les instructions.
- Vérité : les modèles de jugement ont tendance à produire des faits fictifs dans des tâches en domaine fermé.
- Innocuité : l'annotateur évalue si la sortie du modèle est appropriée et contient un contenu discriminatoire.
Le modèle a également été évalué sur les performances de l'apprentissage zéro-shot sur les tâches PNL traditionnelles telles que la réponse aux questions, la compréhension en lecture et le résumé. Les développeurs ont constaté que le modèle fonctionnait moins bien que GPT-3 sur certaines de ces tâches. . , qui est un exemple de « taxe d’alignement » dans laquelle les procédures d’alignement basées sur l’apprentissage par renforcement par rétroaction humaine se font au détriment de la performance sur certaines tâches.
La régression des performances sur ces ensembles de données peut être considérablement réduite par une astuce appelée mélange de pré-entraînement : lors de l'entraînement du modèle PPO via la descente de gradient, les mises à jour de gradient sont calculées en mélangeant les gradients du modèle SFT et du modèle PPO.
Inconvénients de la méthode
Une limitation très évidente de cette méthode est que les données utilisées pour le modèle de réglage fin sont soumises à une variété de facteurs complexes et subjectifs dans le processus d'alignement du modèle de langage avec l'intention humaine. Les influences incluent principalement :
- Les préférences des annotateurs humains qui génèrent des données de démonstration ;
- Les chercheurs qui conçoivent des études et rédigent des descriptions d'étiquettes
- Sélectionnent les invites créées par les développeurs ou fournies par les clients d'OpenAI ;
- ; Le biais de l'annotateur est inclus à la fois dans la formation du modèle RM et dans l'évaluation du modèle.
Les auteurs de ChatGPT reconnaissent également le fait évident que les annotateurs et les chercheurs impliqués dans le processus de formation peuvent ne pas représenter pleinement tous les utilisateurs finaux potentiels des modèles de langage.
En plus de cette limitation "endogène" évidente, cette méthode présente également d'autres défauts et problèmes qui doivent être résolus :
- Manque d'études contrôlées : les résultats rapportés comparent les performances du modèle PPO final par rapport au modèle SFT. Cela peut être trompeur : comment savez-vous que ces améliorations sont dues au RLHF ? Des études contrôlées sont donc nécessaires, notamment en investissant exactement le même nombre d'heures de travail d'annotation que celui utilisé pour entraîner le modèle RM, afin de créer un ensemble de données plus vaste, organisé et supervisé, avec des données de haute qualité. Cela permet une mesure objective des améliorations de performances des méthodes RLHF par rapport aux méthodes supervisées. En termes simples, l’absence de telles études contrôlées laisse une question fondamentale complètement ouverte : le RLHF fait-il vraiment du bon travail en matière de modélisation cohérente du langage ?
- Les données comparatives manquent de vérité terrain : les annotateurs sont souvent en désaccord sur le classement des résultats du modèle. Techniquement, le risque est qu’une grande quantité de variance soit ajoutée aux données comparatives sans aucune vérité sous-jacente.
- Les préférences humaines ne sont pas homogènes : l'approche RLHF traite les préférences humaines comme homogènes et statiques. Il est évidemment inexact de supposer que tout le monde a les mêmes valeurs. Même s’il existe un grand nombre de valeurs publiques, les humains ont encore de nombreuses perceptions différentes sur de nombreux sujets.
- Test de stabilité de l'invite du modèle RM : aucune expérience ne montre la sensibilité du modèle RM aux modifications d'invite de saisie. Si deux invites sont syntaxiquement différentes mais sémantiquement équivalentes, le modèle RM peut-il montrer une différence significative dans le classement des résultats du modèle ? Autrement dit, quelle est l’importance de la qualité de l’invite pour RM ?
- Autres problèmes : Dans les méthodes RL, les modèles peuvent parfois apprendre à contrôler leurs propres modèles RM pour obtenir les résultats souhaités, conduisant à des « stratégies sur-optimisées ». Cela peut amener le modèle à recréer certains modèles qui, pour une raison inconnue, ont attribué au modèle RM un score plus élevé. ChatGPT corrige ce problème en utilisant la pénalité KL dans la fonction RM.
Lecture connexe :
- Articles connexes sur la méthode RLHF pour ChatGPT : Former des modèles de langage pour suivre les instructions avec des commentaires humains (https://arxiv.org/pdf/2203.02155.pdf), il détaille en fait un modèle appelé InstructionGPT, qu'OpenAI appelle le « modèle frère » de ChatGPT.
- Apprendre à résumer à partir de Human Feedback (https://arxiv.org/pdf/2009.01325.pdf) décrit le RLHF dans le contexte du résumé de texte.
- PPO (https://arxiv.org/pdf/1707.06347.pdf) : article sur l'algorithme PPO.
- Apprentissage par renforcement profond à partir des préférences humaines (https://arxiv.org/abs/1706.03741)
- DeepMind a proposé une alternative à OpenAI RLHF dans Sparrow (https://arxiv.org/pdf/2209.14375 .pdf ) et les fichiers GopherCite (https://arxiv.org/abs/2203.11147).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 La combinaison parfaite de ChatGPT et Python : créer un chatbot de service client intelligent
Oct 27, 2023 pm 06:00 PM
La combinaison parfaite de ChatGPT et Python : créer un chatbot de service client intelligent
Oct 27, 2023 pm 06:00 PM
La combinaison parfaite de ChatGPT et Python : Création d'un chatbot de service client intelligent Introduction : À l'ère de l'information d'aujourd'hui, les systèmes de service client intelligents sont devenus un outil de communication important entre les entreprises et les clients. Afin d'offrir une meilleure expérience de service client, de nombreuses entreprises ont commencé à se tourner vers les chatbots pour effectuer des tâches telles que la consultation des clients et la réponse aux questions. Dans cet article, nous présenterons comment utiliser le puissant modèle ChatGPT et le langage Python d'OpenAI pour créer un chatbot de service client intelligent afin d'améliorer
 Comment installer chatgpt sur un téléphone mobile
Mar 05, 2024 pm 02:31 PM
Comment installer chatgpt sur un téléphone mobile
Mar 05, 2024 pm 02:31 PM
Étapes d'installation : 1. Téléchargez le logiciel ChatGTP depuis le site officiel ou la boutique mobile de ChatGTP ; 2. Après l'avoir ouvert, dans l'interface des paramètres, sélectionnez la langue chinoise 3. Dans l'interface de jeu, sélectionnez le jeu homme-machine et définissez la langue. Spectre chinois ; 4. Après avoir démarré, entrez les commandes dans la fenêtre de discussion pour interagir avec le logiciel.
 Comment développer un chatbot intelligent en utilisant ChatGPT et Java
Oct 28, 2023 am 08:54 AM
Comment développer un chatbot intelligent en utilisant ChatGPT et Java
Oct 28, 2023 am 08:54 AM
Dans cet article, nous présenterons comment développer des chatbots intelligents à l'aide de ChatGPT et Java, et fournirons quelques exemples de code spécifiques. ChatGPT est la dernière version du Generative Pre-training Transformer développé par OpenAI, une technologie d'intelligence artificielle basée sur un réseau neuronal qui peut comprendre le langage naturel et générer du texte de type humain. En utilisant ChatGPT, nous pouvons facilement créer des discussions adaptatives
 Chatgpt peut-il être utilisé en Chine ?
Mar 05, 2024 pm 03:05 PM
Chatgpt peut-il être utilisé en Chine ?
Mar 05, 2024 pm 03:05 PM
chatgpt peut être utilisé en Chine, mais ne peut pas être enregistré, ni à Hong Kong et Macao. Si les utilisateurs souhaitent s'inscrire, ils peuvent utiliser un numéro de téléphone mobile étranger pour s'inscrire. Notez que lors du processus d'enregistrement, l'environnement réseau doit être basculé vers. une adresse IP étrangère.
 Comment créer un robot de service client intelligent en utilisant ChatGPT PHP
Oct 28, 2023 am 09:34 AM
Comment créer un robot de service client intelligent en utilisant ChatGPT PHP
Oct 28, 2023 am 09:34 AM
Comment utiliser ChatGPTPHP pour créer un robot de service client intelligent Introduction : Avec le développement de la technologie de l'intelligence artificielle, les robots sont de plus en plus utilisés dans le domaine du service client. L'utilisation de ChatGPTPHP pour créer un robot de service client intelligent peut aider les entreprises à fournir des services client plus efficaces et personnalisés. Cet article explique comment utiliser ChatGPTPHP pour créer un robot de service client intelligent et fournit des exemples de code spécifiques. 1. Installez ChatGPTPHP et utilisez ChatGPTPHP pour créer un robot de service client intelligent.
 Comment utiliser ChatGPT et Python pour implémenter la fonction de reconnaissance des intentions de l'utilisateur
Oct 27, 2023 am 09:04 AM
Comment utiliser ChatGPT et Python pour implémenter la fonction de reconnaissance des intentions de l'utilisateur
Oct 27, 2023 am 09:04 AM
Comment utiliser ChatGPT et Python pour implémenter la fonction de reconnaissance des intentions des utilisateurs Introduction : À l'ère numérique d'aujourd'hui, la technologie de l'intelligence artificielle est progressivement devenue un élément indispensable dans divers domaines. Parmi eux, le développement de la technologie de traitement du langage naturel (Natural Language Processing, NLP) permet aux machines de comprendre et de traiter le langage humain. ChatGPT (Chat-GeneratingPretrainedTransformer) est une sorte de
 SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
L’Open AI fait enfin son incursion dans la recherche. La société de San Francisco a récemment annoncé un nouvel outil d'IA doté de capacités de recherche. Rapporté pour la première fois par The Information en février de cette année, le nouvel outil s'appelle à juste titre SearchGPT et propose un c
