
 Périphériques technologiques
IA
La vague EDA intelligente arrive, comment ChatGPT aide-t-il à concevoir des puces ?
Périphériques technologiques
IA
La vague EDA intelligente arrive, comment ChatGPT aide-t-il à concevoir des puces ?
La vague EDA intelligente arrive, comment ChatGPT aide-t-il à concevoir des puces ?

Quand vous mentionnez ChatGPT, à quoi pensez-vous ? Quand vous pensez aux chips, à quoi pensez-vous ? Vous pouvez écrire le premier mot qui vous vient à l’esprit après avoir lu cet article, cela changera certainement votre opinion. Si vous êtes un passionné de technologie, votre première impression est que ChatGPT est un modèle de conversation hautement intelligent qui peut communiquer avec les gens. L'industrie des puces est un tout complexe, avec non seulement des concepteurs d'architecture de niveau supérieur, mais également des processus de niveau inférieur. ingénieur. Vous ne pourriez pas combiner les deux parce qu’ils semblent si peu liés.
Mais en fait, la capacité unique de génération de code du modèle ChatGPT accélère considérablement la vitesse de conception des puces. La vague de transformation de l'EDA traditionnelle (Electronic Design Automation) à l'EDA intelligente est sur le point de commencer. Dans l'article d'aujourd'hui, nous examinerons comment l'EDA traditionnelle évolue en EDA intelligente pilotée par ChatGPT, et comment ChatGPT stimule l'innovation dans l'industrie de la conception de puces. chaîne. .
Tout d’abord, examinons une application de ChatGPT à la pointe de l’industrie des puces : le processeur de contrôle quantique est la partie centrale de contrôle de l’ordinateur quantique. Le code d'un processeur de contrôle quantique synthétisé à l'aide de ChatGPT est le suivant.
module QuantumControlProcessor ( input clk, input reset, input [7:0] instruction, input [7:0] control, output reg [7:0] qubit_pulse, output reg [7:0] timing_pulse ); // 此处因为篇幅原因省略实现 endmodule
En fait, ce code peut avoir quelques problèmes mineurs. Par exemple, ChatGPT ne parvient pas à bien contrôler le timing et gaspillera des cycles d'horloge. Cependant, ce code peut être compilé correctement et constitue un plan de conception efficace. Peut-être serez-vous surpris, comment cela se fait-il ? Quelles en sont les perspectives ? La suite de cet article vous donnera la réponse.
Les changements que ChatGPT pourrait apporter au processus de conception des puces
ChatGPT fournira suffisamment de code réutilisable pour l'industrie des puces
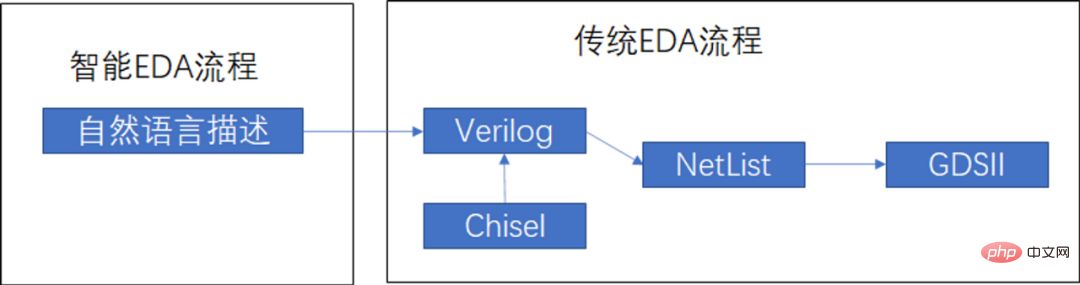
L'énorme quantité de code de conception requise par l'industrie des puces nécessite de toute urgence une solution efficace Outils de développement . La conception de puces est une industrie qui nécessite beaucoup d'accumulation de code. Par exemple, le code open source principal du Xuantie OpenC910 d'Alibaba est d'environ 351 KLOC. Comme le montre la figure 1, l'industrie commence généralement la conception à partir du verilog supérieur, en utilisant les outils front-end et back-end d'EDA pour générer des mises en page. L'écriture de Verilog nécessite un timing de conception, qui est généralement plus complexe, donc ChatGPT peut réduire considérablement les coûts de main-d'œuvre en générant ce morceau de code. Les exigences de synchronisation de la puce sont relativement strictes, il existe donc également un grand nombre de modules liés au timing avec des fonctions relativement fixes, telles que l'interface AXI, FIFO, etc. Ces modules peuvent tous utiliser ChatGPT pour réduire les coûts de main-d'œuvre. Bien qu'il existe actuellement de nouveaux langages de conception matérielle tels que Chisel, Spatial et MyHDL, ces langages sont largement soumis aux limitations du langage hôte et ne peuvent pas décrire les circuits d'une manière proche du langage naturel.
ChatGPT montre une excellente capacité d'expression dans la génération de code. Donnez-lui simplement une invite de tâche et le code correspondant sera automatiquement généré. Par rapport à la synthèse de logiciels et d'algorithmes, étant donné que le code de conception matérielle n'a pas la diversité de scénarios comme le code commercial des logiciels, et que son paramétrage et son contrôle temporel sont complexes par rapport aux capacités cognitives humaines, il existe des modèles fixes à suivre, donc ChatGPT a plus avantages évidents dans la génération automatique du code de conception matérielle. Il possède de bonnes capacités d'induction pour le matériel existant et peut extraire avec précision les points de configuration paramétrables dans le modèle de conception.
L'instructeur de l'auteur, le Dr Wang Ying, chercheur associé à l'Institut de technologie informatique de l'Académie chinoise des sciences, estime que même un ChatGPT entièrement industrialisé ne sera pas en mesure d'apporter les capacités de conception entièrement automatisées idéales à court terme. Cependant, conformément à la tendance du cloud EDA, il devrait rapidement améliorer considérablement l'efficacité de la vérification de la conception en tant qu'assistant de conception et abaisser le seuil de développement, en particulier pour le travail d'enseignement. le niveau d'automatisation démontré par ChatGPT dans divers processus n'est pas sans une meilleure technologie SOTA dans le domaine EDA, mais ChatGPT présente des avantages naturels en termes d'exhaustivité et d'interaction naturelle. Enfin, ChatGPT a vérifié le potentiel des grands modèles dans le domaine de la conception automatisée de puces et peut inciter les développeurs à concevoir davantage le paradigme Prompt par-dessus, laissant ainsi la possibilité d'améliorer encore la précision fonctionnelle de la conception et les performances du jetons générés.
Le niveau intellectuel de ChatGPT dans le domaine de la conception de puces dépasse de loin les travaux similaires précédents
ChatGPT 真的有替代人工的准确性吗?

ChatGPT 和之前最好的代码自动生成的方法比起来好了多少呢?
可以把之前的代码生成方法分为三类,一类是以编程语言社区为代表的基于规则 [11,12,13] 的方法,第二类是基于测试用例的生成方法 [5, 6, 7, 8, 9, 10],第三类是以自然语言处理社区为代表的基于文本和模型的生成方法 [1, 2, 3, 4]。
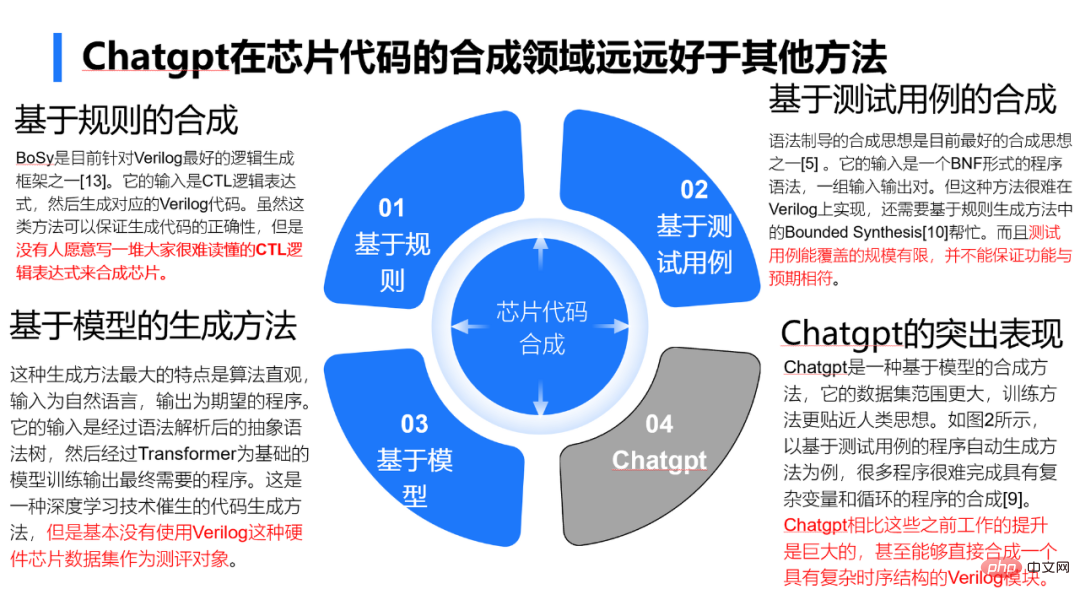
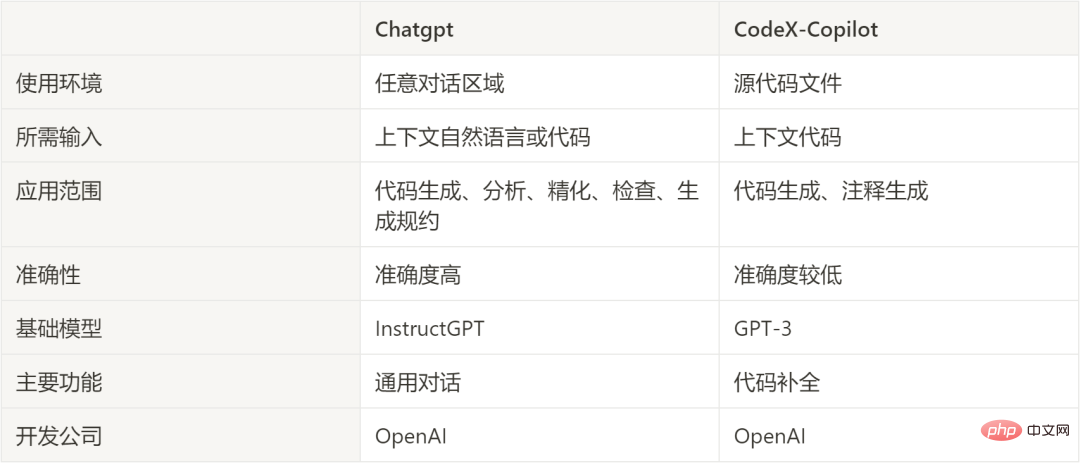
表:比较 OpenAI 两种最新模型用于代码生成

ChatGPT 和 CodeX 都是 OpenAI 公司基于 GPT-3 研发的模型,从上面的分析中可以看出,ChatGPT 的范围更广,并且 Copilot 的用途单一,仅仅为代码补全。这就为基于 ChatGPT 开发智能代码相关工具提供了更广阔的空间。
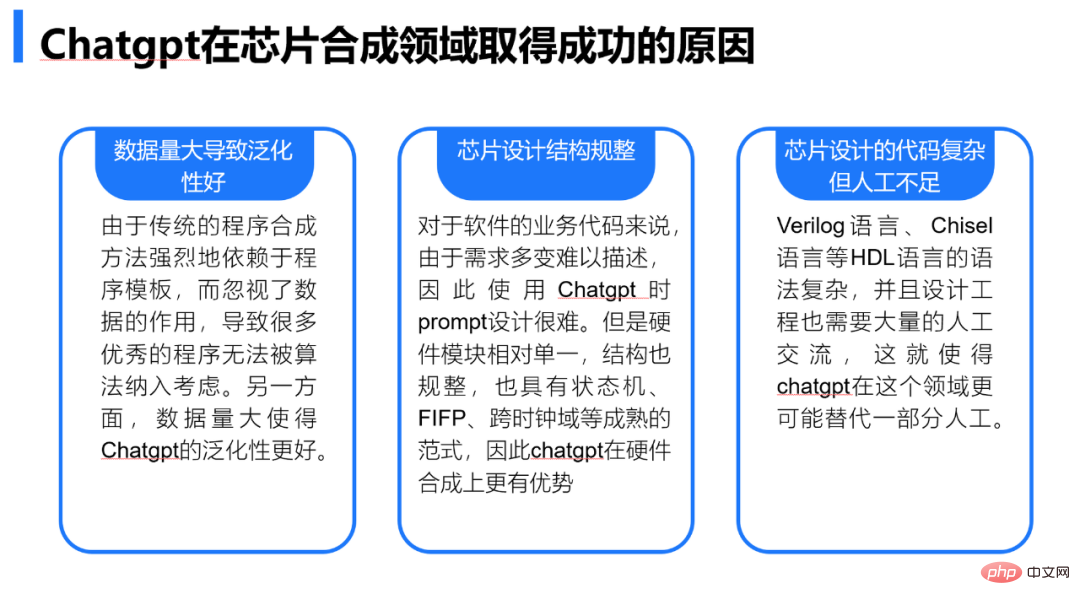
ChatGPT 极大地驱动了智能 EDA 技术的发展
在 ChatGPT 出现之前,就有许多自动化代码生成方式,他们为什么不能够驱动智能 EDA 技术呢?

ChatGPT 在芯片设计代码上有一系列潜在的应用
ChatGPT 能够远远地超越传统方法,并且它可以做到零样本学习(Zero-shot learning),相比传统的程序合成并不需要专门的训练(因为 OpenAI 已经完成了),并且配合细致的功能描述,他庞大的知识储备也可以使能高正确率的代码生成。如表 1 所示,ChatGPT 将会逐渐演变为芯片前端的自动化流程中极为关键的一步,在未来很有可能演变成为继 HLS 开创 C 语言设计芯片后的又一种新的范式。在后文,我们将会介绍如何使用 ChatGPT 做 Verilog 的代码生成。

表 1:ChatGPT 在芯片自动生成各个领域的开创性创新(以 Hardware Design Language 为例,软件语言可以参照分析)
如何使用 ChatGPT 生成芯片代码
与芯片设计相关的程序合成方法包含两类,高层次程序生成和时序相关硬件描述代码生成。高层次程序生成可以生成 HLS 等不具有显式时序控制的 C/C++ 代码等,而低层次程序生成可以生成具有显式时序控制的 Verilog 代码。由于 HLS 在实际工业界设计芯片时较少采用,因此我们采用 Verilog 作为主要的目标语言。对于 ChatGPT 而言,我们以自然语言描述作为输入,就可以获得符合要求的芯片描述代码。具体来说,应该如何做呢?我们以 Verilog 为例介绍如何用 ChatGPT 生成代码。
基于 ChatGPT 的通用生成步骤
act as a professional verilog programmer
因为 ChatGPT 是个通用的代码生成工具,而 Verilog 是个专用领域,我们需要先 “催眠” ChatGPT,使得它能够生成 Verilog 程序。向 ChatGPT 中输入下面的 prompt,之后的生成都会是以 Verilog 代码为基础的。
我们接下来的部分都是以片上网络 NoC 模块为例阐述代码生成方法的通用步骤。

En raison de l'espace limité, le code complet généré par ChatGPT ne sera pas répertorié ici. Mais nous pouvons voir qu'il existe de nombreuses façons différentes de comprendre le mot-clé Réseau sur puce, et ChatGPT a choisi une méthode de compréhension basée sur le bus. Si nous voulons d’autres moyens de compréhension sémantique, nous devons explorer différentes manières de saisir les questions.
Étapes pour combiner et générer des modules
Seuls des modules limités ont été générés auparavant, mais les modules peuvent-ils être combinés ? Notre objectif est de combiner deux modules étranges qui n'existent pas à l'origine en un module non étrange. Un module étrange de niveau supérieur est généré ci-dessous. Il y a deux additionneurs sur la couche inférieure, et leurs sorties sont connectées à un soustracteur. Nous appelons ce module étrange. Le succès de ChatGPT dans la synthèse de puces doit être attribué à sa compréhension du code et à son identification précise de la sémantique du langage naturel.


Bien que le modèle ChatGPT puisse effectuer une partie du travail frontal de conception de puce, il reste encore les défis suivants, qui nécessitent un travail manuel et une chaîne d'outils EDA. Le réglage conjoint peut générer une puce qui répond aux spécifications.
ChatGPT En tant que processus EDA intelligent, il s'agit à la fois d'une crise et d'une opportunité. Il peut remplacer une partie du travail frontal d'EDA, mais comme le back-end EDA s'appuie fortement sur le déterminisme et l'analyse des détails pour obtenir une meilleure structure d'optimisation, il est difficile de prendre en charge le travail d'optimisation back-end d'EDA. Mais cela crée également de nouveaux postes, tels que d’éventuels ingénieurs d’invite de modèles et ingénieurs de correction d’erreurs.
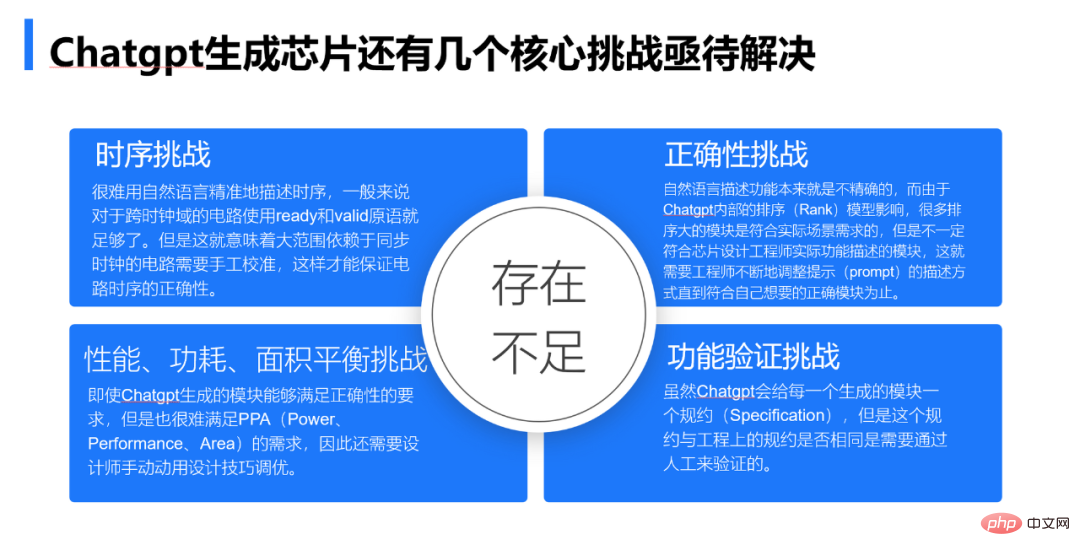
Afin de classer plus clairement les tendances de substituabilité dans l'industrie du silicium aux différents postes, nous avons suivi le processus EDA de haut en bas. est divisé en quatre étapes, à savoir l'étape de conception de l'architecture - l'étape de mise en œuvre du code de la puce - l'étape de réglage du PPA de la puce - l'étape de vérification de la puce, comme le montre la figure 5. Notez que le réglage de la puce fait ici référence au réglage obtenu sur le front-end en modifiant certaines structures matérielles et algorithmes, il est donc répertorié avant la vérification de la puce. Les cases bleues représentent les postes difficiles à remplacer, les cases jaunes représentent les postes faciles à remplacer et les cases grises représentent les postes nouvellement ajoutés. L'analyse suivante de la substituabilité selon des processus spécifiques révèle pourquoi les ingénieurs occupant certains postes sont facilement remplacés par ChatGPT, alors que les ingénieurs occupant certains postes sont difficiles à remplacer par ChatGPT.
Le chercheur Han Yinhe, directeur du Centre de calcul intelligent de l'Institut de technologie informatique de l'Académie chinoise des sciences, estime que ChatGPT peut non seulement aider à accélérer le processus de conception de la puce, mais également apporter une série de défis à la puce. lui-même, qui peuvent être des sujets d'actualité tels que l'intégration du stockage et du calcul, l'intégration des puces et les grandes puces, ainsi que d'autres technologies, donnent naissance aux applications tueuses très attendues.
Processus difficiles à remplacer
Processus nouvellement ajoutés
- Ingénieur de correction de bugs. Étant donné que le programme généré par ChatGPT peut présenter des problèmes détaillés et que certains endroits ne répondent pas aux normes de synchronisation ou de connexion entre les modules, les ingénieurs de correction d'erreurs sont tenus de les corriger.
- Ingénieur d'invite de modèle. La qualité du code généré par ChatGPT est étroitement liée à l'invite de saisie, il est donc nécessaire pour certaines personnes qui connaissent le « caractère » de ChatGPT de concevoir spécialement l'invite afin de générer un code qui répond aux spécifications.
Tendance de développement futur
Sous la vague de l'EDA intelligente, certains postes seront inévitablement remplacés. Alors, dans quel ordre seront-ils remplacés à l'avenir ? Du point de vue de la distribution front-end et back-end, le back-end est hautement irremplaçable en raison de ses tâches détaillées telles que la conception de la mise en page. Pour le front-end, le premier remplaçant est l'ingénieur de module dans l'implémentation des puces, car d'après la pratique de génération de puces ci-dessus, on peut constater que la partie de base de génération de code de module est la plus intuitive. Les postes de remplacement qui apparaîtront après sont des ingénieurs de conception de composants. Cette pièce sera remplacée une fois que les ingénieurs se seront familiarisés avec l'utilisation de ChatGPT pour assembler des modules. Pour d’autres ingénieurs, ChatGPT constitue davantage une valeur auxiliaire qu’un remplacement complet.
Nous pouvons ainsi voir que plus le niveau est élevé, moins il est probable qu'il soit remplacé les parties impliquant une abstraction architecturale ; plus le niveau est bas, moins il est probable qu'il soit remplacé les parties impliquant l'exactitude. L'ordre de remplacement des parties intermédiaires sera ascendant, depuis les modules de base jusqu'aux composants de niveau supérieur.
La politique est de saisir l'opportunité de l'EDA intelligente
L'autonomie et l'absorption complète des avancées mondiales ne sont pas incompatibles. Il existe des raisons complexes pour lesquelles l'EDA traditionnelle et les grands modèles ont fait leurs débuts à OpenAI, mais d'autres sociétés n'ont pas encore rattrapé leur retard. Cependant, les politiques doivent encore se séparer pour détourner une partie des capitaux surchauffés des projets qui résolvent les problèmes d'EDA traditionnels et de grands modèles, et encourager les entreprises à saisir les premières étapes du développement d'EDA intelligent lorsque les barrières industrielles sont faibles, à entrer courageusement dans l'industrie et à construire nouveaux produits. Ce n’est qu’ainsi que nous pourrons résoudre le problème du remplacement constant par les nouvelles technologies. Dans le cas contraire, l'afflux de capitaux en surchauffe dans les industries matures entraînera une baisse du rendement du capital. Dans le même temps, les technologies innovantes ne pourront pas obtenir un soutien financier plus élevé, ce qui incitera les entreprises innovantes à ne pas essayer de commettre des erreurs. augmentent virtuellement les coûts d’essais et d’erreurs des entreprises innovantes, ce qui amène les entreprises innovantes à préférer les technologies éprouvées sur le marché. Par conséquent, les politiques devraient encourager de manière appropriée les entreprises à développer des technologies dérivées basées sur de grands modèles tels que ChatGPT. D'autant plus que les grands modèles ont démontré de solides capacités de génération de code, les entreprises basées sur la technologie EDA intelligente devraient saisir cette opportunité.
L'orientation des investissements du marché des capitaux devrait passer du grand modèle lui-même à ses technologies dérivées
Dans le domaine des technologies de l'information, les technologies avancées continuent de passer du général au spécialisé et évoluent progressivement vers technologies dérivées basées sur des technologies antérieures pour gérer cela est plus évident dans le domaine de la conception d'appareils. Au siècle dernier, les processeurs étaient très populaires, créant des ordinateurs hautes performances. Au début de ce siècle, les GPU sont progressivement devenus populaires, favorisant le développement des jeux. Au cours des dix dernières années, les NPU ont commencé à monter sur scène, permettant ainsi de créer des jeux vidéo. formation et raisonnement sur les réseaux neuronaux économes en énergie. On peut en déduire que lorsque le grand modèle arrivera à maturité, ses technologies dérivées entreront également en scène dans les prochaines années.
La technologie Smart EDA est un dérivé de la technologie des grands modèles. Bien qu’investir dans des technologies dérivées ne semble pas avantageux au début, d’un point de vue économique, le retour sur investissement sera plus élevé jusqu’à ce que cette technologie soit lancée et constitue une barrière technique. À mesure que les technologies de grande envergure telles que ChatGPT mûrissent, les investissements dans les entreprises connaîtront des effets marginaux décroissants. Les investisseurs individuels et les investisseurs institutionnels devraient reconnaître les règles d'investissement des technologies de l'information et se tourner progressivement vers les domaines dérivés des grands modèles, en particulier l'application d'algorithmes basés sur les grands modèles dans le domaine des puces. Les praticiens industriels devraient exploiter pleinement les avantages des fonds importants créés en Chine pour les domaines de l'intelligence artificielle et des circuits intégrés, et postuler activement pour des fonds qui recoupent l'intelligence artificielle et l'EDA. Par conséquent, que ce soit du point de vue de la politique industrielle ou des règles d'investissement, le domaine de l'EDA intelligente est très nécessaire et devrait devenir une cible d'investissement pour les investisseurs chinois.
Littérature connexe
Génération de code basée sur un modèle de texte
[1] Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang et Ming Zhou. 2020. [CodeBERT : Un modèle pré-entraîné pour la programmation et les langages naturels]. Dans Résultats de l'Association pour la linguistique informatique : EMNLP 2020, pages 1536-1547, en ligne. Association for Computational Linguistics.
[2] [GRAPHCODEBERT : PRÉ-FORMATION DES REPRÉSENTATIONS DE CODE AVEC FLUX DE DONNÉES]
[3] [CodeT5 : Modèles d'encodeur-décodeur unifiés pré-entraînés prenant en charge les identifiants pour la compréhension et la génération de code ]
[4] [UniXcoder : pré-formation multimodale unifiée pour la représentation de code]
基于测试用例的代码生成
[5] Alur, Rastislav Bodík, Garvit Juniwal , Milo M. K. Martin, Mukund Raghothaman, Sanjit A. Seshia, Rishabh Singh, Armando Solar-Lezama, Emina Torlak, Abhishek Udupa, [Synthèse guidée par la syntaxe], 2013
[6] Peter-Michael Osera, Steve Zdancewic, [Synthèse de programme dirigée par type et exemple], 2015
[7] John K. Feser, Swarat Chaudhuri, Isil Dillig, [Synthèse des transformations de structure de données à partir d'exemples d'entrée-sortie], 2015
[8 ] Armando Solar-Lezama, [Synthèse de programme par esquisse], 2008
[9] [Kensen Shi], [Jacob Steinhardt], [Percy Liang], FrAngel : Synthèse basée sur des composants avec structures de contrôle, POPL, 2019
[10] Yu Feng, Ruben Martins, Yuepeng Wang, Isil Dillig, Thomas W. Reps, Synthèse basée sur des composants pour les API complexes, [ACM SIGPLAN Notices], 2017
基于逻辑规则的代码生成
[11] Z. Manna et R. Waldinger, « Synthèse : Rêves → Programmes », dans IEEE Transactions on Software Engineering, vol. SE-5, non. 4, pp. 294-328, juillet 1979, doi : 10.1109/TSE.1979.234198.
[12] Bernd Finkbeiner et Sven Schewe, Synthèse limitée, dans Int J Softw Tools Technol Transfer, (2013), 15:519 –539, DOI : 10.1007/s10009-012-0228-z
[13] Peter Faymonville, Bernd Finkbeiner et Leander Tentrup, BoSy : Un cadre d'expérimentation pour la synthèse limitée, CAV 2017
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
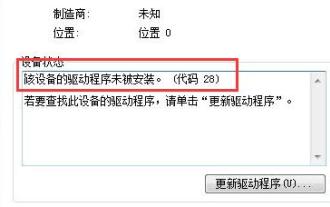 Comment résoudre le code 28 du pilote Win7
Dec 30, 2023 pm 11:55 PM
Comment résoudre le code 28 du pilote Win7
Dec 30, 2023 pm 11:55 PM
Certains utilisateurs ont rencontré des erreurs lors de l'installation du périphérique, provoquant le code d'erreur 28. En fait, cela est principalement dû au pilote. Il nous suffit de résoudre le problème du code de pilote Win7 28. Voyons ce qu'il faut faire. . Que faire avec le code 28 du pilote Win7 : Tout d'abord, nous devons cliquer sur le menu Démarrer dans le coin inférieur gauche de l'écran. Ensuite, recherchez et cliquez sur l'option "Panneau de configuration" dans le menu contextuel. Cette option est généralement située en bas ou près du bas du menu. Après avoir cliqué, le système ouvrira automatiquement l'interface du panneau de configuration. Dans le panneau de configuration, nous pouvons effectuer divers paramètres système et opérations de gestion. C'est la première étape du niveau de nettoyage nostalgique, j'espère que cela aidera. Ensuite, nous devons continuer et entrer dans le système et
 Que faire si le code d'écran bleu 0x0000001 apparaît
Feb 23, 2024 am 08:09 AM
Que faire si le code d'écran bleu 0x0000001 apparaît
Feb 23, 2024 am 08:09 AM
Que faire avec le code d'écran bleu 0x0000001. L'erreur d'écran bleu est un mécanisme d'avertissement en cas de problème avec le système informatique ou le matériel. Le code 0x0000001 indique généralement une panne de matériel ou de pilote. Lorsque les utilisateurs rencontrent soudainement une erreur d’écran bleu lors de l’utilisation de leur ordinateur, ils peuvent se sentir paniqués et perdus. Heureusement, la plupart des erreurs d’écran bleu peuvent être dépannées et traitées en quelques étapes simples. Cet article présentera aux lecteurs certaines méthodes pour résoudre le code d'erreur d'écran bleu 0x0000001. Tout d'abord, lorsque nous rencontrons une erreur d'écran bleu, nous pouvons essayer de redémarrer
 L'ordinateur affiche fréquemment des écrans bleus et le code est différent à chaque fois
Jan 06, 2024 pm 10:53 PM
L'ordinateur affiche fréquemment des écrans bleus et le code est différent à chaque fois
Jan 06, 2024 pm 10:53 PM
Le système Win10 est un très excellent système à haute intelligence. Sa puissante intelligence peut apporter la meilleure expérience utilisateur aux utilisateurs. Dans des circonstances normales, les ordinateurs du système Win10 des utilisateurs n'auront aucun problème ! Cependant, il est inévitable que divers défauts se produisent sur d'excellents ordinateurs. Récemment, des amis ont signalé que leurs systèmes Win10 rencontraient fréquemment des écrans bleus ! Aujourd'hui, l'éditeur vous proposera des solutions aux différents codes qui provoquent des écrans bleus fréquents sur les ordinateurs Windows 10. Jetons un coup d'œil. Solutions aux écrans bleus fréquents de l'ordinateur avec des codes différents à chaque fois : causes des différents codes d'erreur et suggestions de solutions 1. Cause de l'erreur 0×000000116 : Il se peut que le pilote de la carte graphique soit incompatible. Solution : Il est recommandé de remplacer le pilote d'origine du fabricant. 2,
 Résoudre l'erreur du code 0xc000007b
Feb 18, 2024 pm 07:34 PM
Résoudre l'erreur du code 0xc000007b
Feb 18, 2024 pm 07:34 PM
Code de terminaison 0xc000007b Lors de l'utilisation de votre ordinateur, vous rencontrez parfois divers problèmes et codes d'erreur. Parmi eux, le code de terminaison est le plus inquiétant, notamment le code de terminaison 0xc000007b. Ce code indique qu'une application ne peut pas démarrer correctement, provoquant des désagréments pour l'utilisateur. Tout d’abord, comprenons la signification du code de terminaison 0xc000007b. Ce code est un code d'erreur du système d'exploitation Windows qui se produit généralement lorsqu'une application 32 bits tente de s'exécuter sur un système d'exploitation 64 bits. Cela signifie que ça devrait
 Programme de codes à distance universels GE sur n'importe quel appareil
Mar 02, 2024 pm 01:58 PM
Programme de codes à distance universels GE sur n'importe quel appareil
Mar 02, 2024 pm 01:58 PM
Si vous devez programmer un appareil à distance, cet article vous aidera. Nous partagerons les meilleurs codes de télécommande universelle GE pour programmer n’importe quel appareil. Qu'est-ce qu'une télécommande GE ? GEUniversalRemote est une télécommande qui peut être utilisée pour contrôler plusieurs appareils tels que les téléviseurs intelligents, LG, Vizio, Sony, Blu-ray, DVD, DVR, Roku, AppleTV, lecteurs multimédias en streaming et plus encore. Les télécommandes GEUniversal sont disponibles en différents modèles avec différentes caractéristiques et fonctions. GEUniversalRemote peut contrôler jusqu'à quatre appareils. Les meilleurs codes de télécommande universels à programmer sur n'importe quel appareil. Les télécommandes GE sont livrées avec un ensemble de codes qui leur permettent de fonctionner avec différents appareils. vous pouvez
 Comment installer chatgpt sur un téléphone mobile
Mar 05, 2024 pm 02:31 PM
Comment installer chatgpt sur un téléphone mobile
Mar 05, 2024 pm 02:31 PM
Étapes d'installation : 1. Téléchargez le logiciel ChatGTP depuis le site officiel ou la boutique mobile de ChatGTP ; 2. Après l'avoir ouvert, dans l'interface des paramètres, sélectionnez la langue chinoise 3. Dans l'interface de jeu, sélectionnez le jeu homme-machine et définissez la langue. Spectre chinois ; 4. Après avoir démarré, entrez les commandes dans la fenêtre de discussion pour interagir avec le logiciel.
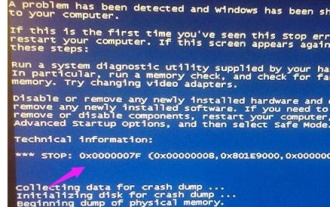 Explication détaillée des causes et des solutions du code d'écran bleu 0x0000007f
Dec 25, 2023 pm 02:19 PM
Explication détaillée des causes et des solutions du code d'écran bleu 0x0000007f
Dec 25, 2023 pm 02:19 PM
L'écran bleu est un problème que nous rencontrons souvent lors de l'utilisation du système. Selon le code d'erreur, il existe de nombreuses raisons et solutions différentes. Par exemple, lorsque nous rencontrons le problème d'arrêt : 0x0000007f, il peut s'agir d'une erreur matérielle ou logicielle. Suivons l'éditeur pour découvrir la solution. Raison du code d'écran bleu 0x000000c5 : Réponse : La mémoire, le processeur et la carte graphique sont soudainement overclockés ou le logiciel ne fonctionne pas correctement. Solution 1 : 1. Continuez à appuyer sur F8 pour entrer lors du démarrage, sélectionnez le mode sans échec et appuyez sur Entrée pour entrer. 2. Après être entré en mode sans échec, appuyez sur win+r pour ouvrir la fenêtre d'exécution, entrez cmd et appuyez sur Entrée. 3. Dans la fenêtre d'invite de commande, saisissez « chkdsk /f /r », appuyez sur Entrée, puis appuyez sur la touche y. 4.
