
 Périphériques technologiques
IA
Aucune annotation manuelle requise, le cadre d'instructions auto-généré élimine le goulot d'étranglement des coûts des LLM tels que ChatGPT
Périphériques technologiques
IA
Aucune annotation manuelle requise, le cadre d'instructions auto-généré élimine le goulot d'étranglement des coûts des LLM tels que ChatGPT
Aucune annotation manuelle requise, le cadre d'instructions auto-généré élimine le goulot d'étranglement des coûts des LLM tels que ChatGPT

ChatGPT est le nouvel acteur majeur du cercle de l'IA à la fin de cette année. Les gens sont étonnés par ses puissantes capacités de langage de questions et réponses et ses connaissances en programmation. Mais plus le modèle est puissant, plus les exigences techniques qui le sous-tendent sont élevées.

ChatGPT est basé sur la série de modèles GPT 3.5, introduisant "données d'annotation manuelles + apprentissage par renforcement" (RLHF) pour affiner continuellement le modèle de langage pré-entraîné, dans le but de permettre de grands modèles de langage (LLM ) pour apprendre à comprendre les commandes humaines et à donner la réponse optimale en fonction de l'invite donnée.
Cette idée technique est la tendance actuelle de développement des modèles de langage. Bien que ce type de modèle ait de grandes perspectives de développement, le coût de la formation et de la mise au point du modèle est très élevé.
Selon les informations actuellement divulguées par OpenAI, le processus de formation de ChatGPT est divisé en trois étapes :
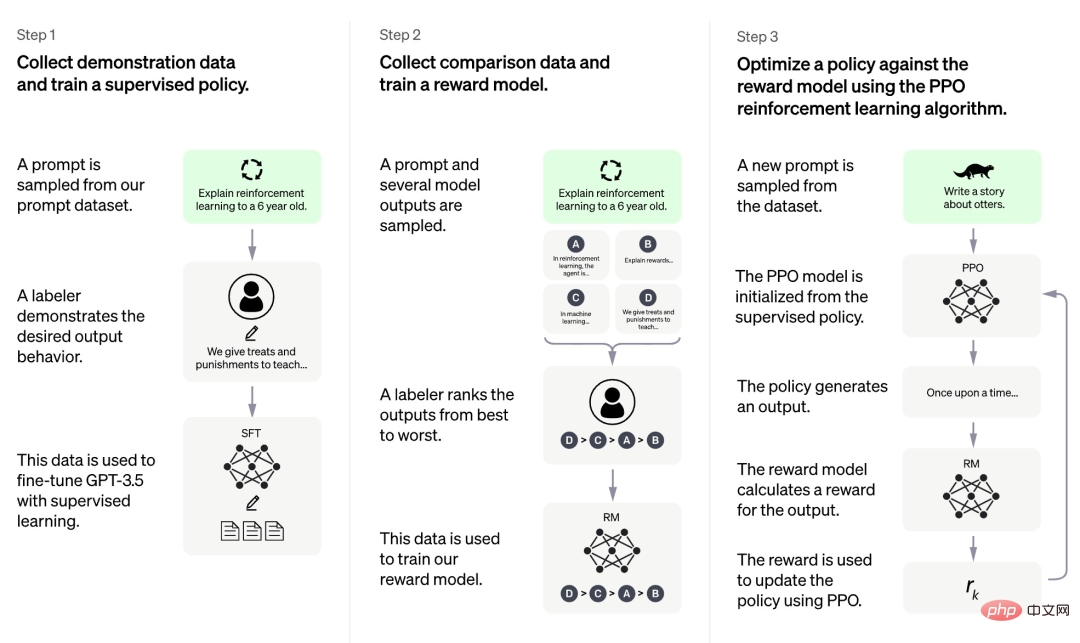
Tout d'abord, la première étape est un modèle de politique supervisé similaire à GPT 3.5. Cette base Il est difficile pour le modèle de comprendre les intentions contenues dans différents types d'instructions humaines, et il est également difficile pour le modèle de juger de la qualité du contenu généré. Les chercheurs ont sélectionné au hasard quelques échantillons dans l'ensemble de données d'invite, puis ont demandé à des annotateurs professionnels de donner des réponses de haute qualité en fonction de l'invite spécifiée. Les invites et leurs réponses correspondantes de haute qualité obtenues grâce à ce processus manuel ont été utilisées pour affiner le modèle de politique supervisé initial afin de fournir une compréhension de base des invites et d'améliorer initialement la qualité des réponses générées.
Dans la deuxième phase, l'équipe de recherche extrait plusieurs sorties générées par le modèle en fonction d'une invite donnée, puis laisse les chercheurs humains trier ces sorties, puis utilise les données triées pour former un modèle de récompense (RM). ChatGPT adopte une perte par paire pour entraîner RM.
Dans la troisième phase, l'équipe de recherche utilise l'apprentissage par renforcement pour améliorer les capacités du modèle de pré-formation, et utilise le modèle RM appris lors de la phase précédente pour mettre à jour les paramètres du modèle de pré-formation.
Nous pouvons constater que parmi les trois étapes de la formation ChatGPT, seule la troisième étape ne nécessite pas d'annotation manuelle des données, tandis que la première et la deuxième étapes nécessitent une grande quantité d'annotation manuelle. Par conséquent, bien que des modèles tels que ChatGPT fonctionnent très bien, afin d’améliorer leur capacité à suivre les instructions, le coût de la main d’œuvre est très élevé. À mesure que l’échelle du modèle s’agrandit et que la portée des capacités s’élargit de plus en plus, ce problème deviendra plus grave et finira par devenir un goulot d’étranglement entravant le développement du modèle.
Certaines recherches tentent de proposer des méthodes pour résoudre ce goulot d'étranglement. Par exemple, l'Université de Washington et d'autres institutions ont récemment publié conjointement un article "SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions". INSTRUCT est guidé par le propre processus de génération du modèle qui améliore la capacité de suivi des instructions du modèle de langage pré-entraîné.

Adresse papier : https://arxiv.org/pdf/2212.10560v1.pdf
SELF-INSTRUCT est un processus semi-automatisé qui utilise des signaux d'instruction du modèle lui-même pour pré- le train LM effectue l'ajustement des instructions. Comme le montre la figure ci-dessous, l'ensemble du processus est un algorithme d'amorçage itératif.
SELF-INSTRUCT commence avec un ensemble limité de graines et guide tout le processus de génération avec des instructions écrites à la main. Dans la première phase, le modèle est invité à saisir de nouvelles instructions de génération de tâches, une étape qui exploite le jeu d'instructions existant pour créer des instructions plus larges afin de définir la nouvelle tâche. SELF-INSTRUCT crée également des instances d'entrée et de sortie pour le jeu d'instructions nouvellement généré à utiliser pour superviser les ajustements des instructions. Enfin, SELF-INSTRUCT élimine également les instructions de mauvaise qualité et en double. L'ensemble du processus est effectué de manière itérative et le modèle final peut générer des instructions pour un grand nombre de tâches.
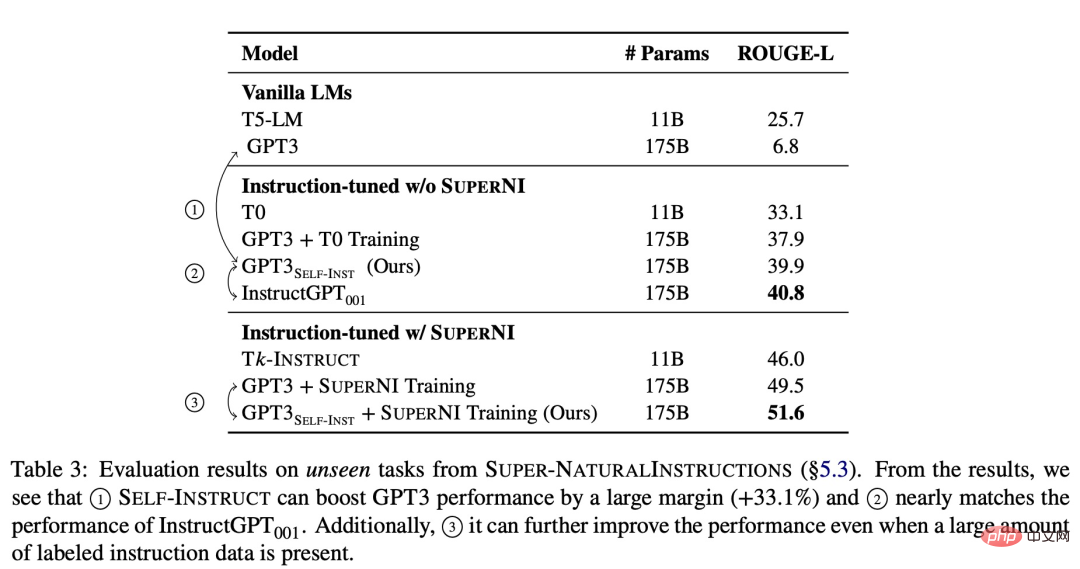
Pour vérifier l'efficacité de la nouvelle méthode, l'étude a appliqué le framework SELF-INSTRUCT sur GPT-3, qui a finalement produit environ 52 000 instructions, 82 000 entrées d'instance et sorties cibles. Nous avons observé que GPT-3 a obtenu une amélioration absolue de 33,1 % par rapport au modèle d'origine sur la nouvelle tâche dans l'ensemble de données SUPER-NATURALINSTRUCTIONS, ce qui était comparable aux performances d'InstructGPT_001 formé à l'aide de données d'utilisateurs privés et d'annotations humaines.
Pour une évaluation plus approfondie, l'étude a compilé un ensemble d'instructions écrites par des experts pour la nouvelle tâche et a démontré par une évaluation humaine que les performances de GPT-3 utilisant SELF-INSTRUCT seront nettement meilleures que celles publiques existantes. méthodes utilisant le modèle sur l’ensemble de données d’instructions et n’est qu’à 5 % derrière InstructGPT_001.
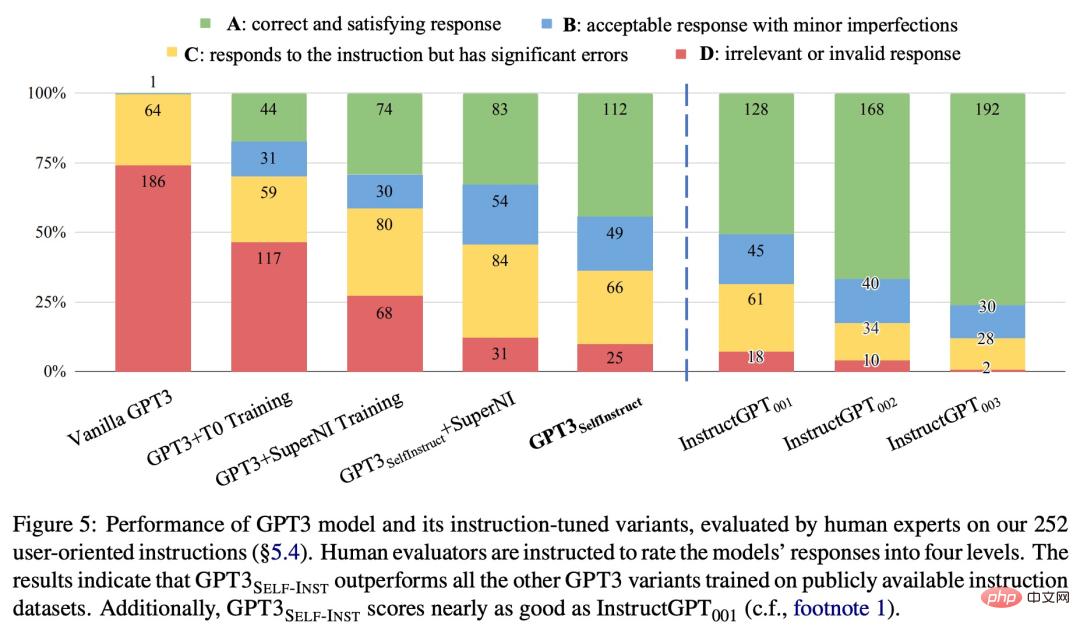
SELF-INSTRUCT fournit une méthode qui ne nécessite presque aucune annotation manuelle et permet d'aligner des modèles de langage pré-entraînés avec des instructions. Plusieurs travaux ont été tentés dans des directions similaires, et tous ont obtenu de bons résultats. On peut voir que ce type de méthode est très efficace pour résoudre le problème des coûts d'étiquetage manuel élevés pour les grands modèles de langage. Cela rendra les LLM tels que ChatGPT plus forts et ira plus loin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 La combinaison parfaite de ChatGPT et Python : créer un chatbot de service client intelligent
Oct 27, 2023 pm 06:00 PM
La combinaison parfaite de ChatGPT et Python : créer un chatbot de service client intelligent
Oct 27, 2023 pm 06:00 PM
La combinaison parfaite de ChatGPT et Python : Création d'un chatbot de service client intelligent Introduction : À l'ère de l'information d'aujourd'hui, les systèmes de service client intelligents sont devenus un outil de communication important entre les entreprises et les clients. Afin d'offrir une meilleure expérience de service client, de nombreuses entreprises ont commencé à se tourner vers les chatbots pour effectuer des tâches telles que la consultation des clients et la réponse aux questions. Dans cet article, nous présenterons comment utiliser le puissant modèle ChatGPT et le langage Python d'OpenAI pour créer un chatbot de service client intelligent afin d'améliorer
 Comment installer chatgpt sur un téléphone mobile
Mar 05, 2024 pm 02:31 PM
Comment installer chatgpt sur un téléphone mobile
Mar 05, 2024 pm 02:31 PM
Étapes d'installation : 1. Téléchargez le logiciel ChatGTP depuis le site officiel ou la boutique mobile de ChatGTP ; 2. Après l'avoir ouvert, dans l'interface des paramètres, sélectionnez la langue chinoise 3. Dans l'interface de jeu, sélectionnez le jeu homme-machine et définissez la langue. Spectre chinois ; 4. Après avoir démarré, entrez les commandes dans la fenêtre de discussion pour interagir avec le logiciel.
 Comment développer un chatbot intelligent en utilisant ChatGPT et Java
Oct 28, 2023 am 08:54 AM
Comment développer un chatbot intelligent en utilisant ChatGPT et Java
Oct 28, 2023 am 08:54 AM
Dans cet article, nous présenterons comment développer des chatbots intelligents à l'aide de ChatGPT et Java, et fournirons quelques exemples de code spécifiques. ChatGPT est la dernière version du Generative Pre-training Transformer développé par OpenAI, une technologie d'intelligence artificielle basée sur un réseau neuronal qui peut comprendre le langage naturel et générer du texte de type humain. En utilisant ChatGPT, nous pouvons facilement créer des discussions adaptatives
 Chatgpt peut-il être utilisé en Chine ?
Mar 05, 2024 pm 03:05 PM
Chatgpt peut-il être utilisé en Chine ?
Mar 05, 2024 pm 03:05 PM
chatgpt peut être utilisé en Chine, mais ne peut pas être enregistré, ni à Hong Kong et Macao. Si les utilisateurs souhaitent s'inscrire, ils peuvent utiliser un numéro de téléphone mobile étranger pour s'inscrire. Notez que lors du processus d'enregistrement, l'environnement réseau doit être basculé vers. une adresse IP étrangère.
 Comment créer un robot de service client intelligent en utilisant ChatGPT PHP
Oct 28, 2023 am 09:34 AM
Comment créer un robot de service client intelligent en utilisant ChatGPT PHP
Oct 28, 2023 am 09:34 AM
Comment utiliser ChatGPTPHP pour créer un robot de service client intelligent Introduction : Avec le développement de la technologie de l'intelligence artificielle, les robots sont de plus en plus utilisés dans le domaine du service client. L'utilisation de ChatGPTPHP pour créer un robot de service client intelligent peut aider les entreprises à fournir des services client plus efficaces et personnalisés. Cet article explique comment utiliser ChatGPTPHP pour créer un robot de service client intelligent et fournit des exemples de code spécifiques. 1. Installez ChatGPTPHP et utilisez ChatGPTPHP pour créer un robot de service client intelligent.
 Comment utiliser ChatGPT et Python pour implémenter la fonction de reconnaissance des intentions de l'utilisateur
Oct 27, 2023 am 09:04 AM
Comment utiliser ChatGPT et Python pour implémenter la fonction de reconnaissance des intentions de l'utilisateur
Oct 27, 2023 am 09:04 AM
Comment utiliser ChatGPT et Python pour implémenter la fonction de reconnaissance des intentions des utilisateurs Introduction : À l'ère numérique d'aujourd'hui, la technologie de l'intelligence artificielle est progressivement devenue un élément indispensable dans divers domaines. Parmi eux, le développement de la technologie de traitement du langage naturel (Natural Language Processing, NLP) permet aux machines de comprendre et de traiter le langage humain. ChatGPT (Chat-GeneratingPretrainedTransformer) est une sorte de
 SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
L’Open AI fait enfin son incursion dans la recherche. La société de San Francisco a récemment annoncé un nouvel outil d'IA doté de capacités de recherche. Rapporté pour la première fois par The Information en février de cette année, le nouvel outil s'appelle à juste titre SearchGPT et propose un c
