
 Périphériques technologiques
IA
Les êtres humains ne disposent pas d'un corpus de qualité suffisant pour que l'IA puisse apprendre, et ils seront épuisés en 2026. Internautes : Un projet de génération de texte humain à grande échelle a été lancé !
Périphériques technologiques
IA
Les êtres humains ne disposent pas d'un corpus de qualité suffisant pour que l'IA puisse apprendre, et ils seront épuisés en 2026. Internautes : Un projet de génération de texte humain à grande échelle a été lancé !
Les êtres humains ne disposent pas d'un corpus de qualité suffisant pour que l'IA puisse apprendre, et ils seront épuisés en 2026. Internautes : Un projet de génération de texte humain à grande échelle a été lancé !

L’appétit de l’IA est trop grand et les données sur le corps humain ne suffisent plus.
Un nouvel article de l'équipe Epoch montre que l'IA utilisera tous les corpus de haute qualité en moins de 5 ans.

Il faut savoir qu'il s'agit d'un résultat prédit prenant en compte le taux de croissance des données du langage humain, même si tous les nouveaux articles et codes écrits par les humains au cours des dernières années sont alimentés par l'IA, ce ne sera pas suffisant.
Si ce développement se poursuit, les grands modèles de langage qui s'appuient sur des données de haute qualité pour améliorer leur niveau seront bientôt confrontés à un goulot d'étranglement.
Certains internautes sont déjà incapables de rester assis :
C'est tellement ridicule. Les humains peuvent s’entraîner efficacement sans tout lire sur Internet.
Nous avons besoin de meilleurs modèles, pas de plus de données.
Certains internautes ont ridiculisé le fait qu'il vaut mieux laisser l'IA manger ce qu'elle crache :
Vous pouvez transmettre à l'IA le texte généré par l'IA elle-même sous forme de données de mauvaise qualité.

Jetons un coup d’oeil : combien de données les humains laissent-ils ?
Que diriez-vous de « l’inventaire » des données texte et image ?
L'article prédit principalement les données de texte et d'image.
Le premier concerne les données textuelles.
La qualité des données varie généralement de bonne à mauvaise. Les auteurs ont divisé les données textuelles disponibles en parties de mauvaise qualité et de haute qualité en fonction des types de données utilisés par les grands modèles existants et d'autres données.
Le corpus de haute qualité fait référence aux ensembles de données de formation utilisés par de grands modèles de langage tels que Pile, PaLM et MassiveText, notamment Wikipédia, les actualités, les codes sur GitHub, les livres publiés, etc.
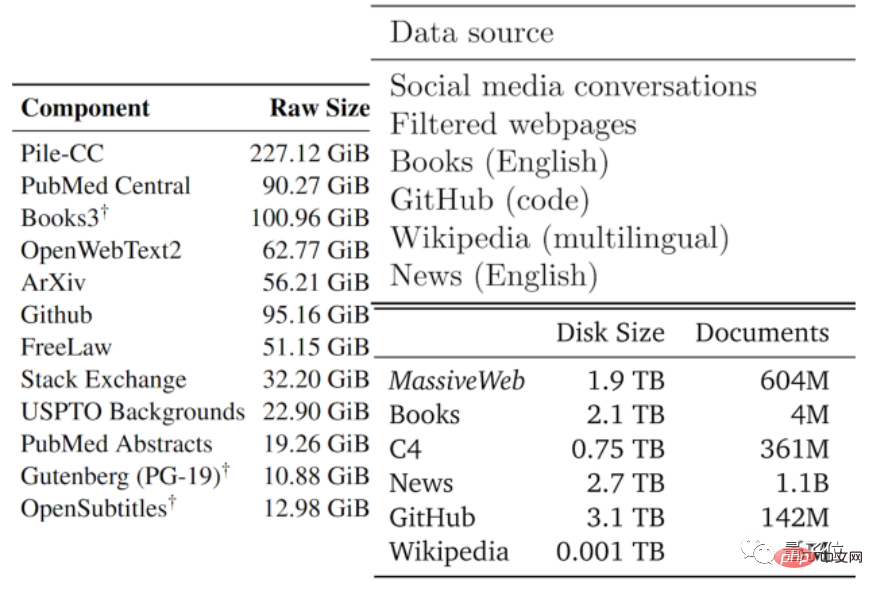
Le corpus de mauvaise qualité provient de tweets sur les réseaux sociaux tels que Reddit et de fan fiction non officielles (fanfic).
Selon les statistiques, il ne reste qu'environ 4,6 × 10 ^ 12 ~ 1,7 × 10 ^ 13 mots dans le stock de données linguistiques de haute qualité, ce qui est moins d'un ordre de grandeur plus grand que le plus grand ensemble de données textuelles actuel.
Combiné au taux de croissance, le document prédit que les données textuelles de haute qualité seront épuisées par l'IA entre 2023 et 2027, et que le nœud estimé se situe vers 2026.
Cela semble un peu rapide...
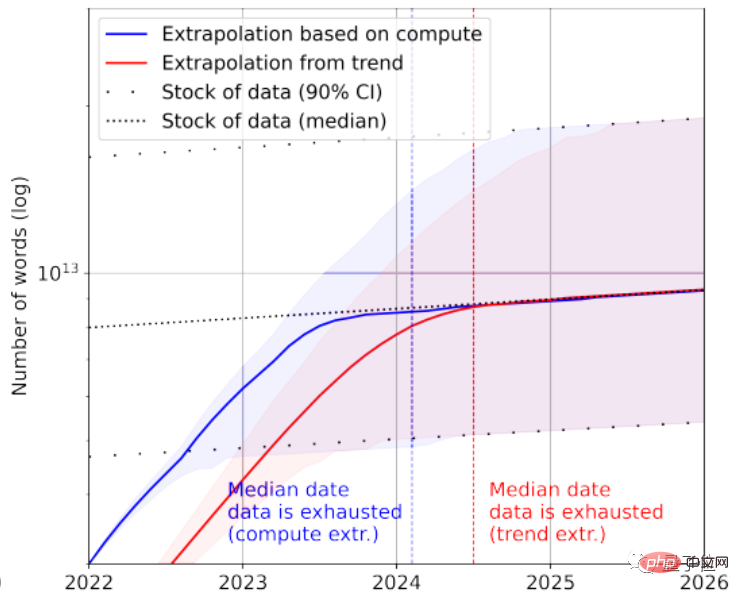
Bien sûr, des données textuelles de mauvaise qualité peuvent être ajoutées à la rescousse. Selon les statistiques, il reste actuellement 7 × 10 ^ 13 ~ 7 × 10 ^ 16 mots dans le stock global de données textuelles, soit 1,5 à 4,5 ordres de grandeur plus grands que le plus grand ensemble de données.
Si les exigences en matière de qualité des données ne sont pas élevées, alors l'IA utilisera toutes les données textuelles entre 2030 et 2050.
En regardant à nouveau les données d'image, l'article ici ne fait pas de différence entre la qualité de l'image.
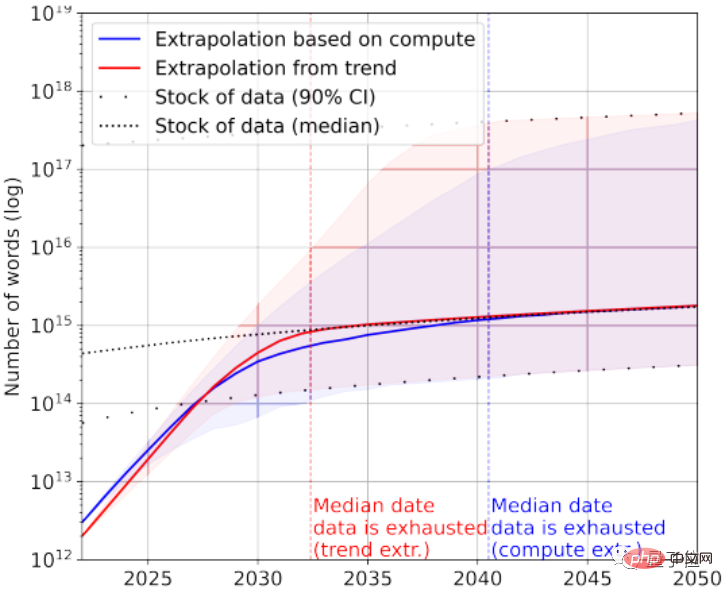
Le plus grand ensemble de données d'images contient actuellement 3 × 10 ^ 9 images.
Selon les statistiques, le nombre total actuel d'images est d'environ 8,11 × 10 ^ 12 ~ 2,3 × 10 ^ 13, soit 3 à 4 ordres de grandeur plus grand que le plus grand ensemble de données d'image.
Le journal prédit que l’IA manquera de ces images entre 2030 et 2070.
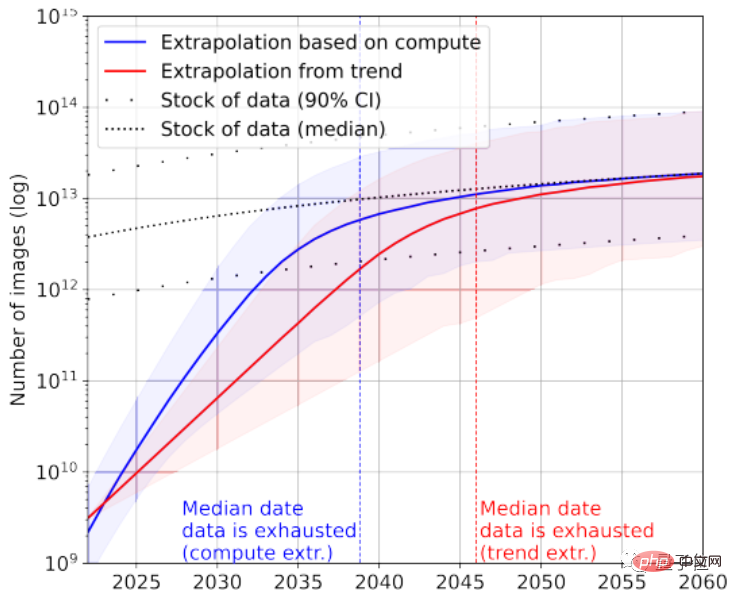
De toute évidence, les grands modèles de langage sont confrontés à une situation de « manque de données » plus grave que les modèles d'image.
Alors, comment est-on arrivé à cette conclusion ?
Calculez le nombre quotidien moyen de messages publiés par les internautes
Le document analyse l'efficacité de la génération de données d'image texte et la croissance de l'ensemble de données de formation sous deux angles.
Il convient de noter que les statistiques présentées dans l'article ne sont pas toutes des données étiquetées. Étant donné que l'apprentissage non supervisé est relativement populaire, des données non étiquetées sont également incluses.
Prenons l'exemple des données textuelles. La plupart des données seront générées à partir de plateformes sociales, de blogs et de forums.
Pour estimer la vitesse de génération de données textuelles, trois facteurs sont à prendre en compte, à savoir la population totale, le taux de pénétration d'Internet et la quantité moyenne de données générées par les internautes.
Par exemple, voici la tendance estimée de la croissance future de la population et des utilisateurs d'Internet basée sur les données historiques de la population et le nombre d'utilisateurs d'Internet :
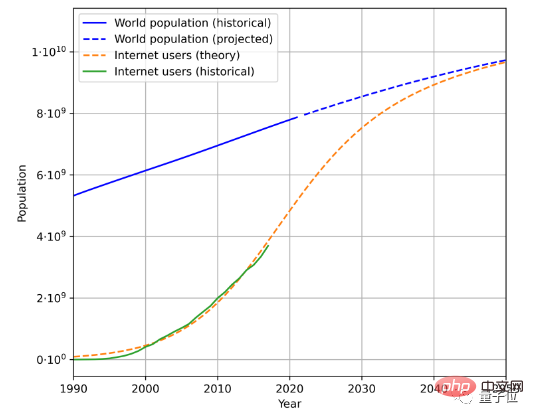
Combiné avec la quantité moyenne de données générées par les utilisateurs, le taux de génération de données peut être calculé. (En raison de changements géographiques et temporels complexes, le document simplifie la méthode de calcul de la quantité moyenne de données générées par les utilisateurs)
Selon cette méthode, on calcule que le taux de croissance des données linguistiques est d'environ 7%, mais cette croissance le taux diminuera progressivement au fil du temps.
On s'attend à ce que d'ici 2100, le taux de croissance de nos données linguistiques diminue à 1 %.
Une méthode similaire est utilisée pour analyser les données d'image. Le taux de croissance actuel est d'environ 8 %. Cependant, le taux de croissance des données d'image ralentira également jusqu'à environ 1 % d'ici 2100.
Le document estime que si le taux de croissance des données n'augmente pas de manière significative ou si de nouvelles sources de données émergent, qu'il s'agisse d'un grand modèle d'image ou de texte formé avec des données de haute qualité, cela pourrait inaugurer une période de goulot d'étranglement à un certain stade.
Certains internautes ont plaisanté à ce sujet, et quelque chose comme un scénario de science-fiction pourrait se produire dans le futur :
Afin de former l'IA, les humains ont lancé des projets de génération de texte à grande échelle, et tout le monde travaille dur pour écrire des choses pour l'IA.
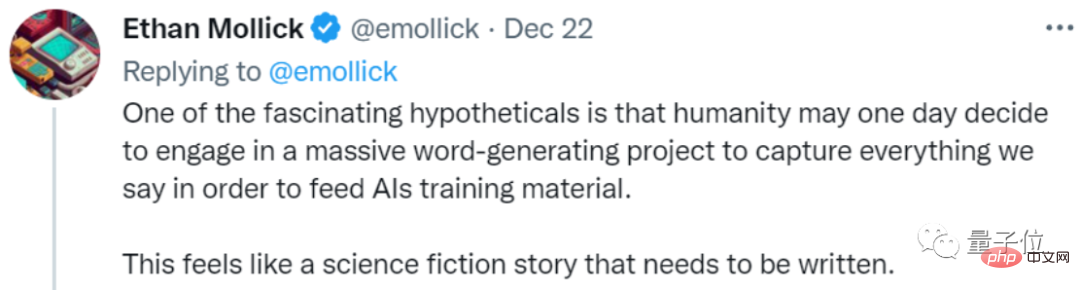
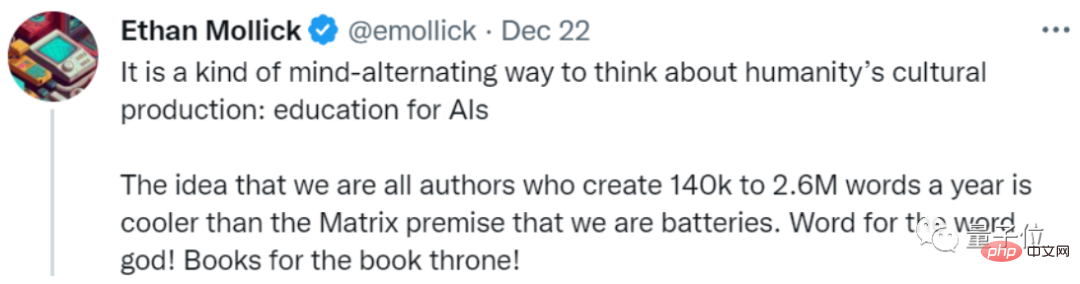
Il appelle cela une sorte d'« éducation à l'IA » :
Nous envoyons chaque année entre 140 000 et 2,6 millions de mots de données textuelles à l'IA. Cela semble-t-il plus cool que d'utiliser des humains comme batteries ?
Qu'en pensez-vous ?
Adresse papier : https://arxiv.org/abs/2211.04325
Lien de référence : https://twitter.com/emollick/status/1605756428941246466
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Partagez un moyen simple de packager des projets PyCharm
Dec 30, 2023 am 09:34 AM
Partagez un moyen simple de packager des projets PyCharm
Dec 30, 2023 am 09:34 AM
Partagez la méthode d'empaquetage de projet PyCharm simple et facile à comprendre. Avec la popularité de Python, de plus en plus de développeurs utilisent PyCharm comme outil principal pour le développement Python. PyCharm est un puissant environnement de développement intégré qui fournit de nombreuses fonctions pratiques pour nous aider à améliorer l'efficacité du développement. L’une des fonctions importantes est le packaging du projet. Cet article explique comment empaqueter des projets dans PyCharm d'une manière simple et facile à comprendre, et fournit des exemples de code spécifiques. Pourquoi packager des projets ? Développé en Python
 L'IA peut-elle vaincre le dernier théorème de Fermat ? Un mathématicien a abandonné 5 ans de sa carrière pour transformer 100 pages de preuve en code
Apr 09, 2024 pm 03:20 PM
L'IA peut-elle vaincre le dernier théorème de Fermat ? Un mathématicien a abandonné 5 ans de sa carrière pour transformer 100 pages de preuve en code
Apr 09, 2024 pm 03:20 PM
Le dernier théorème de Fermat, sur le point d'être conquis par l'IA ? Et la partie la plus significative de tout cela est que le dernier théorème de Fermat, que l’IA est sur le point de résoudre, vise précisément à prouver que l’IA est inutile. Autrefois, les mathématiques appartenaient au domaine de l’intelligence humaine pure ; aujourd’hui, ce territoire est déchiffré et piétiné par des algorithmes avancés. Image Le dernier théorème de Fermat est une énigme « notoire » qui intrigue les mathématiciens depuis des siècles. Cela a été prouvé en 1993, et les mathématiciens ont désormais un grand projet : recréer la preuve à l’aide d’ordinateurs. Ils espèrent que toute erreur logique dans cette version de la preuve pourra être vérifiée par un ordinateur. Adresse du projet : https://github.com/riccardobrasca/flt
 Régression quantile pour la prévision probabiliste de séries chronologiques
May 07, 2024 pm 05:04 PM
Régression quantile pour la prévision probabiliste de séries chronologiques
May 07, 2024 pm 05:04 PM
Ne changez pas la signification du contenu original, affinez le contenu, réécrivez le contenu et ne continuez pas. "La régression quantile répond à ce besoin, en fournissant des intervalles de prédiction avec des chances quantifiées. Il s'agit d'une technique statistique utilisée pour modéliser la relation entre une variable prédictive et une variable de réponse, en particulier lorsque la distribution conditionnelle de la variable de réponse présente un intérêt quand. Contrairement à la régression traditionnelle " Figure (A) : Régression quantile La régression quantile est une estimation. Une méthode de modélisation de la relation linéaire entre un ensemble de régresseurs X et les quantiles. des variables expliquées Y. Le modèle de régression existant est en fait une méthode pour étudier la relation entre la variable expliquée et la variable explicative. Ils se concentrent sur la relation entre variables explicatives et variables expliquées.
 Regardons de plus près PyCharm : un moyen rapide de supprimer des projets
Feb 26, 2024 pm 04:21 PM
Regardons de plus près PyCharm : un moyen rapide de supprimer des projets
Feb 26, 2024 pm 04:21 PM
Titre : En savoir plus sur PyCharm : Un moyen efficace de supprimer des projets Ces dernières années, Python, en tant que langage de programmation puissant et flexible, a été privilégié par de plus en plus de développeurs. Dans le développement de projets Python, il est crucial de choisir un environnement de développement intégré efficace. En tant qu'environnement de développement intégré puissant, PyCharm fournit aux développeurs Python de nombreuses fonctions et outils pratiques, notamment la suppression rapide et efficace des répertoires de projet. Ce qui suit se concentrera sur la façon d'utiliser la suppression dans PyCharm
 Conseils pratiques PyCharm : convertir le projet en fichier EXE exécutable
Feb 23, 2024 am 09:33 AM
Conseils pratiques PyCharm : convertir le projet en fichier EXE exécutable
Feb 23, 2024 am 09:33 AM
PyCharm est un puissant environnement de développement intégré Python qui fournit une multitude d'outils de développement et de configurations d'environnement, permettant aux développeurs d'écrire et de déboguer du code plus efficacement. Lors du processus d'utilisation de PyCharm pour le développement de projets Python, nous devons parfois regrouper le projet dans un fichier EXE exécutable pour l'exécuter sur un ordinateur sur lequel aucun environnement Python n'est installé. Cet article explique comment utiliser PyCharm pour convertir un projet en fichier EXE exécutable et donne des exemples de code spécifiques. tête
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
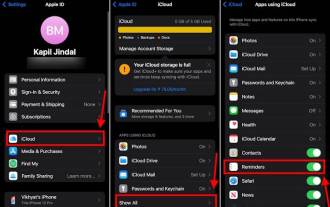 Comment créer une liste de courses dans l'application de rappels iOS 17 sur iPhone
Sep 21, 2023 pm 06:41 PM
Comment créer une liste de courses dans l'application de rappels iOS 17 sur iPhone
Sep 21, 2023 pm 06:41 PM
Comment créer une liste d'épicerie sur iPhone sous iOS17 Créer une liste d'épicerie dans l'application Rappels est très simple. Il vous suffit d'ajouter une liste et de la remplir avec vos éléments. L'application trie automatiquement vos articles en catégories et vous pouvez même travailler avec votre partenaire ou partenaire d'appartement pour dresser une liste de ce que vous devez acheter dans le magasin. Voici les étapes complètes pour ce faire : Étape 1 : activer les rappels iCloud Aussi étrange que cela puisse paraître, Apple dit que vous devez activer les rappels d'iCloud pour créer une liste d'épicerie sur iOS17. Voici les étapes à suivre : Accédez à l'application Paramètres sur votre iPhone et appuyez sur [votre nom]. Ensuite, sélectionnez je
 Comment utiliser la base de données MySQL pour les prévisions et l'analyse prédictive ?
Jul 12, 2023 pm 08:43 PM
Comment utiliser la base de données MySQL pour les prévisions et l'analyse prédictive ?
Jul 12, 2023 pm 08:43 PM
Comment utiliser la base de données MySQL pour les prévisions et l'analyse prédictive ? Présentation : les prévisions et l'analyse prédictive jouent un rôle important dans l'analyse des données. MySQL, un système de gestion de bases de données relationnelles largement utilisé, peut également être utilisé pour des tâches de prédiction et d'analyse prédictive. Cet article explique comment utiliser MySQL pour la prédiction et l'analyse prédictive, et fournit des exemples de code pertinents. Préparation des données : Tout d’abord, nous devons préparer les données pertinentes. Supposons que nous souhaitions faire des prévisions de ventes, nous avons besoin d'un tableau contenant des données de ventes. Dans MySQL, nous pouvons utiliser
