
 Périphériques technologiques
IA
Le convertisseur TabTransformer améliore les performances du perceptron multicouche, analyse approfondie
Périphériques technologiques
IA
Le convertisseur TabTransformer améliore les performances du perceptron multicouche, analyse approfondie
Le convertisseur TabTransformer améliore les performances du perceptron multicouche, analyse approfondie

Aujourd'hui, les Transformers sont des modules clés dans les architectures de traitement du langage naturel (NLP) et de vision par ordinateur (CV) les plus avancées. Cependant, le domaine des données tabulaires est toujours dominé par les algorithmes d’arbre de décision à gradient boosté (GBDT). Il y a donc eu des tentatives pour combler cet écart. Parmi eux, le premier article de modélisation de données tabulaires basé sur un convertisseur est l'article « TabTransformer : Tabular Data Modeling Using Context Embedding » publié par Huang et al.
Cet article vise à fournir un affichage de base du contenu de l'article, tout en approfondissant également les détails de mise en œuvre du modèle TabTransformer et en vous montrant comment utiliser TabTransformer spécifiquement pour nos propres données.
1. Présentation de l'article
L'idée principale de l'article ci-dessus est que si un convertisseur est utilisé pour convertir des intégrations catégorielles régulières en intégrations contextuelles, alors les performances des perceptrons multicouches (MLP) réguliers seront considérablement amélioré. Ensuite, comprenons cette description plus en profondeur.
1. Embeddings catégoriels
Dans les modèles d'apprentissage profond, la manière classique d'utiliser les fonctionnalités catégorielles est de former leurs intégrations. Cela signifie que chaque valeur de catégorie a une représentation vectorielle dense unique et peut être transmise à la couche suivante. Par exemple, vous pouvez voir sur l'image ci-dessous que chaque caractéristique catégorielle est représentée par un tableau à quatre dimensions. Ces intégrations sont ensuite concaténées avec des caractéristiques numériques et utilisées comme entrée dans le MLP.
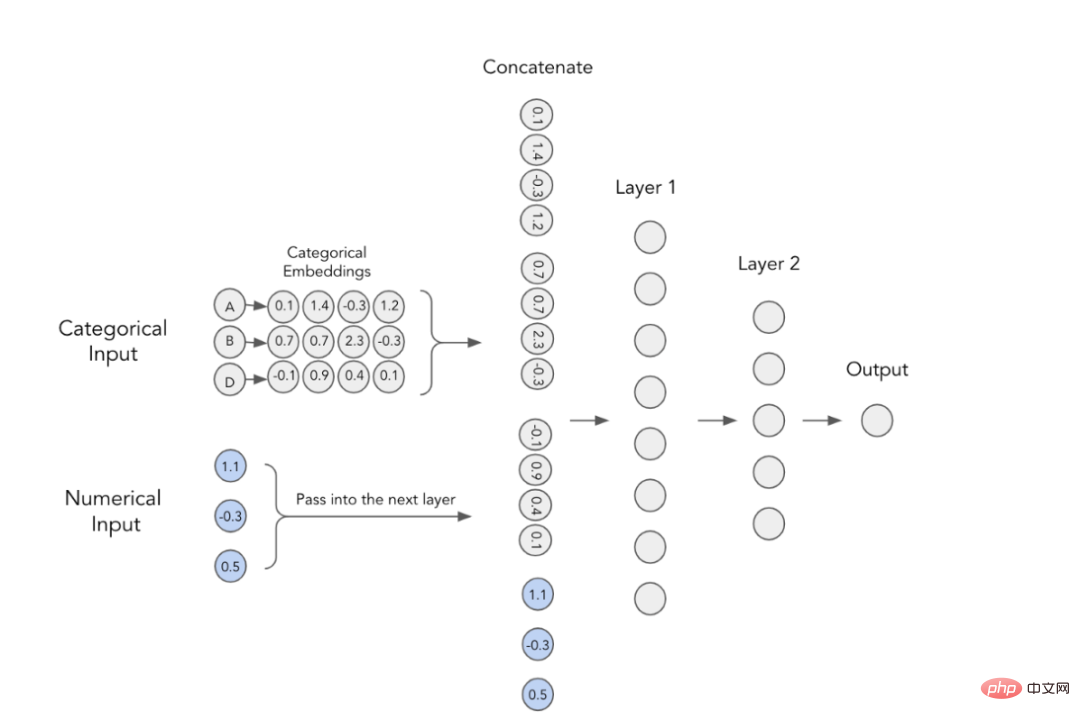
MLP avec intégrations catégorielles
2. Embeddings contextuels
L'auteur de l'article estime que les intégrations catégorielles manquent de signification contextuelle, c'est-à-dire qu'elles n'ont aucune relation entre les variables catégorielles interactives et les informations relationnelles sont codées. Afin de rendre plus concret le contenu embarqué, il a été suggéré d'utiliser à cet effet les transformateurs actuellement utilisés dans le domaine du NLP.
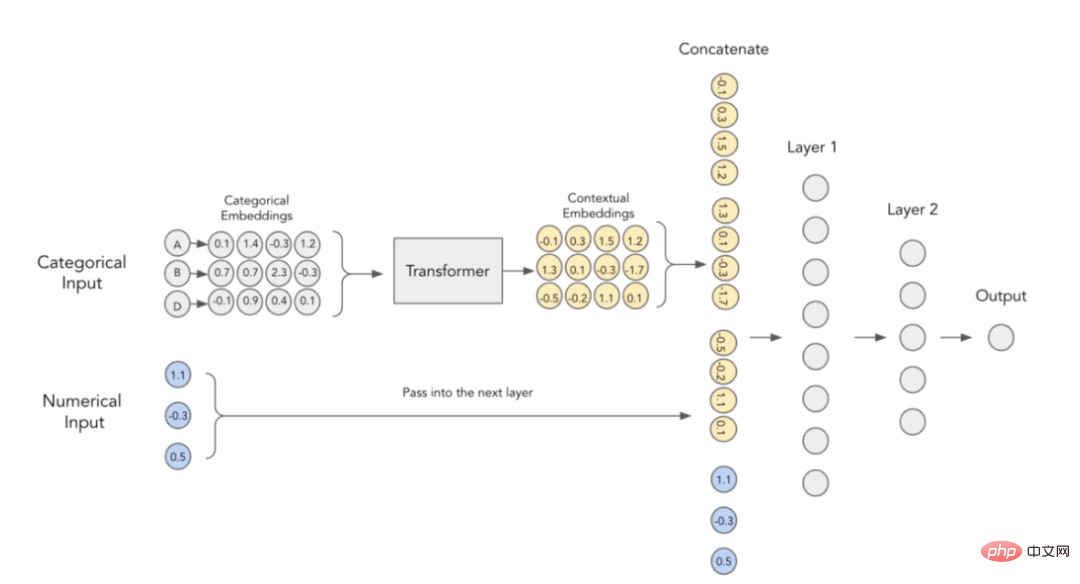
Incorporation de contexte dans TabTransformer
Pour illustrer visuellement l'idée ci-dessus, autant considérer l'image suivante d'intégration de contexte obtenue après la formation. Parmi eux, deux éléments de classification sont mis en évidence : le lien de parenté (noir) et l'état civil (bleu). Ces caractéristiques sont corrélées ; de sorte que les valeurs de « Marié », « Mari » et « Femme » doivent être proches les unes des autres dans l'espace vectoriel, même si elles proviennent de variables différentes.
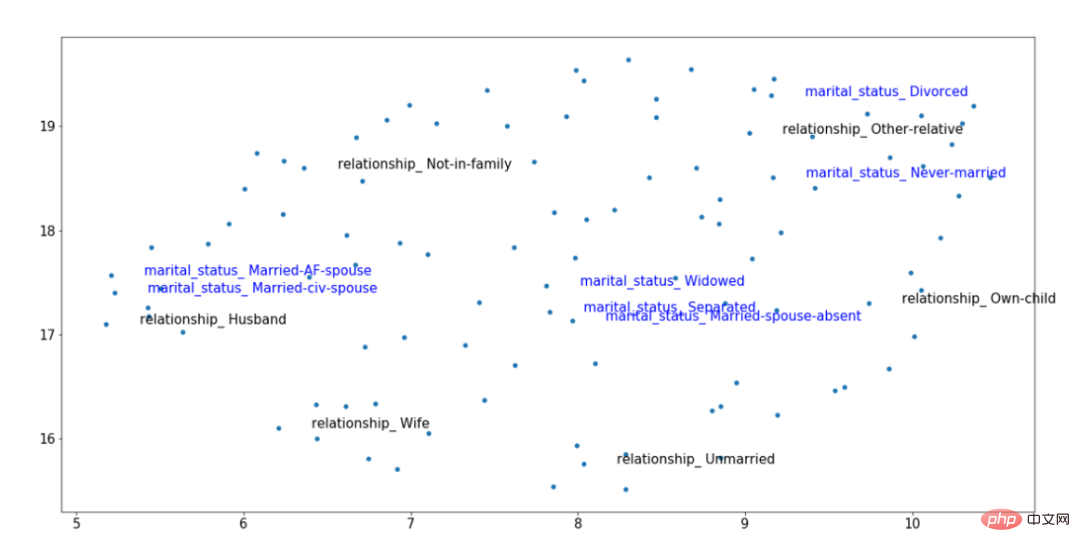
Exemple de résultats d'intégration de TabTransformer entraînés
Grâce au contexte entraîné intégrant les résultats dans la figure ci-dessus, nous pouvons voir que l'état matrimonial de "Marié" est plus proche des "niveaux de relation pour "Mari". et « Femme » proviennent d’un cluster de données distinct sur la droite. Ce type de contexte rend ces intégrations plus utiles, un effet qui n'est pas possible en utilisant des formes simples de techniques d'intégration de catégories.
3. Architecture TabTransformer
Afin d'atteindre l'objectif ci-dessus, l'auteur de l'article a proposé l'architecture suivante :
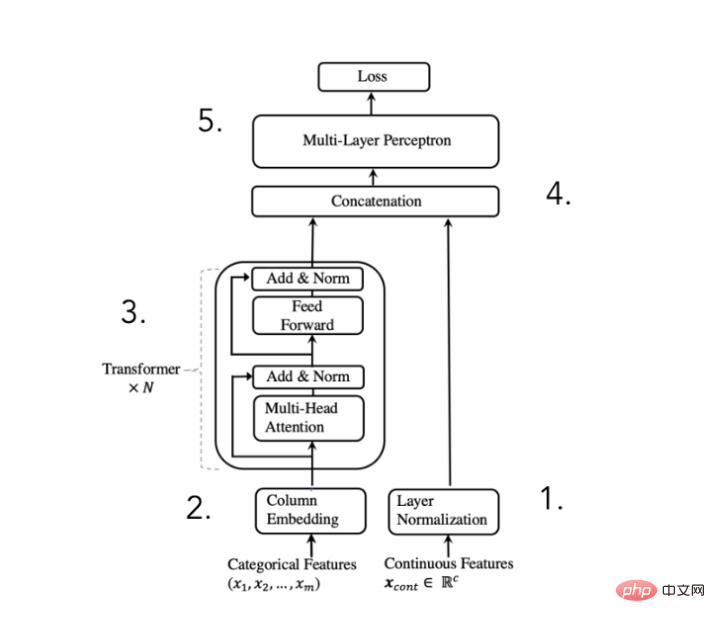
Schéma de l'architecture du convertisseur TabTransformer
(extrait de l'article publié par Huang et al. en 2020)
Nous pouvons décomposer cette architecture en 5 étapes :
- Normaliser les caractéristiques numériques et les transmettre
- Intégrer les caractéristiques catégorielles
- L'intégration est traitée par N fois de blocs de conversion. afin d'obtenir l'intégration contextuelle
- Concaténer les intégrations de classification contextuelle avec des caractéristiques numériques
- Concaténer via MLP pour obtenir les prédictions souhaitées
Bien que l'architecture du modèle soit très simple, les auteurs de l'article ont déclaré que l'ajout d'une couche de convertisseur peut améliorer considérablement les performances de calcul. Bien sûr, toute la « magie » se produit à l’intérieur de ces blocs de conversion ; examinons donc l’implémentation plus en détail.
4. Convertisseur
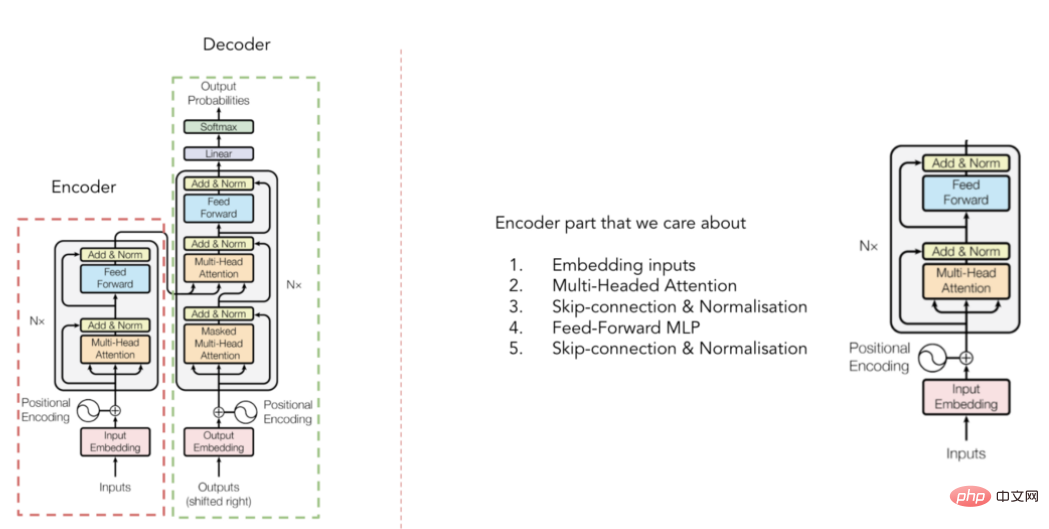
Illustration de l'architecture du transformateur
(sélectionné dans l'article publié par Vaswani et al. en 2017)
Vous avez peut-être déjà vu l'architecture du transformateur, mais pour le Pour une introduction rapide, rappelez-vous que le convertisseur est composé de deux parties : un encodeur et un décodeur (voir photo ci-dessus). Pour TabTransformer, nous nous soucions uniquement de la partie encodeur qui contextualise les intégrations d'entrée (la partie décodeur convertit ces intégrations dans le résultat de sortie final). Mais comment ça se passe exactement ? La réponse est : un mécanisme d’attention multi-têtes.
5. Mécanisme d'attention multi-têtes
Pour citer une description de mon article préféré sur les mécanismes d'attention, cela ressemble à ceci :
« Le concept clé derrière l'auto-attention est que ce mécanisme permet à un réseau neuronal d'apprendre comment agir sur des éléments individuels d'une séquence d'entrée. Planification des informations avec le meilleur schéma de routage entre elles. »
En d'autres termes, l'auto-attention aide le modèle à déterminer quelles parties de l'entrée sont les plus importantes lorsqu'il représente un certain mot/catégorie. À cette fin, je vous recommande fortement de lire l’article référencé ci-dessus pour comprendre plus intuitivement pourquoi la concentration sur soi est si efficace.
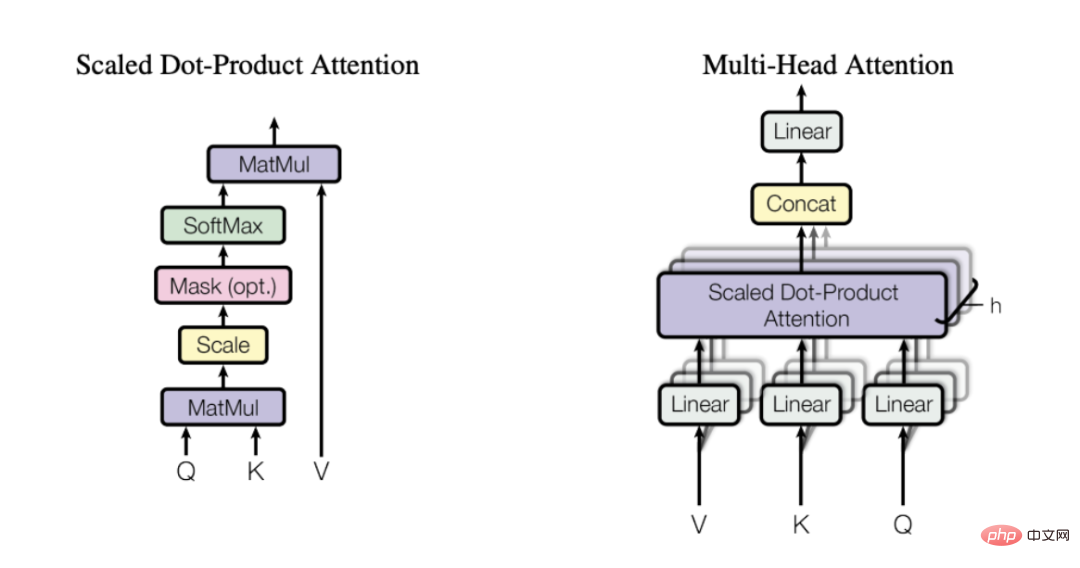
Mécanisme d'attention multi-têtes
(Sélectionné dans l'article publié par Vaswani et al. en 2017)
L'attention est calculée par 3 matrices apprises - Q, K et V, elles représentent la requête ( Requête), clé (Clé) et valeur (Valeur). Tout d’abord, nous multiplions les matrices Q et K pour obtenir la matrice d’attention. Cette matrice est mise à l'échelle et passe à travers la couche softmax. Nous multiplions ensuite cela par la matrice V pour obtenir la valeur finale. Pour une compréhension plus intuitive, considérez le schéma ci-dessous, qui montre comment nous implémentons la transformation de l'intégration d'entrée en intégration de contexte à l'aide des matrices Q, K et V.
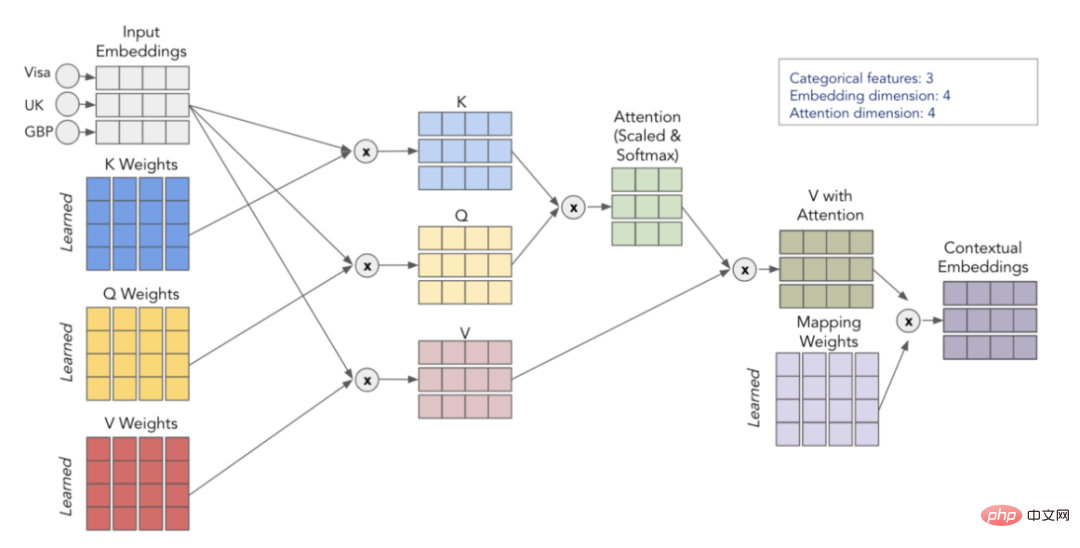
Visualisation du processus d'auto-attention
En répétant ce processus h fois (en utilisant différentes matrices Q, K, V), nous sommes en mesure d'obtenir plusieurs intégrations de contexte, qui forment notre multi-tête final attention .
6. Bref aperçu
Résumons ce que nous avons introduit ci-dessus :
- Les intégrations catégorielles simples ne contiennent aucune information contextuelle
- En passant les intégrations catégorielles via l'encodeur du transformateur, nous sommes en mesure d'intégrer la contextualisation
- La partie transformateur est capable de contextualiser les intégrations car elle utilise un mécanisme d'attention multi-têtes
- Le mécanisme d'attention multi-têtes utilise les matrices Q, K et V pour trouver des informations d'interaction et de corrélation utiles lors de l'encodage des variables
- Dans TabTransformer, contextualisé les intégrations sont concaténées avec des entrées numériques et prédites par une simple sortie MLP
Bien que l'idée derrière TabTransformer soit simple, cela peut vous prendre un certain temps pour maîtriser le mécanisme d'attention. Par conséquent, je vous recommande fortement de relire l’explication ci-dessus. Si vous vous sentez un peu perdu, lisez tous les liens suggérés dans cet article. Je vous garantis qu'une fois que vous aurez fait cela, il ne vous sera pas difficile de comprendre comment fonctionne le mécanisme d'attention.
7. Affichage des résultats expérimentaux
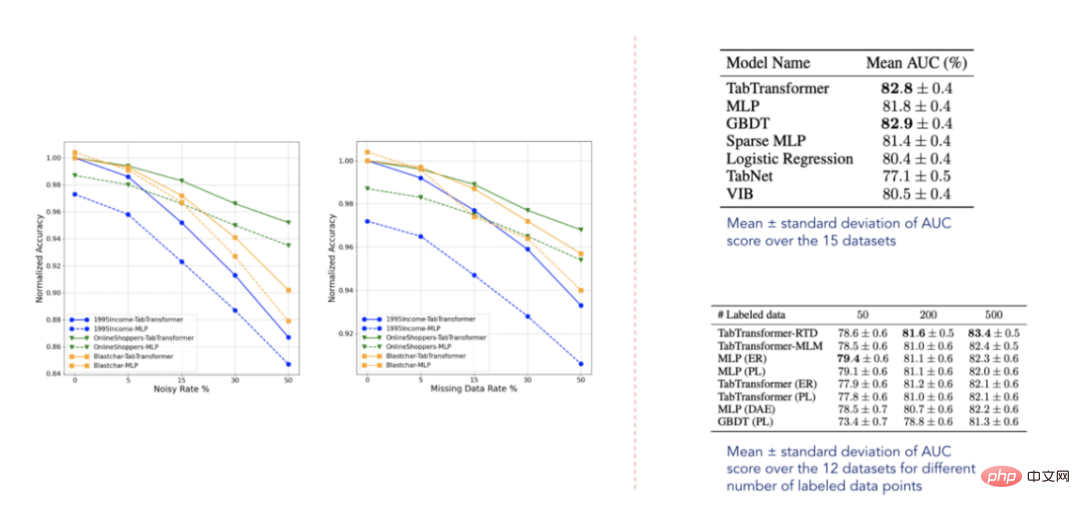
Données de résultat (sélectionnées dans l'article publié par Huang et al. en 2020)
Selon les résultats rapportés, le transformateur TabTransformer surpasse tous les autres apprentissages profonds. modèles tabulaires ,De plus, il est proche du niveau de performance du GBDT, ce qui est très encourageant. Le modèle est également relativement robuste aux données manquantes et bruitées, et surpasse les autres modèles dans des environnements semi-supervisés. Cependant, ces ensembles de données ne sont clairement pas exhaustifs et il reste encore beaucoup à faire, comme le confirment certains articles connexes publiés à l'avenir.
2. Construire notre propre exemple de programme
Maintenant, déterminons enfin comment appliquer le modèle à nos propres données. Les exemples de données suivants sont tirés du célèbre concours Tabular Playground Kaggle. Pour faciliter l'utilisation du convertisseur TabTransformer, j'ai créé un package tabtransformertf. Il peut être installé à l'aide de la commande pip comme ceci :
pip install tabtransformertf
et nous permet d'utiliser le modèle sans prétraitement approfondi.
1. Prétraitement des données
La première étape consiste à définir le type de données approprié et à convertir nos données de formation et de validation en ensembles de données TF. Parmi eux, le package installé précédemment fournit un bon utilitaire capable de faire cela.
from tabtransformertf.utils.preprocessing import df_to_dataset, build_categorical_prep # 设置数据类型 train_data[CATEGORICAL_FEATURES] = train_data[CATEGORICAL_FEATURES].astype(str) val_data[CATEGORICAL_FEATURES] = val_data[CATEGORICAL_FEATURES].astype(str) train_data[NUMERIC_FEATURES] = train_data[NUMERIC_FEATURES].astype(float) val_data[NUMERIC_FEATURES] = val_data[NUMERIC_FEATURES].astype(float) # 转换成TF数据集 train_dataset = df_to_dataset(train_data[FEATURES + [LABEL]], LABEL, batch_size=1024) val_dataset = df_to_dataset(val_data[FEATURES + [LABEL]], LABEL, shuffle=False, batch_size=1024)
L'étape suivante consiste à préparer la couche de prétraitement pour les données catégorielles. Ces données catégorielles seront ensuite transmises à notre modèle principal.
from tabtransformertf.utils.preprocessing import build_categorical_prep
category_prep_layers = build_categorical_prep(train_data, CATEGORICAL_FEATURES)
# 输出结果是一个字典结构,其中键部分是特征名称,值部分是StringLookup层
# category_prep_layers ->
# {'product_code': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05d28ee4e0>,
#'attribute_0': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4fb908>,
#'attribute_1': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4da5f8>}C'est un prétraitement ! Maintenant, nous pouvons commencer à construire le modèle.
2. Construisez le modèle TabTransformer
L'initialisation du modèle est facile. Parmi eux, plusieurs paramètres doivent être spécifiés, mais les paramètres les plus importants sont : embedding_dim, profondeur et têtes. Tous les paramètres sont sélectionnés après le réglage des hyperparamètres.
from tabtransformertf.models.tabtransformer import TabTransformer tabtransformer = TabTransformer( numerical_features = NUMERIC_FEATURES,# 带有数字特征名称的列表 categorical_features = CATEGORICAL_FEATURES, # 带有分类特征名称的列表 categorical_lookup=category_prep_layers, # 带StringLookup层的Dict numerical_discretisers=None,# None代表我们只是简单地传递数字特征 embedding_dim=32,# 嵌入维数 out_dim=1,# Dimensionality of output (binary task) out_activatinotallow='sigmoid',# 输出层激活 depth=4,# 转换器块层的个数 heads=8,# 转换器块中注意力头的个数 attn_dropout=0.1,# 在转换器块中的丢弃率 ff_dropout=0.1,# 在最后MLP中的丢弃率 mlp_hidden_factors=[2, 4],# 我们为每一层划分最终嵌入的因子 use_column_embedding=True,#如果我们想使用列嵌入,设置此项为真 ) # 模型运行中摘要输出: # 总参数个数: 1,778,884 # 可训练的参数个数: 1,774,064 # 不可训练的参数个数: 4,820
Une fois le modèle initialisé, nous pouvons l'installer comme n'importe quel autre modèle Keras. Les paramètres d'entraînement sont également réglables, de sorte que la vitesse d'apprentissage et l'arrêt précoce peuvent être ajustés à volonté.
LEARNING_RATE = 0.0001 WEIGHT_DECAY = 0.0001 NUM_EPOCHS = 1000 optimizer = tfa.optimizers.AdamW( learning_rate=LEARNING_RATE, weight_decay=WEIGHT_DECAY ) tabtransformer.compile( optimizer = optimizer, loss = tf.keras.losses.BinaryCrossentropy(), metrics= [tf.keras.metrics.AUC(name="PR AUC", curve='PR')], ) out_file = './tabTransformerBasic' checkpoint = ModelCheckpoint( out_file, mnotallow="val_loss", verbose=1, save_best_notallow=True, mode="min" ) early = EarlyStopping(mnotallow="val_loss", mode="min", patience=10, restore_best_weights=True) callback_list = [checkpoint, early] history = tabtransformer.fit( train_dataset, epochs=NUM_EPOCHS, validation_data=val_dataset, callbacks=callback_list )
3. Évaluation
L'indicateur le plus critique de la compétition est le ROC AUC. Alors, affichons-le avec la métrique PR AUC pour évaluer les performances du modèle.
val_preds = tabtransformer.predict(val_dataset)
print(f"PR AUC: {average_precision_score(val_data['isFraud'], val_preds.ravel())}")
print(f"ROC AUC: {roc_auc_score(val_data['isFraud'], val_preds.ravel())}")
# PR AUC: 0.26
# ROC AUC: 0.58您也可以自己给测试集评分,然后将结果值提交给Kaggle官方。我现在选择的这个解决方案使我跻身前35%,这并不坏,但也不太好。那么,为什么TabTransfromer在上述方案中表现不佳呢?可能有以下几个原因:
- 数据集太小,而深度学习模型以需要大量数据著称
- TabTransformer很容易在表格式数据示例领域出现过拟合
- 没有足够的分类特征使模型有用
三、结论
本文探讨了TabTransformer背后的主要思想,并展示了如何使用Tabtransformertf包来具体应用此转换器。
归纳起来看,TabTransformer的确是一种有趣的体系结构,它在当时的表现明显优于大多数深度表格模型。它的主要优点是将分类嵌入语境化,从而增强其表达能力。它使用在分类特征上的多头注意力机制来实现这一点,而这是在表格数据领域使用转换器的第一个应用实例。
TabTransformer体系结构的一个明显缺点是,数字特征被简单地传递到最终的MLP层。因此,它们没有语境化,它们的价值也没有在分类嵌入中得到解释。在下一篇文章中,我将探讨如何修复此缺陷并进一步提高性能。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文链接:https://towardsdatascience.com/transformers-for-tabular-data-tabtransformer-deep-dive-5fb2438da820?source=collection_home---------4----------------------------
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
