

analyse d'instance Web Java

Texte
Dans les projets de travail réels, le cache est devenu un élément clé de l'architecture à haute concurrence et hautes performances. Alors pourquoi Redis peut-il être utilisé comme cache ? Tout d'abord, il peut être utilisé comme deux caractéristiques principales du cache :
Dans le système hiérarchique, la mémoire/CPU a de bonnes performances d'accès,
Les données du cache sont saturées et il y a une bonne quantité de données. mécanisme d'élimination
Puisque Redis possède naturellement ces deux caractéristiques, Redis est basé sur des opérations de mémoire et dispose d'un mécanisme complet d'élimination des données, ce qui le rend très approprié comme composant de cache.
Parmi eux, en fonction du fonctionnement de la mémoire, la capacité peut être de 32 à 96 Go, la durée de fonctionnement est de 100 ns en moyenne et l'efficacité de fonctionnement est élevée. De plus, il existe de nombreux mécanismes d'élimination des données, et il y en a 8 après Redis 4.0, ce qui rend Redis applicable à de nombreux scénarios en tant que cache.
Alors pourquoi le cache Redis a-t-il besoin d'un mécanisme d'élimination des données ? Quels sont les 8 mécanismes d’élimination des données ?
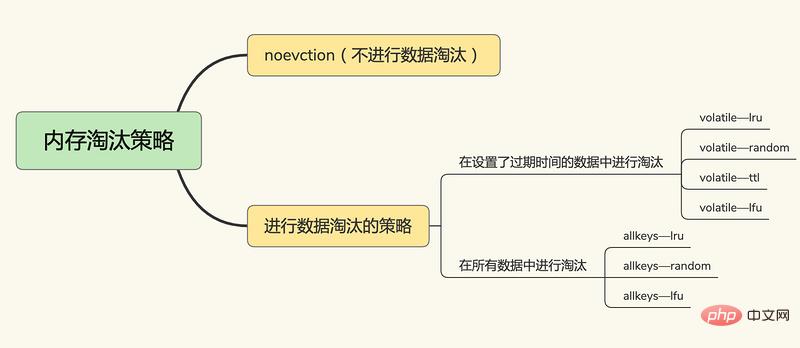
Mécanisme d'élimination des données
Le cache Redis est implémenté en fonction de la mémoire, sa capacité de cache est donc limitée Lorsque le cache est plein, comment Redis doit-il le gérer ?
Redis Lorsque le cache est plein, Redis a besoin d'un mécanisme d'élimination des données du cache pour sélectionner et supprimer certaines données via certaines règles d'élimination afin que le service de cache puisse être à nouveau utilisé. Alors, quelles stratégies d’élimination Redis utilise-t-il pour supprimer des données ?
Après Redis 4.0, il existe 6+2 stratégies d'élimination du cache Redis, dont trois grandes catégories :
Aucune élimination de données
noeviction, aucune élimination de données, lorsque le cache est plein, Redis ne fournira pas de services renvoie directement une erreur.
Dans la paire clé-valeur qui définit l'heure d'expiration,
volatile-random, dans la paire clé-valeur qui définit l'heure d'expiration, supprimez aléatoirement
volatile-ttl, dans le paire clé-valeur qui définit l'heure d'expiration Oui, la suppression sera effectuée en fonction de l'heure d'expiration. Plus la date d'expiration est antérieure, plus elle sera supprimée tôt.
volatile-lru, basé sur l'algorithme LRU (Least Récemment Utilisé) pour filtrer les paires clé-valeur avec un délai d'expiration, filtrer les données selon le principe le moins récemment utilisé
volatile-lfu, en utilisant le LFU ( Algorithme les moins fréquemment utilisés) Sélectionnez les paires clé-valeur avec un délai d'expiration défini et les paires clé-valeur les moins fréquemment utilisées pour filtrer les données.
Dans toutes les paires clé-valeur,
allkeys-random, sélectionnez et supprimez au hasard les données de toutes les paires clé-valeur
allkeys-lru, utilisez l'algorithme LRU pour filtrer parmi toutes les données
allkeys-lfu, utilise l'algorithme LFU pour filtrer toutes les données
Remarque : algorithme LRU (Least Récemment Utilisé), LRU maintient une liste chaînée bidirectionnelle, la liste chaînée La tête et tail représente respectivement l’extrémité MRU et l’extrémité LRU, représentant respectivement les données les plus récemment utilisées et les données récemment les moins couramment utilisées.
Dans la mise en œuvre réelle, l'algorithme LRU doit utiliser des listes chaînées pour gérer toutes les données mises en cache, ce qui entraînera une surcharge d'espace supplémentaire. De plus, lors de l'accès aux données, les données doivent être déplacées vers le MRU sur la liste chaînée. Si une grande quantité de données est accédée, de nombreuses opérations de déplacement de liste chaînée se produiront, ce qui prendra beaucoup de temps et réduira les performances du cache Redis. .
Parmi eux, LRU et LFU sont implémentés sur la base des attributs lru et refcount de redisObject, la structure d'objet de Redis :
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
// 引用计数 * and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;LRU de Redis utilisera le lru de redisObject pour enregistrer l'heure du dernier accès et sélectionnera aléatoirement le nombre configuré de paramètres maxmemory-samples En tant qu'ensemble candidat, les données avec la plus petite valeur d'attribut lru sont sélectionnées et éliminées.
Dans les projets réels, comment choisir le mécanisme d'élimination des données ?
Préférez l'algorithme allkeys-lru pour conserver les données les plus récemment consultées dans le cache afin d'améliorer les performances d'accès aux applications.
Les données principales utilisent l'algorithme volatile-lru. Les données principales ne définissent pas de délai d'expiration du cache. Les autres données définissent un délai d'expiration et sont filtrées en fonction des règles LRU.
Après avoir compris le mécanisme d'élimination du cache Redis, voyons combien de modes Redis dispose en tant que cache ?
Mode cache Redis
Le mode cache Redis peut être divisé en cache en lecture seule et cache en lecture-écriture selon qu'il faut recevoir ou non des demandes d'écriture :
Cache en lecture seule : gère uniquement les opérations de lecture, toutes les opérations de mise à jour sont dans la base de données , donc les données ne seront pas transmises. Il y a un risque de perte.
Mode Cache Aside
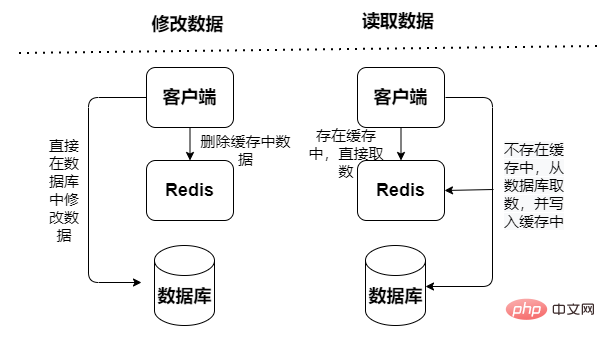
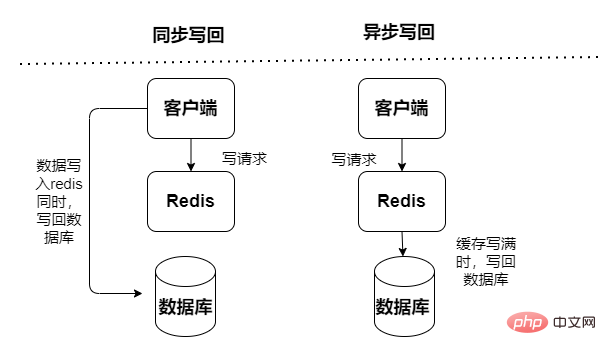
Cache de lecture et d'écriture, les opérations de lecture et d'écriture sont effectuées dans le cache, et une panne de temps d'arrêt entraînera une perte de données. Les données de réécriture du cache dans la base de données sont divisées en deux types : synchrone et asynchrone :
Synchrone : les performances d'accès sont faibles, ce qui se concentre davantage sur la fiabilité des données
Mode lecture directe
Écriture -Mode Through
Asynchrone : risque de perte de données, il se concentre sur la fourniture d'un accès à faible latence
Mode Write-Behind
Mode Cache Aside
La requête de données lit d'abord les données du cache, si elles n'existent pas dans le cache, puis lit les données de la base de données et met à jour après avoir obtenu les données dans le cache, mais lors de la mise à jour des données, les données de la base de données seront d'abord mises à jour, puis les données dans le cache seront invalidées.
Et le mode Cache Aside comportera des risques de concurrence : l'opération de lecture manque le cache, puis interroge la base de données pour récupérer les données. Les données ont été interrogées mais n'ont pas été mises dans le cache. L'opération d'écriture de mise à jour invalide le cache, puis l'opération de lecture échoue à nouveau. La requête charge les données dans le cache, ce qui entraîne des données sales mises en cache.
Mode lecture/écriture
Les données de requête et les données de mise à jour accèdent directement au service de cache, Le service de cache met à jour les données dans la base de données de manière synchrone. La probabilité de données sales est faible, mais elle dépend fortement du cache et nécessite de plus grandes exigences en matière de stabilité du service de cache. Cependant, les mises à jour synchrones entraîneront de mauvaises performances.
Mode Write Behind
L'interrogation des données et la mise à jour des données accèdent directement au service de cache, mais le service de cache utilise une manière asynchrone pour mettre à jour les données dans la base de données (via des tâches asynchrones) C'est rapide et efficace, mais les données est cohérent. Il est relativement médiocre, il peut y avoir une perte de données et la logique de mise en œuvre est également relativement complexe.
Choisissez le mode cache en fonction des exigences réelles du scénario commercial lors du développement réel du projet. Après avoir compris ce qui précède, pourquoi devons-nous utiliser le cache Redis dans notre application ?
L'utilisation du cache Redis dans les applications peut améliorer les performances du système et la concurrence, ce qui se reflète principalement dans
Hautes performances : basées sur les requêtes de mémoire, la structure KV, les opérations logiques simples
Concurrence élevée : MySQL ne peut prendre en charge qu'environ 2 000 par seconde Requêtes, Redis dépasse facilement 1W par seconde. Permettre à plus de 80 % des requêtes de passer par le cache et à moins de 20 % des requêtes de passer par la base de données peut grandement améliorer le débit du système
Bien que l'utilisation du cache Redis puisse grandement améliorer les performances du système, il y aura Il peut y avoir des problèmes lors de l'utilisation du cache. Par exemple, incohérence bidirectionnelle entre le cache et la base de données, avalanche de cache, etc. Comment résoudre ces problèmes ?
Problèmes courants lors de l'utilisation du cache
Lors de l'utilisation du cache, il y aura quelques problèmes, principalement reflétés dans :
Incohérence entre le cache et la double écriture de la base de données
Avalanche de cache : le cache Redis ne peut pas gérer un grand nombre d'applications requêtes, transfert vers La couche base de données provoque une augmentation de la pression sur la couche base de données ;
Pénétration du cache : Les données d'accès n'existent pas dans le cache Redis et la base de données, ce qui entraîne le transfert direct d'un grand nombre de caches de pénétration d'accès ; à la base de données, provoquant une augmentation de la pression sur la couche de base de données ;
Panne du cache : le cache ne peut pas gérer les données chaudes à haute fréquence, ce qui entraîne un accès direct à haute fréquence à la base de données, entraînant une augmentation de la pression sur la base de données. couche de base de données ;
Le cache est incohérent avec les données de la base de données
Cache en lecture seule (mode Cache Aside)
Pour Cache en lecture seule (mode Cache Aside) , toutes les opérations de lecture se produisent dans le cache , l'incohérence des données ne se produira que dans les opérations de suppression (les nouvelles opérations ne le seront pas, car les nouveaux ajouts ne seront traités que dans la base de données), lorsqu'une opération de suppression se produit, le cache marque les données comme invalides et met à jour la base de données. Par conséquent, lors du processus de mise à jour de la base de données et de suppression des valeurs mises en cache, quel que soit l'ordre d'exécution des deux opérations, tant qu'une opération échoue, une incohérence des données se produira.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Racine carrée en Java
Aug 30, 2024 pm 04:26 PM
Racine carrée en Java
Aug 30, 2024 pm 04:26 PM
Guide de la racine carrée en Java. Nous discutons ici du fonctionnement de Square Root en Java avec un exemple et son implémentation de code respectivement.
 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Guide du générateur de nombres aléatoires en Java. Nous discutons ici des fonctions en Java avec des exemples et de deux générateurs différents avec d'autres exemples.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro Armstrong en Java
Aug 30, 2024 pm 04:26 PM
Numéro Armstrong en Java
Aug 30, 2024 pm 04:26 PM
Guide du numéro Armstrong en Java. Nous discutons ici d'une introduction au numéro d'Armstrong en Java ainsi que d'une partie du code.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
