

Tout d'abord, laissez-moi vous expliquer un terme Lorsque vous regardez les informations liées aux transactions distribuées, vous verrez souvent un terme : compensation inversée. Qu’est-ce que la compensation inversée ?
Permettez-moi de vous donner un exemple : supposons que nous ayons maintenant trois microservices, à savoir A, B et C. Maintenant, nous appelons respectivement les services B et C dans le service A. Afin de garantir que B et C réussissent ou échouent en même temps le temps, nous devons utiliser les affaires formelles de distribution. Mais selon notre compréhension précédente des transactions locales, pour les transactions locales dans B et C, une fois la transaction dans le service B terminée et soumise, une exception se produit dans la transaction dans le service C et doit être annulée. Cependant, B l'a déjà fait. soumis. Comment revenir en arrière ?
La restauration dont nous parlons en ce moment n'est en fait pas le sens traditionnel de restaurer le journal de rétablissement MySQL, mais d'utiliser une mise à jour SQL pour restaurer les données modifiées dans le service B.
C'est ce qu'on appelle la compensation inversée !
Il existe trois concepts de base dans Seata :
TC (Coordinateur de transactions) - Coordinateur de transactions : maintient le statut des transactions globales et des succursales et pilote la soumission ou l'annulation des transactions globales.
TM (Transaction Manager) - Transaction Manager : définissez la portée des transactions globales, démarrez des transactions globales, validez ou annulez des transactions globales.
RM (Resource Manager) - Resource Manager : gère les ressources (Resource) pour le traitement des transactions de branche, parle à TC pour enregistrer les transactions de branche et signaler l'état des transactions de branche, et amène les transactions de branche à s'engager ou à annuler.
Parmi eux, TC est un serveur déployé séparément, et TM et RM sont des clients intégrés dans l'application.
Jetons un coup d'œil à l'image suivante :
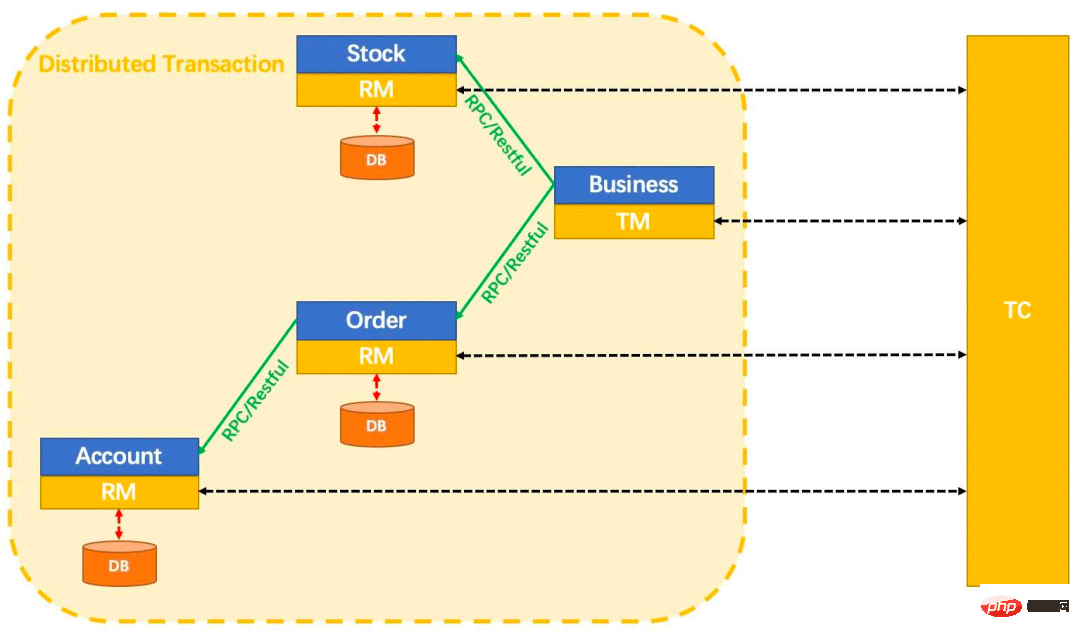
Cette image explique clairement ces trois concepts.
En fait, sans regarder cette image, on peut probablement deviner le principe de mise en œuvre des transactions distribuées : il doit d'abord y avoir un coordinateur de transactions global (TC), et chaque transaction locale (RM) commence à s'exécuter, ou lors de l'exécution en cours , il signale son statut au coordinateur de transactions globales en temps opportun. Le coordinateur de transactions globales connaît l'état d'exécution actuel de chaque transaction de branche. Lorsqu'il (TC) constate que toutes les transactions locales ont été exécutées avec succès, il en informe tout le monde. ensemble ; lorsqu'il constate que quelqu'un n'a pas réussi à exécuter cette transaction, il informera tout le monde de revenir en arrière ensemble (bien sûr, ce rollback n'est pas nécessairement un véritable rollback, mais une compensation inversée). Alors, quand commence et se termine une transaction ? Autrement dit, où sont les limites de la transaction ? Les transactions distribuées dans Seata sont toutes implémentées via des annotations @GlobalTransactional. En d'autres termes, où cette annotation doit-elle être ajoutée ? L'endroit où ajouter cette annotation est en fait le gestionnaire de transactions TM.
Après l'introduction ci-dessus, les amis doivent comprendre qu'utiliser Seata pour mettre en œuvre des transactions distribuées n'est pas aussi difficile qu'on l'imagine, et le principe est toujours très simple.
Seata implique quatre modes différents. Les quatre modes différents présentés ensuite parlent en fait de la manière de revenir en arrière lorsqu'une transaction locale échoue ? Ce sont les quatre modes de transaction distribués différents dont nous parlerons plus tard.
Premier coup d'œil à l'image ci-dessous :

Cette image implique trois concepts :
AP : Cela va sans dire, l'AP. est l'application elle-même.
RM : RM est le gestionnaire de ressources, qui est le participant à la transaction. Dans la plupart des cas, il fait référence à la base de données. Une transaction distribuée implique souvent plusieurs RM.
TM : TM est le gestionnaire de transactions, qui crée des transactions distribuées et coordonne l'exécution et le statut de chaque sous-transaction dans la transaction distribuée. Les sous-transactions font référence à des opérations spécifiques effectuées sur RM.
Alors, qu'est-ce que le Two-Phase Commit (2PC en abrégé) ?
La vérité sur la soumission en deux étapes est très simple. Brother Song vous donnera un exemple simple pour expliquer la soumission en deux étapes :
Par exemple, l'image suivante :
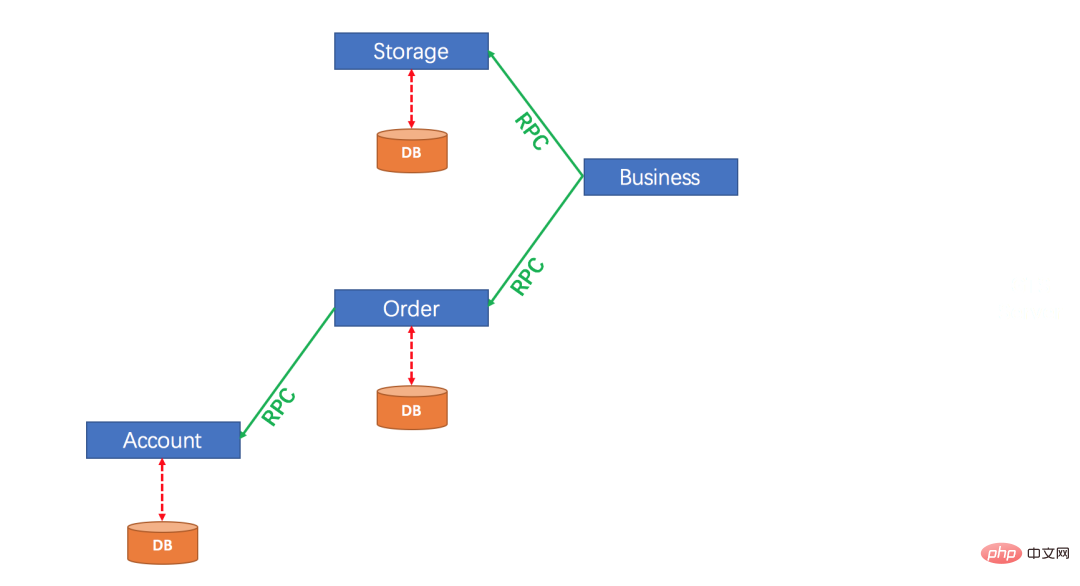
Nous appelons Stockage et Commande. respectivement dans Business Account, les opérations dans ces trois services doivent réussir ou échouer en même temps, mais comme ces trois services sont dans des services différents, nous ne pouvons que laisser les opérations dans ces trois services être exécutées séparément. Les transactions dans les trois services sont exécutées. séparément. La première des deux étapes.
Une fois la première phase d'exécution terminée, ne vous précipitez pas pour soumettre, car certains des trois services peuvent avoir échoué à s'exécuter. À ce stade, les trois services doivent signaler les résultats d'exécution de leur première phase à un coordinateur de transaction. .Le coordinateur de transactions Après avoir reçu le message, si la première phase des trois services est exécutée avec succès, les trois transactions seront respectivement invitées à se soumettre. Si l'un des trois services ne s'exécute pas, les trois transactions seront invitées à annuler. respectivement.
C'est ce qu'on appelle un commit en deux phases.
Pour résumer : Dans une soumission en deux phases, la transaction est divisée entre les participants (comme chaque service spécifique sur la photo ci-dessus) et le coordinateur. Les participants informeront le coordinateur du succès ou de l'échec de l'opération, puis le. Le coordinateur prendra des décisions en fonction des informations de retour de tous les participants. Que le participant souhaite soumettre l'opération ou abandonner l'opération, le participant ici peut être compris comme RM et le coordinateur peut être compris comme TM.
Cependant, les différents modes de transaction distribués dans Seata évoluent essentiellement sur la base d'une soumission en deux phases, ils ne sont donc pas exactement les mêmes. Les amis doivent y prêter attention.
Le mode AT est un mode de restauration de transaction entièrement automatique.
Dans l'ensemble, le mode AT est une évolution du protocole de validation en deux phases :
Une phase : les données commerciales et les enregistrements du journal de restauration sont validés dans la même transaction locale, libérant les verrous locaux et les ressources de connexion.
La deuxième phase est divisée en deux situations : 2.1 Soumettre de manière asynchrone, qui se réalise très rapidement. 2.2 Rollback effectue une compensation inverse via un journal de restauration en une étape.
La logique générale est la suivante. Regardons comment le mode AT fonctionne à travers un cas spécifique :
Supposons qu'il existe un produit de table métier, comme suit :
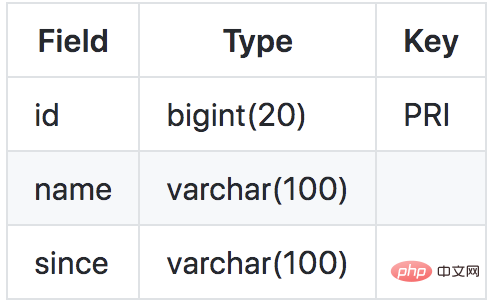
Maintenant, nous voulons faire l'opération de mise à jour suivante :
update product set name = 'GTS' where name = 'TXC';
Les étapes sont les suivantes :
Phase un :
Analyser SQL : obtenir le type SQL (UPDATE), la table (produit), la condition (où nom = ' TXC' ) et d'autres informations connexes.
Image de pré-requête : sur la base des informations conditionnelles obtenues par analyse, générez des instructions de requête et localisez les données (recherchez les données avant la mise à jour).
Exécutez la mise à jour SQL ci-dessus.
Interrogez le post-miroir : sur la base des résultats du pré-miroir, localisez les données via la clé primaire.
Insérer le journal de restauration : combinez les données miroir avant et après et les informations relatives au SQL métier dans un enregistrement de journal de restauration et insérez-le dans la table UNDO_LOG.
Avant de soumettre, enregistrez la branche auprès de TC : demandez un verrouillage global pour l'enregistrement avec la valeur de clé primaire égale à 1 dans la table des produits.
Soumission des transactions locales : la mise à jour des données commerciales est soumise avec le UNDO LOG généré à l'étape précédente.
Rapportez les résultats de la soumission des transactions locales à TC.
Deuxième phase :
La deuxième phase est divisée en deux situations, commit ou rollback.
Examinons d'abord les étapes de restauration :
Tout d'abord, recevez la demande de restauration de branche de TC, démarrez une transaction locale et effectuez les opérations suivantes.
Trouvez l'enregistrement UNDO LOG correspondant via XID et Branch ID (cet enregistrement stocke les images correspondantes avant et après la modification des données).
Vérification des données : Comparez la post-image dans UNDO LOG avec les données actuelles. S'il y a une différence, cela signifie que les données ont été modifiées par des actions autres que la transaction globale en cours. Cette situation doit être gérée conformément à la politique de configuration.
Générez et exécutez des instructions de restauration basées sur les informations pertinentes de l'image précédente et du SQL métier dans UNDO LOG : mettre à jour le nom de l'ensemble de produits = 'TXC' où id = 1 ;update product set name = 'TXC' where id = 1;
提交本地事务。并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
再来看提交步骤:
收到 TC 的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录。
大致上就是这样一个步骤,思路还是比较清晰的,就是当你要更新一条记录的时候,系统将这条记录更新之前和更新之后的内容生成一段 JSON 并存入 undo log 表中,将来要回滚的话,就根据 undo log 中的记录去更新数据(反向补偿),将来要是不回滚的话,就删除 undo log 中的记录。
在整个过程中,开发者只需要额外创建一张 undo log 表就行了,然后给需要处理全局事务的地方加上 @GlobalTransactional
Regardons à nouveau les étapes de soumission :
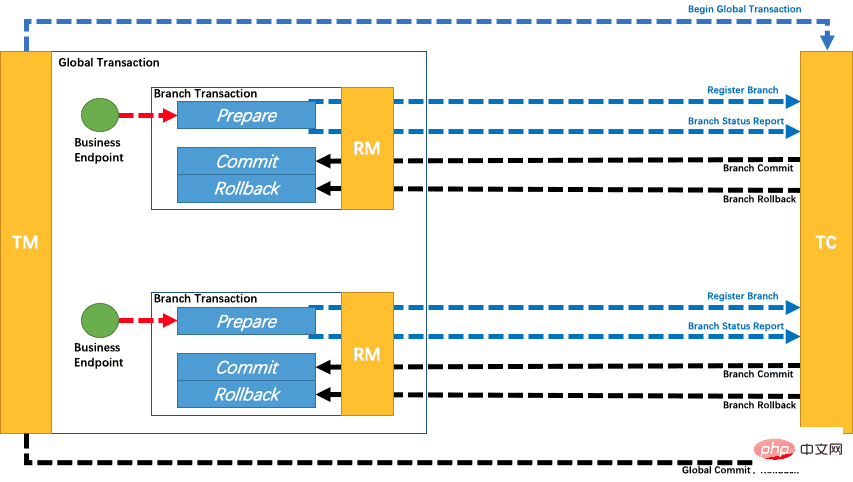 reçoit la demande de soumission de branche de TC, place la demande dans une file d'attente de tâches asynchrone et renvoie immédiatement le résultat de soumission réussi à TC.
reçoit la demande de soumission de branche de TC, place la demande dans une file d'attente de tâches asynchrone et renvoie immédiatement le résultat de soumission réussi à TC.
@GlobalTransactional là où les transactions globales doivent être traitées. 🎜🎜Les autres soumissions, rollbacks et rollbacks sont tous entièrement automatiques, ce qui est plus facile à faire. Ainsi, si vous choisissez d'utiliser Seata pour gérer les transactions distribuées dans votre projet, la probabilité d'utiliser le mode AT est encore assez élevée. 🎜🎜5. Mode TCC🎜🎜Le mode TCC (Try-Confirm-Cancel) a une sensation un peu manuelle. Il est également en deux étapes, mais il est différent de l'AT. 🎜🎜🎜Il y a un organigramme du TCC sur le site officiel, jetons-y un coup d'oeil : 🎜🎜🎜🎜🎜🎜Comme vous pouvez le voir, le TCC est également divisé en deux étapes : 🎜La première étape est la préparation. A cette étape, elle effectue principalement la détection et la réservation des ressources, comme les virements bancaires. A cette étape, nous vérifions d'abord si l'argent de l'utilisateur est suffisant. Si ce n'est pas suffisant, il le fera. lancez une exception directement si cela suffit, elle sera activée en premier.
La deuxième étape est la validation ou le rollback. Il s'agit principalement d'attendre que la première étape de chaque transaction de branche soit terminée. Une fois toutes les exécutions terminées, chacune rapportera sa propre situation à TC. a constaté qu'il n'y a aucune anomalie dans chaque transaction de succursale, puis informez tout le monde de soumettre ensemble si TC constate qu'une transaction de succursale est anormale, puis informez tout le monde d'annuler.
Ensuite, vos amis ont peut-être découvert que le processus ci-dessus implique un total de trois méthodes, préparer, valider et restaurer. Ces trois méthodes sont des méthodes entièrement définies par l'utilisateur et nous devons les implémenter nous-mêmes, alors j'ai dit. le début que TCC est un mode manuel.
Par rapport à AT, tout le monde a constaté que le mode TCC ne dépend en réalité pas de la prise en charge des transactions par la base de données sous-jacente. En d'autres termes, cela n'a pas d'importance même si votre base de données sous-jacente ne prend pas en charge les transactions. Quoi qu'il en soit, les trois méthodes de préparation. , commit et rollback sont Les développeurs l'ont écrit eux-mêmes, et il suffit de lisser les processus correspondant à ces trois méthodes.
Si vous comprenez les transactions XA de la base de données MySQL, alors vous comprendrez en quoi consiste le mode XA dans Seata.
La spécification XA est un standard de traitement transactionnel distribué (DTP, Distributed Transaction Processing) défini par l'organisation X/Open.
La spécification XA décrit l'interface entre le gestionnaire de transactions global et le gestionnaire de ressources local. Le but de la spécification XA est de permettre l'accès à plusieurs ressources (telles que des bases de données, des serveurs d'applications, des files d'attente de messages, etc.) dans la même transaction, afin que les propriétés ACID restent valides dans toutes les applications.
La spécification XA utilise une validation en deux phases pour garantir que toutes les ressources valident ou annulent une transaction spécifique en même temps.
La spécification XA a été proposée au début des années 1990. Actuellement, presque toutes les bases de données grand public prennent en charge la spécification XA.
Les transactions XA sont basées sur le protocole de validation en deux phases. Un coordinateur de transaction est nécessaire pour garantir que tous les participants à la transaction ont terminé le travail de préparation (première phase). Si le coordinateur reçoit un message indiquant que tous les participants sont prêts, il notifiera que toutes les transactions peuvent être validées (phase 2). MySQL joue le rôle de participant à cette transaction XA, et non de coordinateur (gestionnaire de transactions).
Les transactions XA de MySQL sont divisées en XA interne et XA externe. XA externe peut participer à des transactions distribuées externes et nécessite que la couche d'application intervienne en tant que coordinateur ; les transactions XA internes sont utilisées pour les transactions inter-moteurs sous la même instance, avec Binlog comme coordinateur. Par exemple, lorsqu'un moteur de stockage s'engage, le. commit doit être Les informations sont écrites dans le journal binaire, qui est une transaction XA interne distribuée, sauf que le participant au journal binaire est MySQL lui-même. MySQL joue le rôle de participant aux transactions XA, pas de coordinateur.
En d'autres termes, MySQL peut naturellement implémenter des transactions distribuées via la spécification XA, mais il n'a besoin que du support de certaines applications externes. Jetons un coup d'œil au processus d'utilisation du mode XA dans Seata.
Premier aperçu d'une photo officielle :
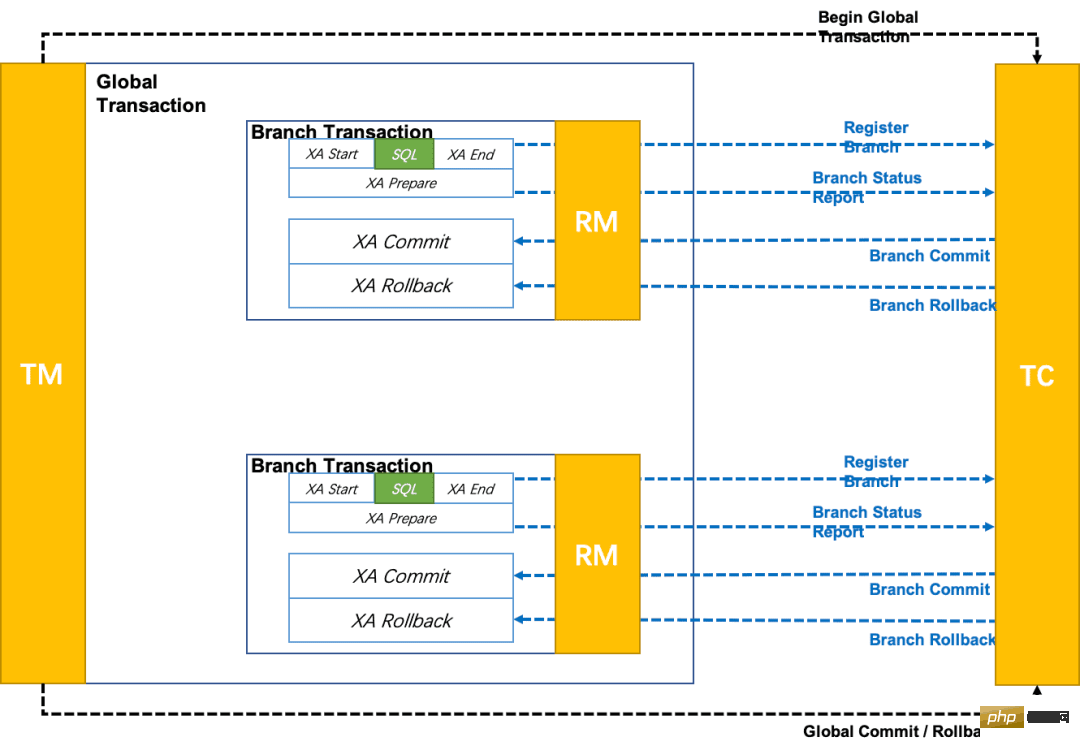
Comme vous pouvez le constater, il s'agit également d'une soumission en deux étapes :
Phase 1 : Les opérations Business SQL sont effectuées dans la branche XA, XA Une fois la branche terminée, la préparation XA est exécutée et la persistance est garantie par la prise en charge par RM du protocole XA (c'est-à-dire que tout accident ultérieur ne provoquera pas d'échec de restauration).
La deuxième phase est divisée en deux situations : commit ou rollback :
Branch commit : exécute le commit de la branche XA
Branch rollback : exécute le rollback de la branche. La différence est que le rollback dans Le mode XA est un sérieux retour en arrière, comme nous l’entendons au sens traditionnel, plutôt qu’une compensation inversée.
Enfin, jetons un coup d'œil au mode saga. Ce mode est rarement utilisé, vous pouvez donc simplement le comprendre.
Ce mode saga est un peu comme un moteur de processus. Le développeur dessine d'abord lui-même un moteur de processus et inclut toutes les méthodes impliquées dans l'ensemble de la transaction. Ce que chaque méthode renvoie est normal, et ce qui est renvoyé est anormal et normal si. c'est anormal, continuez à descendre. Si c'est anormal, un autre ensemble de processus sera exécuté, c'est-à-dire que nous devons préparer deux ensembles de méthodes à l'avance. Le premier ensemble est le processus d'exécution pour diverses situations normales. le deuxième ensemble est le processus d'exécution après qu'une exception se produit. , semblable à ce qui suit :
Les verts sont des processus normaux et les rouges sont les processus qui sont annulés après qu'une exception se produit. Le rollback est aussi une sorte de compensation inversée.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



