
 Périphériques technologiques
IA
Extension de la technologie d'application TensorFlow : classification des images
Périphériques technologiques
IA
Extension de la technologie d'application TensorFlow : classification des images
Extension de la technologie d'application TensorFlow : classification des images

1. Expansion des opérations de déploiement de l'environnement de la plateforme de recherche scientifique
Pour la formation de modèles en apprentissage automatique, je vous recommande d'apprendre davantage de cours ou de ressources TensorFlow officiels, tels que les deux cours du MOOC de l'université chinoise《Introduction à TensorFlow pratique Cours d'opérations》et《Cours d'introduction à TensorFlow - Déploiement》. Pour la formation distribuée de modèles impliqués dans la recherche ou le travail scientifique, une plate-forme de ressources peut souvent prendre beaucoup de temps et ne pas être en mesure de répondre aux besoins individuels en temps opportun. Ici, je vais faire une extension spécifique de l'utilisation de la plateforme Jiutian Bisheng mentionnée dans l'article précédent "Compréhension préliminaire de l'apprentissage du framework TensorFlow"pour permettre aux étudiants et aux utilisateurs d'effectuer plus rapidement une formation sur modèle. Cette plate-forme peut effectuer des tâches telles que la gestion des données et la formation de modèles, et constitue une plate-forme pratique pratique et rapide pour les tâches de recherche scientifique. Les étapes spécifiques de la formation du modèle sont les suivantes :
(1) Inscrivez-vous et connectez-vous à la plateforme Jiutian Bisheng. Étant donné que les tâches de formation ultérieures nécessitent la consommation de beans de puissance de calcul, le nombre de beans de puissance de calcul pour les nouveaux utilisateurs est limité, mais ils peuvent le faire. être obtenu grâce à des tâches telles que le partage avec des amis. Achèvement de l'acquisition de beans de puissance de calcul. Parallèlement, pour les tâches de formation de modèles à grande échelle, afin d'obtenir plus d'espace de stockage de formation de modèles, vous pouvez contacter le personnel de la plateforme par e-mail pour mettre à niveau la console, répondant ainsi aux exigences de stockage de formation requises à l'avenir. Les détails des beans de stockage et de puissance de calcul sont les suivants :

(2) Entrez dans l'interface de gestion des données pour déployer les ensembles de données utilisés par le modèle de projet de recherche scientifique et complétez les ensembles de données requis pour la formation du modèle en empaquetant et télécharger les ensembles de données nécessaires aux tâches de recherche scientifique Déploiement sur cette plateforme.
(3) Ajoutez une nouvelle instance de formation de projet dans la fenêtre de formation du modèle, sélectionnez l'ensemble de données précédemment importé et les ressources CPU requises. L'instance créée est un fichier modèle unique qui doit être formé pour la recherche scientifique. Les détails de la nouvelle instance de projet sont présentés dans la figure ci-dessous :

(4) Exécutez la nouvelle instance de projet, c'est-à-dire exécutez l'environnement de formation du projet. Une fois l'opération réussie, vous pouvez choisir l'instance. éditeur jupyter pour créer et modifier le fichier de code requis.

(5) L'écriture ultérieure du code et la formation du modèle peuvent être effectuées à l'aide de l'éditeur jupyter.
2. Expansion de la technologie de classification d'images
La classification d'images, comme son nom l'indique, consiste à juger les catégories de différentes images en fonction des différences entre les images. Concevoir un modèle discriminant basé sur les différences entre les images est une connaissance qui doit être maîtrisée en apprentissage automatique. Pour les connaissances de base et le processus opérationnel de classification d'images, vous pouvez vous référer au « Cours pratique d'introduction à TensorFlow » sur le MOOC de l'Université chinoise pour comprendre rapidement l'application de base et les idées de conception de TensorFlow. . https://www.php.cn/link/b977b532403e14d6681a00f78f95506e
L'objectif principal de ce chapitre est de fournir aux utilisateurs une compréhension plus approfondie de la classification d'images en développant la technologie de classification d'images.
2.1 A quoi sert l'opération de convolution ?
Quand il s'agit de traiter ou de classer des images, il y a une opération incontournable, et cette opération est la convolution. Les opérations de convolution spécifiques peuvent essentiellement être comprises à travers des vidéos d'apprentissage, mais davantage de lecteurs peuvent seulement rester au niveau de la façon d'effectuer des opérations de convolution, et pourquoi la convolution est effectuée et à quoi servent les opérations de convolution. Un peu de connaissances. Voici une extension pour tout le monde pour vous aider à mieux comprendre la convolution.
Le processus de convolution de base est illustré dans la figure ci-dessous. En prenant une image comme exemple, une matrice est utilisée pour représenter l'image. Chaque élément de la matrice est la valeur de pixel correspondante dans l'image. L'opération de convolution consiste à obtenir les valeurs propres de ces petites zones en multipliant le noyau de convolution par la matrice correspondante. Les caractéristiques extraites varieront en raison des différents noyaux de convolution. C'est pourquoi quelqu'un effectuera des opérations de convolution sur différents canaux de l'image pour obtenir les caractéristiques des différents canaux de l'image afin de mieux effectuer les tâches de classification ultérieures.
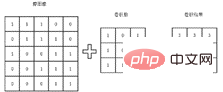
Dans la formation quotidienne du modèle, le noyau de convolution spécifique n'a pas besoin d'être conçu manuellement, mais est automatiquement formé à l'aide du réseau en utilisant l'étiquette réelle de l'image donnée. Cependant, ce processus n'est pas propice à la compréhension du noyau de convolution. Et le processus de convolution, ou pas intuitif. Par conséquent, afin d’aider chacun à mieux comprendre la signification de l’opération de convolution, voici un exemple d’opération de convolution. Comme le montre la matrice ci-dessous, les valeurs numériques représentent les pixels du graphique. Pour faciliter le calcul, seuls 0 et 1 sont pris ici. Il n'est pas difficile de voir que les caractéristiques de ce graphique matriciel sont supérieures. la moitié du graphique est lumineuse et la moitié inférieure du graphique est noire, donc l'image Il y a une ligne de démarcation très claire, c'est-à-dire qu'elle a des caractéristiques horizontales évidentes.

Par conséquent, afin de bien extraire les caractéristiques horizontales de la matrice ci-dessus, le noyau de convolution conçu doit également avoir les attributs d'extraction de caractéristiques horizontales. Le noyau de convolution utilisant les attributs d'extraction de caractéristiques verticales est relativement insuffisant dans le degré évident d'extraction de caractéristiques. Comme indiqué ci-dessous, le noyau de convolution qui extrait les caractéristiques horizontales est utilisé pour la convolution :
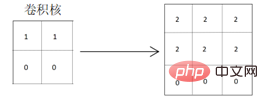
Il ressort de la matrice de résultats de convolution obtenue que les caractéristiques horizontales des graphiques originaux sont bien extraites et que les lignes de séparation des graphiques sera plus évident, car les valeurs de pixels des parties colorées des graphiques sont approfondies, ce qui extrait et met en évidence les caractéristiques horizontales des graphiques. Lors de l'utilisation d'un noyau de convolution qui extrait les caractéristiques verticales pour la convolution :
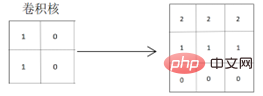
Il peut être vu à partir de la matrice de résultats de convolution obtenue que les caractéristiques horizontales du graphique original peuvent également être extraites, mais deux lignes de démarcation seront générées et la les changements graphiques sont les suivants : De particulièrement clair à clair puis au noir, la situation reflétée sur les graphiques réels passe du clair au foncé puis au noir, ce qui est différent des caractéristiques horizontales des graphiques originaux réels.
Il est facile de savoir à partir des exemples ci-dessus que différents noyaux de convolution affecteront la qualité des caractéristiques graphiques finales extraites. Dans le même temps, les caractéristiques reflétées par différents graphiques sont également différentes. différents attributs de fonctionnalités graphiques ? Il est également particulièrement essentiel de mieux apprendre et concevoir les noyaux de convolution. Dans les projets réels de classification de cartes, il est nécessaire de sélectionner et d’extraire les caractéristiques appropriées en fonction des différences entre les images, et des compromis doivent souvent être pris en compte.
2.2 Comment envisager la convolution pour une meilleure classification des images ?
Comme vous pouvez le voir sur le rôle des opérations de convolution dans la section précédente, il est particulièrement important de concevoir un modèle de réseau pour mieux apprendre le noyau de convolution qui s'adapte à l'image. Cependant, dans les applications pratiques, l'apprentissage et la formation automatiques sont effectués en convertissant les étiquettes réelles des catégories d'images données en données vectorielles que la machine peut comprendre. Bien entendu, il n’est pas totalement impossible de s’améliorer via des réglages manuels. Bien que les étiquettes de l'ensemble de données soient fixes, nous pouvons choisir différents modèles de réseau en fonction des types d'images de l'ensemble de données. La prise en compte des avantages et des inconvénients des différents modèles de réseau donnera souvent de bons résultats de formation.
Dans le même temps, lors de l'extraction des caractéristiques de l'image, vous pouvez également envisager d'utiliser la méthode d'apprentissage multitâche. Dans les données d'image existantes, utilisez à nouveau les données d'image pour extraire certaines caractéristiques d'image supplémentaires (telles que les caractéristiques de canal et les caractéristiques spatiales de). l'image, etc. ), puis complétez ou remplissez les caractéristiques précédemment extraites pour améliorer les caractéristiques de l'image extraite finale. Bien entendu, cette opération entraînera parfois une redondance des caractéristiques extraites et l'effet de classification obtenu est souvent contre-productif. Par conséquent, il doit être pris en compte sur la base des résultats réels de la classification de la formation.
2.3 Quelques suggestions pour la sélection du modèle de réseau
Le domaine de la classification d'images s'est développé depuis longtemps, du modèle de réseau classique original AlexNet au modèle de réseau ResNet populaire ces dernières années, la technologie de classification d'images est relativement complète. , la précision de la classification de certains ensembles de données d'images couramment utilisés a tendance à atteindre 100 %. À l'heure actuelle, dans ce domaine, la plupart des gens utilisent les derniers modèles de réseau, et dans la plupart des tâches de classification d'images, l'utilisation des derniers modèles de réseau peut en effet apporter des effets de classification évidents. Par conséquent, de nombreuses personnes dans ce domaine ignorent souvent les modèles de réseau précédents et y vont directement. pour découvrir les modèles de réseau les plus récents et les plus populaires.
Ici, je recommande toujours aux lecteurs de se familiariser avec certains modèles de réseau classiques dans le domaine de la classification des graphiques, car les mises à jour technologiques et les itérations sont très rapides, et même les derniers modèles de réseau pourraient être éliminés à l'avenir, mais les principes de fonctionnement. Les modèles de réseau de base sont à peu près les mêmes. En maîtrisant les modèles de réseau classiques, vous pouvez non seulement maîtriser les principes de base, mais également comprendre les différences entre les différents modèles de réseau ainsi que les avantages et les inconvénients du traitement de différentes tâches. Par exemple, lorsque votre ensemble de données d'image est relativement petit, la formation avec le dernier modèle de réseau peut être très complexe et prendre beaucoup de temps, mais l'effet d'amélioration est minime, donc sacrifier votre propre coût de temps de formation pour un effet négligeable ne vaut pas le gain. . Par conséquent, pour maîtriser le modèle de réseau de classification d'images, vous devez savoir de quoi il s'agit et pourquoi il existe afin de pouvoir véritablement être ciblé lors du choix d'un modèle de classification d'images à l'avenir.
Présentation de l'auteur :
Porridge, rédacteur en chef de la communauté 51CTO, a déjà travaillé dans le département de technologie Big Data d'un centre de recherche et développement sur l'intelligence artificielle pour le commerce électronique, en créant des algorithmes de recommandation. Actuellement engagé dans des recherches dans le domaine du traitement du langage naturel, ses principaux domaines d'expertise comprennent les algorithmes de recommandation, le PNL et le CV. Les langages de codage utilisés incluent Java, Python et Scala. Publication d'un document de conférence de l'ICCC.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment annuler la suppression de l'écran d'accueil sur iPhone
Apr 17, 2024 pm 07:37 PM
Comment annuler la suppression de l'écran d'accueil sur iPhone
Apr 17, 2024 pm 07:37 PM
Vous avez supprimé quelque chose d'important de votre écran d'accueil et vous essayez de le récupérer ? Vous pouvez remettre les icônes d’applications à l’écran de différentes manières. Nous avons discuté de toutes les méthodes que vous pouvez suivre et remettre l'icône de l'application sur l'écran d'accueil. Comment annuler la suppression de l'écran d'accueil sur iPhone Comme nous l'avons mentionné précédemment, il existe plusieurs façons de restaurer cette modification sur iPhone. Méthode 1 – Remplacer l'icône de l'application dans la bibliothèque d'applications Vous pouvez placer une icône d'application sur votre écran d'accueil directement à partir de la bibliothèque d'applications. Étape 1 – Faites glisser votre doigt sur le côté pour trouver toutes les applications de la bibliothèque d'applications. Étape 2 – Recherchez l'icône de l'application que vous avez supprimée précédemment. Étape 3 – Faites simplement glisser l'icône de l'application de la bibliothèque principale vers le bon emplacement sur l'écran d'accueil. Voici le schéma d'application
 Le rôle et l'application pratique des symboles fléchés en PHP
Mar 22, 2024 am 11:30 AM
Le rôle et l'application pratique des symboles fléchés en PHP
Mar 22, 2024 am 11:30 AM
Le rôle et l'application pratique des symboles fléchés en PHP En PHP, le symbole fléché (->) est généralement utilisé pour accéder aux propriétés et méthodes des objets. Les objets sont l'un des concepts de base de la programmation orientée objet (POO) en PHP. Dans le développement actuel, les symboles fléchés jouent un rôle important dans le fonctionnement des objets. Cet article présentera le rôle et l'application pratique des symboles fléchés et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre. 1. Le rôle du symbole flèche pour accéder aux propriétés d'un objet. Le symbole flèche peut être utilisé pour accéder aux propriétés d'un objet. Quand on instancie une paire
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
 Du débutant au compétent : explorez différents scénarios d'application de la commande Linux tee
Mar 20, 2024 am 10:00 AM
Du débutant au compétent : explorez différents scénarios d'application de la commande Linux tee
Mar 20, 2024 am 10:00 AM
La commande Linuxtee est un outil de ligne de commande très utile qui peut écrire la sortie dans un fichier ou envoyer la sortie à une autre commande sans affecter la sortie existante. Dans cet article, nous explorerons en profondeur les différents scénarios d'application de la commande Linuxtee, du débutant au compétent. 1. Utilisation de base Tout d'abord, jetons un coup d'œil à l'utilisation de base de la commande tee. La syntaxe de la commande tee est la suivante : tee[OPTION]...[FILE]...Cette commande lira les données de l'entrée standard et enregistrera les données dans
 Découvrez les avantages et les scénarios d'application du langage Go
Mar 27, 2024 pm 03:48 PM
Découvrez les avantages et les scénarios d'application du langage Go
Mar 27, 2024 pm 03:48 PM
Le langage Go est un langage de programmation open source développé par Google et lancé pour la première fois en 2007. Il est conçu pour être un langage simple, facile à apprendre, efficace et hautement simultané, et est favorisé par de plus en plus de développeurs. Cet article explorera les avantages du langage Go, présentera quelques scénarios d'application adaptés au langage Go et donnera des exemples de code spécifiques. Avantages : Forte concurrence : le langage Go prend en charge de manière intégrée les threads-goroutine légers, qui peuvent facilement implémenter une programmation simultanée. Goroutin peut être démarré en utilisant le mot-clé go
 Revoir! Fusion profonde de modèles (LLM/modèle de base/apprentissage fédéré/mise au point, etc.)
Apr 18, 2024 pm 09:43 PM
Revoir! Fusion profonde de modèles (LLM/modèle de base/apprentissage fédéré/mise au point, etc.)
Apr 18, 2024 pm 09:43 PM
Le 23 septembre, l'article « DeepModelFusion:ASurvey » a été publié par l'Université nationale de technologie de la défense, JD.com et l'Institut de technologie de Pékin. La fusion/fusion de modèles profonds est une technologie émergente qui combine les paramètres ou les prédictions de plusieurs modèles d'apprentissage profond en un seul modèle. Il combine les capacités de différents modèles pour compenser les biais et les erreurs des modèles individuels pour de meilleures performances. La fusion profonde de modèles sur des modèles d'apprentissage profond à grande échelle (tels que le LLM et les modèles de base) est confrontée à certains défis, notamment un coût de calcul élevé, un espace de paramètres de grande dimension, l'interférence entre différents modèles hétérogènes, etc. Cet article divise les méthodes de fusion de modèles profonds existantes en quatre catégories : (1) « Connexion de modèles », qui relie les solutions dans l'espace de poids via un chemin de réduction des pertes pour obtenir une meilleure fusion de modèles initiale.
 Plus qu'une simple gaussienne 3D ! Dernier aperçu des techniques de reconstruction 3D de pointe
Jun 02, 2024 pm 06:57 PM
Plus qu'une simple gaussienne 3D ! Dernier aperçu des techniques de reconstruction 3D de pointe
Jun 02, 2024 pm 06:57 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que la reconstruction 3D basée sur l'image est une tâche difficile qui implique de déduire la forme 3D d'un objet ou d'une scène à partir d'un ensemble d'images d'entrée. Les méthodes basées sur l’apprentissage ont attiré l’attention pour leur capacité à estimer directement des formes 3D. Cet article de synthèse se concentre sur les techniques de reconstruction 3D de pointe, notamment la génération de nouvelles vues inédites. Un aperçu des développements récents dans les méthodes d'éclaboussure gaussienne est fourni, y compris les types d'entrée, les structures de modèle, les représentations de sortie et les stratégies de formation. Les défis non résolus et les orientations futures sont également discutés. Compte tenu des progrès rapides dans ce domaine et des nombreuses opportunités d’améliorer les méthodes de reconstruction 3D, un examen approfondi de l’algorithme semble crucial. Par conséquent, cette étude fournit un aperçu complet des progrès récents en matière de diffusion gaussienne. (Faites glisser votre pouce vers le haut
 GPT-4o révolutionnaire : remodeler l'expérience d'interaction homme-machine
Jun 07, 2024 pm 09:02 PM
GPT-4o révolutionnaire : remodeler l'expérience d'interaction homme-machine
Jun 07, 2024 pm 09:02 PM
Le modèle GPT-4o publié par OpenAI constitue sans aucun doute une énorme avancée, notamment dans sa capacité à traiter plusieurs supports d'entrée (texte, audio, images) et à générer la sortie correspondante. Cette capacité rend l’interaction homme-machine plus naturelle et intuitive, améliorant considérablement l’aspect pratique et la convivialité de l’IA. Plusieurs points forts de GPT-4o incluent : une évolutivité élevée, des entrées et sorties multimédias, de nouvelles améliorations des capacités de compréhension du langage naturel, etc. 1. Entrée/sortie multimédia : GPT-4o+ peut accepter n'importe quelle combinaison de texte, d'audio et d'images en entrée et générer directement une sortie à partir de ces médias. Cela brise les limites des modèles d’IA traditionnels qui ne traitent qu’un seul type d’entrée, rendant ainsi l’interaction homme-machine plus flexible et plus diversifiée. Cette innovation contribue à alimenter les assistants intelligents
