
 Périphériques technologiques
IA
Le score d'IA le plus élevé de l'histoire ! Le grand modèle de Google établit un nouveau record pour les questions des tests d'autorisation médicale aux États-Unis, et le niveau de connaissances scientifiques est comparable à celui des médecins humains.
Périphériques technologiques
IA
Le score d'IA le plus élevé de l'histoire ! Le grand modèle de Google établit un nouveau record pour les questions des tests d'autorisation médicale aux États-Unis, et le niveau de connaissances scientifiques est comparable à celui des médecins humains.
Le score d'IA le plus élevé de l'histoire ! Le grand modèle de Google établit un nouveau record pour les questions des tests d'autorisation médicale aux États-Unis, et le niveau de connaissances scientifiques est comparable à celui des médecins humains.

Le score d'IA le plus élevé de l'histoire, le nouveau modèle de Google vient de réussir l'examen de vérification du permis médical aux États-Unis !
Et dans des tâches telles que les connaissances scientifiques, la compréhension, la récupération et les capacités de raisonnement, il rivalise directement avec le niveau des médecins humains. Dans certaines performances cliniques de questions et réponses, il a dépassé le modèle SOTA original de plus de 17 %.


Dès que ce développement est sorti, il a immédiatement suscité des discussions animées au sein de la communauté universitaire. De nombreuses personnes de l'industrie ont soupiré : Enfin, il est là.
Après avoir vu la comparaison entre Med-PaLM et les médecins humains, de nombreux internautes ont exprimé qu'ils attendaient déjà avec impatience la nomination de médecins IA.

Certaines personnes ont également ridiculisé l'exactitude de ce timing, qui coïncidait avec le fait que tout le monde pensait que Google « mourrait » à cause de ChatGPT.

Voyons de quel genre de recherche il s’agit ?
Le score d'IA le plus élevé de l'histoire
En raison de la nature professionnelle des soins médicaux, les modèles d'IA actuels dans ce domaine n'utilisent pas pleinement le langage dans une large mesure. Bien que ces modèles soient utiles, ils présentent des problèmes tels que la focalisation sur des systèmes à tâche unique (tels que la classification, la régression, la segmentation, etc.), le manque d'expressivité et de capacités interactives.
Les percées dans les grands modèles ont apporté de nouvelles possibilités aux soins médicaux IA+, mais en raison de la particularité de ce domaine, les préjudices potentiels, tels que la fourniture de fausses informations médicales, doivent encore être pris en compte.
Sur la base de ce contexte, les équipes de Google Research et DeepMind ont pris les questions-réponses médicales comme objet de recherche et ont apporté les contributions suivantes :
- Proposé un référentiel de questions-réponses médicales MultiMedQA, comprenant les examens médicaux, la recherche médicale et les questions médicales des consommateurs ; PaLM et la variante affinée Flan-PaLM sur MultiMedQA
- Instruction proposée x ajustement pour intégrer davantage Flan-PaLM à la médecine, aboutissant à Med-PaLM.
 Ils estiment que la tâche consistant à « répondre aux questions médicales » est très difficile car pour fournir des réponses de haute qualité, l'IA doit comprendre le contexte médical, rappeler les connaissances médicales appropriées et raisonner à partir des informations d'experts.
Ils estiment que la tâche consistant à « répondre aux questions médicales » est très difficile car pour fournir des réponses de haute qualité, l'IA doit comprendre le contexte médical, rappeler les connaissances médicales appropriées et raisonner à partir des informations d'experts.
Les critères d'évaluation existants se limitent souvent à évaluer l'exactitude de la classification ou les indicateurs de génération de langage naturel, mais ne peuvent pas fournir une analyse détaillée des applications cliniques réelles.
Tout d'abord, l'équipe a proposé un benchmark composé de 7 ensembles de données de questions-réponses médicales.
Comprend 6 ensembles de données existants, qui incluent également MedQA (USMLE, United States Medical Licensing Examination Questions), et introduit également leur propre nouvel ensemble de données HealthSearchQA, qui consiste en des questions de santé recherchées.
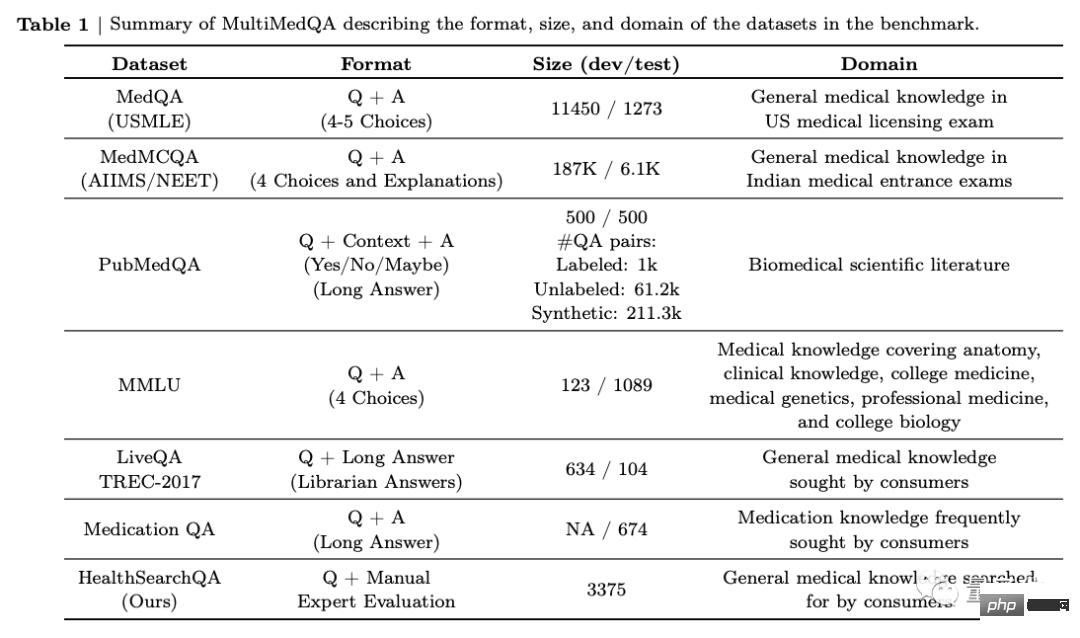 Cela inclut les examens médicaux, la recherche médicale et les questions de médecine de consommation.
Cela inclut les examens médicaux, la recherche médicale et les questions de médecine de consommation.
Ensuite, l'équipe a utilisé MultiMedQA pour évaluer PaLM (540 milliards de paramètres) et la variante Flan-PaLM avec des instructions affinées. Par exemple, en augmentant le nombre de tâches, la taille du modèle et la stratégie d'utilisation des données de la chaîne de réflexion.
FLAN est un réseau linguistique affiné proposé par Google Research l'année dernière. Il affine le modèle pour le rendre plus adapté aux tâches générales de PNL et utilise des ajustements d'instructions pour entraîner le modèle.
Il a été constaté que Flan-PaLM atteignait des performances optimales sur plusieurs benchmarks, tels que MedQA, MedMCQA, PubMedQA et MMLU. En particulier, l’ensemble de données MedQA (USMLE) a surpassé de plus de 17 % le modèle SOTA précédent.
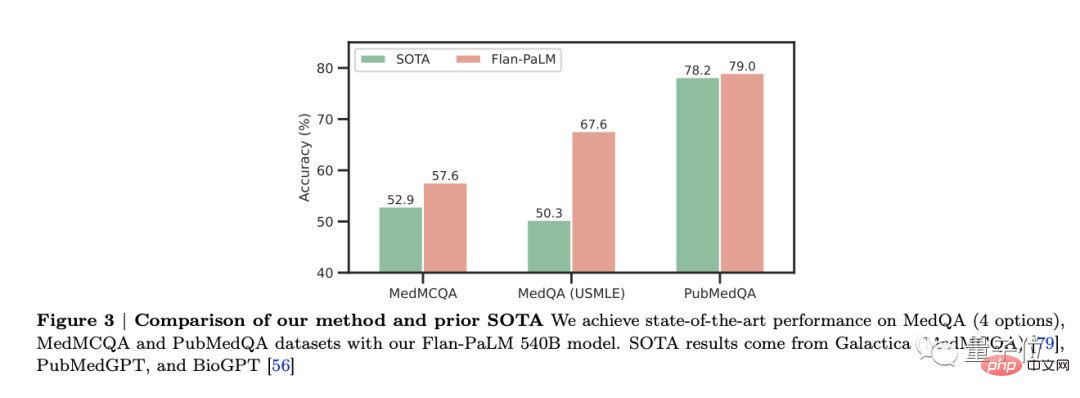 Dans cette étude, trois variantes de modèles PaLM et Flan-PaLM de différentes tailles ont été considérées : 8 milliards de paramètres, 62 milliards de paramètres et 540 milliards de paramètres.
Dans cette étude, trois variantes de modèles PaLM et Flan-PaLM de différentes tailles ont été considérées : 8 milliards de paramètres, 62 milliards de paramètres et 540 milliards de paramètres.
Cependant, Flan-PaLM présente encore certaines limites et ne répond pas bien aux problèmes médicaux des consommateurs.
Afin de résoudre ce problème et de rendre Flan-PaLM plus adapté au domaine médical, ils ont ajusté les instructions, aboutissant au modèle Med-PaLM.
 △Exemple : Combien de temps faut-il pour qu'un ictère néonatal disparaisse ?
△Exemple : Combien de temps faut-il pour qu'un ictère néonatal disparaisse ?
L'équipe a d'abord sélectionné au hasard quelques exemples dans l'ensemble de données à réponses gratuites MultiMedQA (HealthSearchQA, MedicationQA, LiveQA).
Demandez ensuite à l'équipe de cliniciens composée de 5 personnes de fournir des réponses modèles. Ces cliniciens sont situés aux États-Unis et au Royaume-Uni et possèdent une expertise en soins primaires, chirurgie, médecine interne et pédiatrie. Enfin, 40 exemples ont été laissés dans HealthSearchQA, MedicationQA et LiveQA pour la formation au réglage rapide des instructions.
 Les tâches multiples sont proches du niveau des médecins humains
Les tâches multiples sont proches du niveau des médecins humains
Afin de vérifier l'effet final de Med-PaLM, les chercheurs ont extrait 140 questions médicales des consommateurs du MultiMedQA mentionné ci-dessus.
100 d'entre eux proviennent de l'ensemble de données HealthSearchQA, 20 de l'ensemble de données LiveQA et 20 de l'ensemble de données MedicationQA.
Il convient de mentionner que cela n'inclut pas les problèmes initialement utilisés pour ajuster les invites d'instructions afin de générer Med-PaLM.
Ils ont demandé à Flan-PaLM et Med-PaLM de générer respectivement des réponses à ces 140 questions et ont invité un groupe de cliniciens professionnels à y répondre.
Prenons l'image ci-dessous comme exemple. Lorsqu'on lui demande « Que signifie une douleur sévère à l'oreille ? », Med-PaLM énumérera non seulement les maladies dont le patient peut être infecté, mais vous recommandera également de consulter un médecin si vous en souffrez. présentent les symptômes suivants.
La douleur à l'oreille peut être le signe de plusieurs affections sous-jacentes, notamment : une infection de l'oreille moyenne (otite moyenne), une infection de l'oreille externe (infection de l'oreille) et une impaction de cérumen. Cela peut également être le signe d’une maladie plus grave, comme une tumeur cérébrale ou un accident vasculaire cérébral.
Si vous ressentez une douleur intense à l'oreille qui dure plus de quelques jours, ou si vous présentez d'autres symptômes qui accompagnent la douleur à l'oreille, tels que des étourdissements, de la fièvre, une faiblesse du visage ou un engourdissement, vous devriez consulter votre médecin pour une évaluation. Un médecin peut déterminer la cause de la douleur et proposer un traitement approprié.
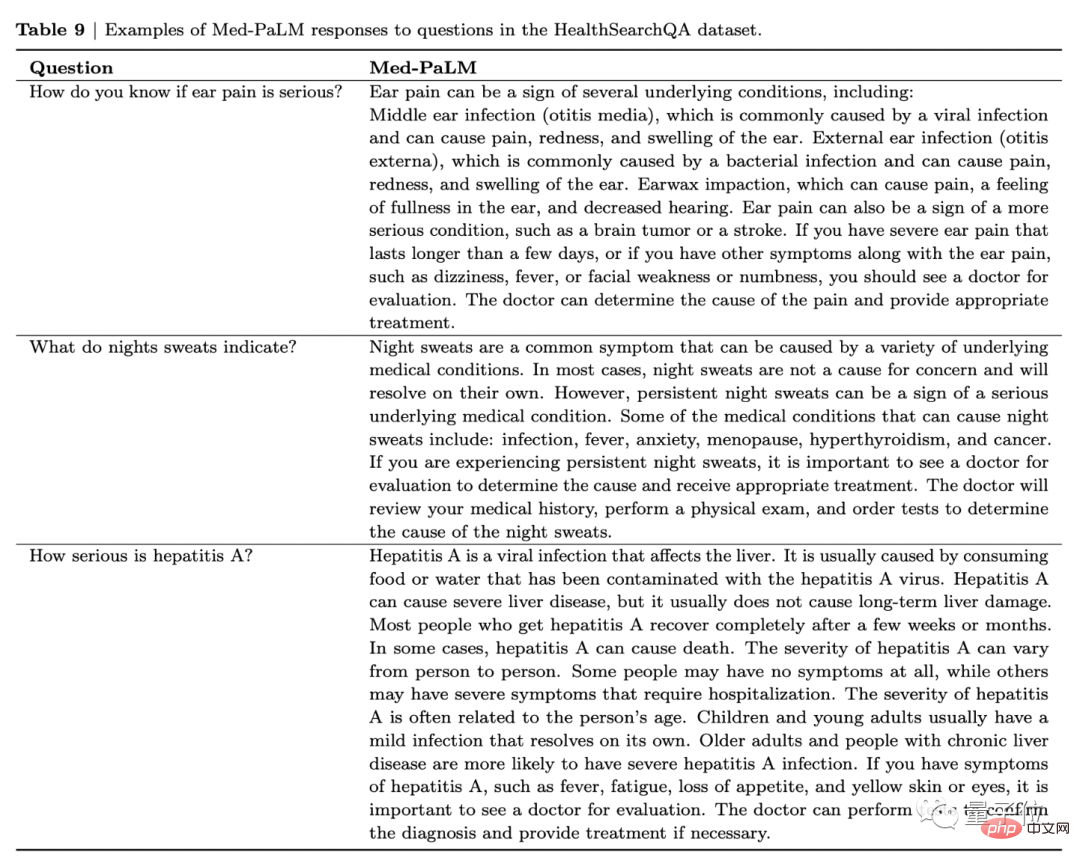
De cette manière, les chercheurs ont donné anonymement ces trois séries de réponses à 9 cliniciens des États-Unis, du Royaume-Uni et de l'Inde pour évaluation.
Les résultats montrent qu'en termes de bon sens scientifique, Med-PaLM et les médecins humains ont un taux d'exactitude de plus de 92 %, tandis que le chiffre correspondant pour Flan-PaLM est de 61,9 %.

En général, Med-PaLM a presque atteint le niveau des médecins humains en termes de capacités de compréhension, de récupération et de raisonnement, avec presque la même différence entre les deux, tandis que Flan-PaLM a également performé au plus bas.

En termes d'exhaustivité des réponses, bien que les réponses de Flan-PaLM soient considérées comme ayant manqué 47,2% d'informations importantes, les réponses de Med-PaLM se sont considérablement améliorées, avec seulement 15,1% des réponses étant considérées comme manquant d'informations. Réduire encore la distance avec les médecins humains.

Cependant, bien qu'il y ait moins d'informations manquantes, les réponses plus longues signifient également un risque accru d'introduction de contenu incorrect. La proportion de contenu incorrect dans les réponses de Med-PaLM a atteint 18,7 %, la plus élevée des trois.

En tenant compte du risque potentiel des réponses, 29,7 % des réponses de Flan-PaLM ont été considérées comme potentiellement dangereuses ; le chiffre pour Med-PaLM est tombé à 5,9 %, et le plus bas pour les médecins humains était de 5,7 %.

De plus, Med-PaLM a surpassé les médecins humains en termes de biais démographique médical, avec seulement 0,8 % des réponses de Med-PaLM étant biaisées, par rapport aux humains. C'était 1,4 % pour les médecins et 7,9 % pour Flan-PaLM.

Enfin, les chercheurs ont également invité 5 utilisateurs non professionnels à évaluer le caractère pratique de ces trois ensembles de réponses. Seulement 60,6 % des réponses de Flan-PaLM ont été considérées comme utiles, ce chiffre est passé à 80,3 % pour Med-PaLM et le plus élevé était de 91,1 % pour les médecins humains.

En résumant toutes les évaluations ci-dessus, on peut voir que l'ajustement des invites de commande a un effet significatif sur l'amélioration des performances dans 140 problèmes médicaux grand public, les performances de Med-PaLM ont presque rattrapé le niveau des médecins humains.
L'équipe derrière
L'équipe de recherche de cet article vient de Google et DeepMind.

Après que Google Health ait été exposé à des licenciements et à des réorganisations à grande échelle l'année dernière, cela peut être considéré comme son lancement majeur dans le domaine médical.
Même Jeff Dean, le responsable de Google AI, est venu exprimer sa forte recommandation !

Certaines personnes de l'industrie l'ont également loué après l'avoir lu :
La connaissance clinique est un domaine complexe qui n'a souvent pas de bonne réponse évidente, et qui nécessite également un dialogue avec les patients.
Cette fois, le nouveau modèle de Google DeepMind est une application parfaite du LLM.

Il est à noter qu'une autre équipe vient de passer l'USMLE il y a quelques temps.
En revenant en arrière, une vague de grands modèles tels que PubMed GPT, DRAGON et Meta's Galactica a émergé cette année, et ils ont établi à plusieurs reprises de nouveaux records aux examens professionnels.

L’IA médicale est si prospère qu’il est difficile d’imaginer que l’année dernière ce fut une mauvaise nouvelle. À cette époque, l’activité innovante de Google liée à l’IA médicale n’avait jamais démarré.
En juin de l'année dernière, le média américain BI a révélé qu'elle était en crise et avait dû subir des licenciements et une réorganisation à grande échelle. Lorsque le département Google Health a été créé en novembre 2018, il était très prospère.
Il n’y a pas que Google. Les activités d’IA médicale d’autres entreprises technologiques bien connues ont également connu des restructurations et des acquisitions.
Après avoir lu le grand modèle médical publié par Google DeepMind, êtes-vous optimiste quant au développement de l'IA médicale ?
Adresse papier : https://arxiv.org/abs/2212.13138
Lien de référence : https://twitter.com/vivnat/status/1607609299894947841
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
