

Comment gérer des objets volumineux en Java

Sous-chaîne dans String
Nous savons tous que String est immuable en Java Si vous modifiez son contenu, elle générera une nouvelle chaîne. Si nous voulons utiliser une partie des données de la chaîne, nous pouvons utiliser la méthode substring.
Ce qui suit est le code source de String en Java11.
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = length() - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
if (beginIndex == 0) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
public static String newString(byte[] val, int index, int len) {
if (String.COMPACT_STRINGS) {
byte[] buf = compress(val, index, len);
if (buf != null) {
return new String(buf, LATIN1);
}
}
int last = index + len;
return new String(Arrays.copyOfRange(val, index << 1, last << 1), UTF16);
}Comme le montre le code ci-dessus, lorsque nous avons besoin d'une sous-chaîne, la sous-chaîne génère une nouvelle chaîne, qui est construite via la fonction Arrays.copyOfRange du constructeur.
Cette fonction n'a plus de problème après Java7, mais en Java6, elle présente un risque de fuite de mémoire. On peut étudier ce cas pour voir les problèmes qui peuvent survenir lors de la réutilisation d'objets volumineux. Voici le code en Java6 :
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ?
this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}Vous pouvez voir que lors de la création d'une sous-chaîne, elle ne copie pas seulement l'objet requis, mais fait référence à la valeur entière. Si la chaîne d'origine est relativement volumineuse, la mémoire ne sera pas libérée même si elle n'est plus utilisée.
Par exemple, le contenu d'un article peut avoir une taille de plusieurs mégaoctets. Nous n'avons besoin que des informations récapitulatives et devons gérer l'intégralité du gros objet.
Certains enquêteurs qui travaillent depuis longtemps ont l'impression que la sous-chaîne est toujours dans le JDK6, mais en fait, Java a déjà modifié ce bug. Si vous rencontrez cette question lors de l'entretien, par mesure de sécurité, vous pouvez répondre à la question sur le processus d'amélioration.
Ce que cela signifie pour nous, c'est : si vous créez un objet relativement volumineux et générez d'autres informations basées sur cet objet, à ce moment-là, vous devez vous rappeler de supprimer la relation de référence avec ce gros objet.
Extension d'objets de grande collection
L'expansion d'objets est un phénomène courant en Java, tel que StringBuilder, StringBuffer, HashMap, ArrayList, etc. En résumé, les données des collections Java, notamment List, Set, Queue, Map, etc., sont incontrôlables. Lorsque la capacité est insuffisante, il y aura des opérations d'expansion. Les opérations d'expansion nécessitent une réorganisation des données, elles ne sont donc pas thread-safe.
Regardons d'abord le code d'extension de StringBuilder :
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}Lorsque la capacité n'est pas suffisante, la mémoire sera doublée et les données source seront copiées à l'aide de Arrays.copyOf.
Ce qui suit est le code d'extension de HashMap. Après l'expansion, la taille est également doublée. Son action d'expansion est beaucoup plus compliquée. En plus de l'impact du facteur de charge, il faut également re-hacher les données d'origine puisque la méthode native Arrays.copy ne peut pas être utilisée, la vitesse sera très lente.
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}Vous pouvez visualiser le code de List par vous-même. Il est également bloquant. La stratégie d'expansion est 1,5 fois la longueur d'origine.
Étant donné que les collections sont utilisées très fréquemment dans le code, si vous connaissez la limite supérieure spécifique des éléments de données, vous souhaiterez peut-être définir une taille d'initialisation raisonnable. Par exemple, HashMap nécessite 1024 éléments et nécessite 7 extensions, ce qui affectera les performances de l'application. Cette question reviendra fréquemment lors des entretiens et il faut comprendre l’impact de ces opérations d’expansion sur les performances.
Mais veuillez noter que pour une collection comme HashMap qui a un facteur de charge (0,75), la taille initiale = le nombre/facteur de charge requis + 1. Si vous n'êtes pas très clair sur la structure sous-jacente, autant conserver le défaut.
Ensuite, j'expliquerai l'optimisation au niveau applicatif à partir de la dimension structurelle et de la dimension temporelle des données.
Maintenir une granularité d'objet appropriée
Laissez-moi partager avec vous un cas pratique : nous avons un système métier à très haute concurrence qui nécessite une utilisation fréquente des données de base des utilisateurs.
Comme le montre la figure ci-dessous, étant donné que les informations de base de l'utilisateur sont stockées dans un autre service, chaque fois que les informations de base de l'utilisateur sont utilisées, une interaction réseau est requise. Ce qui est encore plus inacceptable, c'est que même si seul l'attribut sexe de l'utilisateur est nécessaire, toutes les informations utilisateur doivent être interrogées et extraites.
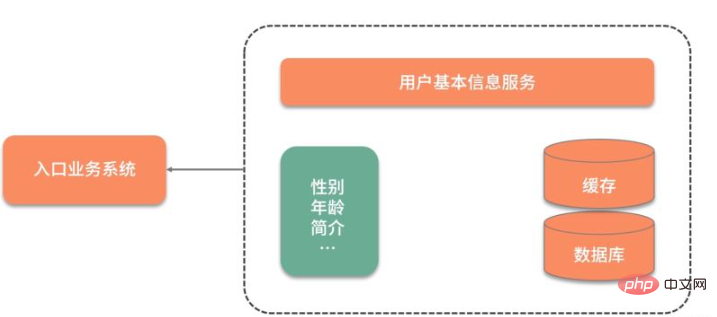
Afin d'accélérer l'interrogation des données, les données ont été initialement mises en cache et placées dans Redis. Les performances des requêtes ont été considérablement améliorées, mais de nombreuses données redondantes devaient encore être interrogées à chaque fois.
La clé Redis d'origine est conçue comme ceci :
type: string
key: user_${userid}
value: jsonIl y a deux problèmes avec cette conception :
Pour interroger la valeur d'un certain champ, vous devez interroger toutes les données json et les analyser vous-même ; d'entre eux La valeur du champ nécessite la mise à jour de l'intégralité de la chaîne json, ce qui coûte cher.
Pour ce type d'informations json à grande granularité, elles peuvent être optimisées de manière dispersée, de sorte que chaque mise à jour et requête ait une cible ciblée.
Ensuite, nous avons conçu les données dans Redis comme suit, en utilisant une structure de hachage au lieu de la structure json :
type: hash
key: user_${userid}
value: {sex:f, id:1223, age:23}De cette façon, nous pouvons utiliser la commande hget ou la commande hmget pour obtenir les données souhaitées et accélérer le flux d'informations .
Bitmap rend les objets plus petits
En plus des opérations ci-dessus, peut-il être davantage optimisé ? Par exemple, les données de genre de l'utilisateur sont fréquemment utilisées dans notre système pour distribuer des cadeaux, recommander des amis du sexe opposé, faire régulièrement appel à des utilisateurs pour effectuer certaines actions de nettoyage, etc. ou pour stocker certaines informations sur le statut de l'utilisateur, par exemple s'il s'agit d'un utilisateur. sont en ligne et s'ils se sont enregistrés, si des informations ont été envoyées récemment, etc., afin de compter les utilisateurs actifs, etc. Ensuite, le fonctionnement des deux valeurs de oui et non peut être compressé à l'aide de la structure Bitmap.
这里还有个高频面试问题,那就是 Java 的 Boolean 占用的是多少位?
在 Java 虚拟机规范里,描述是:将 Boolean 类型映射成的是 1 和 0 两个数字,它占用的空间是和 int 相同的 32 位。即使有的虚拟机实现把 Boolean 映射到了 byte 类型上,它所占用的空间,对于大量的、有规律的 Boolean 值来说,也是太大了。
如代码所示,通过判断 int 中的每一位,它可以保存 32 个 Boolean 值!
int a= 0b0001_0001_1111_1101_1001_0001_1111_1101;
Bitmap 就是使用 Bit 进行记录的数据结构,里面存放的数据不是 0 就是 1。还记得我们在之前 《分布式缓存系统必须要解决的四大问题》中提到的缓存穿透吗?就可以使用 Bitmap 避免,Java 中的相关结构类,就是 java.util.BitSet,BitSet 底层是使用 long 数组实现的,所以它的最小容量是 64。
10 亿的 Boolean 值,只需要 128MB 的内存,下面既是一个占用了 256MB 的用户性别的判断逻辑,可以涵盖长度为 10 亿的 ID。
static BitSet missSet = new BitSet(010_000_000_000);
static BitSet sexSet = new BitSet(010_000_000_000);
String getSex(int userId) {
boolean notMiss = missSet.get(userId);
if (!notMiss) {
//lazy fetch
String lazySex = dao.getSex(userId);
missSet.set(userId, true);
sexSet.set(userId, "female".equals(lazySex));
}
return sexSet.get(userId) ? "female" : "male";
}这些数据,放在堆内内存中,还是过大了。幸运的是,Redis 也支持 Bitmap 结构,如果内存有压力,我们可以把这个结构放到 Redis 中,判断逻辑也是类似的。
再插一道面试算法题:给出一个 1GB 内存的机器,提供 60亿 int 数据,如何快速判断有哪些数据是重复的?
大家可以类比思考一下。Bitmap 是一个比较底层的结构,在它之上还有一个叫作布隆过滤器的结构(Bloom Filter),布隆过滤器可以判断一个值不存在,或者可能存在。
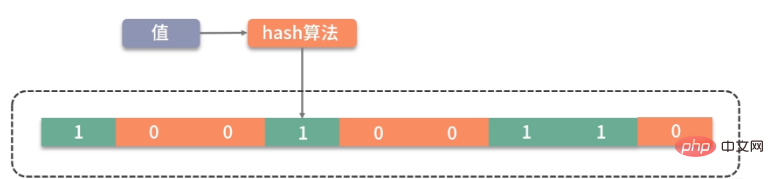
如图,它相比较 Bitmap,它多了一层 hash 算法。既然是 hash 算法,就会有冲突,所以有可能有多个值落在同一个 bit 上。它不像 HashMap一样,使用链表或者红黑树来处理冲突,而是直接将这个hash槽重复使用。从这个特性我们能够看出,布隆过滤器能够明确表示一个值不在集合中,但无法判断一个值确切的在集合中。
Guava 中有一个 BloomFilter 的类,可以方便地实现相关功能。
上面这种优化方式,本质上也是把大对象变成小对象的方式,在软件设计中有很多类似的思路。比如像一篇新发布的文章,频繁用到的是摘要数据,就不需要把整个文章内容都查询出来;用户的 feed 信息,也只需要保证可见信息的速度,而把完整信息存放在速度较慢的大型存储里。
数据的冷热分离
数据除了横向的结构纬度,还有一个纵向的时间维度,对时间维度的优化,最有效的方式就是冷热分离。
所谓热数据,就是靠近用户的,被频繁使用的数据;而冷数据是那些访问频率非常低,年代非常久远的数据。
同一句复杂的 SQL,运行在几千万的数据表上,和运行在几百万的数据表上,前者的效果肯定是很差的。所以,虽然你的系统刚开始上线时速度很快,但随着时间的推移,数据量的增加,就会渐渐变得很慢。
冷热分离是把数据分成两份,如下图,一般都会保持一份全量数据,用来做一些耗时的统计操作。
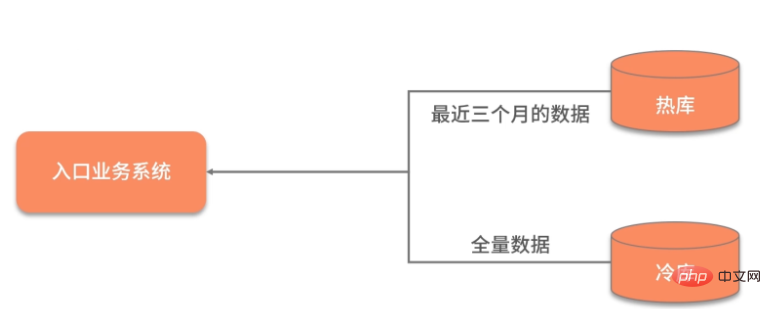
由于冷热分离在工作中经常遇到,所以面试官会频繁问到数据冷热分离的方案。下面简单介绍三种:
数据双写
把对冷热库的插入、更新、删除操作,全部放在一个统一的事务里面。由于热库(比如 MySQL)和冷库(比如 Hbase)的类型不同,这个事务大概率会是分布式事务。在项目初期,这种方式是可行的,但如果是改造一些遗留系统,分布式事务基本上是改不动的,我通常会把这种方案直接废弃掉。
写入 MQ 分发
通过 MQ 的发布订阅功能,在进行数据操作的时候,先不落库,而是发送到 MQ 中。单独启动消费进程,将 MQ 中的数据分别落到冷库、热库中。使用这种方式改造的业务,逻辑非常清晰,结构也比较优雅。像订单这种结构比较清晰、对顺序性要求较低的系统,就可以采用 MQ 分发的方式。但如果你的数据库实体量非常大,用这种方式就要考虑程序的复杂性了。
使用 Binlog 同步
针对 MySQL,就可以采用 Binlog 的方式进行同步,使用 Canal 组件,可持续获取最新的 Binlog 数据,结合 MQ,可以将数据同步到其他的数据源中。
思维发散
对于结果集的操作,我们可以再发散一下思维。可以将一个简单冗余的结果集,改造成复杂高效的数据结构。这个复杂的数据结构可以代理我们的请求,有效地转移耗时操作。
Par exemple, notre index de base de données couramment utilisé est une sorte de réorganisation et d'accélération des données. L'arborescence B+ peut réduire efficacement le nombre d'interactions entre la base de données et le disque. Il indexe les données les plus couramment utilisées via une structure de données similaire à l'arborescence B+ et les stocke dans un espace de stockage limité.
Il existe également une sérialisation couramment utilisée dans RPC. Certains services utilisent le protocole SOAP WebService, qui est un protocole basé sur XML. La transmission de contenus volumineux est lente et inefficace. La plupart des services Web actuels utilisent les données JSON pour l'interaction, et JSON est plus efficace que SOAP.
De plus, tout le monde aurait dû entendre parler du protobuf de Google Comme il s'agit d'un protocole binaire et qu'il compresse les données, ses performances sont très supérieures. Une fois que protobuf compresse les données, la taille n'est que de 1/10 de json et 1/20 de xml, mais les performances sont améliorées de 5 à 100 fois.
La conception de protobuf mérite d'être apprise. Il traite les données de manière très compacte à travers les trois sections tag|leng|value, et la vitesse d'analyse et de transmission est très rapide.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Guide du générateur de nombres aléatoires en Java. Nous discutons ici des fonctions en Java avec des exemples et de deux générateurs différents avec d'autres exemples.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
