
 Périphériques technologiques
IA
Le dilemme de l'open source pour les grands modèles d'IA : monopole, murs et chagrin de la puissance de calcul
Périphériques technologiques
IA
Le dilemme de l'open source pour les grands modèles d'IA : monopole, murs et chagrin de la puissance de calcul
Le dilemme de l'open source pour les grands modèles d'IA : monopole, murs et chagrin de la puissance de calcul

Cet article est réimprimé avec l'autorisation d'AI New Media Qubit (ID de compte public : QbitAI). Veuillez contacter la source pour la réimpression.
En juin 2020, OpenAI a publié GPT-3. Son échelle de centaines de milliards de paramètres et ses étonnantes capacités de traitement du langage ont provoqué un grand choc dans la communauté nationale de l'IA. Cependant, comme GPT-3 n'est pas ouvert au marché intérieur, lorsqu'un certain nombre de sociétés commerciales fournissant des services de génération de texte naissent à l'étranger, nous ne pouvons que regarder en arrière et soupirer.
En août de cette année, Stability AI, une société open source basée à Londres, a publié Stable Diffusion, un modèle de graphique Vincent, et a rendu les poids et le code du modèle librement open source, ce qui a rapidement déclenché la croissance explosive de Applications de peinture IA dans le monde entier.
On peut dire que l'open source a joué un rôle catalyseur direct dans le boom de l'AIGC au second semestre de cette année.
Et quand les grands modèles deviennent un jeu auquel tout le monde peut participer, l'AIGC n'est pas le seul à en profiter.
01
Grand modèle open source en cours
Il y a quatre ans, un modèle de langage appelé BERT est sorti, qui a changé les règles du jeu des modèles d'IA avec 300 millions de paramètres.
Aujourd'hui, le volume des modèles d'IA a atteint des milliards, mais le « monopole » des grands modèles est également devenu de plus en plus important :
Grandes entreprises, grande puissance de calcul et algorithmes puissants, grandes modèles, ils construisent ensemble un mur difficile à franchir pour les développeurs ordinaires et les petites et moyennes entreprises.
Les barrières techniques, ainsi que les ressources informatiques et l'infrastructure nécessaires pour former et utiliser les grands modèles, entravent notre passage du « raffinement » des grands modèles à « l'utilisation » des grands modèles. L’open source est donc urgent. Permettre à davantage de personnes de participer au jeu des grands modèles grâce à l'open source et transformer les grands modèles d'une technologie d'IA émergente en une infrastructure robuste devient le consensus de nombreux créateurs de grands modèles.
C'est également dans le cadre de ce consensus que la communauté modèle open source chinoise "ModelScope" lancée par Alibaba Damo Academy lors de la conférence Yunqi il n'y a pas si longtemps a attiré une grande attention dans l'industrie de l'IA. apporter des modèles à la communauté ou créer leurs propres systèmes de modèles open source.
La construction écologique open source étrangère à grand modèle est actuellement en avance sur la construction nationale. Stability AI est née en tant qu'entreprise privée mais possède ses propres gènes open source. Elle possède sa propre grande communauté de développeurs et dispose d'un modèle de profit stable tout en étant open source.
BLOOM, sorti en juillet de cette année, compte 176 milliards de paramètres et constitue actuellement le plus grand modèle de langage open source. La BigScience qui le sous-tend correspond parfaitement à l'esprit open source, révélant de la tête aux pieds l'élan de la concurrence avec la technologie. des géants. BigScience est une organisation collaborative ouverte dirigée par Huggingface et n'est pas une entité officiellement établie. La naissance de BLOOM est le résultat d'une formation de plus de 1 000 chercheurs de plus de 70 pays sur des superordinateurs pendant 117 jours.
De plus, ce n'est pas que les géants de la technologie n'aient pas participé à l'open source des grands modèles. En mai de cette année, Meta a ouvert le grand modèle OPT avec 175 milliards de paramètres. En plus de permettre l'utilisation d'OPT à des fins non commerciales, il a également publié son code et 100 pages de journaux enregistrant le processus de formation. que l'open source est très complet.
L'équipe de recherche a souligné sans ambages dans le résumé de l'article de l'OPT : « Compte tenu du coût de calcul, ces modèles sont difficiles à reproduire sans financement important. Pour les quelques modèles disponibles via les API, le modèle complet n'est pas accessible. poids, ce qui les rend difficiles à étudier". Le nom complet du modèle « Open Pre-trained Transformers » montre également l'attitude open source de Meta. Cela peut être considéré comme une insinuation du GPT-3 publié par OpenAI, qui n'est pas « ouvert » (fournissant uniquement des services API payants), et du grand modèle PaLM de 540 milliards de paramètres (non open source) lancé par Google en avril de cette année. .
Parmi les grandes entreprises qui ont toujours eu un fort sentiment de monopole, l’initiative open source de Meta est une bouffée d’air frais. Percy Liang, alors directeur du Fundamental Model Research Center de l'Université de Stanford, a commenté : « Il s'agit d'une étape passionnante vers l'ouverture de nouvelles opportunités de recherche. D'une manière générale, nous pouvons penser qu'une plus grande ouverture permettra aux chercheurs de résoudre des problèmes. Des questions plus profondes "
02
L'imagination des grands modèles ne doit pas s'arrêter à l'AIGC
Les propos de Percy Liang répondent également, d'un point de vue académique, à la question de savoir pourquoi les grands modèles doivent être open source.
La naissance de réalisations originales nécessite que l'open source fournisse le terroir.
Une équipe R&D forme un grand modèle si elle s'arrête à publier un article lors d'une conférence de haut niveau, alors les autres chercheurs n'obtiendront que les différents numéros de « démonstration musculaire » dans l'article sans le voir plus de détails. La technologie de formation modèle ne peut être reproduite qu’en prenant du temps, mais elle peut ne pas réussir. La reproductibilité est une garantie de la fiabilité et de la crédibilité des résultats de la recherche scientifique. Grâce à des modèles, des codes et des ensembles de données ouverts, les chercheurs scientifiques peuvent suivre plus rapidement les recherches les plus avancées et s'appuyer sur les épaules des géants pour les toucher. une star. Les fruits provenant de lieux plus élevés peuvent permettre d'économiser beaucoup de temps et d'argent et d'accélérer l'innovation technologique.
Le manque d'originalité dans le travail sur les grands modèles en Chine se reflète principalement dans la recherche aveugle de la taille du modèle, mais il y a peu d'innovation dans l'architecture sous-jacente C'est un phénomène courant parmi les experts de l'industrie engagés. dans le consensus de recherche sur les grands modèles.
Le professeur agrégé Liu Zhiyuan du Département d'informatique de l'Université Tsinghua a souligné à AI Technology Review : Il existe des travaux relativement innovants sur l'architecture des grands modèles en Chine, mais ils sont essentiellement basés sur Transformer. Il manque encore des outils comme Transformer en Chine. Cette architecture fondamentale, ainsi que des modèles comme BERT et GPT-3, peuvent provoquer des changements majeurs dans le domaine.
Le Dr Zhang Jiaxing, scientifique en chef de l'Institut de recherche IDEA (Institut de recherche sur l'économie numérique de la région de la Grande Baie de Guangdong-Hong Kong-Macao), a également déclaré à AI Technology Review que de dizaines de milliards, de centaines de milliards à des milliards, nous avons fait des percées dans divers systèmes et ingénierie. Après avoir relevé le défi, nous devrions réfléchir à une nouvelle structure de modèle au lieu de simplement agrandir le modèle.
D'un autre côté, pour que les grands modèles réalisent des progrès technologiques, un ensemble de normes d'évaluation des modèles est nécessaire, et la génération de normes nécessite ouverture et transparence. Certaines recherches récentes tentent de proposer divers indicateurs d'évaluation pour de nombreux grands modèles, mais certains excellents modèles sont exclus en raison de leur inaccessibilité. Par exemple, le grand modèle PaLM de Google formé sous son architecture Pathways possède des capacités de compréhension du langage superbes. une blague, et le grand modèle de langage Chinchilla de DeepMind n'est pas open source.
Mais que ce soit en raison des excellentes capacités du modèle lui-même ou du statut de ces grands constructeurs, ils ne devraient pas être absents d'un terrain de jeu aussi équitable.
Un fait regrettable est qu'une étude récente de Percy Liang et de ses collègues a montré que par rapport aux modèles non open source, il existe certaines lacunes dans les performances des modèles open source actuels sur de nombreux scénarios de base. Les grands modèles open source tels que OPT-175B, BLOOM-176B et GLM-130B de l'Université Tsinghua ont presque complètement perdu au profit de grands modèles non open source dans diverses tâches, notamment InstructGPT d'OpenAI, TNLG-530B de Microsoft/NVIDIA, etc. ci-dessous).
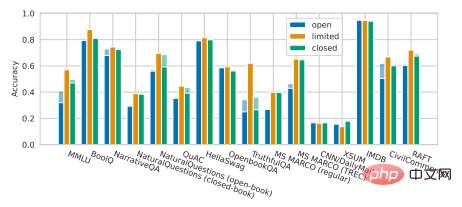
Illustration : Percy Liang et al. Ce n'est qu'avec les progrès globaux dans le domaine de la modélisation que nous pourrons passer plus rapidement au niveau suivant.
En termes d'implémentation industrielle de grands modèles, l'open source est la seule voie à suivre.
Si l'on prend la sortie de GPT-3 comme point de départ, après plus de deux ans de poursuite, les grands modèles sont devenus plus matures en termes de technologie de recherche et développement. , à l'échelle mondiale, le développement de grands modèles. La mise en œuvre en est encore à ses débuts. Bien que les grands modèles développés par les principaux fabricants nationaux disposent de scénarios de mise en œuvre commerciale interne, ils ne disposent pas encore de modèles de commercialisation matures dans leur ensemble.
Lorsque la mise en œuvre de modèles à grande échelle prend de l'ampleur, faire du bon travail en open source peut jeter les bases d'une écologie de mise en œuvre à grande échelle dans le futur.
La nature des grands modèles détermine la nécessité de l'open source pour la mise en œuvre. Zhou Jingren, directeur adjoint de l'Alibaba Damo Academy, a déclaré à AI Technology Review : « Les grands modèles sont des abstractions et des raffinements des systèmes de connaissances humaines, de sorte que les scénarios auxquels ils peuvent être appliqués et la valeur qu'ils génèrent sont énormes et uniquement via l'open source. » les grands modèles peuvent être Le potentiel d'application peut être maximisé par de nombreux développeurs créatifs.
C'est quelque chose que le modèle API qui ferme les détails techniques internes du grand modèle ne peut pas faire. Tout d'abord, ce modèle convient aux utilisateurs de modèles ayant de faibles capacités de développement. Pour eux, le succès ou l'échec de la mise en œuvre d'un grand modèle équivaut à être entièrement entre les mains de l'institution de R&D.
Prenez comme exemple OpenAI, le plus grand gagnant qui fournit des services payants d'API à grand modèle. Selon les statistiques d'OpenAI, il existe actuellement plus de 300 applications utilisant la technologie GPT-3 dans le monde, mais ce fait est fondé. sur OpenAI La force de recherche et développement est suffisamment forte, et GPT-3 est également assez puissant. Si le modèle lui-même fonctionne mal, ces développeurs sont alors impuissants.
Plus important encore, les capacités que les grands modèles peuvent fournir via des API ouvertes sont limitées, ce qui rend difficile la gestion des exigences d'applications complexes et diverses. À l'heure actuelle, il n'existe que quelques applications créatives sur le marché, mais elles sont globalement encore au stade de "jouet" et sont loin d'avoir atteint le stade d'une industrialisation à grande échelle.
"La valeur générée n'est pas si grande et le coût ne peut pas être récupéré, donc les scénarios d'application basés sur l'API GPT-3 sont très limités. De nombreuses personnes dans l'industrie ne reconnaissent pas cette approche." » dit Jiaxing. En effet, des sociétés étrangères telles que copy.ai et Jasper choisissent de se lancer dans le secteur de l'écriture assistée par l'IA. Le marché des utilisateurs est relativement plus vaste, de sorte qu'elles peuvent générer une valeur commerciale relativement importante, alors que davantage d'applications ne sont qu'à petite échelle.
En revanche, L'Open source consiste à "apprendre aux gens à pêcher".
Dans le modèle open source, les entreprises s'appuient sur le code open source pour organiser des formations et des développements secondaires qui répondent à leurs propres besoins commerciaux sur la base du cadre de base existant. Cela peut tirer pleinement parti des avantages de polyvalence des grandes. modèles et libérer des capacités de grande envergure. Une productivité au-delà des niveaux actuels conduira à terme à une véritable mise en œuvre de la technologie des grands modèles dans l'industrie.
En tant que piste la plus clairement visible pour la commercialisation des grands modèles à l'heure actuelle, le décollage de l'AIGC a confirmé le succès du modèle open source des grands modèles. Cependant, dans d'autres scénarios plus applicatifs, l'open. source de grands modèles L'ouverture est encore minoritaire, tant en Suisse qu'à l'étranger. Lan Zhenzhong, directeur du Deep Learning Laboratory de l'Université de West Lake, a déclaré un jour à AI Technology Review que bien qu'il existe de nombreux résultats sur de grands modèles, il existe très peu de sources ouvertes et un accès limité aux chercheurs ordinaires, ce qui est très regrettable.
Contribution, participation et collaboration. L'Open source avec ces mots-clés comme noyau peut rassembler un grand nombre de développeurs enthousiastes pour créer conjointement un grand projet de modèle potentiellement transformateur, permettant aux grands modèles de passer plus rapidement d'expériences en expériences. .espace pour l'industrie.
03
Poids insupportable : la puissance de calcul
L'importance de l'open source pour les grands modèles fait consensus, mais il reste encore un énorme obstacle sur le chemin de l'open source : la puissance de calcul.
C'est aussi le plus grand défi auquel est confrontée la mise en œuvre actuelle des grands modèles. Même si Meta dispose d'OPT open source, jusqu'à présent, il ne semble pas avoir eu un grand impact sur le marché des applications. En fin de compte, le coût de la puissance de calcul reste insupportable pour les petits développeurs, sans parler du réglage fin des grands modèles et du développement secondaire. , le simple raisonnement est très difficile.
Pour cette raison, sous la vague de réflexion sur l'appariement des paramètres, de nombreuses institutions de R&D se sont tournées vers l'idée decréer des modèles légers, contrôlant les paramètres du modèle entre des centaines de millions et des milliards. Le modèle « Mencius » lancé par Lanzhou Technology et la série de modèles open source « Fengshen Bang » fournis par l'IDEA Research Institute sont tous deux des représentants nationaux de cette voie. Ils ont divisé les différentes capacités de très grands modèles en modèles dotés de paramètres relativement plus petits et ont prouvé leur capacité à surpasser des centaines de milliards de modèles dans certaines tâches uniques.
Mais il ne fait aucun doute que la route vers les grands modèles ne s'arrêtera pas là. De nombreux experts du secteur ont déclaré à AI Technology Review qu'il y avait encore place à l'amélioration des paramètres des grands modèles et que quelqu'un devait continuer à explorer. plus. Modèle à grande échelle. Nous devons donc faire face au dilemme des grands modèles open source. Alors, quelles sont les solutions ?
Considérons-le d’abord du point de vue de la puissance de calcul elle-même. La construction de clusters informatiques et de centres de puissance de calcul à grande échelle sera certainement une tendance à l'avenir. Après tout, les ressources informatiques ne peuvent pas répondre à la demande. Mais maintenant, la loi de Moore a ralenti, et les arguments dans l'industrie ne manquent pas selon lesquels la loi de Moore touche à sa fin Si vous placez simplement vos espoirs dans l'amélioration de la puissance de calcul, vous ne pourrez pas assouvir votre immédiateté. soif.
"Maintenant, une carte peut exécuter (en termes de raisonnement) un modèle d'un milliard. Selon le taux de croissance actuel de la puissance de calcul, lorsqu'une carte peut exécuter un modèle de cent milliards, c'est-à-dire que la puissance de calcul sera être cent fois plus élevé. Cela peut prendre dix ans pour s'améliorer", a expliqué Zhang Jiaxing.
Le grand mannequin ne peut pas attendre aussi longtemps.
Une autre direction est de faire toute une histoire sur la technologie de formation pour accélérer la vitesse d'inférence des grands modèles, réduire les coûts de puissance de calcul et réduire la consommation d'énergie, afin d'améliorer la convivialité des grands modèles.
Par exemple, l'OPT de Meta (par rapport à GPT-3) ne nécessite que 16 GPU NVIDIA v100 pour former et déployer la base de code complète du modèle, soit un septième de celle de GPT-3. Récemment, l'Université Tsinghua et Zhipu AI ont lancé conjointement le grand modèle bilingue GLM-130B Grâce à des méthodes d'inférence rapides, le modèle a été compressé au point où il peut être utilisé pour une inférence autonome sur un A100 (40G*8) ou. Serveur V100 (32G*8).
Bien sûr, il est logique de travailler dur dans cette direction. La raison évidente pour laquelle les grands fabricants ne sont pas disposés à ouvrir de grands modèles open source est le coût élevé de la formation. Les experts ont précédemment estimé que des dizaines de milliers de GPU Nvidia v100 ont été utilisés pour entraîner GPT-3, pour un coût total pouvant atteindre 27,6 millions de dollars. Si un particulier souhaite former un PaLM, cela coûtera entre 9 et 17 millions de dollars. Si le coût de formation des grands modèles peut être réduit, leur volonté d'ouvrir la source augmentera naturellement.
Mais en dernière analyse, cela ne peut qu'alléger les contraintes sur les ressources informatiques d'un point de vue technique, mais ce n'est pas la solution ultime. Bien que de nombreux modèles à grande échelle comportant des centaines de milliards et des milliards de niveaux aient commencé à promouvoir leurs avantages de « faible consommation d'énergie », le mur de la puissance de calcul est encore trop élevé.
En fin de compte, nous devons encore revenir au grand modèle lui-même pour trouver un point de rupture Une direction très prometteuse est le grand modèle dynamique clairsemé.
Les grands modèles clairsemés se caractérisent par une très grande capacité, mais seules certaines pièces pour une tâche, un échantillon ou une étiquette donnée sont activées. En d’autres termes, cette structure dynamique clairsemée peut permettre à de grands modèles de monter de quelques niveaux en termes de quantité de paramètres sans avoir à payer d’énormes coûts de calcul, faisant d’une pierre deux coups. C'est un énorme avantage par rapport aux grands modèles denses comme GPT-3, qui nécessitent d'activer l'ensemble du réseau neuronal pour accomplir même les tâches les plus simples, ce qui représente un énorme gaspillage de ressources.
Google est le pionnier des structures dynamiques clairsemées. Ils ont proposé pour la première fois MoE (Sparsely-Gated Mixture-of-Experts Layer, couche de mélange expert clairsemée) en 2017, et ont lancé l'année dernière le grand modèle de transformateurs de commutation de 1,6 billion de paramètres. intègre l'architecture de style MoE et l'efficacité de la formation est augmentée de 7 fois par rapport à leur précédent modèle dense T5-Base Transformer.
L'architecture unifiée Pathways sur laquelle est basé le PaLM de cette année est un modèle de structure dynamique clairsemée : le modèle peut apprendre dynamiquement quelles tâches pour lesquelles des parties spécifiques du réseau sont bonnes, et nous appelons les petits chemins à travers le réseau comme nécessaire peut être utilisé sans activer l’ensemble du réseau neuronal pour accomplir une tâche.

Légende : Architecture des voies
Cela est essentiellement similaire au fonctionnement du cerveau humain. Il y a des dizaines de milliards de neurones dans le cerveau humain, mais seuls certains spécifiques sont activés pour fonctionner. tâches spécifiques. Neurones fonctionnels, sinon la consommation d'énergie énorme serait insupportable.
Grande, polyvalente et efficace, cette voie grand modèle est sans aucun doute très attractive.
"Avec le support de la dynamique clairsemée à l'avenir, le coût de calcul ne sera pas si élevé, mais les paramètres du modèle deviendront certainement de plus en plus grands. La structure dynamique clairsemée pourrait ouvrir une nouvelle monde pour les grands modèles. Ce n’est pas un problème d’atteindre 10 000 milliards ou 100 milliards. » Zhang Jiaxing estime qu’une structure dynamique clairsemée sera le moyen ultime de résoudre la contradiction entre la grande taille des modèles et le coût de la puissance de calcul. Mais il a également ajouté que lorsque ce type de structure de modèle n'est pas encore populaire, cela n'a pas beaucoup de sens de continuer aveuglément à agrandir le modèle.
À l'heure actuelle, il existe relativement peu de tentatives nationales dans ce sens, et elles ne sont pas aussi approfondies que Google. L'exploration et l'innovation dans les grandes structures de modèles et l'open source se favorisent mutuellement, et nous avons besoin de plus d'open source pour stimuler les changements dans la technologie des grands modèles.
Ce qui entrave l'open source des grands modèles, ce n'est pas seulement la faible disponibilité causée par le coût en puissance de calcul des grands modèles, mais aussi les problèmes de sécurité.
Concernant le risque d'abus des grands modèles, en particulier ceux générés après l'open source, il semble y avoir plus d'inquiétudes de l'étranger et beaucoup de controverses. Cela est devenu la base pour laquelle de nombreuses institutions choisissent de ne pas ouvrir la source. grands modèles, mais c'est peut-être aussi pour eux un prétexte pour refuser la générosité.
OpenAI a suscité de nombreuses critiques pour cela. Lorsqu'ils ont publié GPT-2 en 2019, ils ont affirmé que la capacité de génération de texte du modèle était trop puissante et pourrait causer un préjudice éthique, le rendant impropre à l'open source. Lorsque GPT-3 a été publié un an plus tard, il ne proposait qu'un essai d'API. La version open source actuelle de GPT-3 est en fait reproduite par la communauté open source elle-même.
En fait, restreindre l'accès aux grands modèles sera préjudiciable aux grands modèles en améliorant leur robustesse et en réduisant les biais et la toxicité. Lorsque Joelle Pineau, responsable de Meta AI, a parlé de la décision d'ouvrir l'OPT source, elle a sincèrement déclaré que sa propre équipe ne peut pas résoudre à elle seule tous les problèmes, tels que les préjugés éthiques et les propos malveillants qui peuvent survenir lors du processus de génération de texte. Ils pensent que si suffisamment de travail est fait, les grands modèles peuvent être rendus accessibles au public de manière responsable.
Maintenir un accès ouvert et une transparence suffisante tout en se prémunissant contre les risques d'abus n'est pas une tâche facile. En tant que personne qui a ouvert la « Boîte de Pandore », Stability AI jouit d'une bonne réputation grâce à l'open source proactif, mais elle a également récemment rencontré les réactions négatives provoquées par l'open source, provoquant une controverse sur des aspects tels que la propriété des droits d'auteur.
L'ancienne proposition dialectique de « liberté et sécurité » derrière l'open source existe depuis longtemps. Il n'y a peut-être pas de réponse absolument correcte, mais alors que le grand modèle commence à être mis en œuvre, un fait clair est que. : Big Nous n'avons pas fait assez pour rendre les modèles open source.
Plus de deux ans se sont écoulés et nous avons déjà notre propre modèle à grande échelle de plusieurs milliards de dollars. Dans le prochain processus de transformation des modèles à grande échelle de « lire des milliers de livres » à « parcourir des milliers de kilomètres », ouvert. la source est un choix inévitable.
Récemment, GPT-4 est sur le point de sortir, et tout le monde attend beaucoup de son bond en avant en termes de capacités, mais nous ne savons pas quelle productivité il libérera pour combien de personnes dans le futur ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
