

La fonction drop() peut s'avérer utile lors de l'ingénierie des fonctionnalités et de la division d'ensembles de données. Il peut facilement éliminer les données, les colonnes d'opérations, les lignes d'opérations, etc. La syntaxe détaillée de
drop() est la suivante :
La suppression des lignes est un index, la suppression des colonnes est des colonnes :
DataFrame.drop(labels=None, axis=0, index=None, columns=None, inplace=False)
Paramètres :
labels : Les étiquettes des lignes ou des colonnes à supprimer, qui peuvent être un seul étiquette ou une liste d'étiquettes.
axis : L'axe de la ligne ou de la colonne à supprimer, 0 signifie ligne, 1 signifie colonne.
index : L'index de la ligne à supprimer, qui peut être un index unique ou une liste d'index.
columns : Le nom de la colonne à supprimer, qui peut être un nom de colonne unique ou une liste de noms de colonnes.
inplace : indique s'il faut opérer sur le DataFrame d'origine. La valeur par défaut est False, ce qui signifie que l'opération ne sera pas effectuée sur le DataFrame d'origine.
Scénario d'utilisation 1 : supprimer les fonctionnalités inutiles.
Par exemple : si certaines fonctionnalités ont peu d'impact sur les résultats, vous pouvez supprimer les variables indépendantes qui ne sont pas liées à la variable dépendante ; afin d'éviter la multicolinéarité, vous devez supprimer les variables indépendantes qui ont une forte corrélation.
df = data.drop(data[['RowNumber','CustomerId','Surname']],axis=1) df
Explication du code :
data est un ensemble de données, les deux crochets représentent le format DataFrame, qui filtre 3 champs à supprimer
axis=1 représente la colonne d'opération ;
Scénario d'utilisation 2 : Supprimer la variable dépendante
# 自变量、因变量 x_data = df.drop(['Exited'],axis=1) y_data = df['Exited'] x_data
Explication du code : Remplissez le champ à supprimer dans la fonction 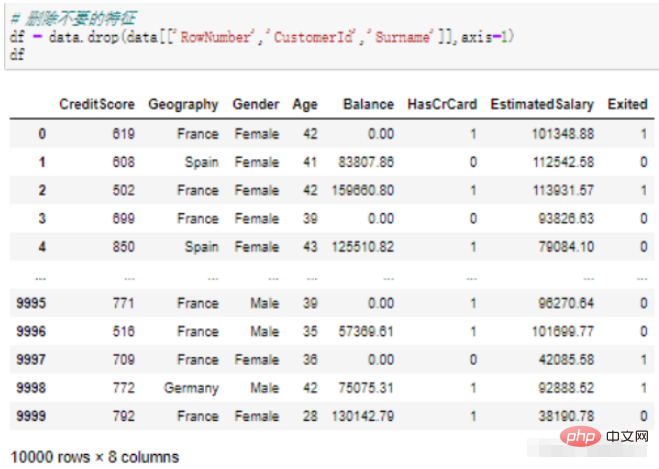
Supprimer les lignes
Scénario d'utilisation 3 : Lors de la division de l'ensemble de données, une formation L'ensemble est généré et l'ensemble d'apprentissage est divisé. Les échantillons de l'ensemble sont éliminés et le reste constitue l'ensemble de test.
#划分训练集 train_data = data.sample(frac = 0.8, random_state = 0) #测试集 test_data = data.drop(train_data.index)
Explication du code : 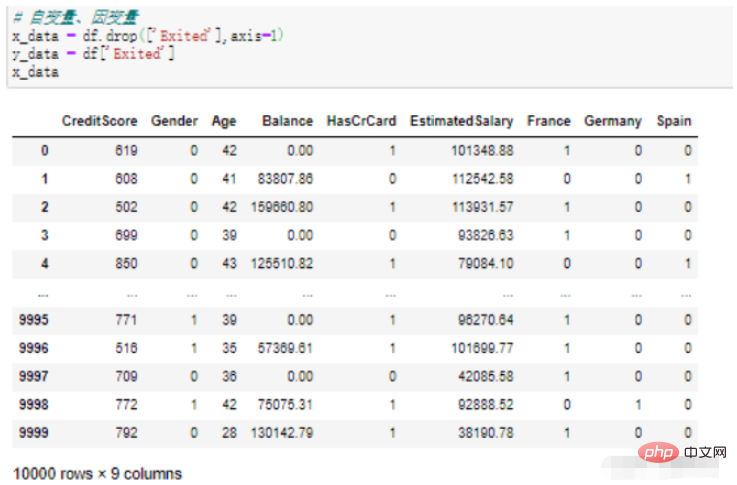
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



