


Que ce soit dans les romans ou les films, l'intelligence artificielle est un sujet fascinant depuis des décennies. Alors que les humains synthétiques imaginés par Philip K. Dick n’existent encore que dans la science-fiction, l’intelligence artificielle est réelle et joue un rôle croissant dans de nombreux aspects de nos vies.
Bien qu'il existe des arguments pour et contre les robots dotés d'un cerveau doté d'une intelligence artificielle, une forme d'intelligence artificielle plus courante et tout aussi puissante commence à jouer un rôle dans la cybersécurité. L’objectif est de faire de l’IA un multiplicateur de force pour les professionnels de la sécurité qui travaillent dur.
Comme le montre le DevoSOC Performance Report™, les analystes du Security Operations Center (SOC) sont souvent submergés par le nombre d'alertes qui continuent d'apparaître sur leurs écrans chaque jour. La « fatigue de la vigilance » est devenue une cause d’épuisement professionnel des analystes dans l’ensemble du secteur.
Idéalement, l'IA peut aider les analystes SOC à suivre (et à garder une longueur d'avance) sur les acteurs malveillants intelligents et impitoyables qui exploitent efficacement l'IA pour des opérations criminelles ou d'espionnage. Mais heureusement, cela ne s’est pas encore produit.
Devo a chargé Wakefield Research de mener une enquête auprès de 200 professionnels de la sécurité informatique afin de déterminer leur point de vue sur l'intelligence artificielle. L'enquête couvre la mise en œuvre de l'IA dans une gamme de disciplines de défense, notamment la détection des menaces, la prévision des risques de violation et la réponse/gestion des incidents.
L'intelligence artificielle est considérée comme un multiplicateur de force pour les équipes de cybersécurité qui tentent de rattraper les acteurs malveillants avisés, les pénuries de talents, etc. Cependant, toutes les IA ne sont pas aussi intelligentes, et ce sans même prendre en compte l’inadéquation des besoins et des capacités.
Tous les répondants à l'enquête ont déclaré que leur organisation utilisait l'IA dans un ou plusieurs domaines. Le domaine le plus utilisé est la gestion de l’inventaire des actifs informatiques, suivi de la détection des menaces et de la prévision des risques de violation.
Mais en ce qui concerne l’utilisation de l’IA pour lutter directement contre les acteurs menaçants, ce n’est pas encore vraiment une bataille. Quelque 67 % des personnes interrogées ont déclaré que l’utilisation de l’IA par leur organisation « ne fait qu’effleurer la surface du problème ».
Voici un aperçu de la manière dont les personnes interrogées perçoivent le recours de leur organisation à l'intelligence artificielle dans les programmes de cybersécurité.

Plus de la moitié des personnes interrogées estiment que leur organisation – du moins pour l'instant – dépend trop de l'intelligence artificielle. Moins d’un tiers des personnes interrogées estiment que le recours à l’IA est approprié, tandis qu’une minorité estime que leurs organisations n’en font pas assez dans ce domaine.
Quand on leur demande leur point de vue sur les défis posés par l'utilisation de l'IA dans leurs organisations, les personnes interrogées ont répondu la vérité. Seulement 11 % des personnes interrogées ont déclaré n’avoir aucun problème à utiliser l’IA pour la cybersécurité. La grande majorité des personnes interrogées avaient un point de vue très différent.
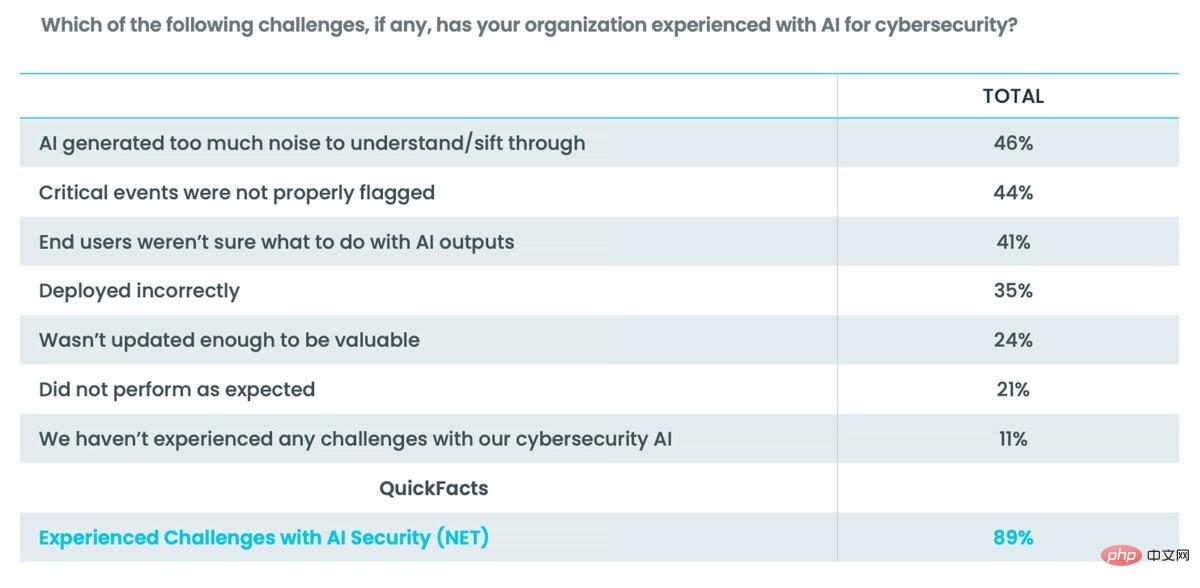
Lorsqu'on leur demande où se situent les défis liés à l'IA au sein de la pile de sécurité de leur organisation, les fonctions principales de cybersécurité fonctionnent mal. 53 % des personnes interrogées ont déclaré que la gestion de l'inventaire des actifs informatiques est le principal problème de l'IA, mais les réponses étaient également insatisfaisantes dans trois catégories de cybersécurité :
Fait intéressant, très peu de personnes interrogées (13 %) ont mentionné la réponse aux incidents comme un défi apporté par l'intelligence artificielle.
Il est clair que même si l'IA est déjà utilisée en cybersécurité, les résultats sont mitigés. La plus grande idée fausse à propos de l’IA est que toutes les IA ne sont pas aussi « intelligentes » que son nom l’indique, et cela sans même prendre en compte l’inadéquation entre les besoins et les capacités de l’organisation.
Le secteur de la cybersécurité se concentre depuis longtemps sur la recherche de solutions « miracles ». L'intelligence artificielle est la dernière en date. Les organisations doivent être réfléchies et axées sur les résultats lors de l’évaluation et du déploiement de solutions d’IA. Les organisations doivent s’assurer de travailler avec des experts expérimentés en technologie de l’IA, sinon elles échoueront dans un domaine critique avec peu de marge d’erreur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Quelle est la devise STAKE ?
Quelle est la devise STAKE ?
 Comment implémenter la fonction carrousel CSS
Comment implémenter la fonction carrousel CSS
 Convertir le texte en valeur numérique
Convertir le texte en valeur numérique
 pagination mysql
pagination mysql
 Pourquoi ne puis-je pas voir les visiteurs sur mon TikTok
Pourquoi ne puis-je pas voir les visiteurs sur mon TikTok
 iexplore.exe
iexplore.exe








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



