

Qu'est-ce que la lecture fantôme MySQL ?

Dans MySQL, la lecture fantôme signifie que lorsque l'utilisateur lit une certaine plage de lignes de données, une autre transaction insère une nouvelle ligne dans la plage. Lorsque l'utilisateur lit les lignes de données dans la plage, il constatera qu'il y a de nouvelles lignes. la gamme. La ligne "Phantom". La lecture dite fantôme signifie que l'ensemble de données interrogé via SELECT n'est pas un ensemble de données réel. L'utilisateur demande via l'instruction SELECT qu'un certain enregistrement n'existe pas, mais qu'il peut exister dans la table réelle.

L'environnement d'exploitation de ce tutoriel : système windows7, version mysql8, ordinateur Dell G3.
Qu'est-ce que la lecture fantôme
Regardons d'abord le niveau d'isolement de la transaction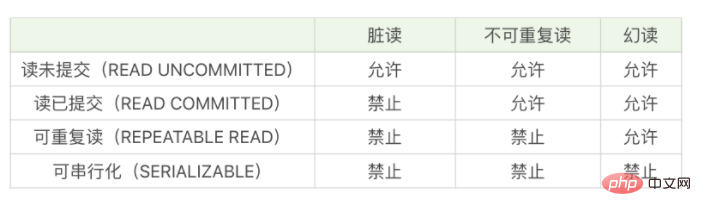
Ensuite, avant de parler de la lecture fantôme, permettez-moi d'abord de parler de ma compréhension de la lecture fantôme :
La soi-disant lecture fantôme, le point clé est " Le mot "illusion" est très rêveur et mystérieux. On ne sait pas si c'est vrai ou non. C'est comme être recouvert d'une couche de brouillard. Vous ne pouvez pas vraiment voir l'autre personne, donner aux gens le sentiment d'illusion. La lecture dite fantôme signifie que l'ensemble de données que vous interrogez via SELECT n'est pas un ensemble de données réel. Un certain enregistrement que vous interrogez via l'instruction SELECT n'existe pas, mais il peut exister dans la table réelle.
C'est ainsi que je comprends la lecture fantôme et la lecture non répétable :
-
La lecture fantômeconsiste à savoir si elle existe ou non : si elle n'existait pas avant, mais maintenant elle existe, c'est une lecture fantôme li>幻读说的是存不存在的问题:原来不存在的,现在存在了,则是幻读 -
不可重复读说的是变没变化的问题:原来是A,现在却变为了B,则为不可重复读
幻读,目前我了解的有两种说法:
说法一:事务 A 根据条件查询得到了 N 条数据,但此时事务 B 删除或者增加了 M 条符合事务 A 查询条件的数据,这样当事务 A 再次进行查询的时候真实的数据集已经发生了变化,但是A却查询不出来这种变化,因此产生了幻读。
这一种说法强调幻读在于某一个范围内的数据行变多或者是变少了,侧重说明的是数据集不一样导致了产生了幻读。
说法二:幻读并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:A事务select 某记录是否存在,结果为不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。产生这样的原因是因为有另一个事务往表中插入了数据。
我个人更赞成第一种说法。
说法二这种情况也属于幻读,说法二归根到底还是数据集发生了改变,查询得到的数据集与真实的数据集不匹配。
对于说法二:当进行INSERT的时候,也需要隐式的读取,比如插入数据时需要读取有没有主键冲突,然后再决定是否能执行插入。如果这时发现已经有这个记录了,就没法插入。所以,SELECT 显示不存在,但是INSERT的时候发现已存在,说明符合条件的数据行发生了变化,也就是幻读的情况,而不可重复读指的是同一条记录的内容被修改了。
举例来说明:说法二说的是如下的情况:
有两个事务A和B,A事务先开启,然后A开始查询数据集中有没有id = 30的数据,查询的结果显示数据中没有id = 30的数据。紧接着又有一个事务B开启了,B事务往表中插入了一条id = 30的数据,然后提交了事务。然后A再开始往表中插入id = 30的数据,由于B事务已经插入了id = 30的数据,自然是不能插入,紧接着A又查询了一次,结果发现表中没有id = 30的数据呀,A事务就很纳闷了,怎么会插入不了数据呢。当A事务提交以后,再次查询,发现表中的确存在id = 30的数据。但是A事务还没提交的时候,却查不出来?
其实,这便是可重复读的作用。
过程如下图所示:

上图中操作的t表的创建语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
MySQL使用的InnoDB引擎默认的隔离级别是可重复读Lecture non répétable concerne le problème du changement : c'était autrefois A, mais maintenant il est devenu B, alors c'est une lecture non répétable< /li>
Lecture fantôme, il y a deux théories que je comprends jusqu'à présent : 🎜🎜🎜🎜 Théorie 1🎜 : La transaction A a obtenu N éléments de données basés sur une requête conditionnelle, mais à ce moment, la transaction B a supprimé ou ajouté M éléments de données qui répondaient aux conditions de requête de la transaction A. De cette façon, lorsque la transaction A interroge à nouveau, l'ensemble de données réel a changé, mais A ne peut pas interroger ce changement, donc des lectures fantômes se produisent. 🎜🎜🎜Cette déclaration souligne que la lecture fantôme se produit lorsqu'il y a plus ou moins de lignes de données dans une certaine plage. Elle souligne que différents ensembles de données conduisent à une lecture fantôme. 🎜🎜🎜🎜Deuxième déclaration🎜 : La lecture fantôme ne signifie pas que les ensembles de résultats obtenus par deux lectures sont différents. L'objectif de la lecture fantôme est que l'état des données représenté par le résultat d'une certaine opération de sélection ne peut pas prendre en charge les opérations commerciales ultérieures. Pour être plus précis : la transaction A sélectionne si un certain enregistrement existe, et le résultat est qu'il n'existe pas. Elle se prépare à insérer cet enregistrement, mais lors de l'exécution de l'insertion, il s'avère que cet enregistrement existe déjà et ne peut pas être inséré. cette fois, une lecture fantôme se produit. La raison en est qu'une autre transaction a inséré des données dans la table. 🎜🎜
🎜Personnellement, je préfère la première affirmation. 🎜🎜Le deuxième argument est également une lecture fantôme. Le deuxième argument est que l'ensemble de données a changé et que l'ensemble de données obtenu par la requête ne correspond pas à l'ensemble de données réel. 🎜🎜 Concernant l'instruction 2 : lors de l'exécution d'INSERT, une lecture implicite est également requise. Par exemple, lors de l'insertion de données, vous devez lire s'il y a un conflit de clé primaire, puis décider si l'insertion peut être effectuée. S'il s'avère que cet enregistrement existe déjà, il ne peut pas être inséré. Par conséquent, SELECT montre qu'il n'existe pas, mais il existe lors de INSERT, ce qui signifie que les lignes de données qui remplissent les conditions ont changé, ce qui est le cas de la lecture fantôme, tandis que la lecture non répétable signifie que le contenu de le même enregistrement a été modifié. 🎜🎜Pour illustrer avec un exemple : la deuxième instruction parle de la situation suivante : 🎜 Il y a deux transactions A et B. La transaction A est ouverte en premier, puis A commence à demander s'il y a des données avec id = 30 dans les données set. Le résultat de la requête montre qu'il n'y a aucune donnée dans les données avec l'identifiant = 30. Immédiatement après, une autre transaction B a été ouverte. La transaction B a inséré une donnée avec l'identifiant = 30 dans la table, puis a soumis la transaction. Ensuite, A commence à insérer les données avec l'identifiant = 30 dans la table. Puisque la transaction B a déjà inséré les données avec l'identifiant = 30, elles ne peuvent pas être insérées naturellement. Ensuite, A interroge à nouveau et constate qu'il n'y a pas de données avec l'identifiant = 30 dans. la table. , la transaction A est très confuse, pourquoi les données ne peuvent-elles pas être insérées ? Une fois la transaction A soumise, interrogez à nouveau et constatez que les données avec l'identifiant = 30 existent dans la table. Mais avant que la transaction A ne soit soumise, elle n'a pas pu être découverte ? 🎜 En fait, c'est le rôle de la
lecture répétable. 🎜🎜Le processus est le suivant : 🎜🎜🎜🎜L'instruction de création de la table t opérée dans la figure ci-dessus est la suivante : 🎜SELECT * FROM player WHERE ...
Repeatable Read, qui signifie que dans la même transaction, si vous exécutez deux fois la même requête, les résultats devraient être les mêmes. Par conséquent, bien que la transaction B ait ajouté des données à la table avant la fin de la transaction A, afin de maintenir une lecture reproductible, les données nouvellement ajoutées ne peuvent pas être interrogées, quelle que soit la manière dont elles sont interrogées dans la transaction A. Mais pour le vrai tableau, les données du tableau ont effectivement augmenté. 🎜
A查询不到这个数据,不代表这个数据不存在。查询得到了某条数据,不代表它真的存在。这样是是而非的查询,就像是幻觉一样,似真似假,故为幻读。
产生幻读的原因归根到底是由于查询得到的结果与真实的结果不匹配。
幻读 VS 不可重复读
幻读重点在于数据是否存在。原本不存在的数据却真实的存在了,这便是幻读。在同一个事务中,第一次读取到结果集和第二次读取到的结果集不同。(对比上面的例子,当B事务INSERT以后,A事务中再进行插入,此次插入相当于一次隐式查询)。引起幻读的原因在于另一个事务进行了INSERT操作。不可重复读重点在于数据是否被改变了。在一个事务中对同一条记录进行查询,第一次读取到的数据和第二次读取到的数据不一致,这便是可重复读。引起不可重复读的原因在于另一个事务进行了UPDATE或者是DELETE操作。
简单来说:幻读是说数据的条数发生了变化,原本不存在的数据存在了。不可重复读是说数据的内容发生了变化,原本存在的数据的内容发生了改变。
可重复读隔离下为什么会产生幻读?
在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在 当前读 下才会出现。
什么是快照读,什么是当前读?
快照读读取的是快照数据。不加锁的简单的 SELECT都属于快照读,比如这样:
SELECT * FROM player WHERE ...
当前读就是读取最新数据,而不是历史版本的数据。加锁的 SELECT,或者对数据进行增删改都会进行当前读。这有点像是 Java 中的 volatile 关键字,被 volatile 修饰的变量,进行修改时,JVM 会强制将其写回内存,而不是放在 CPU 缓存中,进行读取时,JVM 会强制从内存读取,而不是放在 CPU 缓存中。这样就能保证其可见行,保证每次读取到的都是最新的值。如果没有用 volatile 关键字修饰,变量的值可能会被放在 CPU 缓存中,这就导致读取到的值可能是某次修改的值,不能保证是最新的值。
说多了,我们继续来看,如下的操作都会进行 当前读。
SELECT * FROM player LOCK IN SHARE MODE; SELECT * FROM player FOR UPDATE; INSERT INTO player values ... DELETE FROM player WHERE ... UPDATE player SET ...
说白了,快照读就是普通的读操作,而当前读包括了 加锁的读取 和 DML(DML只是对表内部的数据操作,不涉及表的定义,结构的修改。主要包括insert、update、deletet) 操作。
比如在可重复读的隔离条件下,我开启了两个事务,在另一个事务中进行了插入操作,当前事务如果使用当前读 是可以读到最新的数据的。

MySQL中如何实现可重复读
当隔离级别为可重复读的时候,事务只在第一次 SELECT 的时候会获取一次 Read View,而后面所有的 SELECT 都会复用这个 Read View。也就是说:对于A事务而言,不管其他事务怎么修改数据,对于A事务而言,它能看到的数据永远都是第一次SELECT时看到的数据。这显然不合理,如果其它事务插入了数据,A事务却只能看到过去的数据,读取不了当前的数据。
既然都说到 Read View 了,就不得不说 MVCC (多版本并发控制) 机制了。MVCC 其实字面意思还比较好理解,为了防止数据产生冲突,我们可以使用时间戳之类的来进行标识,不同的时间戳对应着不同的版本。比如你现在有1000元,你借给了张三 500 元, 之后李四给了你 500 元,虽然你的钱的总额都是 1000元,但是其实已经和最开始的 1000元不一样了,为了判断中途是否有修改,我们就可以采用版本号来区分你的钱的变动。
如下,在数据库的数据表中,id,name,type 这三个字段是我自己建立的,但是除了这些字段,其实还有些隐藏字段是 MySQL 偷偷为我们添加的,我们通常是看不到这样的隐藏字段的。

我们重点关注这两个隐藏的字段:
db_trx_id : L'ID de transaction qui exploite cette ligne de données, qui est le dernier ID de transaction qui a inséré ou mis à jour les données. Chaque fois que nous démarrons une transaction, nous obtiendrons un identifiant de transaction (c'est-à-dire le numéro de version de la transaction) de la base de données. Cet identifiant de transaction augmente automatiquement grâce à la taille de l'ID, nous pouvons juger de la séquence temporelle de la transaction.
db_roll_ptr : pointeur de restauration, pointant vers les informations Undo Log de cet enregistrement. Qu'est-ce que l'annulation du journal ? On peut comprendre que lorsque nous devons modifier un certain enregistrement, MySQL craint que la modification puisse être révoquée à l'avenir et ramenée à l'état précédent, donc avant de modifier, enregistrez les données actuelles dans un fichier, puis modifiez-le. , Annuler le journal Cela peut être compris comme ce fichier d'archive. C'est comme lorsque nous jouons à un jeu. Après avoir atteint un certain niveau, nous sauvegardons d'abord un fichier, puis continuons à défier le niveau suivant, au lieu de revenir au point de sauvegarde précédent. repartir de zéro.
Dans le mécanisme MVCC (Multiple Version Concurrency Control), plusieurs transactions mettant à jour le même enregistrement de ligne généreront plusieurs instantanés historiques, et ces instantanés historiques sont enregistrés dans Undo Log. Comme le montre la figure ci-dessous, le pointeur de restauration enregistré dans la ligne actuelle pointe vers son état précédent, et le pointeur de restauration de son état précédent pointe vers l'état précédent de l'état précédent. De cette façon, nous pouvons théoriquement trouver n'importe quel état de la ligne de données en parcourant le pointeur de restauration.
Diagramme schématique d'Undo Log
Nous ne nous attendions pas à ce que ce que nous avons vu ne soit qu'une seule donnée, mais MySQL a stocké plusieurs versions de ces données en coulisses et a enregistré de nombreux fichiers pour ces données. Voici la question. Lorsque nous démarrons une transaction, nous voulons interroger une certaine donnée dans la transaction, mais chaque donnée correspond à plusieurs versions. À ce stade, quelle version de l'enregistrement de ligne devons-nous lire ?
À ce stade, nous devons utiliser le mécanisme Read View, qui nous aide à résoudre le problème de visibilité des lignes. Read View enregistre une liste de toutes les transactions actives (pas encore validées) lorsque la transaction en cours est ouverte.
Il y a plusieurs attributs importants dans Read VIew :
- trx_ids, l'ensemble des identifiants de transaction actuellement actifs dans le système
- low_limit_id, le plus grand identifiant de transaction parmi les transactions actives
- up_limit_id, actif Le plus petit ID de transaction dans la transaction
- creator_trx_id, l'ID de transaction qui a créé cette vue en lecture
Comme nous l'avons dit précédemment, il y a un champ caché dans chaque ligne d'enregistrementsdb_trx_id, qui représente l'ID de transaction qui exploite cette ligne de données, et l'ID de transaction est auto-augmentant Grâce à la taille de l'ID, nous pouvons juger de la séquence temporelle de la transaction.
Après avoir démarré la transaction, nous allons interroger un certain enregistrement et trouver le db_trx_id < up_limit_id de l'enregistrement. Cela signifie que cet enregistrement doit avoir été soumis avant le début de cette transaction. Pour la transaction en cours, il s'agit de données historiques et nous pouvons donc certainement trouver cet enregistrement via select.
Mais s'il est trouvé, le db_trx_id > up_limit_id de l'enregistrement à interroger. Qu'est-ce que cela signifie ? Cela signifie que lorsque j'ai ouvert la transaction, cet enregistrement ne devait pas encore exister. Il a été créé plus tard et ne devrait pas être vu par la transaction en cours. À ce moment, nous pouvons utiliser le pointeur rollback + Undo Log. Retrouvez la version historique du dossier et remettez-la à la transaction en cours. Dans cet article Qu'est-ce que la lecture fantôme ? Un exemple donné dans ce chapitre. Lorsque la transaction A est démarrée, il n'y a aucun enregistrement (30, 30, 30) dans la base de données. Une fois la transaction A démarrée, la transaction B insère l'enregistrement (30, 30, 30) dans la base de données. À ce stade, la transaction A ne peut pas interroger cet enregistrement lors de l'utilisation de select sans verrouiller pour effectuer une lecture instantanée de l'enregistrement nouvellement inséré. est conforme à nos attentes. Pour la transaction A, le db_trx_id de cet enregistrement (30, 30, 30) doit être supérieur au up_limit_id lorsque la transaction A est démarrée, cet enregistrement ne doit donc pas être vu par la transaction A.
Si letrx_id de l'enregistrement qui doit être interrogé satisfait à la condition de up_limit_id < trx_id < la transaction creator_trx_id actuelle est créée. , peut être encore active, nous devons donc parcourir la collection trx_ids Si trx_id existe dans la collection trx_ids, cela prouve que cette transaction trx_id est toujours active. et invisible. Si l'enregistrement a un journal d'annulation, nous pouvons parcourir le pointeur de restauration et interroger les données de version historique de l'enregistrement. Si trx_id n'existe pas dans la collection trx_ids, cela prouve que la transaction trx_id a été soumise et l'enregistrement de la ligne est visible.
从图中你能看到回滚指针将数据行的所有快照记录都通过链表的结构串联了起来,每个快照的记录都保存了当时的 db_trx_id,也是那个时间点操作这个数据的事务 ID。这样如果我们想要找历史快照,就可以通过遍历回滚指针的方式进行查找。
最后,再来强调一遍:事务只在第一次 SELECT 的时候会获取一次 Read View
因此,如下图所示,在 可重复读 的隔离条件下,在该事务中不管进行多少次 以WHERE heigh > 2.08为条件 的查询,最终结果得到都是一样的,尽管可能会有其它事务对这个结果集进行了更改。

如何解决幻读
即便是给每行数据都加上行锁,也无法解决幻读,行锁只能阻止修改,无法阻止数据的删除。而且新插入的数据,自然是数据库中不存在的数据,原本不存在的数据自然无法对其加锁,因此仅仅使用行锁是无法阻止别的事务插入数据的。
为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。顾名思义,间隙锁,锁的就是两个值之间的空隙。比如文章开头的表 t,初始化插入了 6 个记录,这就产生了 7 个间隙。
表 t 主键索引上的行锁和间隙锁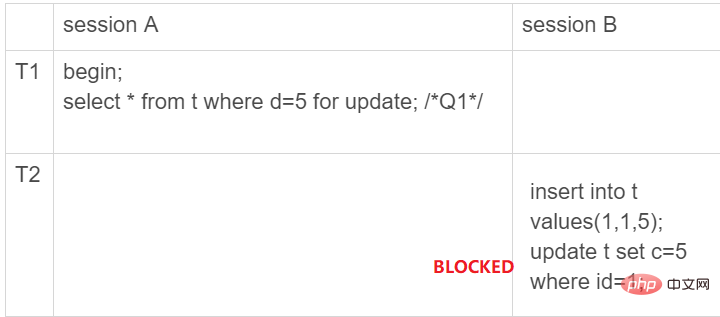
也就是说这时候,在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。现在你知道了,数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。但是间隙锁跟我们之前碰到过的锁都不太一样。
- 间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。也就是说,我们的表 t 初始化以后,如果用
SELECT * FEOM t FOR UPDATE要把整个表所有记录锁起来,就形成了 7 个 next-key lock,分别是 (负无穷,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, 正无穷]。 - 间隙锁是在可重复读隔离级别下才会生效的
怎么加间隙锁呢?使用写锁(又叫排它锁,X锁)时自动生效,也就是说我们执行 SELECT * FEOM t FOR UPDATE时便会自动触发间隙锁。会给主键加上上图所示的锁。
如下图所示,如果在事务A中执行了SELECT * FROM t WHERE d = 5 FOR UPDATE以后,事务B则无法插入数据了,因此就避免了产生幻读。
数据表的创建语句如下
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
需要注意的是,由于创建数据表的时候仅仅只在c字段上创建了索引,因此使用条件WHERE id = 5查找时是会扫描全表的。因此,SELECT * FROM t WHERE d = 5 FOR UPDATE实际上锁住了整个表,如上图所示,产生了七个间隙,这七个间隙都不允许数据的插入。
因此当B想插入一条数据(1, 1, 1)时就会被阻塞住,因为它的主键位于位于(0, 5]这个区间,被禁止插入。
还需要注意的一点是,间隙锁和间隙锁是不会产生冲突的。读锁(又称共享锁,S锁)和写锁会冲突,写锁和写锁也会产生冲突。但是间隙锁和间隙锁是不会产生冲突的
如下:
A事务对id = 5的数据加了读锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁则会成功。读锁和读锁可以兼容,读锁和写锁则不能兼容。
A事务对id = 5的数据加了写锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁同样也会失败。
在加了间隙锁以后,当A事务开启以后,并对(5, 10]这个区间加了间隙锁,那么B事务则无法插入数据了。

但是当A事务对(5, 10]加了间隙锁以后,B事务也可以对这个区间加间隙锁。
Le but du verrou d'espacement est d'empêcher l'insertion de données dans cet intervalle. Par conséquent, une fois la transaction A ajoutée, la transaction B continue d'ajouter des verrous d'espacement. Mais c’est différent pour les verrous en écriture et les verrous en lecture.
Un verrou en écriture ne permet pas aux autres transactions de lire ou d'écrire, tandis qu'un verrou en lecture permet l'écriture, il y a donc un conflit sémantique. Bien entendu, vous ne pouvez pas ajouter ces deux verrous en même temps.
Il en va de même pour les verrous en écriture et les verrous en écriture. Les verrous en écriture ne permettent pas la lecture ou l'écriture. Pensez-y, la transaction A ajoute un verrou en écriture aux données, ce qui signifie qu'elle ne souhaite pas que d'autres transactions opèrent sur les données. Ensuite, si d'autres données peuvent être utilisées pour ces données, l'ajout d'un verrou en écriture équivaut à effectuer une opération sur les données, ce qui viole la signification du verrou en écriture et n'est naturellement pas autorisé.
【Recommandations associées : tutoriel vidéo mysql】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
