
 Java
javaDidacticiel
Analyse des instances de file d'attente de messages Kafka distribuée Java
Java
javaDidacticiel
Analyse des instances de file d'attente de messages Kafka distribuée Java
Analyse des instances de file d'attente de messages Kafka distribuée Java

Introduction
Apache Kafka est un système de messagerie de publication-abonnement distribué. La définition de kafka sur le site officiel de kafka est : un système de messagerie de publication-abonnement distribué. Il a été initialement développé par LinkedIn, qui a contribué à la Fondation Apache en 2010 et est devenu l'un des principaux projets open source. Kafka est un service de journal de validation rapide, évolutif et intrinsèquement distribué, partitionné et réplicable.
Remarque : Kafka ne suit pas la spécification JMS (), il fournit uniquement des méthodes de communication de publication et d'abonnement.
Noms associés au noyau Kafka
Courtier : nœud Kafka, un nœud Kafka est un courtier, plusieurs courtiers peuvent former un cluster Kafka
Sujet : un type de message, le répertoire où le message est stocké est le sujet , tels que les journaux d'affichage de page, les journaux de clics, etc. peuvent exister sous forme de sujets. Le cluster Kafka peut être responsable de la distribution de plusieurs sujets en même temps
massage : l'objet de diffusion le plus basique de Kafka.
Partition : le regroupement physique de sujets. Un sujet peut être divisé en plusieurs partitions, et chaque partition est une file d'attente ordonnée. Le partitionnement est implémenté dans Kafka et un courtier représente une région.
Segment : La partition est physiquement composée de plusieurs segments, chaque segment stocke les informations sur les messages
Producteur : Producteur, produit des messages et les envoie au sujet
Consommateur : Consommateur, s'abonne au sujet et consomme des messages, consommateur consomme comme un fil de discussion
Groupe de consommateurs : groupe de consommateurs, un groupe de consommateurs contient plusieurs consommateurs
Offset : décalage, compris comme la position d'index du message dans la partition de messages
topic et La différence entre les files d'attente :
La file d'attente est une structure de données qui suit le principe du premier entré, premier sorti
Installation du cluster Kafka
Installer l'environnement jdk1.8 sur chaque serveur
Installer l'environnement de cluster Zookeeper
Installer kafka cluster Environment
Exécution du test d'environnement
L'installation de l'environnement jdk et de zookeeper ne sera pas détaillée ici.
Pourquoi kafka dépend-il de zookeeper : Kafka stockera les informations mq sur zookeeper Afin de faciliter l'expansion de l'ensemble du cluster, la notification d'événement de zookeeper est utilisée pour se détecter.
Étapes d'installation du cluster Kafka :
1. Téléchargez le package compressé de Kafka
2 Décompressez le package d'installation
tar -zxvf kafka_2.11-1.0.0.tgz
3. .properties
Contenu de la modification du fichier de configuration :
Adresse de connexion zookeeper :
zookeeper.connect=192.168.1.19:2181zookeeper.connect=192.168.1.19:2181监听的ip,修改为本机的ip
listeners=PLAINTEXT://192.168.1.19:9092kafka的brokerid,每台broker的id都不一样
broker.id=0
4、依次启动kafka
./kafka-server-start.sh -daemon config/server.properties
kafka使用
kafka文件存储
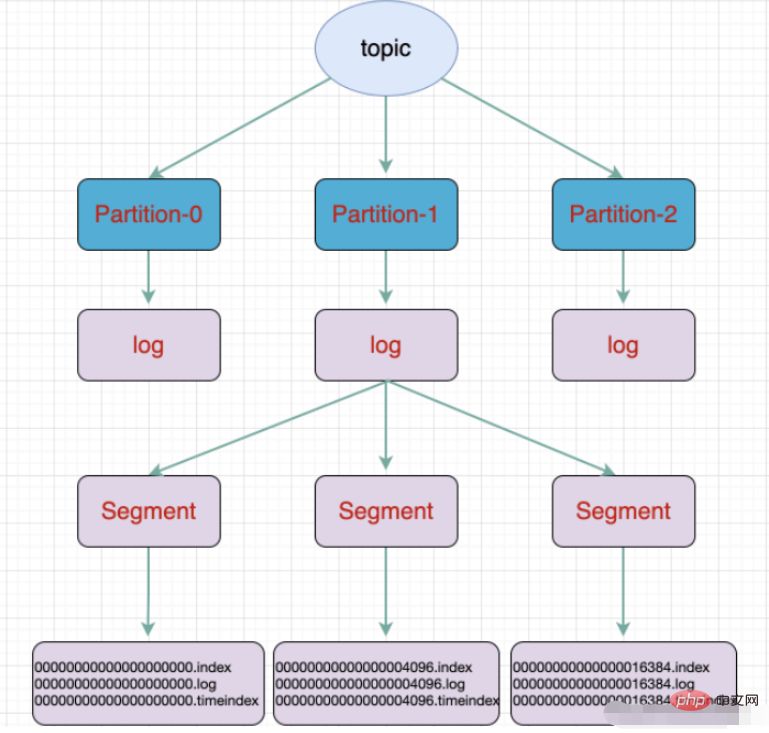
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生成的数据。Producer生成的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。
例如:执行命令新建一个主题,分三个区存放放在三个broker中:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kaico
 L'adresse IP d'écoute est remplacée par l'adresse IP locale
L'adresse IP d'écoute est remplacée par l'adresse IP localeauditeurs =PLAINTEXT://192.168.1.19:9092
broker.id=0- 4 Démarrez kafka dans l'ordre.
-
./kafka-server-start.sh -daemon config/server.propertieskafka utilise - le stockage de fichiers Kafkale sujet est un concept logique et la partition est physique Basé sur le concept ci-dessus, chaque partition correspond à un fichier journal, et le fichier journal stocke les données générées par le Producteur. Les données générées par le producteur seront continuellement ajoutées à la fin du fichier journal. Afin d'éviter que le fichier journal ne soit trop volumineux et ne provoque une inefficacité dans le positionnement des données, Kafka adopte un mécanisme de partitionnement et d'indexation pour diviser chaque partition en plusieurs segments. . Chaque segment comprend : des fichiers ".index", des fichiers ".log" et des fichiers .timeindex. Ces fichiers se trouvent dans un dossier et la règle de dénomination du dossier est la suivante : nom du sujet + numéro de série de la partition.
- Par exemple : exécutez la commande pour créer un nouveau sujet, divisé en trois zones et stocké dans trois courtiers :
./kafka-topics.sh --create --zookeeper localhost:2181 --replication -facteur 1 - -partitions 3 --topic kaico
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies># kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094@RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}@Component
public class TopicKaicoConsumer {
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topics = "kaico") //监听的主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
//输出key对应的value的值
System.out.println(consumer.value());
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1663
1663
 14
1419
52
1313
25
1263
29
1236
24
14
1419
52
1313
25
1263
29
1236
24

 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 PHP: un langage clé pour le développement Web
Apr 13, 2025 am 12:08 AM
PHP: un langage clé pour le développement Web
Apr 13, 2025 am 12:08 AM
PHP est un langage de script largement utilisé du côté du serveur, particulièrement adapté au développement Web. 1.Php peut intégrer HTML, traiter les demandes et réponses HTTP et prend en charge une variété de bases de données. 2.PHP est utilisé pour générer du contenu Web dynamique, des données de formulaire de traitement, des bases de données d'accès, etc., avec un support communautaire solide et des ressources open source. 3. PHP est une langue interprétée, et le processus d'exécution comprend l'analyse lexicale, l'analyse grammaticale, la compilation et l'exécution. 4.PHP peut être combiné avec MySQL pour les applications avancées telles que les systèmes d'enregistrement des utilisateurs. 5. Lors du débogage de PHP, vous pouvez utiliser des fonctions telles que error_reportting () et var_dump (). 6. Optimiser le code PHP pour utiliser les mécanismes de mise en cache, optimiser les requêtes de base de données et utiliser des fonctions intégrées. 7
 PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP et Python ont chacun leurs propres avantages, et le choix doit être basé sur les exigences du projet. 1.Php convient au développement Web, avec une syntaxe simple et une efficacité d'exécution élevée. 2. Python convient à la science des données et à l'apprentissage automatique, avec une syntaxe concise et des bibliothèques riches.
 PHP vs autres langues: une comparaison
Apr 13, 2025 am 12:19 AM
PHP vs autres langues: une comparaison
Apr 13, 2025 am 12:19 AM
PHP convient au développement Web, en particulier dans le développement rapide et le traitement du contenu dynamique, mais n'est pas bon dans les applications de la science des données et de l'entreprise. Par rapport à Python, PHP présente plus d'avantages dans le développement Web, mais n'est pas aussi bon que Python dans le domaine de la science des données; Par rapport à Java, PHP fonctionne moins bien dans les applications au niveau de l'entreprise, mais est plus flexible dans le développement Web; Par rapport à JavaScript, PHP est plus concis dans le développement back-end, mais n'est pas aussi bon que JavaScript dans le développement frontal.
 PHP vs Python: fonctionnalités et fonctionnalités de base
Apr 13, 2025 am 12:16 AM
PHP vs Python: fonctionnalités et fonctionnalités de base
Apr 13, 2025 am 12:16 AM
PHP et Python ont chacun leurs propres avantages et conviennent à différents scénarios. 1.PHP convient au développement Web et fournit des serveurs Web intégrés et des bibliothèques de fonctions riches. 2. Python convient à la science des données et à l'apprentissage automatique, avec une syntaxe concise et une bibliothèque standard puissante. Lors du choix, il doit être décidé en fonction des exigences du projet.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Impact de PHP: développement Web et au-delà
Apr 18, 2025 am 12:10 AM
Impact de PHP: développement Web et au-delà
Apr 18, 2025 am 12:10 AM
PHPhassignificantlyimpactedwebdevelopmentandextendsbeyondit.1)ItpowersmajorplatformslikeWordPressandexcelsindatabaseinteractions.2)PHP'sadaptabilityallowsittoscaleforlargeapplicationsusingframeworkslikeLaravel.3)Beyondweb,PHPisusedincommand-linescrip
 PHP: la fondation de nombreux sites Web
Apr 13, 2025 am 12:07 AM
PHP: la fondation de nombreux sites Web
Apr 13, 2025 am 12:07 AM
Les raisons pour lesquelles PHP est la pile technologique préférée pour de nombreux sites Web incluent sa facilité d'utilisation, son soutien communautaire solide et son utilisation généralisée. 1) Facile à apprendre et à utiliser, adapté aux débutants. 2) Avoir une énorme communauté de développeurs et des ressources riches. 3) Largement utilisé dans WordPress, Drupal et d'autres plateformes. 4) Intégrez étroitement aux serveurs Web pour simplifier le déploiement du développement.
