
 Périphériques technologiques
IA
Recherchez les articles les plus pertinents sur arXiv en un clic Grâce à ChatGPT, cela peut être complété en quelques jours.
Périphériques technologiques
IA
Recherchez les articles les plus pertinents sur arXiv en un clic Grâce à ChatGPT, cela peut être complété en quelques jours.
Recherchez les articles les plus pertinents sur arXiv en un clic Grâce à ChatGPT, cela peut être complété en quelques jours.

Pour les amis qui recherchent des articles tous les jours, ne soyez pas trop heureux s'il existe un outil de recherche utile, et l'efficacité sera grandement améliorée.
Mais le résultat réel est que soit l'outil de recherche n'est pas puissant, soit les mots-clés que vous saisissez ne fonctionnent pas. Quoi qu'il en soit, on ne peut pas dire que le document que vous souhaitez trouver dans votre esprit et les résultats de la recherche n'ont rien à voir. les uns avec les autres. C'est tout simplement une énorme différence.
Le site Web que nous allons présenter ci-dessous peut vous aider à résoudre les problèmes rencontrés dans la recherche papier. Le site Web s'appelle arXiv Xplorer, qui est spécialement utilisé pour la recherche sémantique d'articles sur arXiv. Selon les auteurs du projet, l’algorithme interne du site utilise le dernier modèle d’intégration d’OpenAI pour générer des requêtes de recherche permettant aux utilisateurs de trouver les articles les plus pertinents.

Adresse arXiv Xplorer : https://arxivxplorer.com/
L'auteur du projet a déclaré : Il a été profondément impressionné par la nouvelle API d'intégration d'OpenAI, il a donc voulu jeter un œil à l'intégration Comment il est utilisé dans la pratique. Il a donc passé quelques jours à construire le projet et jusqu'à présent, cela fonctionne très bien. En plus de cela, il a écrit 80 % de l'interface utilisateur dans ChatGPT, utilisé Pinecone pour stocker la base de données vectorielle et utilisé les fonctions GoogleCloud pour intégrer des requêtes et effectuer des recherches.
Si vous souhaitez en savoir plus sur le modèle embarqué, vous pouvez vous rendre sur le site pour le visualiser.
Modèle d'intégration : https://openai.com/blog/new-and-improved-embedding-model/
Avec arXiv Xplorer, vous pouvez trouver le papier dont vous avez besoin, même si votre description est très Le moteur peut vous aider avec des descriptions floues, voire simplement des descriptions sans contenu informatif, telles que des « papiers ML intéressants ». Comme indiqué ci-dessous, les résultats de la requête affichés par le site Web après la saisie de plusieurs mots-clés.
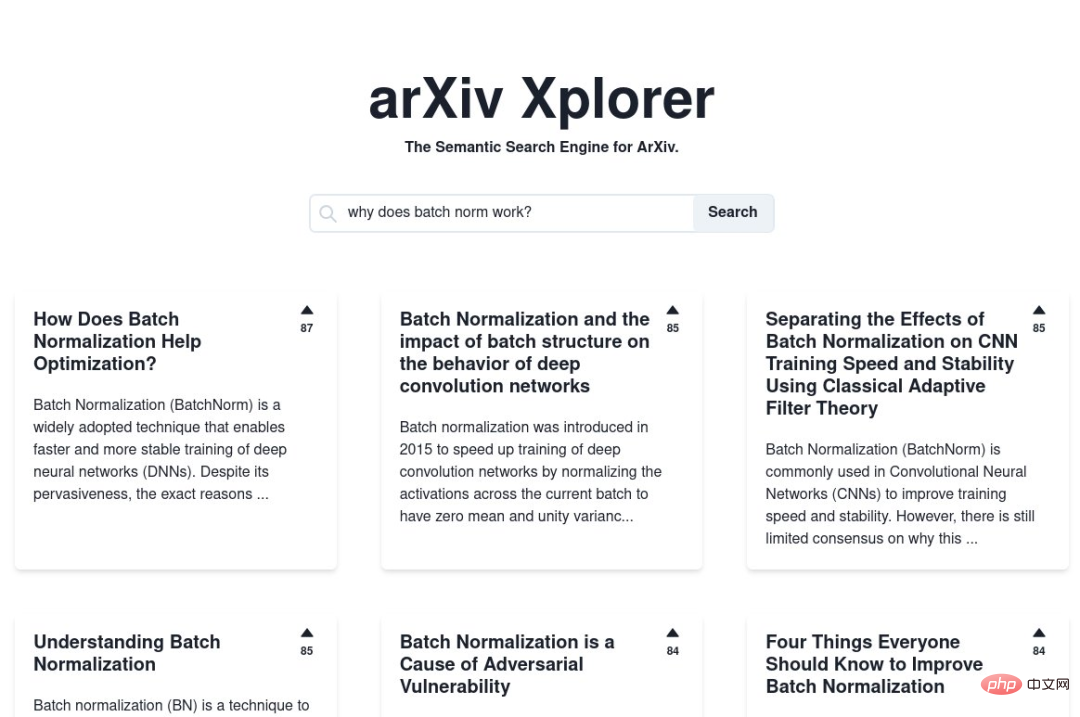
Dans le processus, vous pouvez également découvrir des articles intéressants que vous n'avez jamais vus auparavant par rapport aux outils de recherche traditionnels tels que Google ou la propre recherche d'arXiv. En comparaison, arXiv Xplorer semble être plus efficace que cela. .
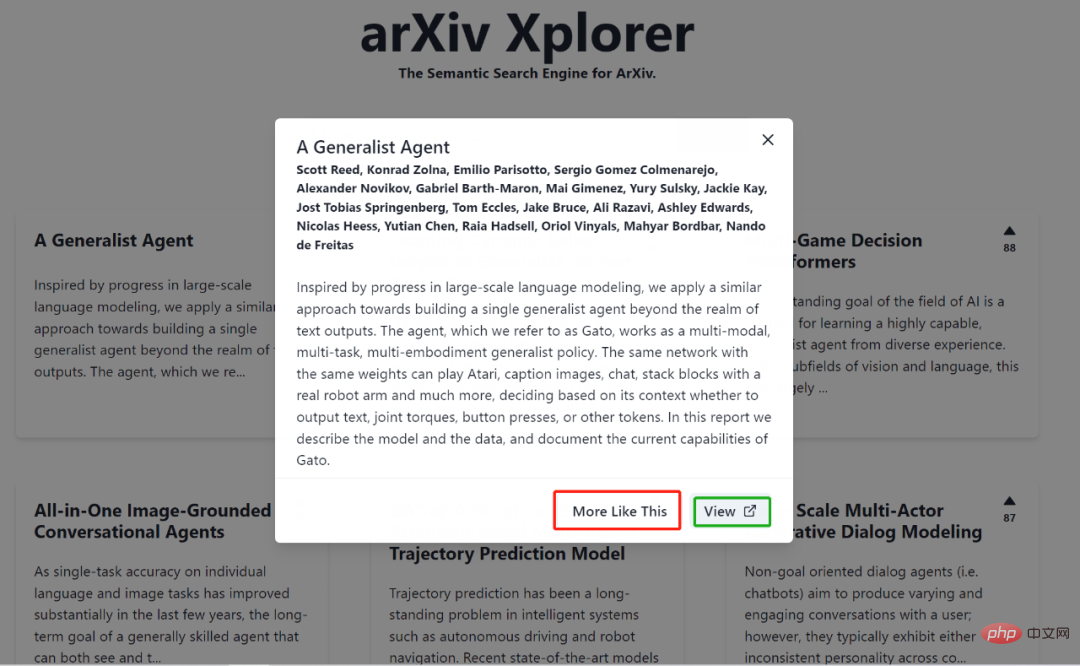
Vous pouvez également rechercher directement des articles similaires en collant l'url arxiv. Par exemple, l'entrée dans la figure ci-dessous est l'adresse de l'article "Un agent généraliste". Les résultats de la recherche s'affichent (encadré rouge), la similarité. d'Un Agent Généraliste est de 100 %, les autres résultats de recherche sont développés dans l'ordre en fonction du score.
De plus, vous pouvez également cliquer sur le petit triangle dans la case rouge ci-dessus, puis l'interface deviendra comme indiqué ci-dessous, montrant les participants à l'article et le résumé, et il y a deux fonctions ci-dessous : "Plus comme ça" D'autres articles similaires seront affichés ; "View" sera lié à la page d'accueil de l'article sur arXiv.
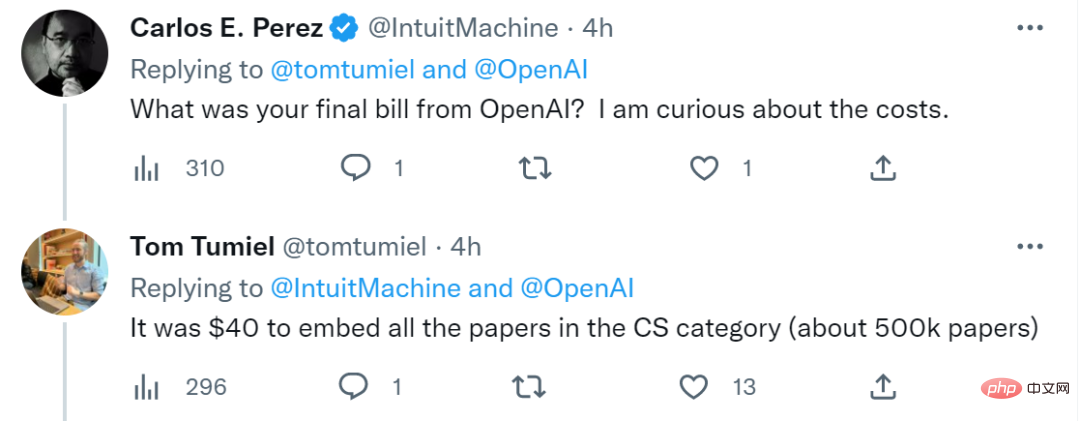
En voyant ce site Web entièrement fonctionnel, les internautes n'ont pas pu retenir leur curiosité et ont demandé : « Vous avez utilisé la technologie d'intégration d'OpenAI, mais cette technologie est payante, alors pourquoi avez-vous payé ? ce?" L'auteur du projet a déclaré : "Il en coûte 40 dollars américains pour intégrer tous les articles dans la catégorie CS (environ 500 000 articles)." : "Ce site Web est intégré. Avez-vous intégré tous les titres arXiv ?" L'auteur du projet a déclaré : "Il a intégré les titres et les résumés de tous les articles. Au départ, il a effectué la similarité cosinus et le tri manuellement, mais Pinecone a rendu les choses très faciles !"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment interpréter les résultats de sortie de Debian Sniffer
Apr 12, 2025 pm 11:00 PM
Comment interpréter les résultats de sortie de Debian Sniffer
Apr 12, 2025 pm 11:00 PM
DebianSniffer est un outil de renifleur de réseau utilisé pour capturer et analyser les horodatages du paquet de réseau: affiche le temps de capture de paquets, généralement en quelques secondes. Adresse IP source (SourceIP): l'adresse réseau de l'appareil qui a envoyé le paquet. Adresse IP de destination (DestinationIP): l'adresse réseau de l'appareil recevant le paquet de données. SourcePort: le numéro de port utilisé par l'appareil envoyant le paquet. Destinatio
 Comment vérifier la configuration de Debian OpenSSL
Apr 12, 2025 pm 11:57 PM
Comment vérifier la configuration de Debian OpenSSL
Apr 12, 2025 pm 11:57 PM
Cet article présente plusieurs méthodes pour vérifier la configuration OpenSSL du système Debian pour vous aider à saisir rapidement l'état de sécurité du système. 1. Confirmez d'abord la version OpenSSL, vérifiez si OpenSSL a été installé et des informations de version. Entrez la commande suivante dans le terminal: si OpenSSLVersion n'est pas installée, le système invitera une erreur. 2. Affichez le fichier de configuration. Le fichier de configuration principal d'OpenSSL est généralement situé dans /etc/ssl/opensessl.cnf. Vous pouvez utiliser un éditeur de texte (tel que Nano) pour afficher: Sutonano / etc / ssl / openssl.cnf Ce fichier contient des informations de configuration importantes telles que la clé, le chemin de certificat et l'algorithme de chiffrement. 3. Utiliser OPE
 Quels sont les paramètres de sécurité des journaux debian Tomcat?
Apr 12, 2025 pm 11:48 PM
Quels sont les paramètres de sécurité des journaux debian Tomcat?
Apr 12, 2025 pm 11:48 PM
Pour améliorer la sécurité des journaux Debiantomcat, nous devons prêter attention aux politiques clés suivantes: 1. Contrôle d'autorisation et gestion des fichiers: Autorisations du fichier journal: Les autorisations de fichier journal par défaut (640) restreignent l'accès. Il est recommandé de modifier la valeur UMask dans le script Catalina.sh (par exemple, de passer de 0027 à 0022), ou de définir directement des filepermissions dans le fichier de configuration log4j2 pour garantir les autorisations de lecture et d'écriture appropriées. Emplacement du fichier journal: Les journaux Tomcat sont généralement situés dans / opt / tomcat / journaux (ou chemin similaire), et les paramètres d'autorisation de ce répertoire doivent être vérifiés régulièrement. 2. Rotation du journal et format: rotation du journal: configurer server.xml
 Comparaison entre Debian Sniffer et Wireshark
Apr 12, 2025 pm 10:48 PM
Comparaison entre Debian Sniffer et Wireshark
Apr 12, 2025 pm 10:48 PM
Cet article traite de l'outil d'analyse de réseau Wireshark et de ses alternatives dans Debian Systems. Il devrait être clair qu'il n'y a pas d'outil d'analyse de réseau standard appelé "Debiansniffer". Wireshark est le principal analyseur de protocole de réseau de l'industrie, tandis que Debian Systems propose d'autres outils avec des fonctionnalités similaires. Comparaison des fonctionnalités fonctionnelles Wireshark: Il s'agit d'un puissant analyseur de protocole de réseau qui prend en charge la capture de données réseau en temps réel et la visualisation approfondie du contenu des paquets de données, et fournit des fonctions de prise en charge, de filtrage et de recherche et de recherche riches pour faciliter le diagnostic des problèmes de réseau. Outils alternatifs dans le système Debian: le système Debian comprend des réseaux tels que TCPDump et Tshark
 Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Les journaux TomCat sont la clé pour diagnostiquer les problèmes de fuite de mémoire. En analysant les journaux TomCat, vous pouvez avoir un aperçu de l'utilisation de la mémoire et du comportement de collecte des ordures (GC), localiser et résoudre efficacement les fuites de mémoire. Voici comment dépanner les fuites de mémoire à l'aide des journaux Tomcat: 1. Analyse des journaux GC d'abord, activez d'abord la journalisation GC détaillée. Ajoutez les options JVM suivantes aux paramètres de démarrage TomCat: -xx: printgcdetails-xx: printgcdatestamps-xloggc: gc.log Ces paramètres généreront un journal GC détaillé (GC.Log), y compris des informations telles que le type GC, la taille et le temps des objets de recyclage. Analyse GC.Log
 Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Cet article traite de la méthode de détection d'attaque DDOS. Bien qu'aucun cas d'application directe de "Debiansniffer" n'ait été trouvé, les méthodes suivantes ne peuvent être utilisées pour la détection des attaques DDOS: technologie de détection d'attaque DDOS efficace: détection basée sur l'analyse du trafic: identification des attaques DDOS en surveillant des modèles anormaux de trafic réseau, tels que la croissance soudaine du trafic, une surtension dans des connexions sur des ports spécifiques, etc. Par exemple, les scripts Python combinés avec les bibliothèques Pyshark et Colorama peuvent surveiller le trafic réseau en temps réel et émettre des alertes. Détection basée sur l'analyse statistique: en analysant les caractéristiques statistiques du trafic réseau, telles que les données
 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Cet article décrit comment personnaliser le format de journal d'Apache sur les systèmes Debian. Les étapes suivantes vous guideront à travers le processus de configuration: Étape 1: Accédez au fichier de configuration Apache Le fichier de configuration apache principal du système Debian est généralement situé dans /etc/apache2/apache2.conf ou /etc/apache2/httpd.conf. Ouvrez le fichier de configuration avec les autorisations racinaires à l'aide de la commande suivante: sudonano / etc / apache2 / apache2.conf ou sudonano / etc / apache2 / httpd.conf Étape 2: définir les formats de journal personnalisés à trouver ou
