
 développement back-end
Golang
Une brève analyse de la façon dont le découpage de la langue Go est étendu
développement back-end
Golang
Une brève analyse de la façon dont le découpage de la langue Go est étendu
Une brève analyse de la façon dont le découpage de la langue Go est étendu

Comment le découpage linguistique Go s'étend-il ? L'article suivant vous présentera le mécanisme d'expansion des tranches dans le langage Go. J'espère qu'il vous sera utile !

Dans le langage Go, il existe une structure de données très couramment utilisée, à savoir la tranche.
Une tranche est une séquence de longueur variable avec des éléments du même type. C'est une couche d'encapsulation basée sur le type de tableau. Il est très flexible et prend en charge l'expansion automatique.
Une tranche est un type de référence qui possède trois propriétés : Pointeur, Longueur et Capacité.

Le code source sous-jacent est défini comme suit :
type slice struct {
array unsafe.Pointer
len int
cap int
}- Pointeur : Pointe vers le premier élément auquel la tranche peut accéder.
- Longueur : Le nombre d'éléments dans la tranche.
- Capacité : Le nombre d'éléments entre l'élément de départ de la tranche et le dernier élément du tableau sous-jacent.
Par exemple, utilisez make([]byte, 5) pour créer une tranche qui ressemble à ceci : make([]byte, 5) 创建一个切片,它看起来是这样的:
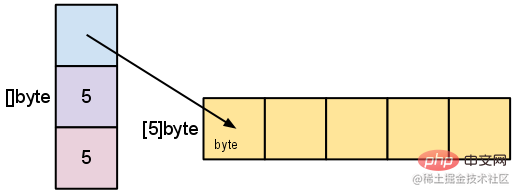
声明和初始化
切片的使用还是比较简单的,这里举一个例子,直接看代码吧。
func main() {
var nums []int // 声明切片
fmt.Println(len(nums), cap(nums)) // 0 0
nums = append(nums, 1) // 初始化
fmt.Println(len(nums), cap(nums)) // 1 1
nums1 := []int{1,2,3,4} // 声明并初始化
fmt.Println(len(nums1), cap(nums1)) // 4 4
nums2 := make([]int,3,5) // 使用make()函数构造切片
fmt.Println(len(nums2), cap(nums2)) // 3 5
}扩容时机
当切片的长度超过其容量时,切片会自动扩容。这通常发生在使用 append 函数向切片中添加元素时。
扩容时,Go 运行时会分配一个新的底层数组,并将原始切片中的元素复制到新数组中。然后,原始切片将指向新数组,并更新其长度和容量。
需要注意的是,由于扩容会分配新数组并复制元素,因此可能会影响性能。如果你知道要添加多少元素,可以使用 make 函数预先分配足够大的切片来避免频繁扩容。
接下来看看 append 函数,签名如下:
func Append(slice []int, items ...int) []int
append 函数参数长度可变,可以追加多个值,还可以直接追加一个切片。使用起来比较简单,分别看两个例子:
追加多个值:
package main
import "fmt"
func main() {
s := []int{1, 2, 3}
fmt.Println("初始切片:", s)
s = append(s, 4, 5, 6)
fmt.Println("追加多个值后的切片:", s)
}输出结果为:
初始切片: [1 2 3] 追加多个值后的切片: [1 2 3 4 5 6]
再来看一下直接追加一个切片:
package main
import "fmt"
func main() {
s1 := []int{1, 2, 3}
fmt.Println("初始切片:", s1)
s2 := []int{4, 5, 6}
s1 = append(s1, s2...)
fmt.Println("追加另一个切片后的切片:", s1)
}输出结果为:
初始切片: [1 2 3] 追加另一个切片后的切片: [1 2 3 4 5 6]
再来看一个发生扩容的例子:
package main
import "fmt"
func main() {
s := make([]int, 0, 3) // 创建一个长度为0,容量为3的切片
fmt.Printf("初始状态: len=%d cap=%d %v\n", len(s), cap(s), s)
for i := 1; i <= 5; i++ {
s = append(s, i) // 向切片中添加元素
fmt.Printf("添加元素%d: len=%d cap=%d %v\n", i, len(s), cap(s), s)
}
}输出结果为:
初始状态: len=0 cap=3 [] 添加元素1: len=1 cap=3 [1] 添加元素2: len=2 cap=3 [1 2] 添加元素3: len=3 cap=3 [1 2 3] 添加元素4: len=4 cap=6 [1 2 3 4] 添加元素5: len=5 cap=6 [1 2 3 4 5]
在这个例子中,我们创建了一个长度为 0,容量为 3 的切片。然后,我们使用 append 函数向切片中添加 5 个元素。
当我们添加第 4 个元素时,切片的长度超过了其容量。此时,切片会自动扩容。新的容量是原始容量的两倍,即 6。
表面现象已经看到了,接下来,我们就深入到源码层面,看看切片的扩容机制到底是什么样的。
源码分析
在 Go 语言的源码中,切片扩容通常是在进行切片的 append 操作时触发的。在进行 append 操作时,如果切片容量不足以容纳新的元素,就需要对切片进行扩容,此时就会调用 growslice 函数进行扩容。
growslice 函数定义在 Go 语言的 runtime 包中,它的调用是在编译后的代码中实现的。具体来说,当执行 append 操作时,编译器会将其转换为类似下面的代码:
slice = append(slice, elem)
在上述代码中,如果切片容量不足以容纳新的元素,则会调用 growslice 函数进行扩容。所以 growslice 函数的调用是由编译器在生成的机器码中实现的,而不是在源代码中显式调用的。
切片扩容策略有两个阶段,go1.18 之前和之后是不同的,这一点在 go1.18 的 release notes 中有说明。
下面我用 go1.17 和 go1.18 两个版本来分开说明。先通过一段测试代码,直观感受一下两个版本在扩容上的区别。
package main
import "fmt"
func main() {
s := make([]int, 0)
oldCap := cap(s)
for i := 0; i < 2048; i++ {
s = append(s, i)
newCap := cap(s)
if newCap != oldCap {
fmt.Printf("[%d -> %4d] cap = %-4d | after append %-4d cap = %-4d\n", 0, i-1, oldCap, i, newCap)
oldCap = newCap
}
}
}上述代码先创建了一个空的 slice,然后在一个循环里不断往里面 append

Déclaration et initialisation
L'utilisation du découpage est relativement simple. Voici un exemple. Regardons directement le code.
[0 -> -1] cap = 0 | after append 0 cap = 1 [0 -> 0] cap = 1 | after append 1 cap = 2 [0 -> 1] cap = 2 | after append 2 cap = 4 [0 -> 3] cap = 4 | after append 4 cap = 8 [0 -> 7] cap = 8 | after append 8 cap = 16 [0 -> 15] cap = 16 | after append 16 cap = 32 [0 -> 31] cap = 32 | after append 32 cap = 64 [0 -> 63] cap = 64 | after append 64 cap = 128 [0 -> 127] cap = 128 | after append 128 cap = 256 [0 -> 255] cap = 256 | after append 256 cap = 512 [0 -> 511] cap = 512 | after append 512 cap = 1024 [0 -> 1023] cap = 1024 | after append 1024 cap = 1280 [0 -> 1279] cap = 1280 | after append 1280 cap = 1696 [0 -> 1695] cap = 1696 | after append 1696 cap = 2304
Minutage d'expansion
Lorsque la longueur de la tranche dépasse sa capacité, la tranche s'agrandit automatiquement. Cela se produit généralement lors de l'ajout d'éléments à une tranche à l'aide de la fonctionappend. Lors du développement, le runtime Go alloue un nouveau tableau sous-jacent et copie les éléments de la tranche d'origine dans le nouveau tableau. La tranche d'origine pointera alors vers le nouveau tableau, avec sa longueur et sa capacité mises à jour.
Il convient de noter que puisquel'expansion alloue de nouveaux tableaux et copie des éléments, cela peut affecter les performances
. Si vous savez combien d'éléments vous souhaitez ajouter, vous pouvez utiliser la fonctionmake pour pré-allouer une tranche suffisamment grande pour éviter une expansion fréquente. 🎜🎜Ensuite, jetons un œil à la fonction append, avec la signature suivante : 🎜[0 -> -1] cap = 0 | after append 0 cap = 1 [0 -> 0] cap = 1 | after append 1 cap = 2 [0 -> 1] cap = 2 | after append 2 cap = 4 [0 -> 3] cap = 4 | after append 4 cap = 8 [0 -> 7] cap = 8 | after append 8 cap = 16 [0 -> 15] cap = 16 | after append 16 cap = 32 [0 -> 31] cap = 32 | after append 32 cap = 64 [0 -> 63] cap = 64 | after append 64 cap = 128 [0 -> 127] cap = 128 | after append 128 cap = 256 [0 -> 255] cap = 256 | after append 256 cap = 512 [0 -> 511] cap = 512 | after append 512 cap = 848 [0 -> 847] cap = 848 | after append 848 cap = 1280 [0 -> 1279] cap = 1280 | after append 1280 cap = 1792 [0 -> 1791] cap = 1792 | after append 1792 cap = 2560
append La longueur des paramètres de la fonction est variable, et plusieurs valeurs peut être ajouté, ou une tranche peut être ajoutée directement. C'est relativement simple à utiliser. Regardons respectivement deux exemples : 🎜🎜🎜Ajouter plusieurs valeurs : 🎜🎜// src/runtime/slice.go
func growslice(et *_type, old slice, cap int) slice {
// ...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
// ...
return slice{p, old.len, newcap}
}// src/runtime/slice.go
func growslice(et *_type, old slice, cap int) slice {
// ...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
// ...
return slice{p, old.len, newcap}
}capmem = roundupsize(uintptr(newcap) * ptrSize) newcap = int(capmem / ptrSize)
0 et d'une capacité de 3 de tranches. Nous utilisons ensuite la fonction append pour ajouter 5 éléments à la tranche. 🎜🎜Lorsque nous ajoutons l'élément 4, la longueur de la tranche dépasse sa capacité. À ce moment-là, la tranche s’agrandira automatiquement. La nouvelle capacité est le double de la capacité d'origine, qui est 6. 🎜🎜Nous avons vu le phénomène de surface. Ensuite, nous approfondirons le niveau du code source pour voir à quoi ressemble le mécanisme d'expansion du découpage. 🎜🎜Analyse du code source🎜
🎜Dans le code source du langage Go, l'expansion des tranches est généralement déclenchée lors de l'exécution de l'opérationappend du tranche. Lors de l'opération append, si la capacité de la tranche n'est pas suffisante pour accueillir de nouveaux éléments, la tranche doit être développée. À ce moment, la fonction growslice sera appelée pour se développer. la capacité. 🎜🎜growslice La fonction est définie dans le package d'exécution du langage Go, et son appel est implémenté dans le code compilé. Plus précisément, lorsque l'opération append est effectuée, le compilateur la convertira en code similaire au suivant : 🎜rrreee🎜Dans le code ci-dessus, si la capacité de la tranche n'est pas suffisante pour accueillir le nouvel élément, elle sera appelée fonction growslice pour l'expansion. Ainsi, l'appel à la fonction growslice est implémenté par le compilateur dans le code machine généré, plutôt que explicitement appelé dans le code source. 🎜🎜La stratégie d'expansion des tranches comporte deux étapes, qui sont différentes avant et après go1.18. Ceci est expliqué dans les notes de version de go1.18. 🎜🎜J'utiliserai les versions go1.17 et go1.18 pour expliquer séparément ci-dessous. Tout d’abord, passons en revue un morceau de code de test pour ressentir intuitivement la différence d’expansion entre les deux versions. 🎜rrreee🎜Le code ci-dessus crée d'abord une tranche vide, puis y ajoute de nouveaux éléments dans une boucle. 🎜🎜Ensuite, enregistrez le changement de capacité. Chaque fois que la capacité change, enregistrez l'ancienne capacité, les éléments ajoutés et la capacité après avoir ajouté les éléments. 🎜🎜De cette façon, vous pouvez observer les changements de capacité des anciennes et des nouvelles tranches et connaître les règles. 🎜🎜Résultats en cours (🎜version 1.17🎜) : 🎜rrreee🎜Résultats en cours (🎜version 1.18🎜) : 🎜rrreee🎜Vous pouvez toujours voir la différence en fonction des résultats ci-dessus. La stratégie d'expansion spécifique est expliquée ci-dessous en regardant la source. code. 🎜go1.17
扩容调用的是 growslice 函数,我复制了其中计算新容量部分的代码。
// src/runtime/slice.go
func growslice(et *_type, old slice, cap int) slice {
// ...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
// ...
return slice{p, old.len, newcap}
}在分配内存空间之前需要先确定新的切片容量,运行时根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于等于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
go1.18
// src/runtime/slice.go
func growslice(et *_type, old slice, cap int) slice {
// ...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
// ...
return slice{p, old.len, newcap}
}和之前版本的区别,主要在扩容阈值,以及这行代码:newcap += (newcap + 3*threshold) / 4。
在分配内存空间之前需要先确定新的切片容量,运行时根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于阈值(默认 256)就会将容量翻倍;
- 如果当前切片的长度大于等于阈值(默认 256),就会每次增加 25% 的容量,基准是
newcap + 3*threshold,直到新容量大于期望容量;
内存对齐
分析完两个版本的扩容策略之后,再看前面的那段测试代码,就会发现扩容之后的容量并不是严格按照这个策略的。
那是为什么呢?
实际上,growslice 的后半部分还有更进一步的优化(内存对齐等),靠的是 roundupsize 函数,在计算完 newcap 值之后,还会有一个步骤计算最终的容量:
capmem = roundupsize(uintptr(newcap) * ptrSize) newcap = int(capmem / ptrSize)
这个函数的实现就不在这里深入了,先挖一个坑,以后再来补上。
总结
切片扩容通常是在进行切片的 append 操作时触发的。在进行 append 操作时,如果切片容量不足以容纳新的元素,就需要对切片进行扩容,此时就会调用 growslice 函数进行扩容。
切片扩容分两个阶段,分为 go1.18 之前和之后:
一、go1.18 之前:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
二、go1.18 之后:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于阈值(默认 256)就会将容量翻倍;
- 如果当前切片的长度大于等于阈值(默认 256),就会每次增加 25% 的容量,基准是
newcap + 3*threshold,直到新容量大于期望容量;
以上就是本文的全部内容,如果觉得还不错的话欢迎点赞,转发和关注,感谢支持。
推荐学习:Golang教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment faire correspondre les horodatages à l'aide d'expressions régulières dans Go ?
Jun 02, 2024 am 09:00 AM
Comment faire correspondre les horodatages à l'aide d'expressions régulières dans Go ?
Jun 02, 2024 am 09:00 AM
Dans Go, vous pouvez utiliser des expressions régulières pour faire correspondre les horodatages : compilez une chaîne d'expression régulière, telle que celle utilisée pour faire correspondre les horodatages ISO8601 : ^\d{4}-\d{2}-\d{2}T \d{ 2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ . Utilisez la fonction regexp.MatchString pour vérifier si une chaîne correspond à une expression régulière.
 Comment envoyer des messages Go WebSocket ?
Jun 03, 2024 pm 04:53 PM
Comment envoyer des messages Go WebSocket ?
Jun 03, 2024 pm 04:53 PM
Dans Go, les messages WebSocket peuvent être envoyés à l'aide du package gorilla/websocket. Étapes spécifiques : Établissez une connexion WebSocket. Envoyer un message texte : appelez WriteMessage(websocket.TextMessage,[]byte("message")). Envoyez un message binaire : appelez WriteMessage(websocket.BinaryMessage,[]byte{1,2,3}).
 La différence entre la langue Golang et Go
May 31, 2024 pm 08:10 PM
La différence entre la langue Golang et Go
May 31, 2024 pm 08:10 PM
Go et le langage Go sont des entités différentes avec des caractéristiques différentes. Go (également connu sous le nom de Golang) est connu pour sa concurrence, sa vitesse de compilation rapide, sa gestion de la mémoire et ses avantages multiplateformes. Les inconvénients du langage Go incluent un écosystème moins riche que les autres langages, une syntaxe plus stricte et un manque de typage dynamique.
 Comment éviter les fuites de mémoire dans l'optimisation des performances techniques de Golang ?
Jun 04, 2024 pm 12:27 PM
Comment éviter les fuites de mémoire dans l'optimisation des performances techniques de Golang ?
Jun 04, 2024 pm 12:27 PM
Les fuites de mémoire peuvent entraîner une augmentation continue de la mémoire du programme Go en : fermant les ressources qui ne sont plus utilisées, telles que les fichiers, les connexions réseau et les connexions à la base de données. Utilisez des références faibles pour éviter les fuites de mémoire et ciblez les objets pour le garbage collection lorsqu'ils ne sont plus fortement référencés. En utilisant go coroutine, la mémoire de la pile de coroutines sera automatiquement libérée à la sortie pour éviter les fuites de mémoire.
 Collection de questions d'entretien sur le cadre Golang
Jun 02, 2024 pm 09:37 PM
Collection de questions d'entretien sur le cadre Golang
Jun 02, 2024 pm 09:37 PM
Le framework Go est un ensemble de composants qui étendent les bibliothèques intégrées de Go, fournissant des fonctionnalités prédéfinies (telles que le développement Web et les opérations de base de données). Les frameworks Go populaires incluent Gin (développement Web), GORM (opérations de base de données) et RESTful (gestion des API). Le middleware est un modèle d'intercepteur dans la chaîne de traitement des requêtes HTTP et est utilisé pour ajouter des fonctionnalités telles que l'authentification ou la journalisation des requêtes sans modifier le gestionnaire. La gestion des sessions maintient l'état de la session en stockant les données utilisateur. Vous pouvez utiliser gorilla/sessions pour gérer les sessions.
 Comment utiliser le wrapper d'erreur de Golang ?
Jun 03, 2024 pm 04:08 PM
Comment utiliser le wrapper d'erreur de Golang ?
Jun 03, 2024 pm 04:08 PM
Dans Golang, les wrappers d'erreurs vous permettent de créer de nouvelles erreurs en ajoutant des informations contextuelles à l'erreur d'origine. Cela peut être utilisé pour unifier les types d'erreurs générées par différentes bibliothèques ou composants, simplifiant ainsi le débogage et la gestion des erreurs. Les étapes sont les suivantes : Utilisez la fonction error.Wrap pour envelopper les erreurs d'origine dans de nouvelles erreurs. La nouvelle erreur contient des informations contextuelles de l'erreur d'origine. Utilisez fmt.Printf pour générer des erreurs encapsulées, offrant ainsi plus de contexte et de possibilités d'action. Lors de la gestion de différents types d’erreurs, utilisez la fonction erreurs.Wrap pour unifier les types d’erreurs.
 Un guide pour les tests unitaires des fonctions simultanées Go
May 03, 2024 am 10:54 AM
Un guide pour les tests unitaires des fonctions simultanées Go
May 03, 2024 am 10:54 AM
Les tests unitaires des fonctions simultanées sont essentiels car cela permet de garantir leur comportement correct dans un environnement simultané. Des principes fondamentaux tels que l'exclusion mutuelle, la synchronisation et l'isolement doivent être pris en compte lors du test de fonctions concurrentes. Les fonctions simultanées peuvent être testées unitairement en simulant, en testant les conditions de concurrence et en vérifiant les résultats.
 Comment créer une Goroutine priorisée dans Go ?
Jun 04, 2024 pm 12:41 PM
Comment créer une Goroutine priorisée dans Go ?
Jun 04, 2024 pm 12:41 PM
Il y a deux étapes pour créer un Goroutine prioritaire dans le langage Go : enregistrer une fonction de création de Goroutine personnalisée (étape 1) et spécifier une valeur de priorité (étape 2). De cette façon, vous pouvez créer des Goroutines avec des priorités différentes, optimiser l'allocation des ressources et améliorer l'efficacité de l'exécution.
