
 Périphériques technologiques
IA
Le grand modèle peut « rédiger » des articles tout seul, avec formules et références. La version d'essai est désormais en ligne.
Périphériques technologiques
IA
Le grand modèle peut « rédiger » des articles tout seul, avec formules et références. La version d'essai est désormais en ligne.
Le grand modèle peut « rédiger » des articles tout seul, avec formules et références. La version d'essai est désormais en ligne.

Ces dernières années, avec l'avancement de la recherche dans divers domaines, la littérature et les données scientifiques ont explosé, rendant de plus en plus difficile pour les chercheurs universitaires de découvrir des informations utiles à partir de grandes quantités d'informations. Habituellement, les gens utilisent les moteurs de recherche pour obtenir des connaissances scientifiques, mais les moteurs de recherche ne peuvent pas organiser les connaissances scientifiques de manière autonome.
Maintenant, une équipe de recherche de Meta AI a proposé Galactica, un nouveau modèle de langage à grande échelle capable de stocker, combiner et raisonner sur les connaissances scientifiques.

- Adresse papier : https://galactica.org/static/paper.pdf
- Adresse d'essai : https://galactica.org/
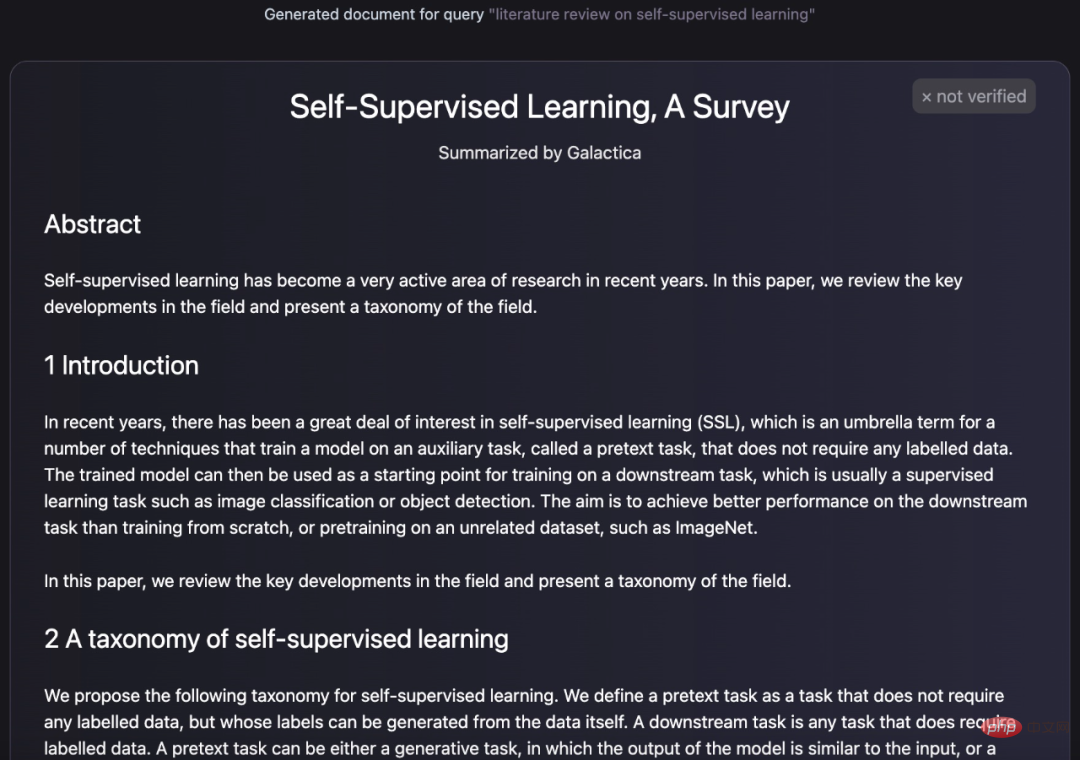
Modèle Galactica Quelle est sa puissance ? Il peut résumer et résumer un article de révision par lui-même :
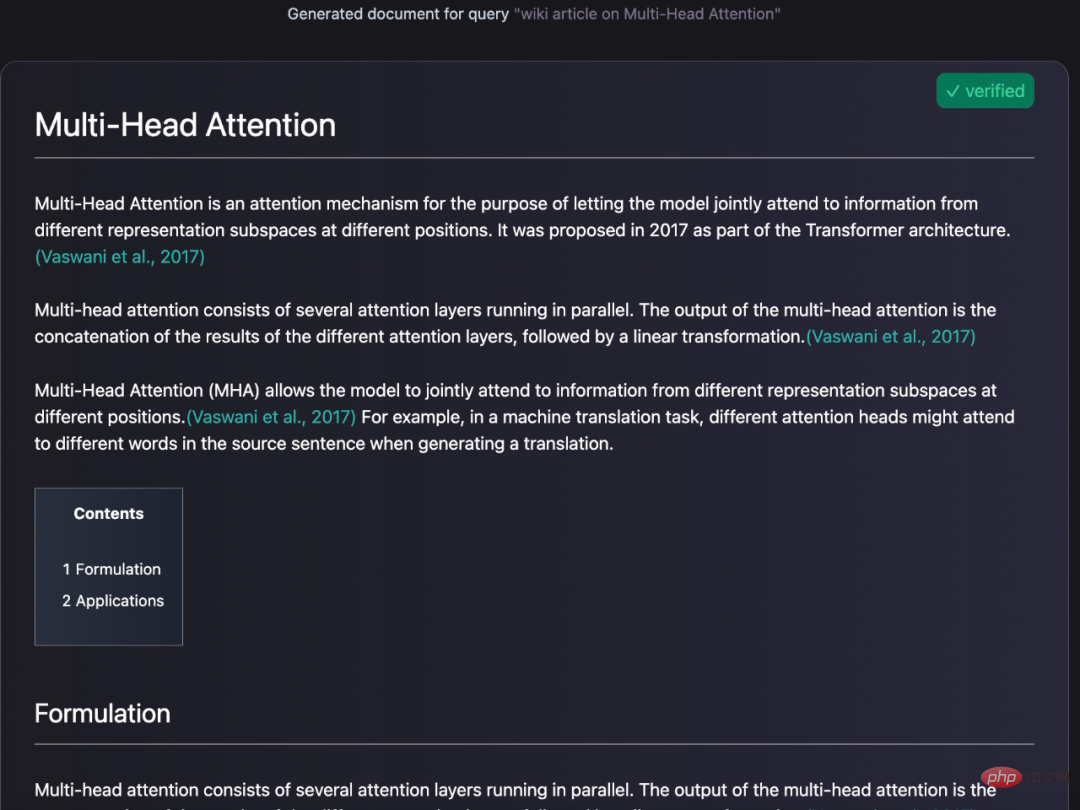
Il peut également générer des requêtes encyclopédiques pour les entrées :
Donner des réponses éclairées aux questions soulevées :
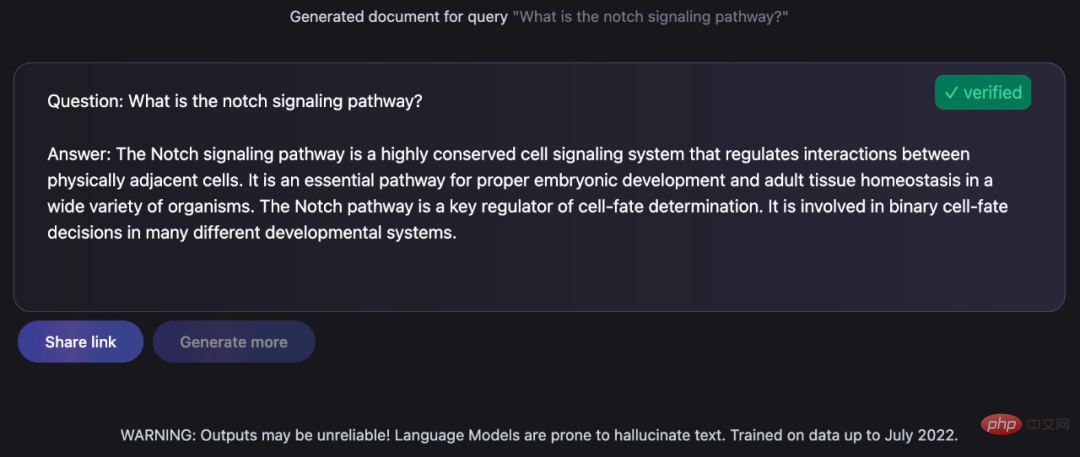
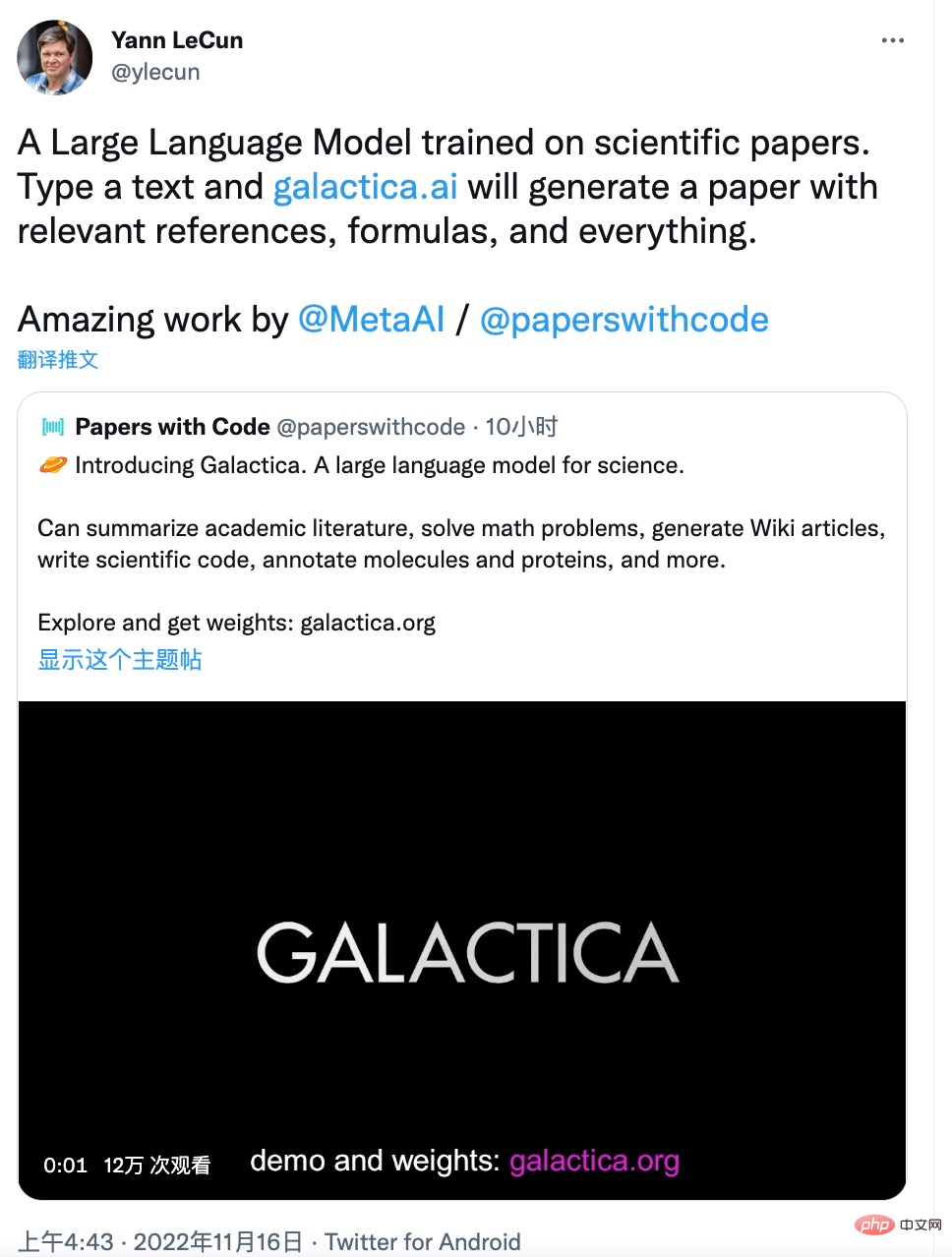
Ces tâches restent un défi pour les anthropologues, mais Galactica les a bien accomplies. Yann LeCun, lauréat du prix Turing, a également tweeté ses éloges :
Jetons un coup d'œil aux détails spécifiques du modèle Galactica.
Aperçu du modèle
Le modèle Galactica est formé sur un vaste corpus scientifique d'articles, de documents de référence, de bases de connaissances et de nombreuses autres sources, y compris plus de 48 millions d'articles, de manuels et de documents, des millions de composés et de connaissances sur les protéines, des connaissances scientifiques. sites Web, encyclopédies, etc. Contrairement aux modèles linguistiques existants qui s'appuient sur du texte non organisé basé sur un robot d'exploration Web, le corpus utilisé pour la formation Galactica est de haute qualité et hautement organisé. Cette étude a entraîné le modèle pour plusieurs époques sans surajustement, où les performances des tâches en amont et en aval ont été améliorées grâce à l'utilisation de jetons répétés.
Le Galactica surpasse les modèles existants dans une gamme de tâches scientifiques. Sur les tâches d'exploration des connaissances techniques telles que les équations LaTeX, les performances de Galactica et GPT-3 sont de 68,2 % contre 49,0 %. Galactica excelle également en inférence, surpassant largement Chinchilla sur le benchmark mathématique MMLU.
Galactica surpasse également BLOOM et OPT-175B sur BIG-bench bien qu'il n'ait pas été formé sur un corpus commun. De plus, il a atteint de nouveaux sommets de performances de 77,6 % et 52,9 % sur les tâches en aval telles que le développement de PubMedQA et MedMCQA.
En termes simples, la recherche résume le raisonnement étape par étape dans des jetons spéciaux pour imiter le fonctionnement interne. Cela permet aux chercheurs d’interagir avec des modèles en utilisant le langage naturel, comme indiqué ci-dessous dans l’interface d’essai de Galactica.
Il convient de mentionner qu'en plus de la génération de texte, Galactica peut également effectuer des tâches multimodales impliquant des formules chimiques et des séquences de protéines. Cela contribuera au domaine de la découverte de médicaments.
Détails de mise en œuvre
Le corpus de cet article contient 106 milliards de jetons, provenant d'articles, de références, d'encyclopédies et d'autres documents scientifiques. On peut dire que ces recherches incluent à la fois des ressources en langage naturel (articles, ouvrages de référence) et des séquences dans la nature (séquences protéiques, formes chimiques). Les détails du corpus sont présentés dans les tableaux 1 et 2 .
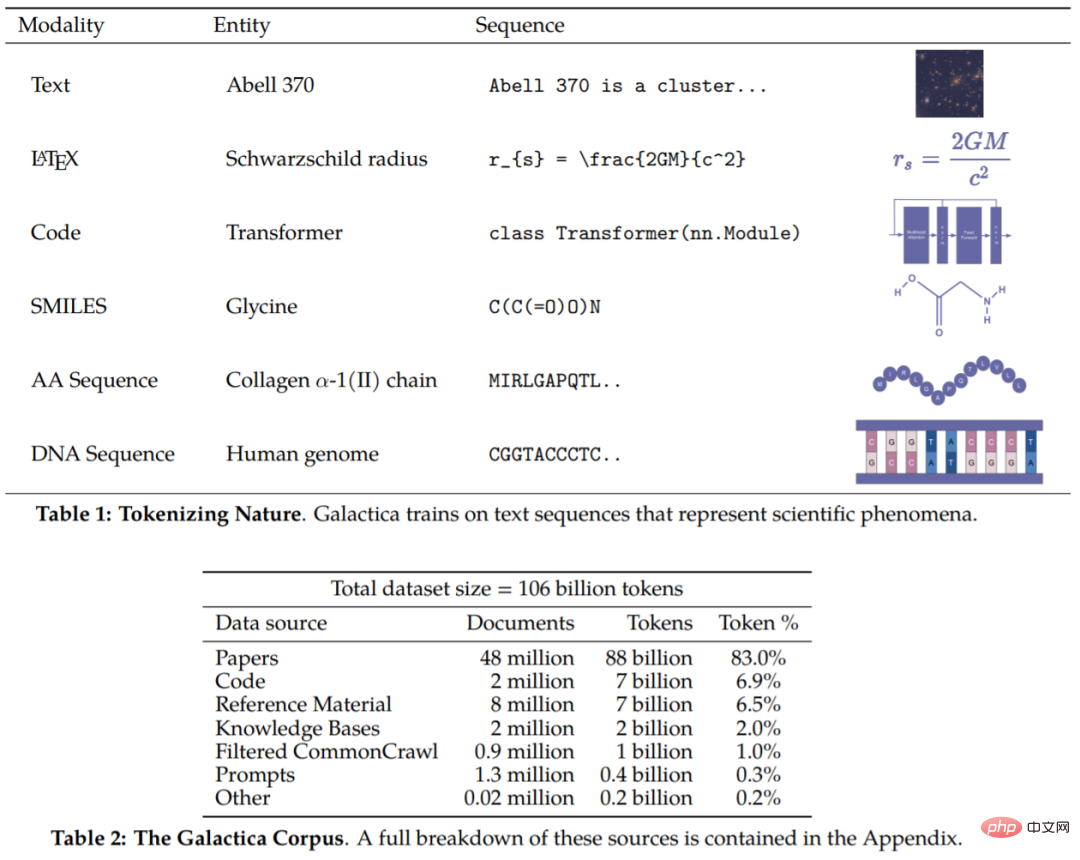
Maintenant que nous avons le corpus, la prochaine étape consiste à savoir comment exploiter les données. D’une manière générale, la conception de la tokenisation est très importante. Par exemple, si les séquences protéiques sont écrites en termes de résidus d’acides aminés, alors la tokenisation basée sur les caractères est appropriée. Afin de réaliser la tokenisation, cette étude a réalisé une tokenisation spécialisée sur différentes modalités. Les manifestations spécifiques incluent (sans s'y limiter) :
- Référence : utilisez des jetons de référence spéciaux [START_REF] et [END_REF] pour envelopper les références
- Raisonnement étape par étape : utilisez des jetons de mémoire de travail pour encapsuler ; Raisonnement et simulation étape par étape Contexte de la mémoire de travail interne ;
- Nombre : divisez les nombres en jetons séparés. Par exemple, 737612.62 → 7,3,7,6,1,2,.,6,2 ; formule
- SMILES : enveloppez la séquence avec [START_SMILES] et [END_SMILES] et appliquez une tokenisation basée sur les caractères. De même, cette étude utilise [START_I_SMILES] et [END_I_SMILES] pour représenter les SMILES isomères. Par exemple : C(C(=O)O)N→C, (,C,(,=,O,),O,),N;
- Séquence d'ADN : appliquez une tokenisation basée sur les caractères à chaque nucléotide. les bases sont considérées comme un jeton, où les jetons de départ sont [START_DNA] et [END_DNA]. Par exemple, CGGTACCCTC → C, G, G, T, A, C, C, C, T, C.
La figure 4 ci-dessous montre un exemple de traitement des références à un article. Lors du traitement des références, utilisez des identifiants globaux et les jetons spéciaux [START_REF] et [END_REF] pour indiquer le lieu de la référence.

Une fois l'ensemble de données traité, l'étape suivante consiste à savoir comment le mettre en œuvre. Galactica a apporté les modifications suivantes basées sur l'architecture du Transformer :
- Activation GeLU : utilisez l'activation GeLU pour les modèles de différentes tailles
- Fenêtre contextuelle : pour les modèles de tailles différentes, utilisez une fenêtre contextuelle de 2048 longueurs ;
- Aucun biais : suivez PaLM, aucun biais n'est utilisé dans les spécifications de noyau ou de couche dense
- Apprendre les intégrations de position : apprendre les intégrations de position pour le modèle
- Glossaire : Utilisez BPE pour créer un glossaire ; contenant 50 000 jetons.
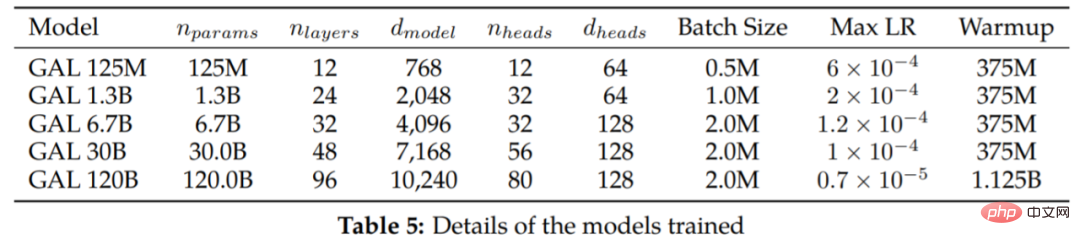
Le tableau 5 répertorie les modèles de différentes tailles et hyperparamètres d'entraînement.
Expérience
Les jetons en double sont considérés comme inoffensifs
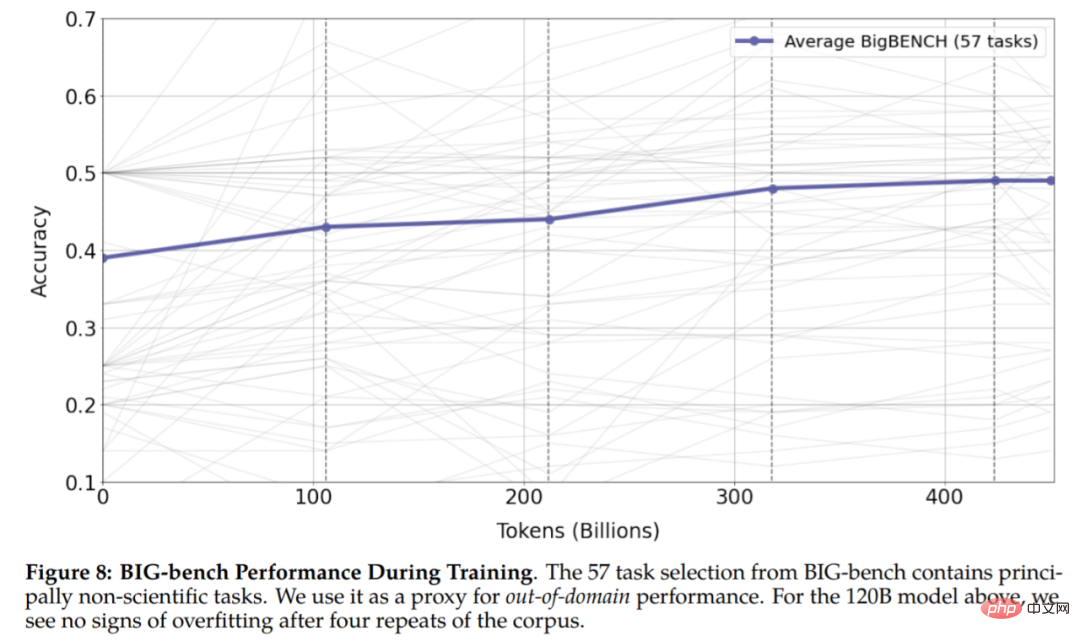
Comme le montre la figure 6, après quatre époques de formation, la perte de validation continue de diminuer. Le modèle avec les paramètres 120B ne commence à surajuster qu'au début de la cinquième époque. Ceci est inattendu car les recherches existantes montrent que les jetons en double peuvent nuire aux performances. L'étude a également révélé que les modèles 30B et 120B présentaient un double effet de déclin selon les époques, où la perte de validation plafonnait (ou augmentait), suivie d'un déclin. Cet effet devient plus fort après chaque époque, notamment pour le modèle 120B en fin d'entraînement.
Figure 8 Les résultats montrent qu'il n'y a aucun signe de surapprentissage dans l'expérience, ce qui montre que les jetons répétés peuvent améliorer les performances des tâches en aval et en amont.
Autres résultats
Il est trop lent de taper des formules, vous pouvez désormais générer du LaTeX avec des invites :

Dans les réactions chimiques, Galactica est invité à prédire les réactions dans les équations chimiques LaTeX Produit de , le modèle peut raisonner uniquement sur la base des réactifs, et les résultats sont les suivants :

Quelques autres résultats sont rapportés dans le tableau 7 :
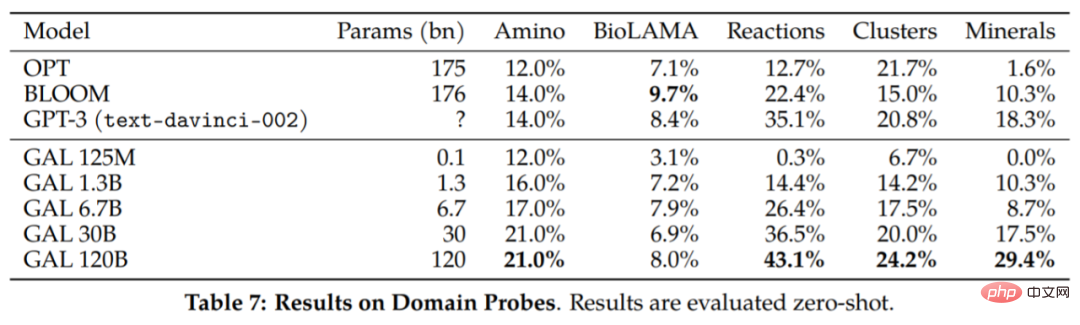
Les capacités de raisonnement du Galactica. L'étude est d'abord évaluée sur la référence mathématique MMLU et les résultats de l'évaluation sont présentés dans le tableau 8. Le Galactica fonctionne très bien par rapport au modèle de base plus grand, et l'utilisation de jetons semble améliorer les performances du Chinchilla, même pour le plus petit modèle Galactica 30B.
L'étude a également évalué l'ensemble de données MATH pour explorer davantage les capacités de raisonnement de Galactica :
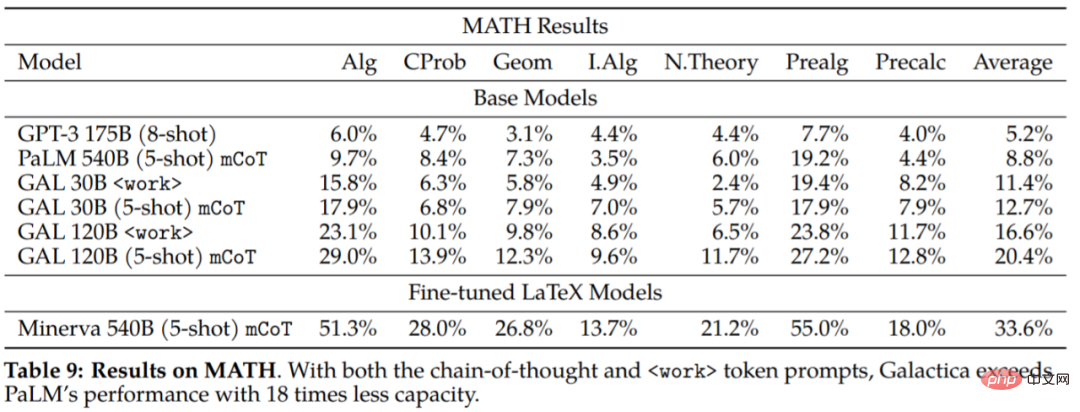
On peut conclure des résultats expérimentaux : Galactica est nettement meilleur que le PaLM de base en termes d'enchaînement de pensées et d'incitation. Modèle. Cela suggère que Galactica est un meilleur choix pour gérer des tâches mathématiques. Les résultats de l'évaluation de
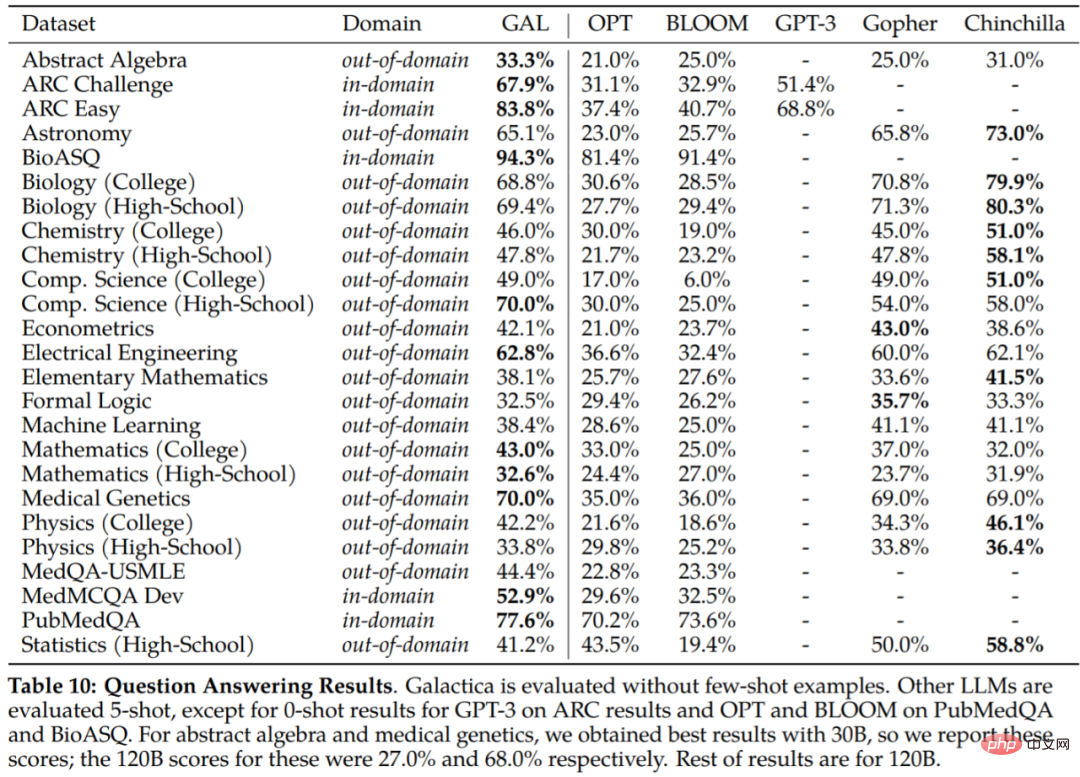
sur les tâches en aval sont présentés dans le tableau 10. Galactica surpasse considérablement les autres modèles de langage et surpasse les modèles plus grands dans la plupart des tâches (Gopher 280B). La différence de performance est plus grande que celle du Chinchilla, qui semble être plus fort sur un sous-ensemble de tâches : en particulier les matières du secondaire et les tâches moins mathématiques et gourmandes en mémoire. En revanche, Galactica a tendance à mieux performer dans les tâches de mathématiques et de niveau universitaire.
L’étude a également évalué la capacité du Chinchilla à prédire les citations en fonction du contexte d’entrée, un test important de la capacité du Chinchilla à organiser la littérature scientifique. Les résultats sont les suivants :
Pour plus de contenu expérimental, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Lors de la sélection d'une version Pytorch sous CentOS, les facteurs clés suivants doivent être pris en compte: 1. CUDA Version Compatibilité GPU Prise en charge: si vous avez NVIDIA GPU et que vous souhaitez utiliser l'accélération GPU, vous devez choisir Pytorch qui prend en charge la version CUDA correspondante. Vous pouvez afficher la version CUDA prise en charge en exécutant la commande nvidia-SMI. Version CPU: Si vous n'avez pas de GPU ou que vous ne souhaitez pas utiliser de GPU, vous pouvez choisir une version CPU de Pytorch. 2. Version Python Pytorch
