
 Périphériques technologiques
IA
Discutez de l'état actuel et des tendances de développement de la technologie de prédiction de trajectoire de conduite autonome
Périphériques technologiques
IA
Discutez de l'état actuel et des tendances de développement de la technologie de prédiction de trajectoire de conduite autonome
Discutez de l'état actuel et des tendances de développement de la technologie de prédiction de trajectoire de conduite autonome

1 Qu'est-ce que la prédiction de trajectoire
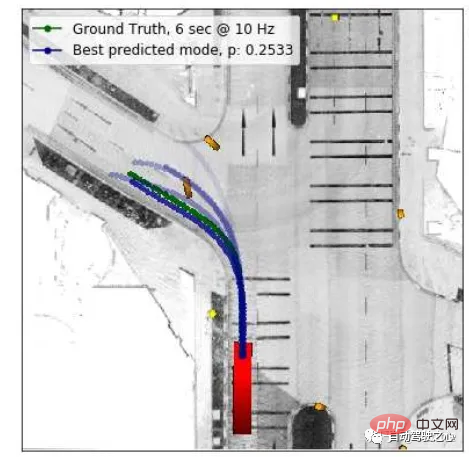
En conduite autonome, la prédiction de trajectoire est généralement située à l'arrière du module de perception, et l'extrémité avant du module de contrôle est un module de connexion. Saisissez les informations d'état et les informations sur la structure routière de la piste cible fournies par le module de perception, prenez en compte de manière exhaustive les informations cartographiques de haute précision, les informations d'interaction entre les cibles, les informations sémantiques de l'environnement et les informations d'intention de la cible, et formulez des intentions pour diverses cibles perçues. . Prédiction (coupure d'entrée/sortie, tout droit) et prédiction de trajectoire pour une période de temps future (allant de 0 à 5 s). Comme indiqué ci-dessous.
Les systèmes ADAS doivent avoir certaines capacités cognitives concernant les informations sur l'environnement environnant. Le niveau le plus élémentaire est de reconnaître l'environnement, le niveau suivant doit comprendre l'environnement et le niveau suivant doit prédire l'environnement. Après avoir prédit la cible, le contrôleur peut planifier la trajectoire du véhicule sur la base des informations prédites et prendre la décision de freiner ou d'émettre des avertissements concernant d'éventuelles situations dangereuses. C'est l'objectif du module de prédiction de trajectoire.
2 Deux défis
La prédiction de trajectoire peut être divisée en prédiction à court terme et prédiction à long terme.
- La prédiction à court terme est généralement basée sur le modèle cinématique (CV/CA/CTRV/CTRA) basé sur les informations sur l'état cible actuel pour prédire la trajectoire pour une période de temps future. Généralement,
- La prévision à long terme est ce que fait actuellement l'industrie. Ce type de prédiction ne convient pas uniquement sur la base du modèle de mouvement. Généralement, la prédiction d'intention est requise et combinée à certaines informations contextuelles (carte, informations d'interaction entre cibles) pour obtenir de bons résultats. À l'heure actuelle, il existe de nombreuses formes de sortie différentes dans l'industrie, telles que la sortie de la distribution de probabilité de la trajectoire, la sortie de plusieurs trajectoires prédites et la sortie de la trajectoire prédite la plus probable.
Il existe deux défis pour la prédiction de trajectoire à long terme :
- Il est déraisonnable de produire une trajectoire possible ou de produire toutes les trajectoires possibles. Si vous produisez une trajectoire prévue, vous risquez de manquer la trajectoire réelle. Si vous produisez toutes les trajectoires possibles, il y aura de fausses alarmes. Ceci est inacceptable pour les systèmes ADAS. Il convient d’envisager de limiter les trajectoires prévues à un sous-ensemble approprié.
- Plus vous faites de prédiction de trajectoire, plus vous devez faire d'hypothèses. Une hypothèse extrême consiste à supposer que tous les objets sur la route obéissent au code de la route. Ceci est raisonnable s’il est utilisé pour des fonctions de simulation de trafic, mais ne convient pas aux systèmes ADAS, qui doivent être sensibles aux situations potentiellement dangereuses.
L'incertitude qui affecte la prévision de trajectoire à long terme provient principalement de trois aspects :
- L'incertitude de l'estimation de l'état cible fournie par le module de détection.
- Incertitude dans la prédiction de l'intention de conduite.
- L'incertitude entre la reconnaissance d'intention et la mobilité des véhicules change.
3 Considérations principales
Quatre questions à prendre en compte pour le système de prédiction de trajectoire :
- La prédiction de trajectoire doit être sensible aux dangers potentiels, ce qui est requis par le sens de la prédiction de trajectoire.
- Il est nécessaire de prendre en compte à la fois le modèle de course et les informations sur l'intention et l'environnement.
- Considérez les incertitudes ci-dessus.
- Considérez le nombre de trajectoires de sortie.
4 Méthodes industrielles
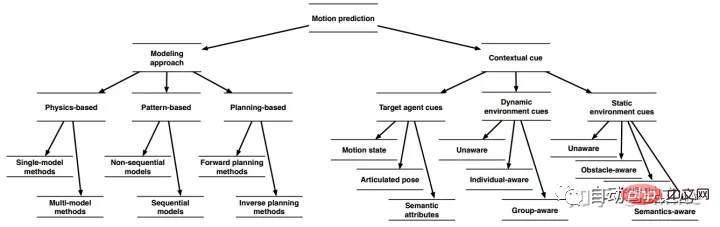
La figure suivante montre la méthode de classification dans l'article de synthèse [2] publié par Bosch.
- Si elles sont classées selon les différents modèles utilisés, les méthodes de prédiction de trajectoire peuvent être divisées en méthodes utilisant des modèles physiques, méthodes utilisant l'apprentissage et méthodes utilisant des algorithmes de planification.
- Si elles sont classées en fonction des informations utilisées, les méthodes de prédiction de trajectoire peuvent être divisées en méthodes qui utilisent des informations cibles, des méthodes qui utilisent des informations cibles dynamiques dans l'environnement et des méthodes qui utilisent des informations statiques sur l'environnement.
Quels algorithmes généraux sont spécifiquement impliqués dans la prédiction de trajectoire ?
- Prédiction d'intention : théorie floue, BN statiques, DBN (HMM, JumpMM), théorie des preuves DS, algorithme de classification en apprentissage automatique.
- Résultat de bout en bout lié au Deep Learning. CNN, LSTM, RNN, Attention.
Alors, quelles informations spécifiques peuvent être utilisées pour la prédiction de trajectoire ?
- Informations cibles : informations actuelles/historiques sur la vitesse et la position, s'il s'agit de prédiction de trajectoire du piéton, l'orientation de la tête du piéton, les informations sur les articulations, les informations sur le sexe et l'âge et les informations sur l'attention humaine peuvent également être utilisées.
- Informations cibles dynamiques dans l'environnement : informations sur la force sociale, l'attraction, la contrainte de groupe.
- Informations statiques sur l'environnement : espace libre, carte, informations sémantiques (structure routière/règles de circulation/feux tricolores actuels).
Il existe de plus en plus d'articles sur la prédiction de trajectoire dans le monde universitaire, la raison principale est qu'il n'existe pas de méthode efficace dans l'industrie.
Les articles suivants sont des articles de l'industrie :
BMW : modèle physique + prédiction d'intention (basée sur l'apprentissage). Utilisez des méthodes heuristiques pour intégrer les connaissances d'experts, simplifier le modèle d'interaction et ajouter des idées de théorie des jeux au modèle de classification de prédiction d'intention [3].
BENZ : Principalement des articles liés à la prédiction d'intention, en utilisant DBN[4].
Uber : LaneRCNN[5].
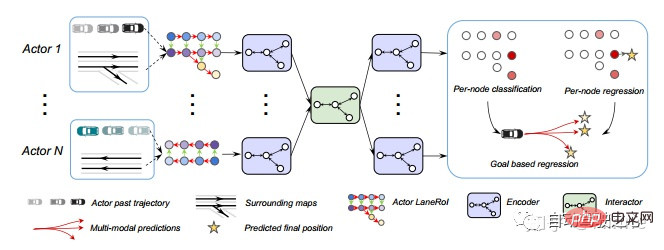
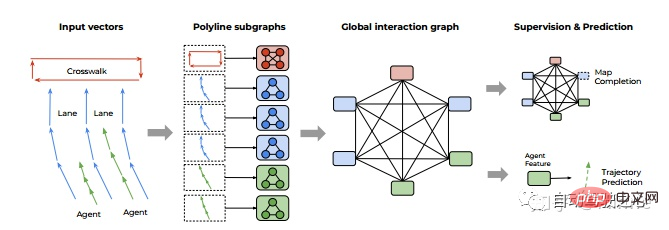
Google : VectorNet[6].
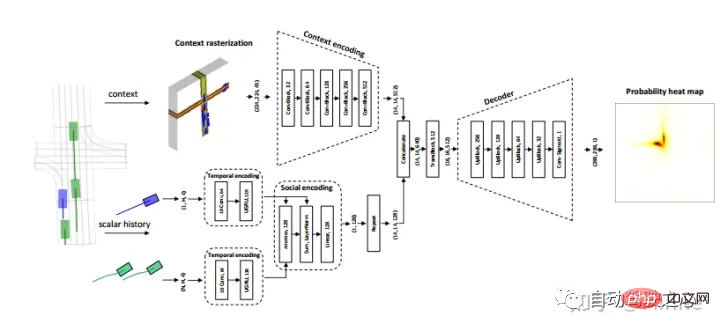
Huawei : ACCUEIL[7].
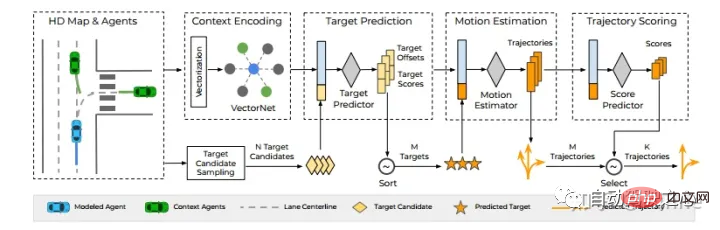
Waymo : TNT[8].
Aptive : Covernet[9].
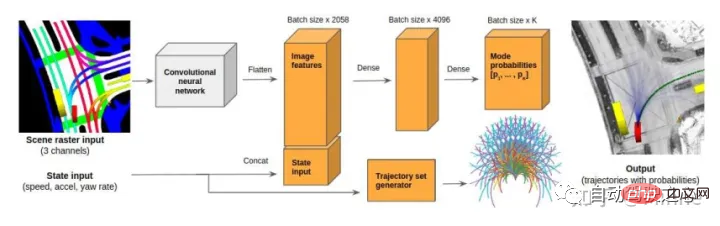
NEC : R2P2[10].
SenseTime : TPNet[11].
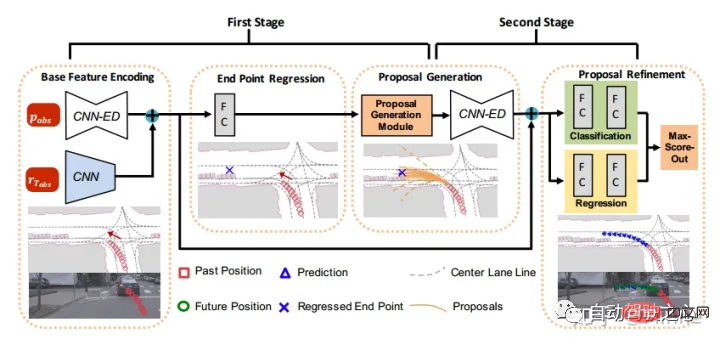
Meituan : StarNet[12]. piéton.
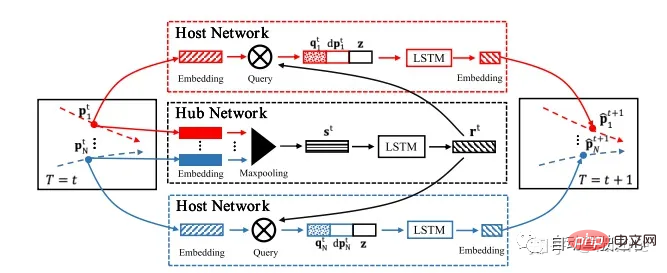
Aibee : Sophie[13]. piéton.
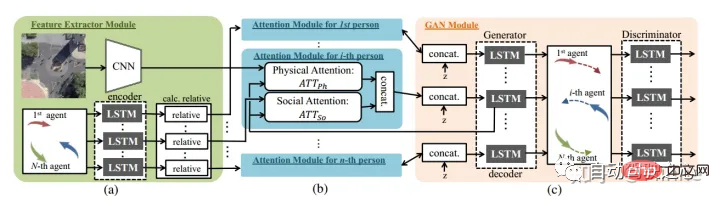
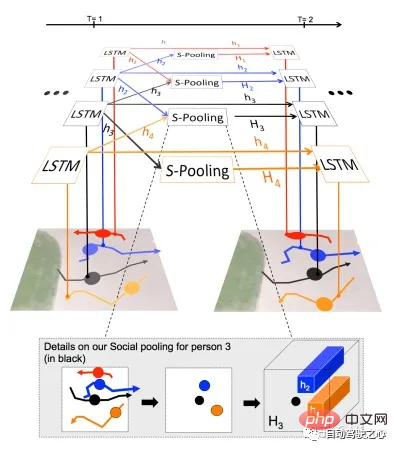
MIT : Social lstm[14]. piéton.
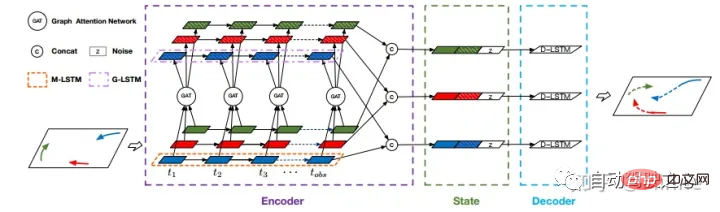
Université des sciences et technologies de Chine : STGAT[15]. piéton.
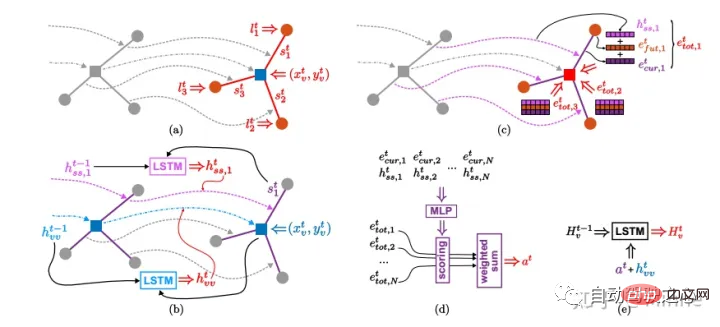
Baidu : Lane-Attention[16].
Apollo : Vous pouvez consulter le blog suivant pour référence.
https://www.cnblogs.com/liuzubing/p/11388485.html
Le module de prédiction d'Apollo reçoit les informations des modules de perception, de positionnement et de cartographie.
1. Premièrement, la scène a été divisée en deux scènes : une route de croisière ordinaire et une intersection.
2. Divisez ensuite l'importance des cibles perçues en cibles qui peuvent être ignorées (n'affecteront pas votre propre voiture), les cibles qui doivent être manipulées avec prudence (peuvent affecter votre propre voiture) et les cibles ordinaires (entre les deux).
3. Entrez ensuite l'évaluateur, qui est essentiellement une prédiction d'intention.

4. Entrez enfin le prédicteur, qui est utilisé pour prédire la génération de trajectoire. Effectuez différentes opérations pour différents scénarios tels que des cibles stationnaires, la conduite sur la route, freeMove et les intersections.

5 Ensemble de données
(1) NGSIM
Cet ensemble de données est constitué de données de conduite sur autoroute collectées par la FHWA aux États-Unis, y compris toutes les routes de l'US101, de l'I-80 et d'autres routes L'état de conduite du véhicule pendant une période donnée. Les données sont acquises à l'aide d'une caméra puis traitées un par un en enregistrements de points de trace. Son ensemble de données est un fichier CSV. Les données n'ont pas beaucoup de bruit.
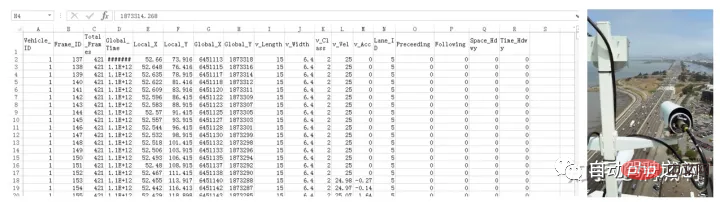
est plus d'informations au niveau global de répartition, telles que la planification des routes, le tracé des voies, l'ajustement de la circulation, etc. L'état cinématique du véhicule doit être extrait davantage. Le code de traitement peut être utilisé sur github ci-dessous.
https://github.com/nachiket92/conv-social-pooling
(2) INTERACTION
Cet ensemble de données a été développé par le Laboratoire de contrôle des systèmes mécaniques (MSC Lab) de l'Université de Californie à Berkeley, et des collaborateurs de l'Institut de technologie de Karlsruhe (KIT) et de l'ensemble de données sexuelles et collaboratives de MINES ParisTech (INTERACTION). Il peut reproduire avec précision un grand nombre de comportements interactifs des usagers de la route (tels que les véhicules et les piétons) dans divers scénarios de conduite dans différents pays.

http://www.interaction-dataset.com/
(3)apolloscape
Il s'agit de l'ensemble de données public de conduite autonome d'Apollo, qui comprend la prédiction de trajectoire. Données fournies . Le fichier interne est une séquence de données d'une minute à 2 images par seconde. La structure des données comprend l'ID du numéro de trame, l'ID de la cible, la catégorie de la cible, la position xyz, les informations sur la longueur, la largeur et la hauteur, ainsi que le cap. , vélos/véhicules électriques et autres.
https://apolloscape.auto/trajectory.html
(4) TRAF
Cet ensemble de données se concentre sur les conditions de circulation à haute densité, ce qui peut aider l'algorithme à mieux se concentrer sur l'analyse du comportement du conducteur humain dans des environnements incertains. Chaque cadre de données contient respectivement environ 13 véhicules à moteur, 5 piétons et 2 vélos
https://gamma.umd.edu/researchdirections/autonomousdriving/ad
Il existe de nombreuses utilisations pour cela dans le lien Projet de prédiction de trajectoire pour l'ensemble de données.
(5) nuScenes
La grande nouvelle arrive. Cet ensemble de données a été proposé en avril 2020. Il a collecté 1 000 scènes de conduite à Boston et à Singapour, deux villes à fort trafic et aux conditions de conduite difficiles. Son ensemble de données contient des articles connexes, vous pouvez y jeter un œil pour mieux comprendre cet ensemble de données.
https://arxiv.org/abs/1903.11027
Il y a des compétitions liées aux pronostics dans cet ensemble de données, vous pouvez les suivre.

https://www.nuscenes.org/prediction?externalData=all&mapData=all&modalities=Any
6 Métriques d'évaluation
Les métriques d'évaluation actuellement principalement utilisées sont des métriques géométriques.
Il existe de nombreux indicateurs de mesure géométrique, les principaux utilisés sont ADE, FDE et MR.
ADE est la distance euclidienne normalisée. FDE est la distance euclidienne entre les points de prédiction finaux. MR est le taux d'échec. Il existe de nombreux noms différents. L'essentiel est de définir un seuil. Si la distance euclidienne entre les points prédits est inférieure à cette prédiction, elle sera enregistrée comme une réussite. Si elle est supérieure à ce seuil, elle sera enregistrée comme. un échec. Enfin, un pourcentage sera calculé.
La métrique géométrique est un indicateur important pour mesurer la similarité entre la trajectoire prédite et la trajectoire réelle, et peut bien représenter la précision. Mais aux fins de la prédiction de trajectoire, cela n’a aucun sens de se contenter d’évaluer la précision. Il devrait également y avoir des mesures probabilistes pour évaluer l'incertitude, en particulier pour les distributions de résultats multimodales ; il devrait également y avoir des mesures au niveau des tâches, des mesures de robustesse et des évaluations d'efficacité.
Mesure de probabilité : la divergence KL, la probabilité prédite et la probabilité cumulée peuvent être utilisées comme mesure de probabilité. Par exemple, NLL, NLL basé sur KDE [17]. Métriques au niveau des tâches : évaluer l'impact de la prédiction de trajectoire sur la régulation back-end (piADE, piFDE) [18]. Robustesse : Tenez compte de la longueur ou de la durée de la partie observée de la trajectoire avant la prédiction ; de la taille des données d'entraînement ; de la fréquence d'échantillonnage des données d'entrée et du bruit du capteur ; de la généralisation du surajustement et de l'analyse de l'utilisation des entrées ; l'entrée d'entrée, si elle est garantie de fonctionner normalement et d'autres facteurs. Efficacité : pensez à la puissance de calcul.
Comme le montre la figure ci-dessous, la principale considération de cet article est que, sur la base de la vraie valeur (bleue), les trajectoires violettes et vertes prédites par la voiture cible grise ont les mêmes ADE et FDE si des métriques géométriques sont utilisées, mais différentes méthodes de prédiction ont La planification du véhicule aura un impact, mais il n'existe actuellement aucune mesure de ce type pour évaluer le niveau de tâche, ils ont donc proposé piADE et piFDE pour le faire.
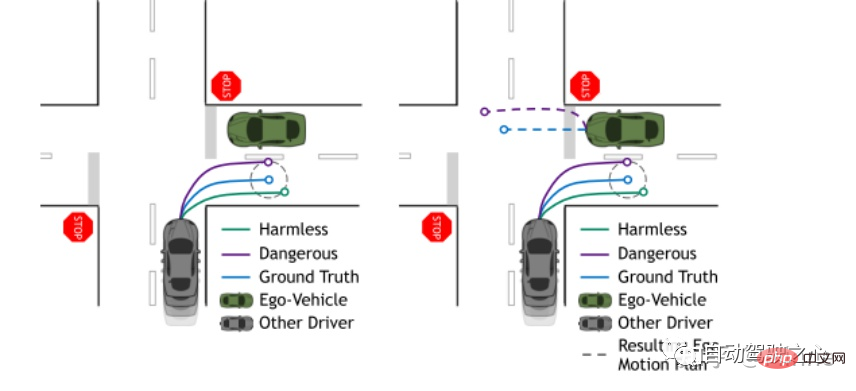
7 Trois questions
Question 1 : Trois méthodes de prédiction de trajectoire différentes : basées sur le modèle physique, basées sur l'apprentissage, basées sur la planification Où sont leurs scénarios d'application respectifs, et quels sont leurs avantages et. inconvénients ?
Différentes méthodes de modélisation peuvent combiner et exploiter différents types d'informations contextuelles. Toutes les méthodes de modélisation peuvent être étendues en utilisant les indices contextuels et les environnements dynamiques et statiques de la cible. Cependant, différentes méthodes de modélisation présentent différents niveaux de complexité et d'efficacité dans la combinaison de différentes catégories d'informations sémantiques.
1. Méthode basée sur un modèle physique
Scénarios applicables : les cibles, les environnements statiques et les simulations dynamiques peuvent être modélisés par des équations de transfert explicites.
Avantages :
- Les méthodes basées sur des modèles physiques peuvent être facilement appliquées dans tous les environnements en choisissant des équations de transfert appropriées sans avoir besoin de données d'entraînement, bien que certaines données pour l'estimation des paramètres soient utiles. Dans l'article, un simple modèle de CV produit également des résultats raisonnables.
- La méthode basée sur un modèle physique peut être facilement étendue en la combinant avec des indices d'agent cible.
Inconvénients :
- Cette approche de la modélisation explicite peut ne pas bien capturer la complexité du monde réel.
- L'équation de transfert manque d'informations globales dans l'espace et le temps, ce qui entraîne la possibilité d'obtenir une solution optimale locale.
De telles lacunes limitent l'utilisation de méthodes physiques à des prévisions à court terme ou à des environnements sans obstacles.
2. Méthode basée sur l'apprentissage
Scénarios applicables : convient aux environnements actuels avec des informations inconnues complexes (telles que les espaces publics avec une sémantique riche), et ces informations peuvent être utilisées pour une plage de prédiction relativement large.
Avantages :
- Les méthodes basées sur l'apprentissage peuvent potentiellement gérer tous les types d'informations contextuelles encodées dans l'ensemble de données collectées. Certains d'entre eux sont basés sur des cartes et d'autres peuvent être utilisés pour étendre davantage les informations contextuelles.
Inconvénients :
- Besoin de collecter suffisamment de données dans un endroit spécifique pour la formation.
- L'expansion des informations contextuelles peut entraîner des problèmes d'apprentissage, d'efficacité des données et de généralisation.
- Tendance à être utilisée dans des composants non critiques pour la sécurité. Dans ADAS, l'interprétabilité est plus importante, ce qui ne peut pas être obtenu par des méthodes basées sur l'apprentissage.
3. Méthode basée sur la planification
Scénarios applicables : elle a de bonnes performances dans les scénarios où le point final est déterminé et la carte de l'environnement est disponible.
Avantages :
- Si les deux conditions ci-dessus sont remplies, il peut obtenir une meilleure précision que les méthodes physiques et de meilleures capacités de généralisation que les méthodes basées sur l'apprentissage.
Inconvénients :
- Algorithmes de planification traditionnels : Dijkstra, Fast Marching Method, les planificateurs de mouvements optimaux basés sur l'échantillonnage connaîtront une croissance exponentielle à mesure que le nombre de cibles, la taille de l'environnement et la plage de prédiction augmentent.
- Comparés aux modèles simples basés sur la physique, les paramètres des méthodes de planification basées sur le contexte (telles que les fonctions de récompense pour la programmation inverse et les modèles pour la programmation directe) sont triviaux et généralement plus faciles à apprendre, mais en termes de raisonnement, pour un état d'agent de dimension élevée (cible), faible efficacité.
Les méthodes basées sur la planification sont essentiellement sensibles aux cartes et aux obstacles, et sont naturellement étendues à l'aide d'indices sémantiques. En règle générale, ils codent la complexité de la situation dans l’équation objectif/récompense, mais cela peut ne pas intégrer correctement les entrées de ligne dynamiques. Par conséquent, les auteurs ont dû concevoir des modifications spécifiques pour incorporer des entrées dynamiques dans l’algorithme de prédiction (processus de saut de Markov, adaptations locales de la trajectoire prédite, théorie des jeux). Contrairement aux méthodes basées sur l’apprentissage, les entrées cibles peuvent être facilement fusionnées car les processus de planification avant et arrière sont basés sur le même modèle dynamique cible.
Question 2 : Le problème de la prédiction de trajectoire est-il désormais résolu ?
Le besoin de prédiction de trajectoire dépend en grande partie du domaine d'application et des scénarios d'utilisation spécifiques qui y sont associés. On ne peut pas dire que le problème de la prédiction de trajectoire soit résolu à court terme. Prenons l'exemple de l'industrie automobile. Parce qu'il existe des normes et des réglementations spéciales qui définissent la vitesse maximale, les règles de circulation, la vitesse des piétons et la répartition des accélérations, ainsi que les spécifications relatives aux taux d'accélération/décélération confortables du véhicule, elle semble être la plus puissante pour formuler des exigences et proposer des solutions. On peut dire que pour la fonction AEB des voitures intelligentes, la solution a atteint un niveau de performance permettant la production industrielle de produits de consommation, et les cas d'utilisation requis ont été résolus. Comme pour d’autres cas d’utilisation, davantage de standardisation et une articulation claire des exigences seront nécessaires dans un avenir proche. Et il faut encore évoluer pour gagner en robustesse et en stabilité.
Donc, avant de répondre si la prédiction de trajectoire a résolu ce problème, nous devrions au moins fixer la norme.
Actuellement dans le domaine de la robotique
- les méthodes basées sur des modèles physiques et l'apprentissage peuvent atteindre une plus grande précision en peu de temps (1-2 s). Il est très approprié pour la planification de mouvements locaux et pour éviter les collisions des foules. Le modèle CV le plus simple a un bon effet sur la planification locale du robot. Si l’on considère l’interaction entre les piétons et l’impact de la présence de robots sur les mouvements des piétons, il existe de nombreux algorithmes avancés.
- Il existe de grands défis pour la planification d'un chemin global qui doit prévoir 15 à 20 secondes. Les exigences peuvent être assouplies de manière appropriée, et il devient très important de comprendre l'entrée de contexte dynamique et statique (qui affecte l'opération à long terme, le raisonnement sur la carte de l'environnement et l'inférence intentionnelle de la cible). Pour la planification de trajectoires locales et globales, les méthodes indépendantes de la position sont les mieux adaptées pour prédire le mouvement dans divers environnements.
- Le robot actuel prédit un ADE de 0,19 à 0,4 m en 4,8 s. Un modèle de vitesse simple peut également atteindre un ADE de 0,53 m. 9s prédit un ADE de 1,4 à 2 millions.
Actuellement dans le domaine de la conduite autonome :
- La plupart des travaux considèrent les piétons qui traversent la route : commencer à marcher, continuer à marcher, arrêter de marcher.
- Vélo : un cycliste s'approche d'une intersection avec jusqu'à cinq directions routières différentes derrière lui.
Question 3 : Les techniques d'évaluation actuelles pour mesurer les performances de prédiction de trajectoire sont-elles suffisamment bonnes ?
Il existe actuellement un manque d'approche systématique des algorithmes de prédiction, en particulier pour les méthodes de prédiction de trajectoire qui prennent en compte les entrées contextuelles et prédisent un nombre arbitraire de cibles.
La plupart des auteurs n'utilisent désormais que les métriques géométriques (AED, FDE) comme indicateur pour mesurer la qualité d'un algorithme. Cependant, pour les prévisions à long terme, les prévisions sont souvent multimodales et associées à une incertitude, et l'évaluation des performances de ces méthodes doit utiliser des mesures qui en tiennent compte, telles que le log de vraisemblance négative ou le logarithme obtenu à partir de la perte KLD.
Il existe également un besoin de mesures probabilistes qui reflètent mieux le caractère aléatoire du mouvement humain et l'incertitude impliquée dans les imperfections de perception.
Il existe également une évaluation de la robustesse, qui doit prendre en compte la stabilité du système lorsque des erreurs de détection, des défauts de suivi, une incertitude d'auto-positionnement ou des changements de carte se produisent du côté de la détection.
Dans le même temps, bien que les ensembles de données actuellement utilisés contiennent des scénarios très complets, ces ensembles de données sont généralement annotés de manière semi-automatique et ne peuvent donc fournir que des estimations de valeurs réelles incomplètes et bruitées. De plus, la longueur de la trajectoire est souvent insuffisante dans certains domaines d’application où des prévisions à long terme sont nécessaires. Enfin, l’interaction entre les cibles dans l’ensemble de données est généralement limitée. Par exemple, dans un environnement clairsemé, il est difficile pour les cibles de s’influencer mutuellement.
Pour résumer : afin d'évaluer la qualité des prédictions, les chercheurs doivent choisir des ensembles de données plus complexes (incluant des obstacles non convexes, des trajectoires longues et des interactions complexes) et des métriques complètes (géométrie + probabilité). Une meilleure méthode consiste à définir différentes exigences de précision en fonction de différents temps de prédiction, de différentes périodes d'observation et de différentes complexités de scène. Et il devrait y avoir une évaluation de la robustesse et une évaluation en temps réel. De plus, il devrait y avoir des indicateurs pertinents permettant de mesurer l'impact des systèmes ADAS sur le backend [18] et des indicateurs mesurant la sensibilité aux scénarios dangereux [1].
8 Future Directions
vient de la discussion dans [2], cité ici.
La tendance actuelle est d'utiliser des méthodes plus complexes pour surpasser la méthode d'utilisation d'un modèle unique + KF
Direction :
- Utiliser des informations contextuelles améliorées : des informations sémantiques plus profondes peuvent être utilisées, cette information sémantique devrait permettre une meilleure compréhension des environnements statiques. Et l'utilisation actuelle de fonctionnalités sémantiques pour la prédiction de trajectoires doit encore être développée
- Concernant les scénarios socialement conscients : ① La plupart des méthodes actuelles supposent que les comportements de toutes les personnes observées sont similaires et que leurs mouvements peuvent être déterminés par les mêmes modèles. et les mêmes caractéristiques à prédire, alors que la capture et l'inférence d'attributs sociaux de haut niveau en sont encore aux premiers stades de développement. ② La plupart des méthodes réalisables reposent sur l'hypothèse que le comportement coopératif entre les personnes et les personnes réelles peut être plus enclin à optimiser les objectifs individuels plutôt que les stratégies communes, de sorte que la méthode combinant l'IA traditionnelle et la théorie des jeux est très prometteuse.
- Pour les prédictions à long terme, les informations contextuelles deviennent particulièrement importantes car l'intention est considérée en fonction du contexte et des circonstances environnantes. De nombreuses méthodes actuelles basées sur l’apprentissage traitent les individus comme des particules et les utilisent pour apprendre à transférer des informations afin de déterminer la direction du mouvement futur. L'extension de ces modèles avec des prédictions davantage basées sur l'intention, similaires au comportement humain orienté vers un objectif, bénéficiera aux prédictions à long terme.
- La plupart des méthodes basées sur la planification s'appuient sur un ensemble d'objectifs donnés, ce qui les rend inutilisables ou imprécis sans connaissance préalable des destinations ou lorsque le nombre de destinations possibles est trop élevé. Cela rend importante l’inférence automatique des points de terminaison de destination basée sur des informations sémantiques. Ou encore, il peut identifier dynamiquement des destinations possibles dans l'environnement et effectuer une prédiction de trajectoire sur cette base. Cela permet d'utiliser des méthodes basées sur la planification dans des environnements inconnus.
- Les méthodes actuelles se concentrent sur la résolution d'un type spécifique de tâches, par exemple lorsqu'il existe des modèles de mouvement évidents dans l'environnement, ou lorsque la structure spatiale de l'environnement et la destination de l'agent cible sont connues à l'avance. Les méthodes de prédiction de trajectoire doivent être capables de s’adapter à des environnements indéfinis/changeants et de gérer des situations inattendues. Cela nécessite un apprentissage par transfert et certaines méthodes pour faire face à de nouveaux environnements, où l'apprentissage et le raisonnement sur des règles immuables de base, ou sur le comportement général des piétons ou sur l'évitement des collisions ne sont pas appropriés. L'adaptation de domaine peut être utilisée pour apprendre des modèles de généralisation.
- Autre direction à laquelle prêter attention : la robustesse et l'intégrabilité.
Pour résumer : pour faire simple, les informations contextuelles doivent être utilisées plus en profondeur, il est préférable d'avoir différents modèles de comportement pour différents objectifs, une théorie des jeux, une prédiction d'intention plus robuste basée sur plus d'informations et une inférence automatique de le point final, les problèmes de généralisation à de nouveaux environnements, de robustesse et d’intégrabilité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La multiplication matricielle universelle de CUDA : de l'entrée à la maîtrise !
Mar 25, 2024 pm 12:30 PM
La multiplication matricielle universelle de CUDA : de l'entrée à la maîtrise !
Mar 25, 2024 pm 12:30 PM
La multiplication matricielle générale (GEMM) est un élément essentiel de nombreuses applications et algorithmes, et constitue également l'un des indicateurs importants pour évaluer les performances du matériel informatique. Une recherche approfondie et l'optimisation de la mise en œuvre de GEMM peuvent nous aider à mieux comprendre le calcul haute performance et la relation entre les systèmes logiciels et matériels. En informatique, une optimisation efficace de GEMM peut augmenter la vitesse de calcul et économiser des ressources, ce qui est crucial pour améliorer les performances globales d’un système informatique. Une compréhension approfondie du principe de fonctionnement et de la méthode d'optimisation de GEMM nous aidera à mieux utiliser le potentiel du matériel informatique moderne et à fournir des solutions plus efficaces pour diverses tâches informatiques complexes. En optimisant les performances de GEMM
 Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le 29 juillet, lors de la cérémonie de lancement de la 400 000e nouvelle voiture d'AITO Wenjie, Yu Chengdong, directeur général de Huawei, président de Terminal BG et président de la BU Smart Car Solutions, a assisté et prononcé un discours et a annoncé que les modèles de la série Wenjie seraient sera lancé cette année En août, la version Huawei Qiankun ADS 3.0 a été lancée et il est prévu de pousser successivement les mises à niveau d'août à septembre. Le Xiangjie S9, qui sortira le 6 août, lancera le système de conduite intelligent ADS3.0 de Huawei. Avec l'aide du lidar, la version Huawei Qiankun ADS3.0 améliorera considérablement ses capacités de conduite intelligente, disposera de capacités intégrées de bout en bout et adoptera une nouvelle architecture de bout en bout de GOD (identification générale des obstacles)/PDP (prédictive prise de décision et contrôle), fournissant la fonction NCA de conduite intelligente d'une place de stationnement à l'autre et mettant à niveau CAS3.0
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Quelle version du système Apple 16 est la meilleure ?
Mar 08, 2024 pm 05:16 PM
Quelle version du système Apple 16 est la meilleure ?
Mar 08, 2024 pm 05:16 PM
La meilleure version du système Apple 16 est iOS16.1.4. La meilleure version du système iOS16 peut varier d'une personne à l'autre. Les ajouts et améliorations de l'expérience d'utilisation quotidienne ont également été salués par de nombreux utilisateurs. Quelle version du système Apple 16 est la meilleure ? Réponse : iOS16.1.4 La meilleure version du système iOS 16 peut varier d'une personne à l'autre. Selon les informations publiques, iOS16, lancé en 2022, est considéré comme une version très stable et performante, et les utilisateurs sont plutôt satisfaits de son expérience globale. De plus, l'ajout de nouvelles fonctionnalités et les améliorations de l'expérience d'utilisation quotidienne dans iOS16 ont également été bien accueillies par de nombreux utilisateurs. Surtout en termes de durée de vie de la batterie mise à jour, de performances du signal et de contrôle du chauffage, les retours des utilisateurs ont été relativement positifs. Cependant, compte tenu de l'iPhone14
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
