
 Périphériques technologiques
IA
Nouvelle recherche DeepMind : le transformateur peut s'améliorer sans intervention humaine
Périphériques technologiques
IA
Nouvelle recherche DeepMind : le transformateur peut s'améliorer sans intervention humaine
Nouvelle recherche DeepMind : le transformateur peut s'améliorer sans intervention humaine

Actuellement, les Transformers sont devenus une puissante architecture de réseau neuronal pour la modélisation de séquences. Une propriété notable des transformateurs pré-entraînés est leur capacité à s'adapter aux tâches en aval grâce au conditionnement des signaux ou à l'apprentissage contextuel. Après une pré-formation sur de grands ensembles de données hors ligne, il a été démontré que les transformateurs à grande échelle se généralisent efficacement aux tâches en aval de complétion de texte, de compréhension du langage et de génération d'images.
Des travaux récents ont montré que les transformateurs peuvent également apprendre des politiques à partir de données hors ligne en traitant l'apprentissage par renforcement (RL) hors ligne comme un problème de prédiction séquentielle. Les travaux de Chen et al. (2021) ont montré que les transformateurs peuvent apprendre des politiques à tâche unique à partir de données RL hors ligne grâce à l'apprentissage par imitation, et des travaux ultérieurs ont montré que les transformateurs peuvent extraire des politiques multitâches dans des contextes de même domaine et inter-domaines. Ces travaux démontrent tous le paradigme d'extraction de politiques générales multitâches, qui consiste d'abord à collecter des ensembles de données d'interaction environnementale diversifiées et à grande échelle, puis à extraire des politiques à partir des données via une modélisation séquentielle. Cette méthode d'apprentissage des politiques à partir de données RL hors ligne via l'apprentissage par imitation est appelée distillation des politiques hors ligne (Offline Policy Distillation) ou distillation des politiques (Policy Distillation, PD).
PD offre simplicité et évolutivité, mais l'un de ses gros inconvénients est que les politiques générées ne s'améliorent pas progressivement avec des interactions supplémentaires avec l'environnement. Par exemple, l'agent généraliste Multi-Game Decision Transformers de Google a appris une politique de retour conditionnée qui peut jouer à de nombreux jeux Atari, tandis que l'agent généraliste de DeepMind, Gato, a appris une solution à divers problèmes grâce à des stratégies de raisonnement contextuel pour les tâches dans l'environnement. Malheureusement, aucun des deux agents ne peut améliorer la politique dans son contexte par essais et erreurs. Par conséquent, la méthode PD apprend les politiques plutôt que les algorithmes d’apprentissage par renforcement.
Dans un récent article de DeepMind, les chercheurs ont émis l'hypothèse que la raison pour laquelle la PD n'a pas réussi à s'améliorer par essais et erreurs était que les données utilisées pour la formation ne pouvaient pas montrer les progrès de l'apprentissage. Les méthodes actuelles apprennent soit une politique à partir de données qui ne contiennent pas d'apprentissage (par exemple une politique d'expert fixe via distillation), soit apprennent une politique à partir de données qui contiennent de l'apprentissage (par exemple le tampon de relecture d'un agent RL), mais la taille du contexte de ce dernier ( trop petit) Incapacité à prendre en compte les améliorations politiques.

Adresse papier : https://arxiv.org/pdf/2210.14215.pdf
La principale observation du chercheur est que la nature séquentielle de l'apprentissage dans la formation aux algorithmes RL peut en principe être un apprentissage par renforcement lui-même est modélisé comme un problème de prédiction de séquence causale. Plus précisément, si le contexte d'un transformateur est suffisamment long pour inclure les améliorations de politique apportées par les mises à jour d'apprentissage, alors il devrait non seulement être capable de représenter une politique fixe, mais également être capable de représenter un algorithme d'amélioration de politique en se concentrant sur les états. , actions et récompenses des épisodes précédents. Cela ouvre la possibilité que n'importe quel algorithme RL puisse être distillé en modèles de séquence suffisamment puissants tels que des transformateurs grâce à l'apprentissage par imitation, et ces modèles peuvent être convertis en algorithmes RL contextuels.
Les chercheurs ont proposé la distillation d'algorithmes (AD), qui est une méthode d'apprentissage des opérateurs d'amélioration des politiques contextuelles en optimisant la perte de prédiction de séquence causale dans l'historique d'apprentissage des algorithmes RL. Comme le montre la figure 1 ci-dessous, AD se compose de deux parties. Un grand ensemble de données multitâches est d'abord généré en enregistrant l'historique d'entraînement d'un algorithme RL sur un grand nombre de tâches individuelles, puis le modèle de transformateur modélise de manière causale les actions en utilisant l'historique d'apprentissage précédent comme contexte. Étant donné que la politique continue de s'améliorer au cours de la formation de l'algorithme RL source, AD doit apprendre des opérateurs améliorés afin de modéliser avec précision les actions à tout moment donné de l'historique de formation. Il est essentiel que le contexte du transformateur soit suffisamment vaste (c'est-à-dire sur plusieurs épisodes) pour capturer les améliorations des données d'entraînement.
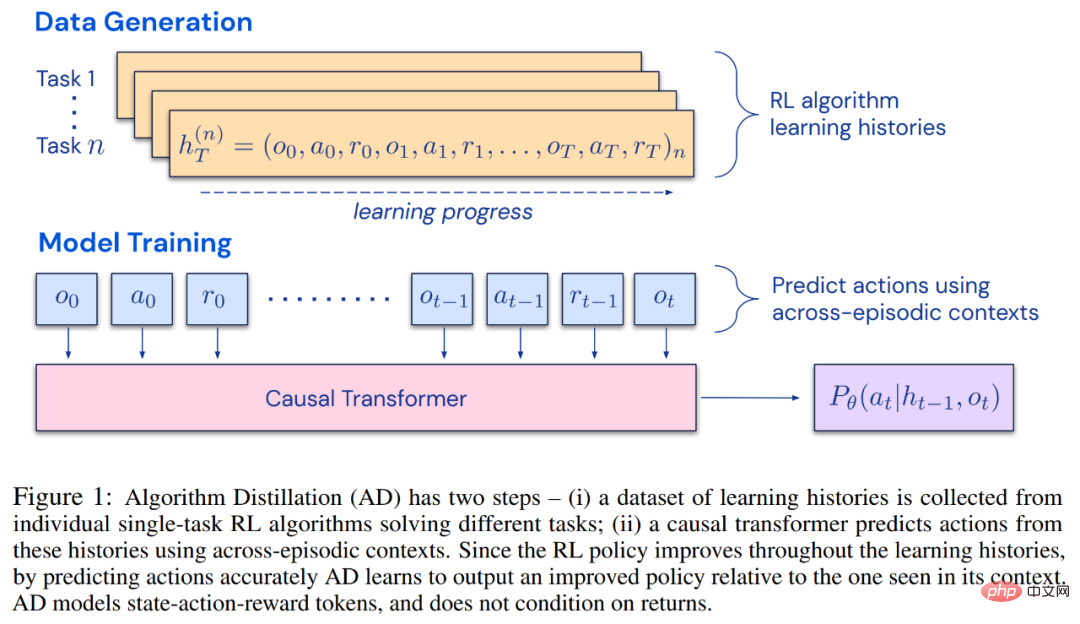
Les chercheurs ont déclaré qu'en utilisant un transformateur causal avec un contexte suffisamment grand pour imiter l'algorithme RL basé sur le gradient, AD peut renforcer pleinement l'apprentissage de nouvelles tâches dans le contexte. Nous avons évalué AD dans un certain nombre d'environnements partiellement observables nécessitant une exploration, y compris Watermaze basé sur des pixels de DMLab, et avons montré qu'AD est capable d'exploration de contexte, d'attribution de confiance temporelle et de généralisation. De plus, l’algorithme appris par AD est plus efficace que l’algorithme qui a généré les données sources d’entraînement du transformateur.
Enfin, il convient de noter que AD est la première méthode pour démontrer l'apprentissage par renforcement contextuel en modélisant séquentiellement des données hors ligne avec perte d'imitation.
Méthode
Au cours de son cycle de vie, un agent d'apprentissage par renforcement doit être performant dans l'exécution d'actions complexes. Pour un agent intelligent, quels que soient son environnement, sa structure interne et son exécution, il peut être considéré comme achevé sur la base de l'expérience passée. Elle peut s'exprimer sous la forme suivante :
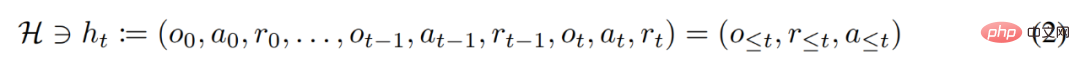
Le chercheur a également considéré la stratégie « conditionnée par une longue histoire » comme un algorithme et en est arrivé à :

où Δ(A) représente l'action Espace de distribution de probabilité sur l'espace A. L'équation (3) montre que l'algorithme peut être déployé dans l'environnement pour générer des séquences d'observations, de récompenses et d'actions. Par souci de simplicité, cette étude désigne l'algorithme par P et l'environnement (c'est-à-dire la tâche) par  . L'historique d'apprentissage est désigné par l'algorithme
. L'historique d'apprentissage est désigné par l'algorithme  , de sorte que pour toute tâche donnée
, de sorte que pour toute tâche donnée 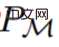 est généré. Il peut être obtenu
est généré. Il peut être obtenu
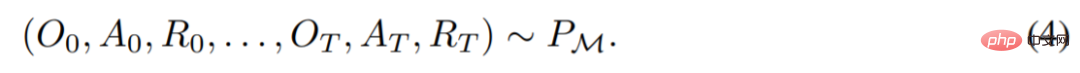
Les chercheurs utilisent des lettres latines majuscules pour représenter des variables aléatoires, telles que O, A, R et leurs formes minuscules correspondantes o, α, r. En considérant les algorithmes comme des politiques à long terme conditionnées par l’histoire, ils ont émis l’hypothèse que tout algorithme générant un historique d’apprentissage peut être converti en un réseau neuronal en effectuant un clonage comportemental d’actions. Ensuite, l'étude propose une approche qui fournit aux agents un apprentissage à vie de modèles de séquence avec des clones comportementaux pour mapper l'historique à long terme aux distributions d'actions.
Mise en œuvre réelle
En pratique, cette recherche met en œuvre la distillation algorithmique (AD) en deux étapes. Premièrement, un ensemble de données d’historique d’apprentissage est collecté en exécutant des algorithmes RL individuels basés sur un gradient sur de nombreuses tâches différentes. Ensuite, un modèle de séquence avec un contexte multi-épisodes est formé pour prédire les actions dans l'histoire. L'algorithme spécifique est le suivant :

Expériences
Les expériences nécessitent que l'environnement utilisé prenne en charge de nombreuses tâches qui ne peuvent pas être facilement déduites des observations, et les épisodes sont suffisamment courts pour former efficacement des transformateurs causals inter-épisodiques. L'objectif principal de ce travail était d'étudier dans quelle mesure le renforcement AD est appris dans son contexte par rapport aux travaux antérieurs. L'expérience a comparé AD, ED (Expert Distillation), RL^2, etc.
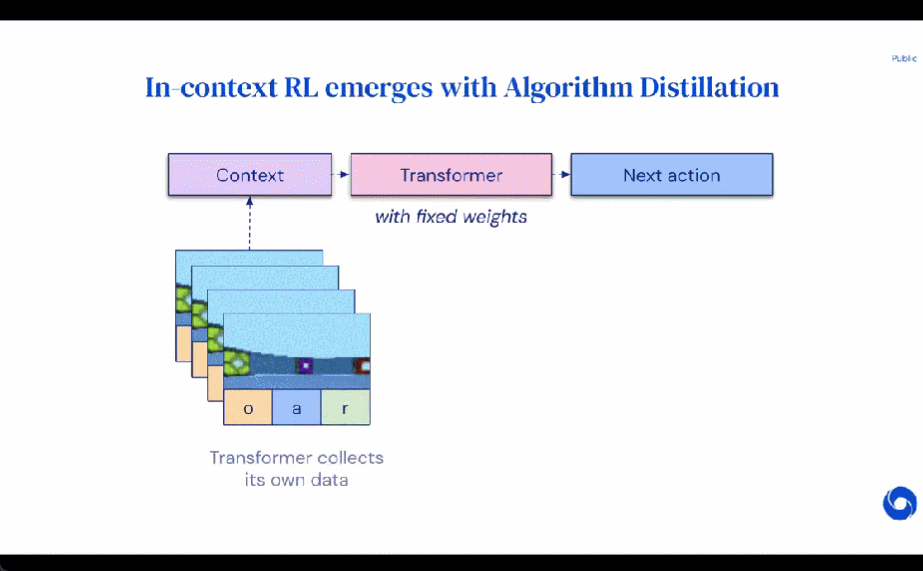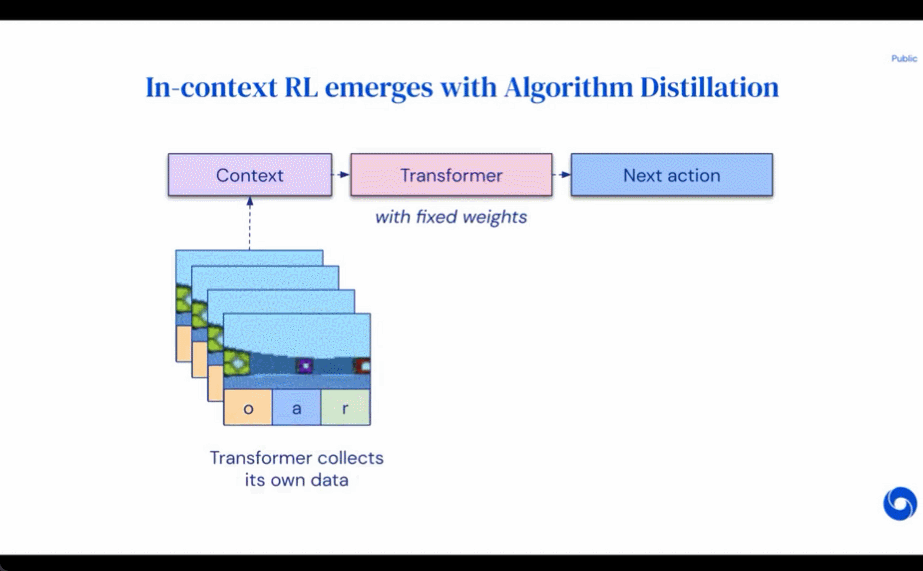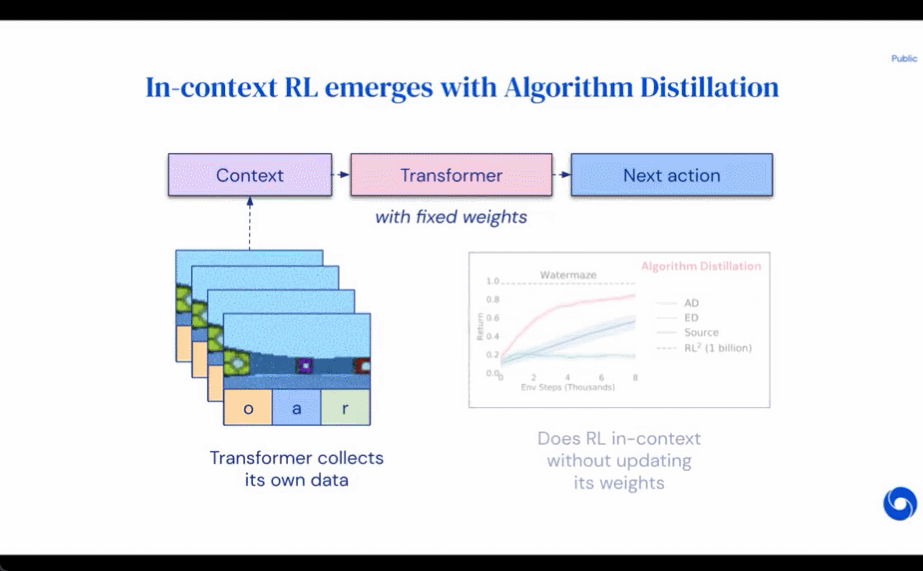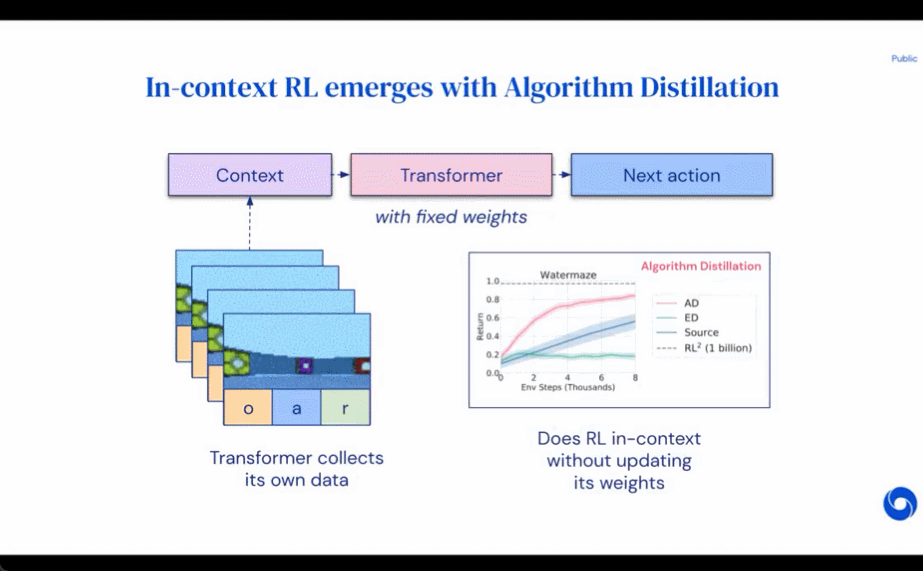
Les résultats de l'évaluation de AD, ED et RL^2 sont présentés dans la figure 3. L'étude a révélé que AD et RL^2 peuvent apprendre contextuellement sur des tâches échantillonnées dans la distribution de formation, alors que ED ne le peuvent pas, bien que ED fasse mieux que les suppositions aléatoires lorsqu'il est évalué au sein d'une distribution.
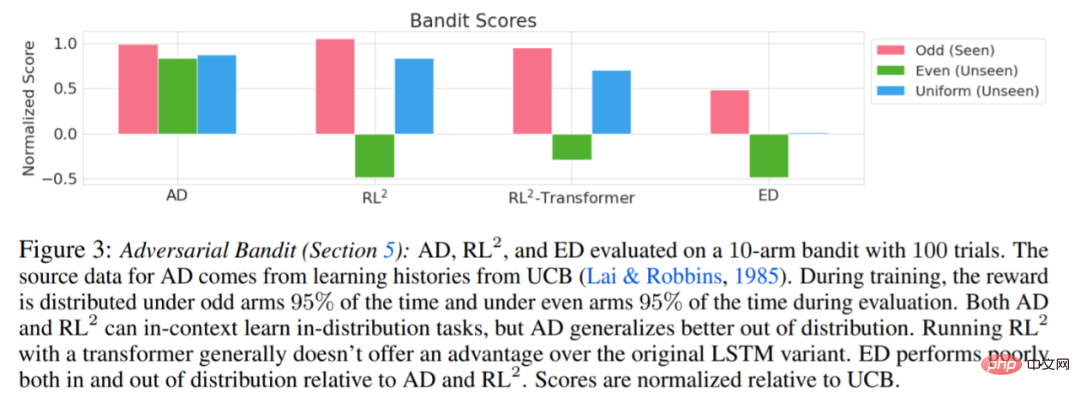
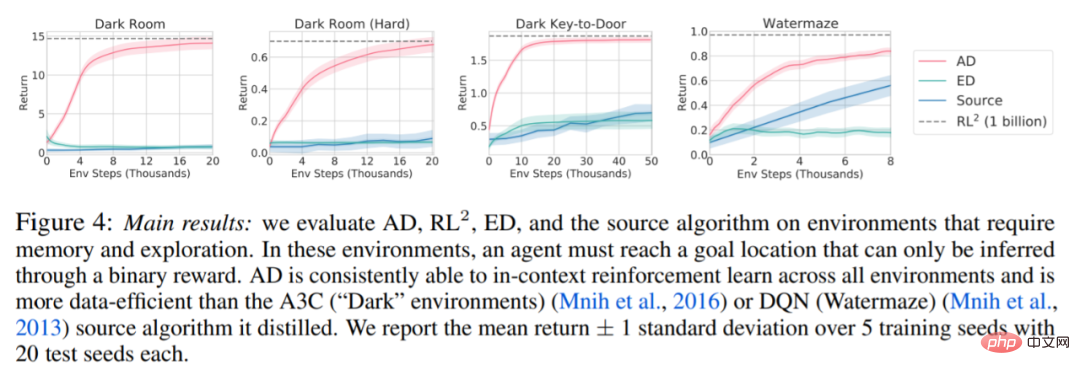
Concernant la figure 4 ci-dessous, le chercheur a répondu à une série de questions. AD présente-t-il un apprentissage par renforcement contextuel ? Les résultats montrent que l’apprentissage par renforcement contextuel AD peut apprendre dans tous les environnements, en revanche, ED ne peut pas explorer et apprendre en contexte dans la plupart des situations.
AD peut-il apprendre des observations basées sur les pixels ? Les résultats montrent que AD maximise la régression épisodique via RL contextuelle, tandis que ED ne parvient pas à apprendre.
AD Est-il possible d'apprendre un algorithme RL plus efficace que l'algorithme qui a généré les données sources ? Les résultats montrent que l’efficacité des données d’AD est nettement supérieure à celle des algorithmes sources (A3C et DQN).
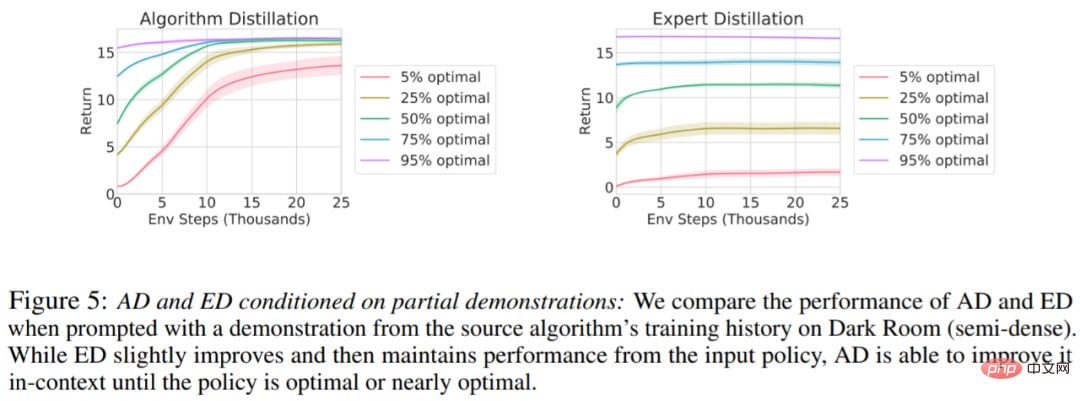
Est-il possible d'accélérer AD via des démos ? Pour répondre à cette question, cette étude conserve la stratégie d'échantillonnage à différents moments de l'historique de l'algorithme source dans les données de l'ensemble de test, puis utilise ces données de stratégie pour pré-remplir le contexte de AD et ED, et exécute les deux méthodes dans le contexte de Dark Room, les résultats sont tracés dans la figure 5. Tandis que ED maintient les performances de la stratégie d’entrée, AD améliore chaque stratégie dans son contexte jusqu’à ce qu’elle soit proche de l’optimum. Il est important de noter que plus la stratégie d’entrée est optimisée, plus AD l’améliore rapidement jusqu’à atteindre l’optimalité.
Pour plus de détails, veuillez vous référer au document original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Comment utiliser la fonction de filtre Excel avec plusieurs conditions
Feb 26, 2024 am 10:19 AM
Comment utiliser la fonction de filtre Excel avec plusieurs conditions
Feb 26, 2024 am 10:19 AM
Si vous avez besoin de savoir comment utiliser le filtrage avec plusieurs critères dans Excel, le didacticiel suivant vous guidera à travers les étapes pour vous assurer que vous pouvez filtrer et trier efficacement vos données. La fonction de filtrage d'Excel est très puissante et peut vous aider à extraire les informations dont vous avez besoin à partir de grandes quantités de données. Cette fonction peut filtrer les données en fonction des conditions que vous définissez et afficher uniquement les pièces qui remplissent les conditions, rendant la gestion des données plus efficace. En utilisant la fonction de filtre, vous pouvez trouver rapidement des données cibles, ce qui vous fait gagner du temps dans la recherche et l'organisation des données. Cette fonction peut non seulement être appliquée à de simples listes de données, mais peut également être filtrée en fonction de plusieurs conditions pour vous aider à localiser plus précisément les informations dont vous avez besoin. Dans l’ensemble, la fonction de filtrage d’Excel est très utile
 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Mais peut-être qu’il ne pourra pas vaincre le vieil homme dans le parc ? Les Jeux Olympiques de Paris battent leur plein et le tennis de table suscite beaucoup d'intérêt. Dans le même temps, les robots ont également réalisé de nouvelles avancées dans le domaine du tennis de table. DeepMind vient tout juste de proposer le premier agent robot apprenant capable d'atteindre le niveau des joueurs amateurs humains de tennis de table de compétition. Adresse papier : https://arxiv.org/pdf/2408.03906 Quelle est la capacité du robot DeepMind à jouer au tennis de table ? Probablement à égalité avec les joueurs amateurs humains : tant en coup droit qu'en revers : l'adversaire utilise une variété de styles de jeu, et le robot peut également résister : recevoir des services avec des tours différents : Cependant, l'intensité du jeu ne semble pas aussi intense que le vieil homme dans le parc. Pour les robots, le tennis de table
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
