
 Périphériques technologiques
IA
Une équipe chinoise a développé avec succès l'IA pour prédire les médicaments appropriés pour les patients atteints de cancer, et les résultats ont été publiés dans la revue Nature.
Périphériques technologiques
IA
Une équipe chinoise a développé avec succès l'IA pour prédire les médicaments appropriés pour les patients atteints de cancer, et les résultats ont été publiés dans la revue Nature.
Une équipe chinoise a développé avec succès l'IA pour prédire les médicaments appropriés pour les patients atteints de cancer, et les résultats ont été publiés dans la revue Nature.

Avec une seule IA, les réponses cliniques de 9 808 patients atteints de cancer aux médicaments peuvent être entièrement prédites.
Et les résultats sont cohérents avec les observations cliniques.
Il s'agit du dernier résultat CODE-AE (autoencodeur déconfondant sensible au contexte) apporté par l'équipe de Lei Xie à la City University de New York.

Il propose un nouveau modèle d'auto-encodage contextuel capable de prédire les réponses spécifiques de différents patients aux médicaments.
Cela aura un impact significatif sur le développement de nouveaux médicaments et les essais cliniques.
Vous devez savoir que dans le modèle traditionnel, il faut près de 10 ans pour qu'un nouveau médicament soit développé, testé et entièrement lancé, et les fonds consommés sont d'une ampleur sans précédent, atteignant facilement 1 milliard de dollars américains.
Le cycle est si long parce que la réaction des nouveaux médicaments dans le corps humain est difficile à prédire et des essais répétés sont souvent nécessaires pour les tests.
Et si l’IA peut utiliser les données pour faire des prédictions, elle réduira considérablement les délais de commercialisation des nouveaux médicaments et réduira les coûts.
Actuellement, cette recherche a été publiée dans la sous-revue Nature "Nature Machine Intelligence".
En termes simples, CODE-AE utilise les données issues de la validation cellulaire in vitro de nouveaux médicaments pour prédire la réponse du médicament dans le corps humain.
Cela évite la dépendance de la formation des modèles d'IA aux données cliniques des patients.
La principale raison pour laquelle l'IA n'a pas été très efficace dans la prédiction de la réponse clinique dans le passé est qu'il est trop difficile de collecter des données massives et continues sur la réponse clinique.
Du point de vue du mécanisme, les chercheurs divisent les biomarqueurs des médicaments en domaines source et domaine cible.
Le domaine source représente un domaine différent de l'échantillon de test, mais contient de riches informations de supervision, qui peuvent être comprises comme des données de vérification cellulaire in vitro.
Le domaine cible est le domaine où se trouve l'échantillon de test. Il n'a pas d'étiquettes ou seulement quelques étiquettes, c'est-à-dire les données du patient.
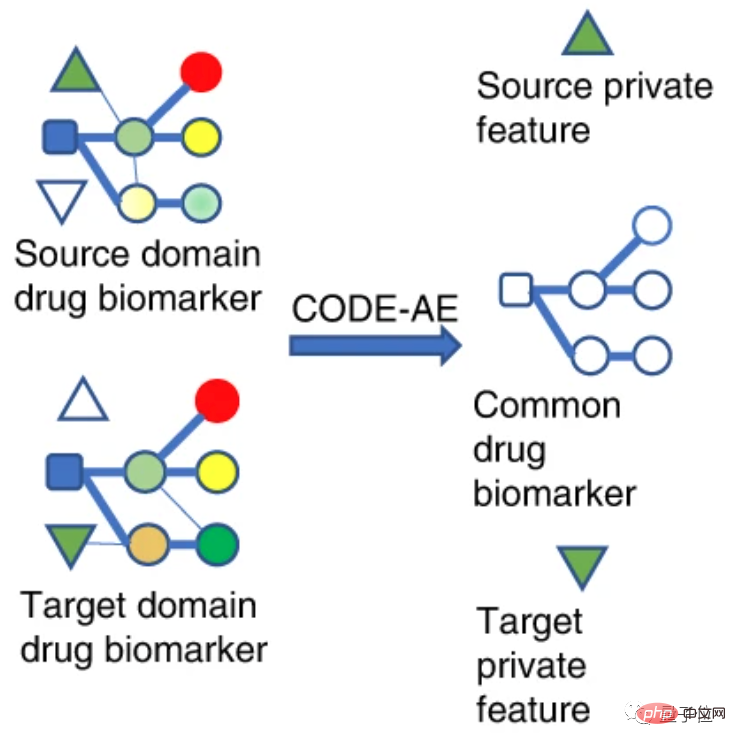
Mappez les caractéristiques de données de différents champs dans le même espace de caractéristiques afin que leurs distances dans cet espace soient aussi proches que possible.
Ainsi, la fonction objectif formée sur le domaine source dans l'espace des fonctionnalités peut être transférée vers le domaine cible pour améliorer la précision dans le domaine cible.
Dans le contexte de cette recherche, le domaine source et le domaine cible sont tous deux des caractéristiques de données des biomarqueurs de médicaments, c'est-à-dire des caractéristiques de données de cibles de médicaments.
En ce qui concerne spécifiquement le cadre du modèle, il est principalement divisé en trois parties : pré-entraînement, réglage fin et inférence.
La pré-formation utilise principalement l'apprentissage auto-supervisé pour créer un module de codage de fonctionnalités permettant de cartographier les profils d'expression génique non étiquetés des données cellulaires in vitro et des données des patients dans l'espace d'intégration. De cette façon, certains facteurs de confusion peuvent être éliminés et la distribution latente des deux données peut être cohérente pour éliminer les biais systématiques.
L'étape de mise au point consiste à ajouter un modèle supervisé sur la base d'un pré-entraînement et à utiliser des données cellulaires in vitro étiquetées pour l'entraînement.
Enfin, lors de la phase d'inférence, les patients obtenus lors de la pré-formation sont d'abord levés et intégrés, puis le modèle optimisé est utilisé pour prédire la réponse du patient au médicament.

Dans ce mode, CODE-AE a deux fonctionnalités.
Premièrement, il peut extraire des signaux biologiques communs et des représentations privées dans des échantillons incohérents, éliminant ainsi les interférences causées par différents modèles de données.
Deuxièmement, après avoir séparé le signal de réponse au médicament et les facteurs de confusion, un alignement local peut également être obtenu.
En résumé, CODE-AE peut être compris comme le processus de sélection de caractéristiques uniques dans le modèle de données incohérent intégrant l'espace de données étiquetées et non étiquetées.
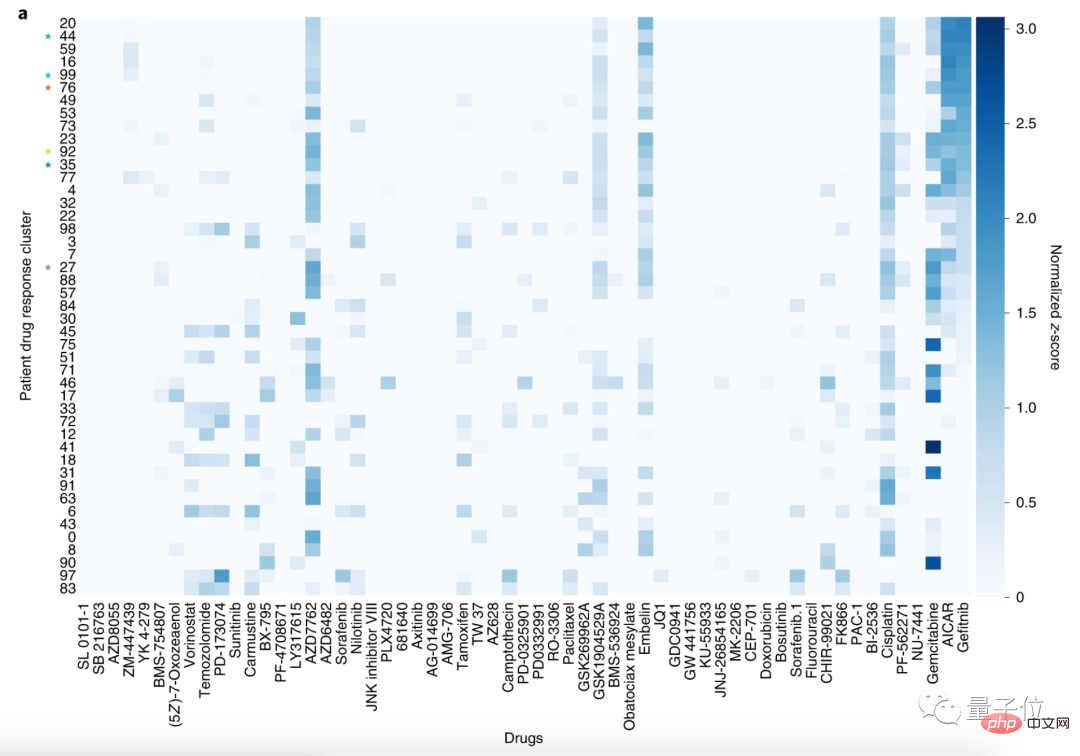
Pour démontrer l'efficacité du modèle, les chercheurs ont prédit l'adéquation du médicament à 9 808 patients atteints de cancer.
Si les résultats de site prédits par le modèle pour l'état du patient sont liés à la cible médicamenteuse qu'il utilise, cela prouve que la prédiction est correcte.
Les chercheurs ont ensuite divisé les patients en 100 clusters et les 59 médicaments en 30 clusters.
Grâce à cette méthode d'analyse, les patients présentant des profils de réponse médicamenteuse similaires peuvent être regroupés.
Ici, nous prenons comme exemple le regroupement de patients atteints d'un carcinome épidermoïde du poumon (LSCC) et d'un cancer du poumon non à petites cellules (NSCLC).
Parmi les 59 médicaments, les médicaments les plus sensibles au LSCC sont le géfitinib, l'AICAR et la gemcitabine.
Les cibles du géfitinib et de l'AICAR sont tous deux les récepteurs du facteur de croissance épidermique (EGFR), et la gemcitabine est souvent utilisée pour traiter le cancer du poumon non à petites cellules sans mutations de l'EGFR.
Le document indique que, conformément aux modes d'action de ces médicaments, CODE-AE a constaté que les patients utilisant le géfitinib et l'AICAR présentaient des profils de réponse aux médicaments similaires.
En d’autres termes, CODE-AE a découvert la bonne cible pour le traitement des patients, c’est-à-dire qu’il peut prédire les médicaments applicables.
L'équipe de recherche ci-dessus appartient à la City University de New York.
L'auteur correspondant est Lei Xie, diplômé de l'Université des sciences et technologies de Chine avec une licence en physique des polymères.
Diplômé d'une maîtrise en informatique de l'Université Rutgers ; d'un doctorat de l'Université Rutgers, mais avec un diplôme en chimie.

Il est entendu que la prochaine étape de l'équipe de recherche consistera à développer la fonction de prédiction de CODE-AE en termes de concentration et de métabolisme de la réponse clinique de nouveaux médicaments.
Les chercheurs ont déclaré que le modèle d'IA pourrait également être adapté pour prédire les effets secondaires des médicaments sur le corps humain.
Il convient de mentionner que la sous-revue Nature "Nature Machine Intelligence" se concentre spécifiquement sur la recherche appliquée interdisciplinaire en intelligence artificielle et en sciences de la vie, avec un nombre moyen d'articles publiés chaque année d'environ 60.
Adresse papier : https://www.nature.com/articles/s42256-022-00541-0
Lien de référence : https://phys.org/news/2022-10-ai-accurately-human-response -drogue.html
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
