
 développement back-end
Tutoriel Python
Utiliser Python pour implémenter un simple interpréteur arithmétique à quatre
développement back-end
Tutoriel Python
Utiliser Python pour implémenter un simple interpréteur arithmétique à quatre
Utiliser Python pour implémenter un simple interpréteur arithmétique à quatre

Démonstration de la fonction de calcul
Ici, nous montrons d'abord les informations d'aide du programme, puis quelques tests simples de quatre opérations arithmétiques. Il semble qu'il n'y ait pas de problème (je ne peux pas garantir que le programme n'a pas de bugs !).
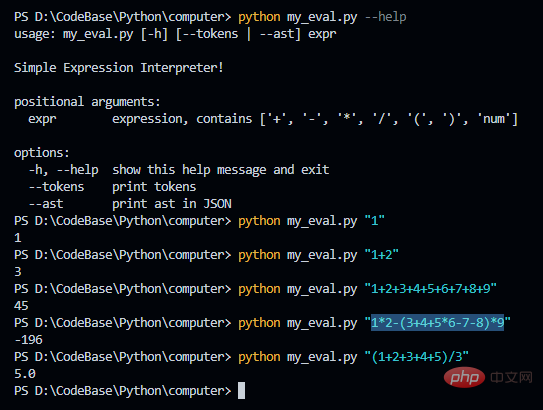
Jetons de sortie
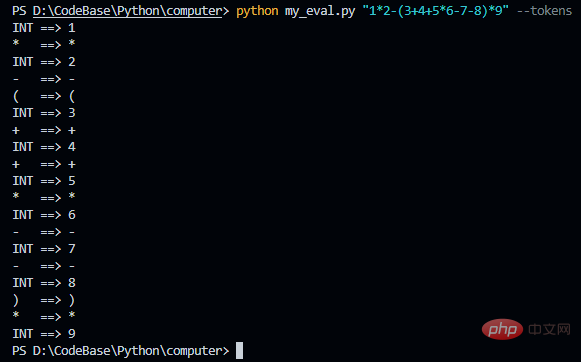
Sortie AST
Ces informations JSON formatées sont trop longues et ne sont pas propices à une visualisation directe. Nous le rendons pour voir l'arborescence générée finale (voir les deux blogs précédents pour les méthodes). Enregistrez le JSON suivant dans un fichier, ici je l'appelle demo.json, puis exécutez la commande suivante : pytm-cli -d LR -i demo.json -o demo.html, puis ouvrez dans le navigateur Fichier HTML généré. pytm-cli -d LR -i demo.json -o demo.html,然后再浏览器打开生成的 html 文件。

代码
所有的代码都在这里了,只需要一个文件 my_eval.py,想要运行的话,复制、粘贴,然后按照演示的步骤执行即可。
Node、BinOp、Constan 是用来表示节点的类.
Calculator 中 lexizer 方法是进行分词的,本来我是打算使用正则的,如果你看过我前面的博客的话,可以发现我是用的正则来分词的(因为 Python 的官方文档正则表达式中有一个简易的分词程序)。不过我看其他人都是手写的分词,所以我也这样做了,不过感觉并不是很好,很繁琐,而且容易出错。
parse 方法是进行解析的,主要是解析表达式的结构,判断是否符合四则运算的文法,最终生成表达式树(它的 AST)。
"""
Grammar
G -> E
E -> T E'
E' -> '+' T E' | '-' T E' | ɛ
T -> F T'
T' -> '*' F T' | '/' F T' | ɛ
F -> '(' E ')' | num | name
"""
import json
import argparse
class Node:
"""
简单的抽象语法树节点,定义一些需要使用到的具有层次结构的节点
"""
def eval(self) -> float: ... # 节点的计算方法
def visit(self): ... # 节点的访问方法
class BinOp(Node):
"""
BinOp Node
"""
def __init__(self, left, op, right) -> None:
self.left = left
self.op = op
self.right = right
def eval(self) -> float:
if self.op == "+":
return self.left.eval() + self.right.eval()
if self.op == "-":
return self.left.eval() - self.right.eval()
if self.op == "*":
return self.left.eval() * self.right.eval()
if self.op == "/":
return self.left.eval() / self.right.eval()
return 0
def visit(self):
"""
遍历树的各个节点,并生成 JSON 表示
"""
return {
"name": "BinOp",
"children": [
self.left.visit(),
{
"name": "OP",
"children": [
{
"name": self.op
}
]
},
self.right.visit()
]
}
class Constant(Node):
"""
Constant Node
"""
def __init__(self, value) -> None:
self.value = value
def eval(self) -> float:
return self.value
def visit(self):
return {
"name": "NUMBER",
"children": [
{
"name": str(self.value) # 转成字符是因为渲染成图像时,需要该字段为 str
}
]
}
class Calculator:
"""
Simple Expression Parser
"""
def __init__(self, expr) -> None:
self.expr = expr # 输入的表达式
self.parse_end = False # 解析是否结束,默认未结束
self.toks = [] # 解析的 tokens
self.index = 0 # 解析的下标
def lexizer(self):
"""
分词
"""
index = 0
while index < len(self.expr):
ch = self.expr[index]
if ch in [" ", "\r", "\n"]:
index += 1
continue
if '0' <= ch <= '9':
num_str = ch
index += 1
while index < len(self.expr):
n = self.expr[index]
if '0' <= n <= '9':
if ch == '0':
raise Exception("Invalid number!")
num_str = n
index += 1
continue
break
self.toks.append({
"kind": "INT",
"value": int(num_str)
})
elif ch in ['+', '-', '*', '/', '(', ')']:
self.toks.append({
"kind": ch,
"value": ch
})
index += 1
else:
raise Exception("Unkonwn character!")
def get_token(self):
"""
获取当前位置的 token
"""
if 0 <= self.index < len(self.toks):
tok = self.toks[self.index]
return tok
if self.index == len(self.toks): # token解析结束
return {
"kind": "EOF",
"value": "EOF"
}
raise Exception("Encounter Error, invalid index = ", self.index)
def move_token(self):
"""
下标向后移动一位
"""
self.index += 1
def parse(self) -> Node:
"""
G -> E
"""
# 分词
self.lexizer()
# 解析
expr_tree = self.parse_expr()
if self.parse_end:
return expr_tree
else:
raise Exception("Invalid expression!")
def parse_expr(self):
"""
E -> T E'
E' -> + T E' | - T E' | ɛ
"""
# E -> E E'
left = self.parse_term()
# E' -> + T E' | - T E' | ɛ
while True:
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if tok["kind"] == "EOF":
# 解析结束的标志
self.parse_end = True
break
if kind in ["+", "-"]:
self.move_token()
left = BinOp(left, value, self.parse_term())
else:
break
return left
def parse_term(self):
"""
T -> F T'
T' -> * F T' | / F T' | ɛ
"""
# T -> F T'
left = self.parse_factor()
# T' -> * F T' | / F T' | ɛ
while True:
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if kind in ["*", "/"]:
self.move_token()
right = self.parse_factor()
left = BinOp(left, value, right)
else:
break
return left
def parse_factor(self):
"""
F -> '(' E ')' | num | name
"""
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if kind == '(':
self.move_token()
expr_node = self.parse_expr()
if self.get_token()["kind"] != ")":
raise Exception("Encounter Error, expected )!")
self.move_token()
return expr_node
if kind == "INT":
self.move_token()
return Constant(value=value)
raise Exception("Encounter Error, unknown factor: ", kind)
if __name__ == "__main__":
# 添加命令行参数解析器
cmd_parser = argparse.ArgumentParser(
description="Simple Expression Interpreter!")
group = cmd_parser.add_mutually_exclusive_group()
group.add_argument("--tokens", help="print tokens", action="store_true")
group.add_argument("--ast", help="print ast in JSON", action="store_true")
cmd_parser.add_argument(
"expr", help="expression, contains ['+', '-', '*', '/', '(', ')', 'num']")
args = cmd_parser.parse_args()
calculator = Calculator(expr=args.expr)
tree = calculator.parse()
if args.tokens: # 输出 tokens
for t in calculator.toks:
print(f"{t['kind']:3s} ==> {t['value']}")
elif args.ast: # 输出 JSON 表示的 AST
print(json.dumps(tree.visit(), indent=4))
else: # 计算结果
print(tree.eval())总结
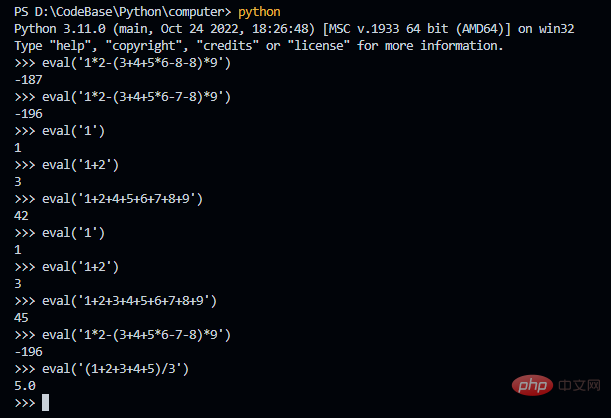
本来想在前面说一下为什么叫 my_eval.py,但是感觉看到后面的人不多,那就在这里说好了。如果写了一个复杂的表达式,那么怎么验证是否正确的。这里我们直接利用 Python 这个最完美的解释器就好了,哈哈。这里用 Python 的 eval 函数,你当然是不需要调用这个函数,直接复制计算的表达式即可。我用 eval 函数,只是想表达为什么我的程序会叫 my_eval
Code
Tout le code est ici. Vous n'avez besoin que d'un seul fichier my_eval.py. Si vous souhaitez l'exécuter, copiez-le et collez-le, puis suivez les étapes de la démonstration.
La méthode lexizer dans Calculator est utilisée pour la segmentation des mots. À l'origine, j'avais prévu d'utiliser la régularisation. Si vous avez lu mon blog précédent, vous pouvez le constater. Je suis Les expressions régulières sont utilisées pour segmenter les mots (car il existe un simple programme de segmentation de mots dans les expressions régulières de la documentation officielle de Python). Mais j’ai vu que d’autres personnes écrivaient les participes à la main, alors j’ai fait la même chose, mais ça ne me semblait pas très agréable, c’était très fastidieux et sujet aux erreurs.
La méthode parse effectue une analyse. Elle analyse principalement la structure de l'expression, détermine si elle est conforme à la grammaire des quatre opérations arithmétiques et génère enfin l'arbre d'expression (son AST). 🎜rrreee
Résumé
🎜Au départ, je voulais expliquer pourquoi il s'appellemy_eval.py, mais j'ai l'impression qu'il n'y a pas beaucoup de monde derrière, alors je vais le dire ici . Si vous écrivez une expression complexe, comment vérifier si elle est correcte ? Ici, nous pouvons simplement utiliser Python, l'interpréteur le plus parfait, haha. La fonction eval de Python est utilisée ici. Bien sûr, vous n'avez pas besoin d'appeler cette fonction, copiez simplement l'expression calculée directement. J'utilise la fonction eval juste pour exprimer pourquoi mon programme s'appelle my_eval. 🎜🎜🎜🎜🎜Après avoir été implémenté de cette manière, il peut être considéré comme un simple interpréteur arithmétique à quatre. Cependant, si vous recommencez, vous aurez probablement l'impression que l'ensemble du processus est très fastidieux, comme moi. Puisqu’il existe des outils prêts à l’emploi pour la segmentation des mots et l’analyse grammaticale, et qu’ils ne sont pas sujets aux erreurs, la charge de travail peut être considérablement réduite. Cependant, il est nécessaire de le faire vous-même. Avant d’utiliser l’outil, vous devez au moins comprendre la fonction de l’outil. 🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse du XML mobile à PDF dépend des facteurs suivants: la complexité de la structure XML. Méthode de conversion de configuration du matériel mobile (bibliothèque, algorithme) Méthodes d'optimisation de la qualité du code (sélectionnez des bibliothèques efficaces, optimiser les algorithmes, les données de cache et utiliser le multi-threading). Dans l'ensemble, il n'y a pas de réponse absolue et elle doit être optimisée en fonction de la situation spécifique.
 Comment convertir les fichiers XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:12 PM
Comment convertir les fichiers XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:12 PM
Il est impossible de terminer la conversion XML à PDF directement sur votre téléphone avec une seule application. Il est nécessaire d'utiliser les services cloud, qui peuvent être réalisés via deux étapes: 1. Convertir XML en PDF dans le cloud, 2. Accédez ou téléchargez le fichier PDF converti sur le téléphone mobile.
 Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Il n'y a pas de fonction de somme intégrée dans le langage C, il doit donc être écrit par vous-même. La somme peut être obtenue en traversant le tableau et en accumulant des éléments: Version de boucle: la somme est calculée à l'aide de la longueur de boucle et du tableau. Version du pointeur: Utilisez des pointeurs pour pointer des éléments de tableau, et un résumé efficace est réalisé grâce à des pointeurs d'auto-incitation. Allouer dynamiquement la version du tableau: allouer dynamiquement les tableaux et gérer la mémoire vous-même, en veillant à ce que la mémoire allouée soit libérée pour empêcher les fuites de mémoire.
 Comment convertir XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:18 PM
Comment convertir XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:18 PM
Il n'est pas facile de convertir XML en PDF directement sur votre téléphone, mais il peut être réalisé à l'aide des services cloud. Il est recommandé d'utiliser une application mobile légère pour télécharger des fichiers XML et recevoir des PDF générés, et de les convertir avec des API Cloud. Les API Cloud utilisent des services informatiques sans serveur et le choix de la bonne plate-forme est crucial. La complexité, la gestion des erreurs, la sécurité et les stratégies d'optimisation doivent être prises en compte lors de la gestion de l'analyse XML et de la génération de PDF. L'ensemble du processus nécessite que l'application frontale et l'API back-end fonctionnent ensemble, et il nécessite une certaine compréhension d'une variété de technologies.
 Comment convertir XML en images
Apr 03, 2025 am 07:39 AM
Comment convertir XML en images
Apr 03, 2025 am 07:39 AM
XML peut être converti en images en utilisant un convertisseur XSLT ou une bibliothèque d'images. Convertisseur XSLT: Utilisez un processeur XSLT et une feuille de style pour convertir XML en images. Bibliothèque d'images: utilisez des bibliothèques telles que PIL ou ImageMagick pour créer des images à partir de données XML, telles que des formes de dessin et du texte.
 Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Il n'y a pas de salaire absolu pour les développeurs Python et JavaScript, selon les compétences et les besoins de l'industrie. 1. Python peut être davantage payé en science des données et en apprentissage automatique. 2. JavaScript a une grande demande dans le développement frontal et complet, et son salaire est également considérable. 3. Les facteurs d'influence comprennent l'expérience, la localisation géographique, la taille de l'entreprise et les compétences spécifiques.
 Comment convertir XML en mp3
Apr 03, 2025 am 09:00 AM
Comment convertir XML en mp3
Apr 03, 2025 am 09:00 AM
Les étapes pour convertir XML en MP3 incluent: Extraire les données audio de XML: analyser le fichier XML, trouver la chaîne de codage Base64 contenant les données audio et les décoder en format binaire. Encoder les données audio à MP3: Installez l'encodeur MP3 et définissez les paramètres de codage, encodez les données audio binaires au format MP3 et enregistrez-les dans un fichier.
 Comment changer le format de XML
Apr 03, 2025 am 08:42 AM
Comment changer le format de XML
Apr 03, 2025 am 08:42 AM
Il existe plusieurs façons de modifier les formats XML: édition manuellement avec un éditeur de texte tel que le bloc-notes; Formatage automatique avec des outils de mise en forme XML en ligne ou de bureau tels que XMLBeautifier; Définir les règles de conversion à l'aide d'outils de conversion XML tels que XSLT; ou analyser et fonctionner à l'aide de langages de programmation tels que Python. Soyez prudent lorsque vous modifiez et sauvegardez les fichiers d'origine.
