
 développement back-end
Tutoriel Python
Apprenez Python pour implémenter un système de conduite autonome
développement back-end
Tutoriel Python
Apprenez Python pour implémenter un système de conduite autonome
Apprenez Python pour implémenter un système de conduite autonome
Apr 21, 2023 pm 04:58 PM
Environnement d'installation
gym est une boîte à outils permettant de développer et de comparer des algorithmes d'apprentissage par renforcement. Il est relativement simple d'installer la bibliothèque gym et ses sous-scénarios en python.
Installer gym:
pip install gym
Installer le module de conduite autonome, on utilise ici le package Highway-env publié par Edouard Leurent sur github:
pip install --user git+https://github.com/eleurent/highway-env
Il contient 6 scènes :
- Highway - "highway-v0"
- Fusionner - "fusion-v0"
- Rond-point - "rond-point-v0"
- Parking - "parking-v0"
- Carrefour - "intersection-v0"
- Piste de course - "racetrack- v0"
Une documentation détaillée peut être trouvé ici :
https://www.php.cn/link/c0fda89ebd645bd7cea60fcbb5960309
Configurer l'environnement
Après l'installation, vous pouvez expérimenter le code (avec Prenons l'exemple de la scène d'autoroute) :
import gym
import highway_env
%matplotlib inline
env = gym.make('highway-v0')
env.reset()
for _ in range(3):
action = env.action_type.actions_indexes["IDLE"]
obs, reward, done, info = env.step(action)
env.render()
Après l'exécution, la scène suivante sera générée dans le simulateur :
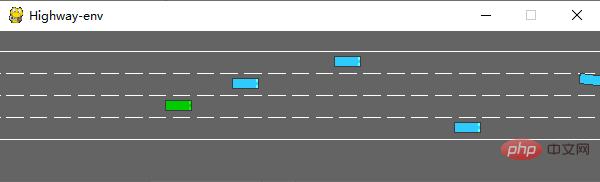
La classe env a de nombreux paramètres qui peuvent être configurés, veuillez vous référer au document original pour plus de détails.
Modèle de formation
1. Traitement des données
(1) Il n'y a aucun capteur défini dans le package state
highway-env Tous les états (observations) du véhicule sont lus à partir du code sous-jacent, économisant ainsi beaucoup de préliminaires. travail. Selon la documentation, l'état (overservations) dispose de trois méthodes de sortie : cinématique, image en niveaux de gris et grille d'occupation.
Cinématique
Sortez une matrice de V*F, V représente le nombre de véhicules qui doivent être observés (y compris le véhicule de l'ego lui-même) et F représente le nombre de caractéristiques qui doivent être comptées. Exemple :
Les données seront normalisées par défaut lors de leur génération et la plage de valeurs est : [100, 100, 20, 20]. Vous pouvez également définir les attributs du véhicule autres que le véhicule ego comme étant les coordonnées absolues de la carte ou les coordonnées relatives du véhicule du moi.
Lors de la définition de l'environnement, vous devez définir les paramètres de la fonctionnalité :
config =
{
"observation":
{
"type": "Kinematics",
#选取5辆车进行观察(包括ego vehicle)
"vehicles_count": 5,
#共7个特征
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
Image en niveaux de gris
Générer une image en niveaux de gris W*H, W représente la largeur de l'image, H représente la hauteur de l'image
Grille d'occupation
Générer a La matrice tridimensionnelle de WHF utilise un tableau W*H pour représenter les conditions du véhicule autour du véhicule ego. Chaque grille contient des caractéristiques F.
(2) action
Les actions du package Highway-env sont divisées en deux types : continues et discrètes. L'action continue peut définir directement les valeurs de l'accélérateur et de l'angle de braquage. L'action discrète contient 5 méta-actions :
ACTIONS_ALL = {
0: 'LANE_LEFT',
1: 'IDLE',
2: 'LANE_RIGHT',
3: 'FASTER',
4: 'SLOWER'
}
(3) récompense
Le package autoroute-env utilise la même fonction de récompense sauf pour la scène de stationnement :

Cette fonction ne peut être modifiée que dans son code source, et le poids ne peut être ajusté que dans la couche externe.
(La fonction de récompense de la scène de stationnement est incluse dans le document original)
2. Construire le modèle
Réseau DQN J'utilise la première méthode de représentation d'état - Cinématique pour la démonstration. Étant donné que la quantité de données d'état est faible (5 voitures * 7 fonctionnalités), vous pouvez ignorer l'utilisation de CNN et convertir directement la taille [5,7] des données bidimensionnelles en [1,35]. le modèle est de 35. Le résultat est le nombre d’actions discrètes, 5 au total.
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from torch import FloatTensor, LongTensor, ByteTensor
from collections import namedtuple
import random
Tensor = FloatTensor
EPSILON = 0# epsilon used for epsilon greedy approach
GAMMA = 0.9
TARGET_NETWORK_REPLACE_FREQ = 40 # How frequently target netowrk updates
MEMORY_CAPACITY = 100
BATCH_SIZE = 80
LR = 0.01 # learning rate
class DQNNet(nn.Module):
def __init__(self):
super(DQNNet,self).__init__()
self.linear1 = nn.Linear(35,35)
self.linear2 = nn.Linear(35,5)
def forward(self,s):
s=torch.FloatTensor(s)
s = s.view(s.size(0),1,35)
s = self.linear1(s)
s = self.linear2(s)
return s
class DQN(object):
def __init__(self):
self.net,self.target_net = DQNNet(),DQNNet()
self.learn_step_counter = 0
self.memory = []
self.position = 0
self.capacity = MEMORY_CAPACITY
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self,s,e):
x=np.expand_dims(s, axis=0)
if np.random.uniform() < 1-e:
actions_value = self.net.forward(x)
action = torch.max(actions_value,-1)[1].data.numpy()
action = action.max()
else:
action = np.random.randint(0, 5)
return action
def push_memory(self, s, a, r, s_):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(torch.unsqueeze(torch.FloatTensor(s), 0),torch.unsqueeze(torch.FloatTensor(s_), 0),
torch.from_numpy(np.array([a])),torch.from_numpy(np.array([r],dtype='float32')))#
self.position = (self.position + 1) % self.capacity
def get_sample(self,batch_size):
sample = random.sample(self.memory,batch_size)
return sample
def learn(self):
if self.learn_step_counter % TARGET_NETWORK_REPLACE_FREQ == 0:
self.target_net.load_state_dict(self.net.state_dict())
self.learn_step_counter += 1
transitions = self.get_sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
b_s = Variable(torch.cat(batch.state))
b_s_ = Variable(torch.cat(batch.next_state))
b_a = Variable(torch.cat(batch.action))
b_r = Variable(torch.cat(batch.reward))
q_eval = self.net.forward(b_s).squeeze(1).gather(1,b_a.unsqueeze(1).to(torch.int64))
q_next = self.target_net.forward(b_s_).detach() #
q_target = b_r + GAMMA * q_next.squeeze(1).max(1)[0].view(BATCH_SIZE, 1).t()
loss = self.loss_func(q_eval, q_target.t())
self.optimizer.zero_grad() # reset the gradient to zero
loss.backward()
self.optimizer.step() # execute back propagation for one step
return loss
Transition = namedtuple('Transition',('state', 'next_state','action', 'reward'))
3. Résultats d'exécution
Une fois chaque partie terminée, les modèles peuvent être combinés pour entraîner le modèle. Le processus est similaire à celui de CARLA, je n'entrerai donc pas dans les détails.
Environnement d'initialisation (ajoutez simplement la classe DQN) :
import gym
import highway_env
from matplotlib import pyplot as plt
import numpy as np
import time
config =
{
"observation":
{
"type": "Kinematics",
"vehicles_count": 5,
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
env = gym.make("highway-v0")
env.configure(config)
Modèle de formation :
dqn=DQN()
count=0
reward=[]
avg_reward=0
all_reward=[]
time_=[]
all_time=[]
collision_his=[]
all_collision=[]
while True:
done = False
start_time=time.time()
s = env.reset()
while not done:
e = np.exp(-count/300)#随机选择action的概率,随着训练次数增多逐渐降低
a = dqn.choose_action(s,e)
s_, r, done, info = env.step(a)
env.render()
dqn.push_memory(s, a, r, s_)
if ((dqn.position !=0)&(dqn.position % 99==0)):
loss_=dqn.learn()
count+=1
print('trained times:',count)
if (count%40==0):
avg_reward=np.mean(reward)
avg_time=np.mean(time_)
collision_rate=np.mean(collision_his)
all_reward.append(avg_reward)
all_time.append(avg_time)
all_collision.append(collision_rate)
plt.plot(all_reward)
plt.show()
plt.plot(all_time)
plt.show()
plt.plot(all_collision)
plt.show()
reward=[]
time_=[]
collision_his=[]
s = s_
reward.append(r)
end_time=time.time()
episode_time=end_time-start_time
time_.append(episode_time)
is_collision=1 if info['crashed']==True else 0
collision_his.append(is_collision)
J'ai ajouté quelques fonctions de dessin au code et je peux saisir certains indicateurs clés pendant le processus en cours, en m'entraînant 40 fois à chaque fois Calculer la moyenne valeur.
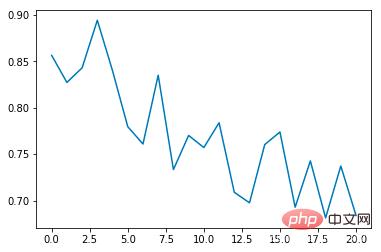
Taux d'incidence moyen des collisions :
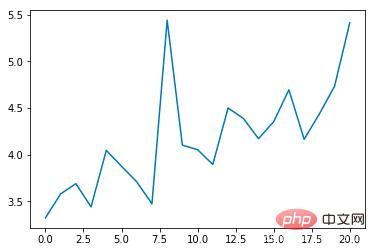
Durée moyenne des époques :
Récompense moyenne :
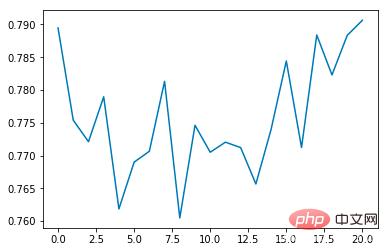
On peut constater que le taux d'incidence moyen des collisions diminuera progressivement à mesure que le nombre de formations augmente, chaque époque La durée s'allongera progressivement (si une collision se produit, l'époque se terminera immédiatement)
Résumé
Comparé au simulateur CARLA, le package d'environnement Highway-env est nettement plus abstrait, utilisant une représentation de type jeu, afin que l'algorithme puisse être implémenté dans un idéal, il peut être entraîné dans un environnement virtuel sans tenir compte des problèmes du monde réel tels que les méthodes d'acquisition de données, la précision des capteurs et le temps de calcul. Il est très convivial pour la conception et les tests d'algorithmes de bout en bout, mais du point de vue du contrôle automatique, il y a moins d'aspects par lesquels commencer et il n'est pas très flexible pour la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Article chaud

Outils chauds Tags

Article chaud

Tags d'article chaud

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Derrière le premier accès Android à Deepseek: voir le pouvoir des femmes
Mar 12, 2025 pm 12:27 PM
Derrière le premier accès Android à Deepseek: voir le pouvoir des femmes
Mar 12, 2025 pm 12:27 PM
Derrière le premier accès Android à Deepseek: voir le pouvoir des femmes
 Version Web Deepseek Entrée officielle
Mar 12, 2025 pm 01:42 PM
Version Web Deepseek Entrée officielle
Mar 12, 2025 pm 01:42 PM
Version Web Deepseek Entrée officielle
 Comment résoudre le problème des serveurs occupés pour Deepseek
Mar 12, 2025 pm 01:39 PM
Comment résoudre le problème des serveurs occupés pour Deepseek
Mar 12, 2025 pm 01:39 PM
Comment résoudre le problème des serveurs occupés pour Deepseek
 Recherche approfondie Entrée du site officiel Deepseek
Mar 12, 2025 pm 01:33 PM
Recherche approfondie Entrée du site officiel Deepseek
Mar 12, 2025 pm 01:33 PM
Recherche approfondie Entrée du site officiel Deepseek
 Un autre produit national de Baidu est lié à Deepseek.
Mar 12, 2025 pm 01:48 PM
Un autre produit national de Baidu est lié à Deepseek.
Mar 12, 2025 pm 01:48 PM
Un autre produit national de Baidu est lié à Deepseek.
 Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
 Midea lance son premier climatiseur Deepseek: l'interaction vocale AI peut réaliser 400 000 commandes!
Mar 12, 2025 pm 12:18 PM
Midea lance son premier climatiseur Deepseek: l'interaction vocale AI peut réaliser 400 000 commandes!
Mar 12, 2025 pm 12:18 PM
Midea lance son premier climatiseur Deepseek: l'interaction vocale AI peut réaliser 400 000 commandes!
 Nubia Flip 2 est lancé: intégrant profondément le grand modèle Deepseek, au prix de 3399 yuans
Mar 12, 2025 pm 01:21 PM
Nubia Flip 2 est lancé: intégrant profondément le grand modèle Deepseek, au prix de 3399 yuans
Mar 12, 2025 pm 01:21 PM
Nubia Flip 2 est lancé: intégrant profondément le grand modèle Deepseek, au prix de 3399 yuans
