
 développement back-end
Tutoriel Python
Tutoriel Python : Comment diviser et fusionner des fichiers volumineux à l'aide de Python ?
développement back-end
Tutoriel Python
Tutoriel Python : Comment diviser et fusionner des fichiers volumineux à l'aide de Python ?
Tutoriel Python : Comment diviser et fusionner des fichiers volumineux à l'aide de Python ?

Parfois, nous devons envoyer un fichier volumineux à d'autres, mais en raison des limitations du canal de transmission, telles que la limite de taille des pièces jointes aux e-mails, ou que l'état du réseau n'est pas très bon, nous devons diviser le fichier volumineux. en petits fichiers, envoyer et recevoir plusieurs fois. La fin fusionne ensuite ces petits fichiers. Aujourd'hui, je vais partager comment diviser et fusionner des fichiers volumineux à l'aide de Python.
Idées et mise en œuvre
S'il s'agit d'un fichier texte, il peut être divisé par le nombre de lignes. Qu'il s'agisse d'un fichier texte ou d'un fichier binaire, il peut être divisé selon la taille spécifiée.
À l'aide de la fonction de lecture et d'écriture de fichiers de Python, vous pouvez diviser et fusionner des fichiers, définir la taille de chaque fichier, puis lire les octets de la taille spécifiée et les écrire dans un nouveau fichier. L'extrémité réceptrice lit les petits fichiers dans l'ordre. et écrit les octets obtenus sont écrits dans un fichier dans l'ordre et la fusion peut être terminée.
Split
size = 1024 * 1000 * 10# 10MB
with open("bigfile", "rb") as reader:
part = 1
while True:
part_content = reader.read(size)
if not part_content:
print("split done.")
break
with open(f"bigfile_part{part}","wb") as writer:
writer.write(part_content)Fusionner
total_parts = 5
with open("bigfile","wb") as writer:
for i in range(5):
with open(f"bigfile_part{i}", "rb") as reader:
writer.write(reader.read())Utiliser une bibliothèque tierce
Bien que vous puissiez l'écrire vous-même, mais que d'autres l'ont écrit, pourquoi ne pas gagner du temps et l'utiliser directement ? Installez-le simplement directement avec pip :
pip install filesplit
Split
from filesplit.split import Split
split = Split("./data.rar", "./output")
split.bysize(size = 1024*1000*10) # 每个文件最多 10MBAprès l'exécution, nous pouvons voir les fichiers fractionnés dans le dossier de sortie :
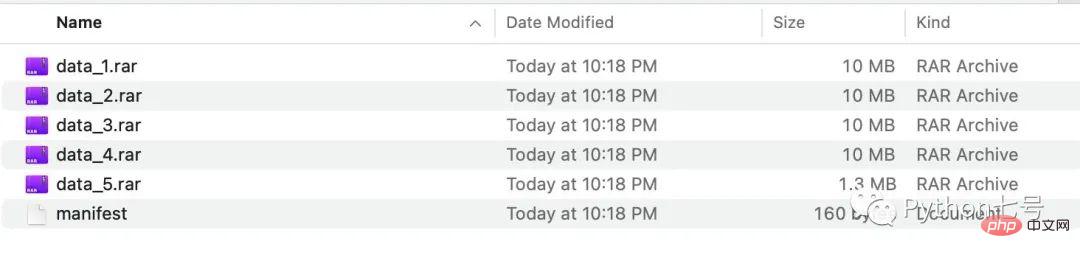
Vous pouvez également diviser en fonction du nombre de lignes de fichier :
split.bylinecount(linecount = 10000) # 每个文件最多 10000 行
Fusionner
La fusion doit fusionner les petits fichiers dans le dossier. Cet outil nécessite qu'il y ait un fichier manifeste dans le dossier. Son format est le suivant :
filename,filesize,header data_1.rar,10000000,False data_2.rar,10000000,False data_3.rar,10000000,False data_4.rar,10000000,False data_5.rar,1304145,False
Le code pour fusionner les fichiers doit uniquement spécifier le répertoire. à fusionner et le répertoire cible, nom du fichier fusionné, le code est le suivant :
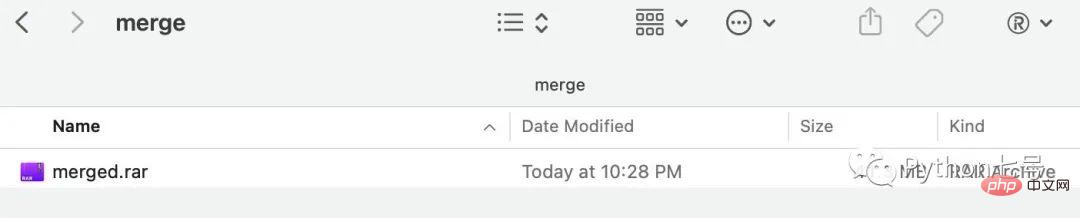
from filesplit.merge import Merge merge = Merge(inputdir = "./output", outputdir="./merge", outputfilename = "merged.rar") merge.merge()
Après exécution, vous pouvez voir le fichier fusionné dans le répertoire de fusion :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment optimiser la configuration des HDF sur CentOS
Apr 14, 2025 pm 07:09 PM
Comment optimiser la configuration des HDF sur CentOS
Apr 14, 2025 pm 07:09 PM
Guide d'optimisation des performances du cluster HDFS CENTOS PLATTE HDFS Cet article explique comment optimiser la configuration HDFS sur le système CentOS et améliorer les performances du cluster. Le processus d'optimisation couvre plusieurs aspects et doit être ajusté en fonction des besoins réels et de l'environnement matériel. Il est recommandé de vérifier l'efficacité de tout changement significatif dans l'environnement de production avant de mettre en œuvre ses données. 1. Installation simplifiée de la configuration de base du système: adoptez une méthode d'installation minimale, installez uniquement les packages logiciels nécessaires pour réduire la consommation de ressources système. Paramètres réseau: assurez-vous que la configuration du réseau est correcte, il est recommandé d'utiliser une adresse IP statique et de configurer raisonnablement les paramètres réseau pour assurer la stabilité du réseau et la transmission à grande vitesse. 2. Fichier de configuration du noyau du paramètre de noyau HDFS: Configurer correctement Core-site.xml
 Comment surveiller le statut HDFS sur CentOS
Apr 14, 2025 pm 07:33 PM
Comment surveiller le statut HDFS sur CentOS
Apr 14, 2025 pm 07:33 PM
Il existe de nombreuses façons de surveiller l'état des HDF (système de fichiers distribué Hadoop) sur les systèmes CentOS. Cet article présentera plusieurs méthodes couramment utilisées pour vous aider à choisir la solution la plus appropriée. 1. Utilisez le propre webui de Hadoop, la propre interface Web de Hadoop pour fournir une fonction de surveillance de l'état du cluster. Étapes: Assurez-vous que le cluster Hadoop est opérationnel. Accédez au webui: entrez http: //: 50070 (hadoop2.x) ou http: //: 9870 (hadoop3.x) dans votre navigateur. Le nom d'utilisateur et le mot de passe par défaut sont généralement des HDF / HDF. 2. La surveillance des outils de ligne de commande Hadoop fournit une série d'outils de ligne de commande pour faciliter la surveillance
