

J'ai récemment vu un exemple d'utilisation du multi-threading pour télécharger des fichiers. Je l'ai trouvé très intéressant, alors je l'ai exploré et j'ai essayé d'utiliser le multi-threading pour copier des fichiers localement. Après avoir fini d'écrire, j'ai découvert que les deux sont en fait très similaires. Qu'il s'agisse de copie de fichiers locaux ou de téléchargement multithread en réseau, l'utilisation des flux est la même. Pour les systèmes de fichiers locaux, le flux d'entrée est obtenu à partir d'un fichier dans le système de fichiers local. Pour les ressources réseau, il est obtenu à partir d'un fichier sur un serveur distant.
Remarque : Bien que de nombreuses personnes aient écrit ce code de téléchargement multithread, tout le monde ne le comprend peut-être pas, je vais donc l'écrire à nouveau ici, ha.
Un avantage évident de l'utilisation du multithreading est le suivant : Utiliser le processeur inactif pour accélérer. Mais notez que plus il y a de threads, mieux c'est. Bien qu'il semble que n threads téléchargent ensemble, chaque thread télécharge une petite partie et le temps de téléchargement deviendra 1/n. C'est une compréhension très simple, tout comme il faut 100 jours à une personne pour construire une maison, mais cela ne prend que 1/10 de jour pour 10 000 personnes ? (C'est une exagération, haha !)
Basculer entre les threads nécessite également une surcharge du système et le nombre de threads doit être contrôlé dans une plage raisonnable.
Cette classe est relativement unique. Elle peut lire des données à partir de fichiers et écrire des données dans des fichiers. Mais ce n'est pas une sous-classe de OutputStream et InputStream, c'est une classe qui implémente ces deux interfaces DataOutput et DataInput.
Introduction à l'API :
Les instances de cette classe prennent en charge la lecture et l'écriture de fichiers à accès aléatoire. L'accès aléatoire à un fichier se comporte comme un grand nombre d'octets stockés dans le système de fichiers. Il existe un type de curseur, ou d'index dans un tableau implicite, appelé pointeur de fichier ; les opérations d'entrée lisent les octets en commençant au pointeur de fichier et étendent le pointeur de fichier au-delà des octets lus. L'opération de sortie est également disponible si le fichier à accès aléatoire est créé en mode lecture/écriture ; l'opération de sortie écrit les octets en commençant au pointeur de fichier et avance le pointeur de fichier jusqu'aux octets écrits. Les opérations de sortie écrivant sur le côté actuel d’un tableau implicite entraînent l’expansion du tableau. Le pointeur de fichier peut être lu par la méthode getFilePointer et défini par la méthode seek.
Donc, la chose la plus importante à propos de cette classe est la méthode de recherche. En utilisant la méthode de recherche, vous pouvez contrôler la position d'écriture, il est donc beaucoup plus facile d'implémenter le multi-thread. Par conséquent, qu'il s'agisse de copie de fichiers locaux ou de téléchargement multithread en réseau, cette classe est nécessaire.
L'idée spécifique est la suivante : Utilisez d'abord RandomAccessFile pour créer un objet File, puis définissez la taille de ce fichier. (Oui, il peut définir directement la taille du fichier.) Définissez ce fichier pour qu'il soit identique à celui que vous souhaitez copier ou télécharger. (Bien que nous n'ayons pas écrit de données dans ce fichier, le fichier a été créé.) Divisez le fichier en plusieurs parties et utilisez des fils de discussion pour copier ou télécharger le contenu de chaque partie.
C'est quelque peu similaire à l'écrasement de fichier. Si vous écrivez des données dans un fichier déjà existant en commençant par la tête du fichier et en écrivant jusqu'à la fin du fichier, le fichier d'origine n'existera plus et deviendra le nouveau fichier écrit. document.
Définissez la taille du fichier :
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
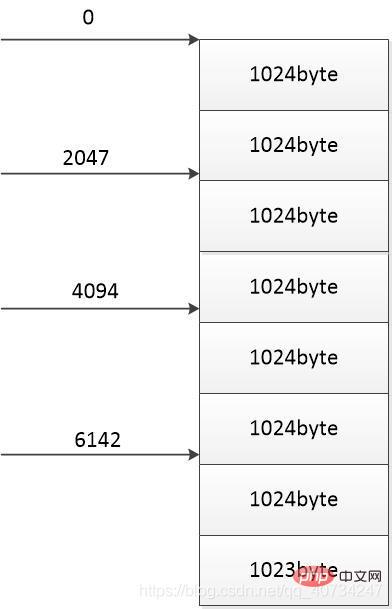
}Utilisez des images pour illustrer : Cette image représente un fichier d'une taille de 8191 octets : La taille de chaque partie est : 8191 / 4 = 2047 octets
Divisez ce fichier en Quatre parties, chaque partie utilise un fil pour la copie ou le téléchargement, et chaque flèche représente la position de téléchargement de départ d'un fil. J'ai intentionnellement laissé la dernière partie non définie sur 1024 octets car les fichiers sont rarement divisibles exactement par 1024 octets. (La raison pour laquelle j'utilise 1024 octets est que je lirai 1024 octets à chaque fois. Si 1024 octets sont lus, sinon le nombre correspondant d'octets lus sera écrit).
Selon ce schéma, chaque thread télécharge 2047 octets, alors le nombre total d'octets téléchargés est : 2047 * 4 = 8188 octets < 8191 octets (taille totale du fichier) Cela crée donc un problème, le nombre de le nombre d'octets téléchargés est inférieur au nombre total d'octets. Il s'agit d'un problème, le nombre d'octets téléchargés doit donc être supérieur au nombre total d'octets. (Peu importe s'il y en a plus, car les parties supplémentaires téléchargées seront écrasées par les parties ultérieures et ne poseront pas de problèmes.)
Donc, la taille de chaque partie devrait être : 8191 / 4 + 1 = 2048 octets. (De cette façon, la somme des tailles des quatre parties dépasse la taille totale et aucune perte de données ne se produira.)
Donc, ajouter 1 ici est très nécessaire.
long size = len / FileCopyUtil.THREAD_NUM + 1;
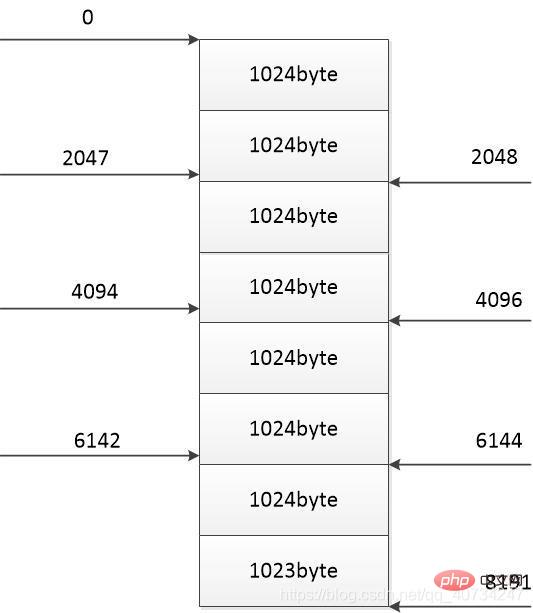
La position où chaque fil termine le téléchargement (à droite) Chaque fil copie et télécharge uniquement sa propre partie, il n'est donc pas nécessaire de télécharger tout le contenu, donc les données du fichier sont lues et écrites la partie dossier, un jugement supplémentaire sera ajouté.
这里增加一个计数器:curlen。它表示是当前复制或者下载的长度,然后每次读取后和 size(每部分的大小)进行比较,如果 curlen 大于 size 就表示相应的部分下载完成了(当然了,这些都要在数据没有读取完的条件下判断)。
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position);
raf.seek(position);
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
还有需要注意的是,每个线程下载的时候都要: 1. 输出流设置文件指针的位置。 2. 输入流跳过不需要读取的字节。
这是很重要的一步,应该是很好理解的。
bis.skip(position); raf.seek(position);
package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
/**
* 用于进行文件复制,但不是常规的文件复制 。
* 准备仿照疯狂Java,写一个多线程的文件复制工具。
* 即可以本地复制和网络复制
* */
/**
* 设计思路:
* 获取目标文件的大小,然后设置复制文件的大小(这样做是有好处的),
* 然后使用将文件分为 n 分,使用 n 个线程同时进行复制(这里我将 n 取为 4)。
*
* 可以进一步拓展:
* 加强为断点复制功能,即程序中断以后,
* 仍然可以继续从上次位置恢复复制,减少不必要的重复开销
* */
public class FileCopyUtil {
//设置一个常量,复制线程的数量
private static final int THREAD_NUM = 4;
private FileCopyUtil() {}
/**
* @param targetPath 目标文件的路径
* @param outputPath 复制输出文件的路径
* @throws IOException
* */
public static void transferFile(String targetPath, String outputPath) throws IOException {
File targetFile = new File(targetPath);
File outputFilePath = new File(outputPath);
if (!targetFile.exists() || targetFile.isDirectory()) { //目标文件不存在,或者是一个文件夹,则抛出异常
throw new FileNotFoundException("目标文件不存在:"+targetPath);
}
if (!outputFilePath.exists()) { //如果输出文件夹不存在,将会尝试创建,创建失败,则抛出异常。
if(!outputFilePath.mkdir()) {
throw new FileNotFoundException("无法创建输出文件:"+outputPath);
}
}
long len = targetFile.length();
File outputFile = new File(outputFilePath, "copy"+targetFile.getName());
createOutputFile(outputFile, len); //创建输出文件,设置好大小。
long[] position = new long[4];
//每一个线程需要复制文件的起点
long size = len / FileCopyUtil.THREAD_NUM + 1;
for (int i = 0; i < FileCopyUtil.THREAD_NUM; i++) {
position[i] = i*size;
copyThread(i, position[i], size, targetFile, outputFile);
}
}
//创建输出文件,设置好大小。
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
}
private static void copyThread(int i, long position, long size, File targetFile, File outputFile) {
int n = i; //Lambda 表达式的限制,无法使用变量。
new Thread(()->{
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position); //跳过不需要读取的字节数,注意只能先后跳
raf.seek(position); //跳到需要写入的位置,没有这句话,会出错,但是很难改。
int hasRead = 0;
byte[] b = new byte[1024];
/**
* 注意,每个线程只是读取一部分数据,不能只以 -1 作为循环结束的条件
* 循环退出条件应该是两个,即写入的字节数大于需要读取的字节数 或者 文件读取结束(最后一个线程读取到文件末尾)
*/
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.net.URL;
import java.net.URLConnection;
/*
* 多线程下载文件:
* 通过一个 URL 获取文件输入流,使用多线程技术下载这个文件。
* */
public class FileDownloadUtil {
//下载线程数
private static final int THREAD_NUM = 4;
/**
* @param url 资源位置
* @param output 输出路径
* @throws IOException
* */
public static void transferFile(String url, String output) throws IOException {
init(output);
URL resource = new URL(url);
URLConnection connection = resource.openConnection();
//获取文件类型
String type = connection.getContentType();
if (type != null) {
type = "."+type.split("/")[1];
} else {
type = "";
}
//创建文件,并设置长度。
long len = connection.getContentLength();
String filename = System.currentTimeMillis()+type;
try (RandomAccessFile raf = new RandomAccessFile(new File(output, filename), "rw")){
raf.setLength(len);
}
//为每一个线程分配相应的下载其实位置
long size = len / THREAD_NUM + 1;
long[] position = new long[THREAD_NUM];
File downloadFile = new File(output, filename);
//开始下载文件: 4个线程
download(url, downloadFile, position, size);
}
private static void download(String url, File file, long[] position, long size) throws IOException {
//开始下载文件: 4个线程
for (int i = 0 ; i < THREAD_NUM; i++) {
position[i] = i * size; //每一个线程下载的起始位置
int n = i; // Lambda 表达式的限制,无法使用变量
new Thread(()->{
URL resource = null;
URLConnection connection = null;
try {
resource = new URL(url);
connection = resource.openConnection();
} catch (IOException e) {
e.printStackTrace();
}
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream());
RandomAccessFile raf = new RandomAccessFile(file, "rw")){ //每个流一旦关闭,就不能打开了
raf.seek(position[n]); //跳到需要下载的位置
bis.skip(position[n]); //跳过不需要下载的部分
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position[n]+" "+curlen+" "+size);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}) .start();
}
}
private static void init(String output) throws FileNotFoundException {
File path = new File(output);
if (!path.exists()) {
if (!path.mkdirs()) {
throw new FileNotFoundException("无法创建输出路径:"+output);
}
} else if (path.isFile()) {
throw new FileNotFoundException("输出路径不是一个目录:"+output);
}
}
}因为这个多线程文件复制和多线程下载是很相似的,所以就放在一起测试了。我也想将两个写在一个类里面,这样可以做成方法的重载调用。 文件复制的第一个参数可以是 String 或者 URI。 使用这个作为目标文件的参数。
public File(URI uri)
网络文件下载的第一个参数,可以使用 String 或者是 URL。 不过,因为先写的这个文件复制,后写的多线程下载,就没有做这部分。不过现在这样功能也达到了,可以进行本地文件的复制(多线程)和网络文件的下载(多线程)。
package dragon;
import java.io.IOException;
public class FileCopyTest {
public static void main(String[] args) throws IOException {
//复制文件
long start = System.currentTimeMillis();
try {
FileCopyUtil.transferFile("D:\\DB\\download\\timg.jfif", "D:\\DBC");
} catch (IOException e) {
e.printStackTrace();
}
long time = System.currentTimeMillis()-start;
System.out.println("time: "+time);
//下载文件
start = System.currentTimeMillis();
FileDownloadUtil.transferFile("https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1578151056184&di=594a34f05f3587c31d9377a643ddd72e&imgtype=0&src=http%3A%2F%2Fn.sinaimg.cn%2Fsinacn%2Fw1600h2000%2F20180113%2F0bdc-fyqrewh6850115.jpg", "D:\\DB\\download");
System.out.println("time: "+(System.currentTimeMillis()-start));
}
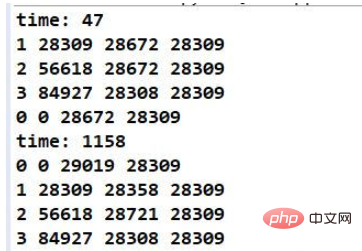
}运行截图: 注意:这里这个时间并不是复制和下载需要的时间,实际上它没有这个功能!
注意:虽然两部分代码是相同的,但是第三列数字,却不是完全相同的,这个似乎是因为本地和网络得区别吧。但是最后得文件是完全相同的,没有问题得。(我本地文件复制得是网络下载得那张图片,使用图片进行测试有一个好处,就是如果错了一点(字节数目不对),这个图片基本上就会产生问题。)
产生错误之后的图片: 图片无法正常显示,会出现很多的问题,这就说明一定是代码写错了。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



