
 Périphériques technologiques
IA
De U-Net à DiT : application de la technologie des transformateurs dans le modèle de diffusion de dominance
Périphériques technologiques
IA
De U-Net à DiT : application de la technologie des transformateurs dans le modèle de diffusion de dominance
De U-Net à DiT : application de la technologie des transformateurs dans le modèle de diffusion de dominance

Ces dernières années, porté par Transformer, le machine learning connaît une renaissance. Au cours des cinq dernières années, les architectures neuronales pour le traitement du langage naturel, la vision par ordinateur et d’autres domaines ont été largement dominées par les transformateurs.
Cependant, il existe de nombreux modèles génératifs au niveau de l'image qui ne sont toujours pas affectés par cette tendance. Par exemple, les modèles de diffusion ont obtenu des résultats étonnants en matière de génération d'images au cours de l'année écoulée, et presque tous ces modèles utilisent U- convolutif. Net comme colonne vertébrale. C'est un peu surprenant ! La grande histoire de l’apprentissage profond au cours des dernières années a été la domination de Transformer dans tous les domaines. Y a-t-il quelque chose de spécial à propos d'U-Net ou des convolutions qui les rend si performants dans les modèles de diffusion ?
La recherche qui a introduit pour la première fois le réseau fédérateur U-Net dans le modèle de diffusion remonte à Ho et al. Ce modèle de conception hérite du modèle génératif autorégressif PixelCNN++ avec seulement de légers changements. PixelCNN++ se compose de couches convolutives, qui contiennent de nombreux blocs ResNet. Par rapport au U-Net standard, le bloc d’auto-attention spatiale supplémentaire de PixelCNN++ devient un composant de base du transformateur. Contrairement à d'autres études, Dhariwal et Nichol et al. éliminent plusieurs choix architecturaux d'U-Net, tels que l'utilisation de couches de normalisation adaptatives pour injecter des informations sur les conditions et le nombre de canaux dans les couches convolutives.
Dans cet article, William Peebles de l'UC Berkeley et Xie Saining de l'Université de New York ont écrit "Modèles de diffusion évolutifs avec transformateurs". L'objectif est de découvrir l'importance des choix architecturaux dans les modèles de diffusion et de fournir une base empirique pour les futures générations. recherche de modèles. Cette étude montre que la polarisation inductive U-Net n'est pas essentielle aux performances des modèles de diffusion et peut être facilement remplacée par des conceptions standards telles que des transformateurs.
Cette découverte montre que les modèles de diffusion peuvent bénéficier des tendances d'unification architecturale. Par exemple, les modèles de diffusion peuvent hériter des meilleures pratiques et méthodes de formation d'autres domaines, conservant l'évolutivité, la robustesse et l'efficacité de ces modèles. Une architecture standardisée ouvrira également de nouvelles possibilités pour la recherche inter-domaines.

- Adresse papier : https://arxiv.org/pdf/2212.09748.pdf
- Adresse du projet : https://github.com/facebookresearch/DiT
- Page d'accueil du papier : https://www.wpeebles.com/DiT
Cette recherche se concentre sur un nouveau type de modèle de diffusion basé sur un transformateur : les transformateurs de diffusion (DiTs en abrégé). Les DiT suivent les meilleures pratiques des Vision Transformers (ViT), avec quelques ajustements mineurs mais importants. Il a été démontré que DiT évolue plus efficacement que les réseaux convolutifs traditionnels tels que ResNet.
Plus précisément, cet article étudie le comportement de mise à l'échelle de Transformer en termes de complexité du réseau et de qualité des échantillons. L'étude montre qu'en construisant et en évaluant l'espace de conception DiT dans le cadre du modèle de diffusion latente (LDM), où le modèle de diffusion est formé dans l'espace latent de VAE, il est possible de remplacer avec succès le squelette U-Net par un transformateur. Cet article montre en outre que DiT est une architecture évolutive pour les modèles de diffusion : il existe une forte corrélation entre la complexité du réseau (mesurée par Gflops) et la qualité des échantillons (mesurée par FID). En étendant simplement DiT et en entraînant un LDM avec un réseau fédérateur haute capacité (118,6 Gflops), des résultats de pointe de 2,27 FID sont obtenus sur le benchmark de génération ImageNet 256 × 256 conditionnel à la classe.
Diffusion Transformers
DiTs est une nouvelle architecture de modèles de diffusion qui vise à être la plus fidèle possible à l'architecture standard du transformateur afin de conserver son évolutivité. DiT conserve bon nombre des meilleures pratiques de ViT, et la figure 3 montre l'architecture complète de DiT. L'entrée de
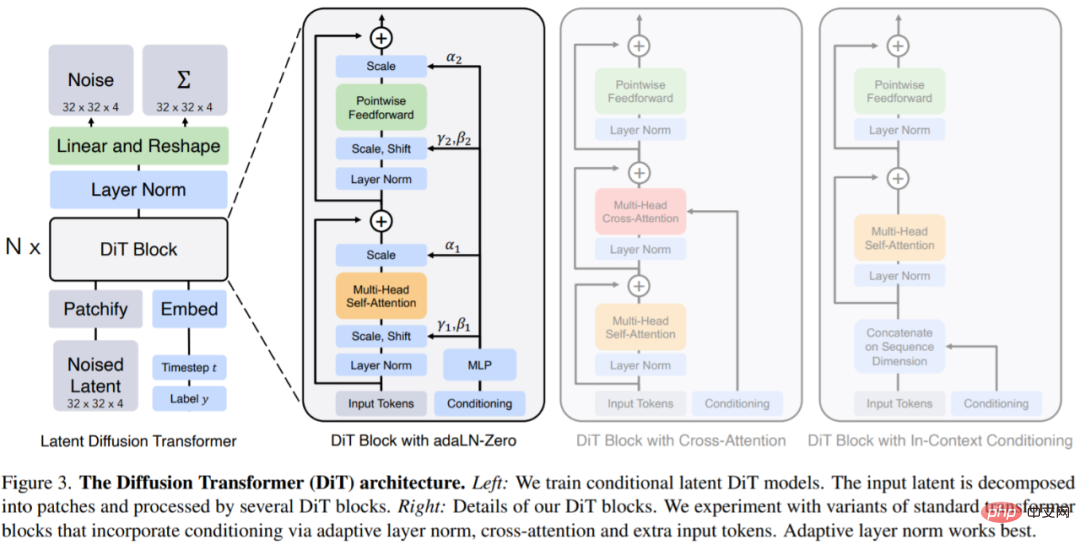
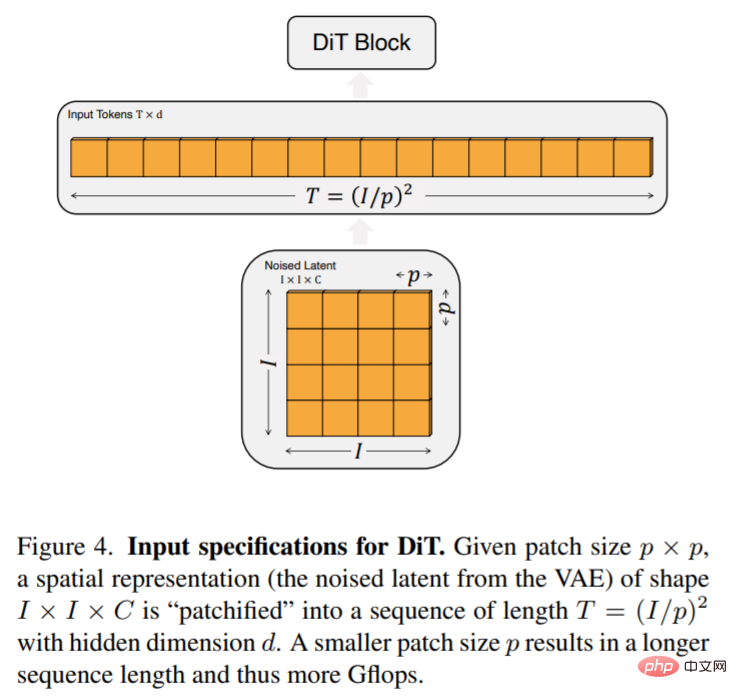
DiT est la représentation spatiale z (pour une image 256 × 256 × 3, la forme de z est 32 × 32 × 4). La première couche de DiT est patchify, qui convertit l'entrée spatiale en une séquence de jetons T en intégrant linéairement chaque patch dans l'entrée. Après patchify, nous appliquons des intégrations positionnelles standard basées sur la fréquence ViT à tous les jetons d'entrée.
Le nombre de tokens T créés par patchify est déterminé par l'hyperparamètre de taille du patch p. Comme le montre la figure 4, la réduction de moitié de p quadruple T et donc au moins quadruple les Gflops du transformateur. Cet article ajoute p = 2,4,8 à l'espace de conception DiT.
Conception du bloc DiT : après patchify, le jeton d'entrée est traité par une série de blocs de transformateur. En plus de l'entrée d'image bruitée, les modèles de diffusion gèrent parfois des informations conditionnelles supplémentaires, telles que le pas de temps de bruit t, l'étiquette de classe c, le langage naturel, etc. Cet article explore quatre variantes de blocs de transformateur qui gèrent l'entrée conditionnelle de différentes manières. Ces conceptions comportent des modifications mineures mais significatives par rapport à la conception standard du bloc ViT. La conception de tous les modules est illustrée à la figure 3.
Cet article a essayé quatre configurations qui varient selon la profondeur et la largeur du modèle : DiT-S, DiT-B, DiT-L et DiT-XL. Ces configurations de modèles vont de 33 M à 675 M de paramètres et de Gflops de 0,4 à 119.
Expérience
Les chercheurs ont formé quatre modèles DiT-XL/2 avec les Gflops les plus élevés, chacun utilisant une conception de bloc différente - en contexte (119,4 Gflops), attention croisée (137,6 Gflops), norme de couche adaptative (adaLN , 118,6 Gflops) ou adaLN-zéro (118,6 Gflops). Le FID a ensuite été mesuré pendant l'entraînement et la figure 5 montre les résultats.
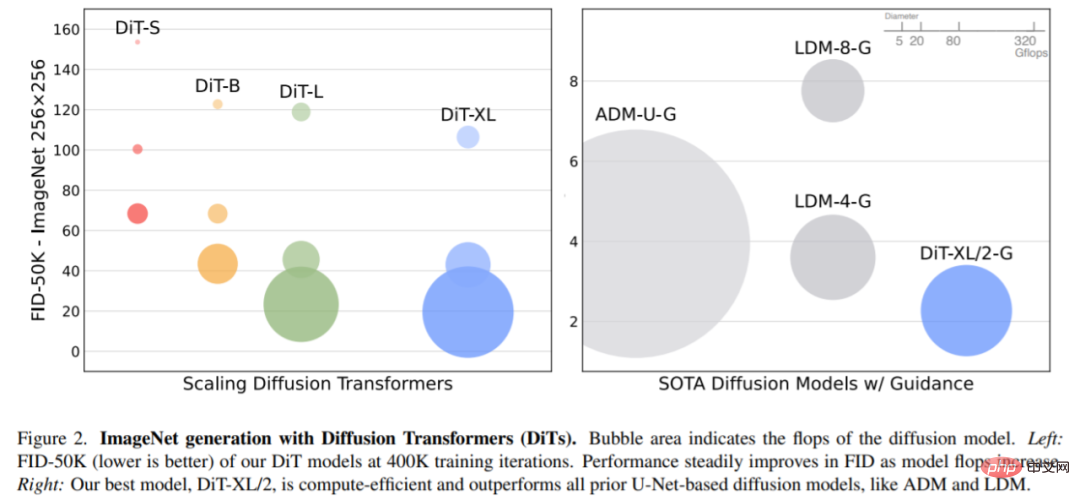
Taille du modèle étendue et taille du patch. La figure 2 (à gauche) donne un aperçu des Gflops pour chaque modèle et de leur FID à 400 000 itérations de formation. On peut constater que l’augmentation de la taille du modèle et la réduction de la taille des patchs produisent des améliorations considérables du modèle de diffusion.
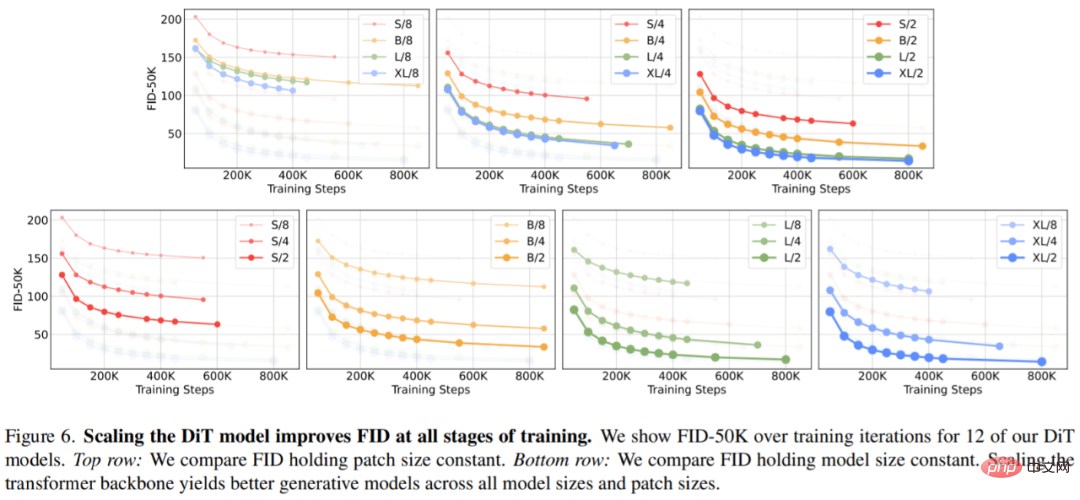
La figure 6 (en haut) montre comment le FID change à mesure que la taille du modèle augmente et que la taille du patch reste constante. Dans les quatre paramètres, des améliorations significatives du FID sont obtenues à toutes les étapes de la formation en rendant le Transformer plus profond et plus large. De même, la figure 6 (en bas) montre le FID lorsque la taille du patch est réduite et que la taille du modèle reste constante. Les chercheurs ont de nouveau observé que le FID s'est considérablement amélioré en augmentant simplement le nombre de jetons traités par DiT et en maintenant les paramètres à peu près fixes tout au long du processus de formation.
La figure 8 montre la comparaison du FID-50K avec le modèle Gflops à 400K étapes de formation :
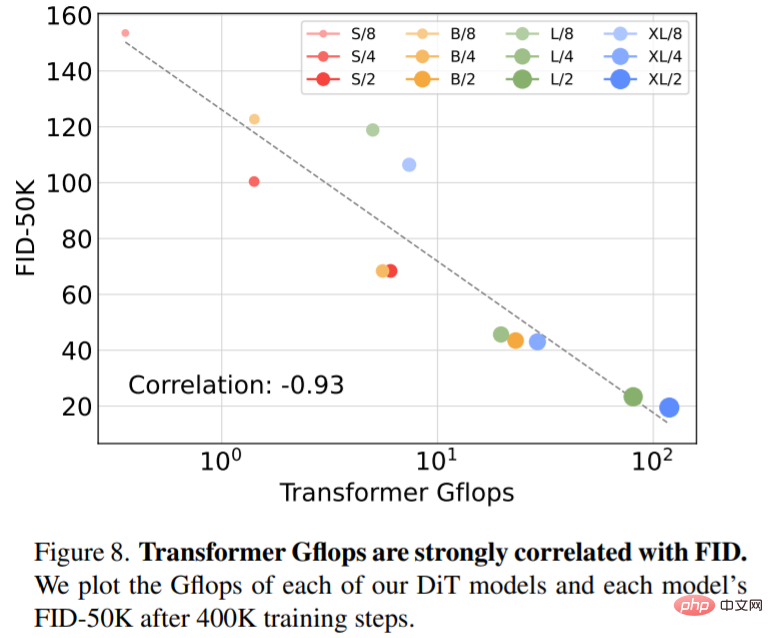
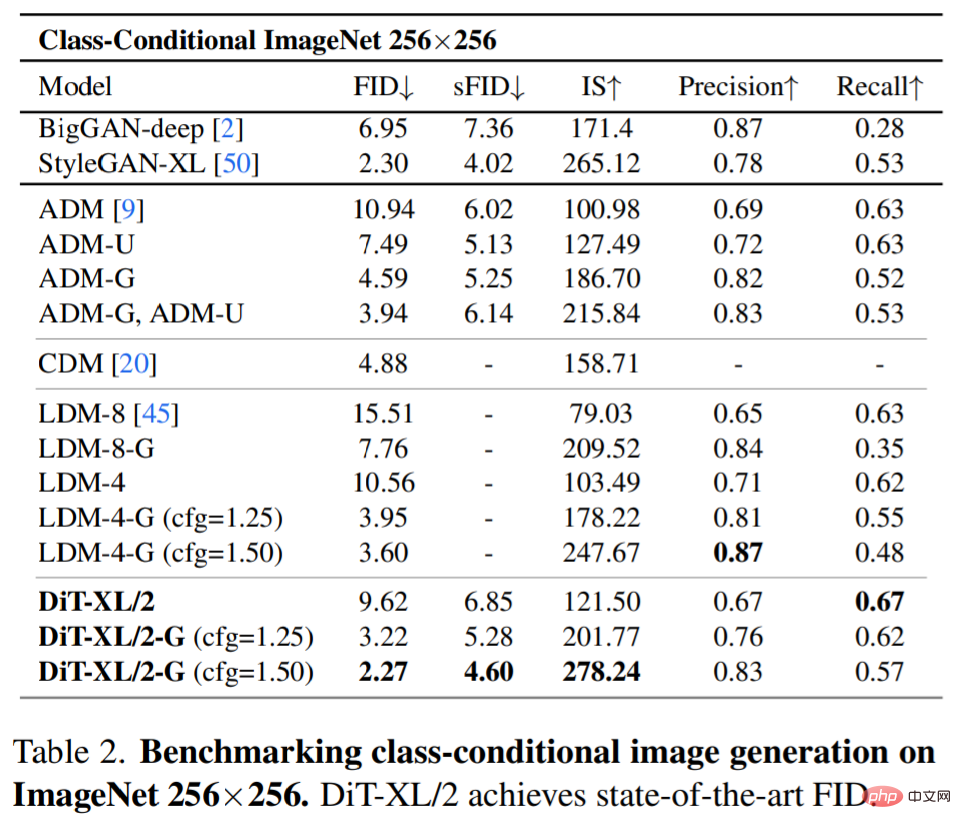
Modèle de diffusion SOTA 256×256 ImageNet. Après l’analyse approfondie, les chercheurs ont continué à entraîner le modèle Gflop le plus élevé, DiT-XL/2, avec un nombre de pas de 7 M. La figure 1 montre un échantillon de ce modèle et le compare au modèle SOTA de génération conditionnelle de catégorie, et les résultats sont présentés dans le tableau 2.

Lors de l'utilisation d'un guidage sans classificateur, DiT-XL/2 surpasse tous les modèles de diffusion précédents, réduisant le précédent meilleur FID-50K de 3,60 obtenu par LDM à 2,27. Comme le montre la figure 2 (à droite), comparé aux modèles U-Net à espace latent tels que LDM-4 (103,6 Gflops), DiT-XL/2 (118,6 Gflops) est beaucoup plus efficace en termes de calcul que ADM (1 120 Gflops) ou). ADM-U (742 Gflops), les modèles U-Net à espace pixel sont beaucoup plus efficaces.
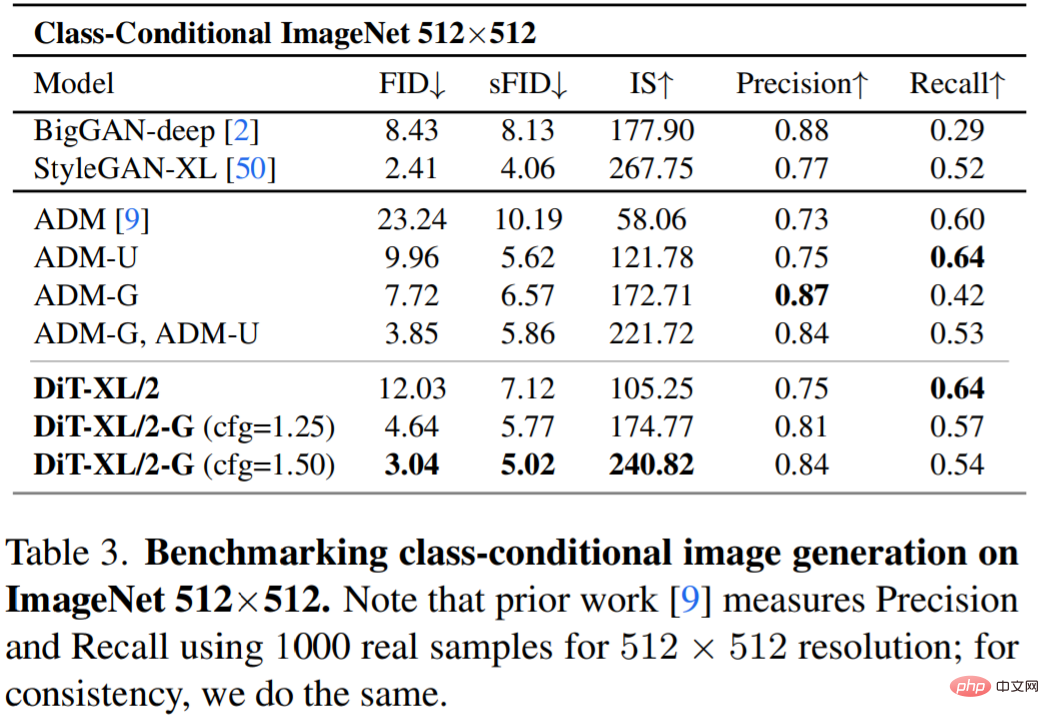
Le tableau 3 montre la comparaison avec les méthodes SOTA. XL/2 surpasse encore une fois tous les modèles de diffusion précédents à cette résolution, améliorant le précédent meilleur FID d'ADM de 3,85 à 3,04.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
